
阅读量:0
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)
正文
novel_Type = text.xpath(“.//table[@id=‘at’]/tr[1]/td[1]/a/text()”) if response.xpath(“.//table[@id=‘at’]/tr[1]/td[1]/a/text()”) else “None”
novel_Writer = “”.join(text.xpath(“.//table[@id=‘at’]/tr[1]/td[2]/text()”)) if response.xpath(“.//table[@id=‘at’]/tr[1]/td[2]/text()”) else “None”
novel_Status = “”.join(text.xpath(“.//table[@id=‘at’]/tr[1]/td[3]/text()”)) if response.xpath(“.//table[@id=‘at’]/tr[1]/td[3]/text()”) else “None”
novel_Words = self.getNumber(“”.join(text.xpath(“.//table[@id=‘at’]/tr[2]/td[2]/text()”))) if response.xpath(“.//table[@id=‘at’]/tr[2]/td[2]/text()”) else “None”
novel_UpdateTime = “”.join(text.xpath(“.//table[@id=‘at’]/tr[2]/td[3]/text()”)) if response.xpath(“.//table[@id=‘at’]/tr[2]/td[3]/text()”) else “None”
novel_AllClick = int(“”.join(text.xpath(“.//table[@id=‘at’]/tr[3]/td[1]/text()”))) if response.xpath(“.//table[@id=‘at’]/tr[3]/td[1]/text()”) else “None”
novel_MonthClick = int(“”.join(text.xpath(“.//table[@id=‘at’]/tr[3]/td[2]/text()”))) if response.xpath(“.//table[@id=‘at’]/tr[3]/td[2]/text()”) else “None”
novel_WeekClick = int(“”.join(text.xpath(“.//table[@id=‘at’]/tr[3]/td[3]/text()”))) if response.xpath(“.//table[@id=‘at’]/tr[3]/td[3]/text()”) else “None”
novel_AllComm = int(“”.join(text.xpath(“.//table[@id=‘at’]/tr[4]/td[1]/text()”))) if response.xpath(“.//table[@id=‘at’]/tr[4]/td[1]/text()”) else “None”
novel_MonthComm = int(“”.join(text.xpath(“.//table[@id=‘at’]/tr[4]/td[3]/text()”))) if response.xpath(“.//table[@id=‘at’]/tr[4]/td[2]/text()”) else “None”
novel_WeekComm = int(“”.join(text.xpath(“.//table[@id=‘at’]/tr[4]/td[3]/text()”))) if response.xpath(“.//table[@id=‘at’]/tr[4]/td[3]/text()”) else “None”
pattern = re.compile(‘
(.*)<br’)
match = pattern.search(ht)
novel_Introduction = “”.join(match.group(1).replace(" “,”")) if match else “None”
#封装小说信息类
bookitem = BookItem(
novel_Type = novel_Type[0],
novel_Name = novel_Name,
novel_ImageUrl = novel_ImageUrl,
_id = novel_ID, #小说id作为唯一标识符
novel_Writer = novel_Writer,
novel_Status = novel_Status,
novel_Words = novel_Words,
novel_UpdateTime = novel_UpdateTime,
novel_AllClick = novel_AllClick,
novel_MonthClick = novel_MonthClick,
novel_WeekClick = novel_WeekClick,
novel_AllComm = novel_AllComm,
novel_MonthComm = novel_MonthComm,
novel_WeekComm = novel_WeekComm,
novel_Url = novel_Url,
novel_Introduction = novel_Introduction,
)
return bookitem
2.解析章节信息
def parse_chapter_content(self,response):
if not response.body:
print(response.url+“已经被爬取过了,跳过”)
return;
ht = response.body.decode(‘utf-8’)
text = html.fromstring(ht)
soup = BeautifulSoup(ht)
novel_ID = response.url.split(“/”)[-2]
novel_Name = text.xpath(“.//p[@class=‘fr’]/following-sibling::a[3]/text()”)[0]
chapter_Name = text.xpath(“.//h1[1]/text()”)[0]
‘’’
chapter_Content = “”.join(“”.join(text.xpath(“.//dd[@id=‘contents’]/text()”)).split())
if len(chapter_Content) < 25:
chapter_Content = “”.join(“”.join(text.xpath(“.//dd[@id=‘contents’]//*/text()”)))
pattern = re.compile(‘dd id=“contents”.?>(.?)’)
match = pattern.search(ht)
chapter_Content = “”.join(match.group(1).replace(" “,”").split()) if match else “爬取错误”
‘’’
result,number = re.subn(“<.*?>”,“”,str(soup.find(“dd”,id=‘contents’)))
chapter_Content = “”.join(result.split())
print(len(chapter_Content))
novel_ID = response.url.split(“/”)[-2]
return ChapterItem(
chapter_Url = response.url,
_id=int(response.url.split(“/”)[-1].split(“.”)[0]),
novel_Name=novel_Name,
chapter_Name=chapter_Name,
chapter_Content= chapter_Content,
novel_ID = novel_ID,
is_Error = len(chapter_Content) < 3000
)
3.scrapy中实现增量式爬取的几种方式
1.缓存
通过开启缓存,将每个请求缓存至本地,下次爬取时,scrapy会优先从本地缓存中获得response,这种模式下,再次请求已爬取的网页不用从网络中获得响应,所以不受带宽影响,对服务器也不会造成额外的压力,但是无法获取网页变化的内容,速度也没有第二种方式快,而且缓存的文件会占用比较大的内存,在setting.py的