
阅读量:0
文章目录
一、IP-Adapter简介
- IP-Adapter是图像提示适配器,用于预训练的文本到图像扩散模型,以实现使用图像提示生成图像的能力;
- IP-Adapter的关键设计是解耦的交叉注意力机制,将交叉注意力层分离为文本特征和图像特征,实现了图像提示的能力。
二、IP-Adapter与img2img的区分
(一)结构上的区别
- img2img使用unet架构,包括一个编码器(下采样)和一个解码器(上采样)
- IP-Adapter包括一个图像编码器和包含解耦交叉注意力机制的适配器
(二)流程上的区别
- img2img通过编码/解码器,需要通过一系列上采样、下采样
- IP-Adapter通过图像编码器,文本提示和图像特征通过适配模块与预训练的文本到图像模型进行交互
(三)输出上的区别
现在给出prompt要求在图1一个男人的基础上加上参考图2:
- img2img是输出一个转换后的图像:相当于直接盖在参考图上开始临摹,画出一些强行混合不知所谓的图来。

- IP-Adapter是根据文本和图像提示生成的图片:IP-Adapter则不是临摹,而是真正的自己去画,将参考图与原图荣威一体

(四)原理上的区别
stable diffustion是扩散模型,它的核心作用机制就是对噪音的处理,prompt可以看做是我们的目标,通过不断的去噪过程,向着目标越来越靠近,最终生成出预期的图片。

IP-Adapter将图片单独提出作为一种提示特征,相比SD模型把图像特征和文本特征抽取后拼接在一起的方法,IP-Adapter通过带有解耦交叉注意力的适配模块,将文本特征的Cross-Attention 和图像特征的Cross-Attention区分开来,在Unet的模块中新增了一路Cross-Attention模块,用于引入图像特征。
img2img是直接将参考图传入unet,去替换了原始的随机噪音,这样所有的生成结果都是建立在它的基础上,于是有了前面人和老虎混杂的现象就比较好理解了。
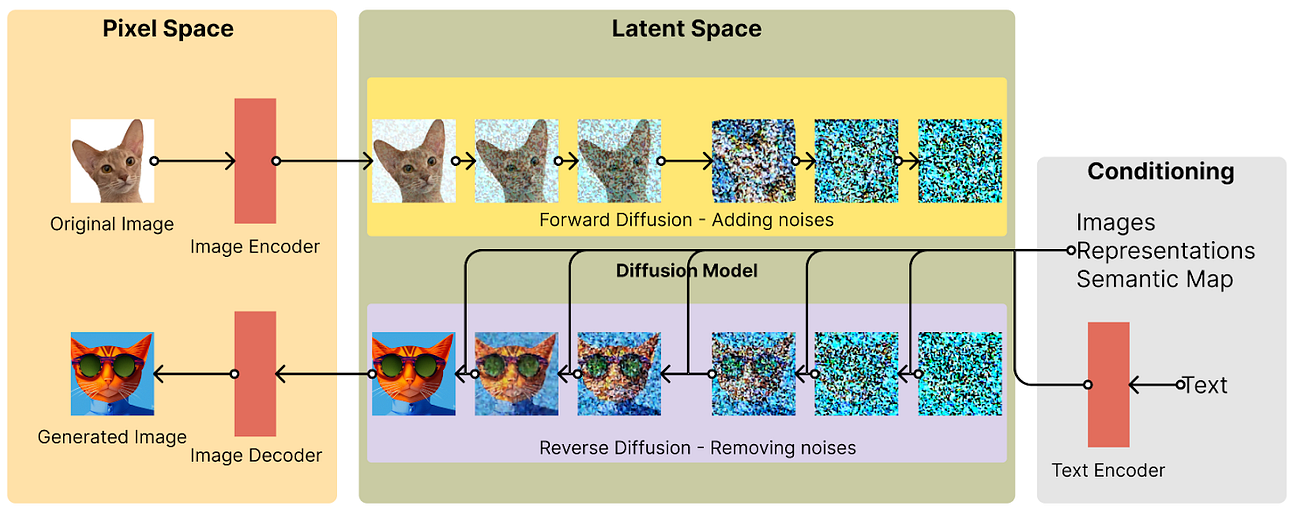
三、IP-Adapter的网络架构
- 当前adapter很难达到微调图像提示模型或从头训练的模型性能,主要原因是图像特征无法有效的嵌入预训练模型中。大多数方法只是将拼接的特征输入到冻结的cross-attention中,阻止了扩散模型捕捉图像图像提示的细粒度特征。
- 为了解决这个问题,我们提出了一种解耦交叉注意力策略,即通过新添加的交叉注意力层嵌入图像特征。提议的IP-adapter包含两个部分:
- 图像编码器用于从图像提示中提取图像特征;
- 具有解耦的cross-attention的适配模块,用于将图像特征嵌入预训练的文本到图像扩散模型中。
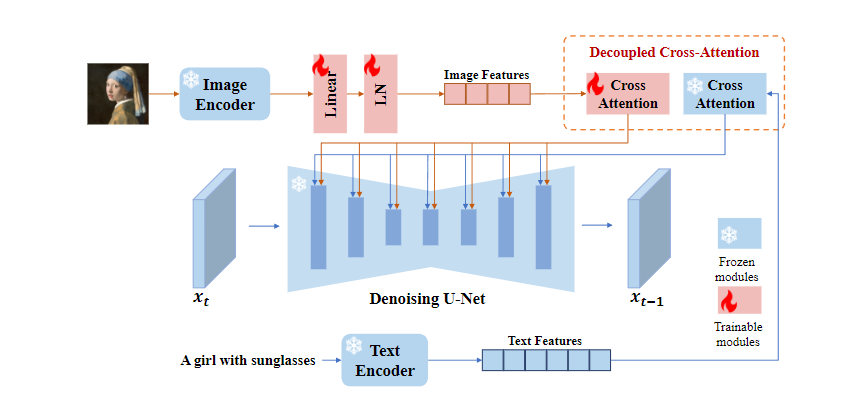
(一)图像编码器
- 与大多数方法一样,我们使用预训练好的 CLIP 图像编码器模型从图像提示中提取图像特征;
- 我们利用 CLIP 图像编码器中的全局图像嵌入,它与图像字幕非常吻合,能代表图像的丰富内容和风格;
- 在训练阶段,CLIP 图像编码器被冻结。
(二)解耦交叉注意力
图像特征由具有解耦交叉注意力的适配模块集成到预训练的UNet模型中。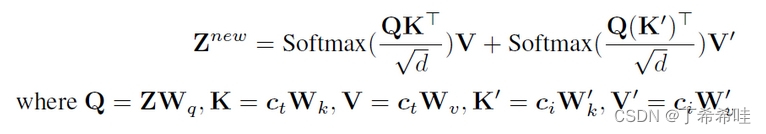 把文本特征和图像特征分开cross-attention再相加,之前的想法大多数先将图像特征和文本特征拼接后再cross。
把文本特征和图像特征分开cross-attention再相加,之前的想法大多数先将图像特征和文本特征拼接后再cross。
(三)训练和推理
- 在训练过程中,我们只对 IP 适配器进行优化,同时保持预训练扩散模型的参数不变,训练目标与原始 SD 相同:
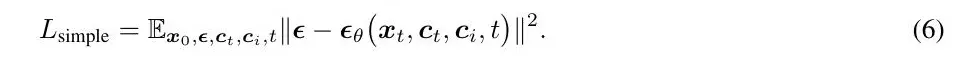
- 我们还在训练阶段随机放弃图像条件,以便在推理阶段实现无分类器指导:
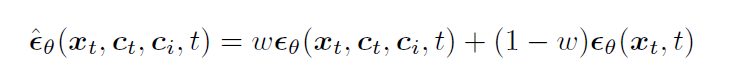
- 如果丢弃了图像条件,可以将clip图像embedding归0。由于文本cross-attention和图像cross-attention是分离的,在推理阶段还可以调整图像条件的权重:

参考:
图像作为prompt#IP-Adapter
新一代“垫图”神器,IP-Adapter的完整应用解读
IP-Adapter:text compatible image prompt adapter for text-to-image diffusion models
IP-Adapter:用于文本到图像扩散模型的文本兼容图像提示适配器
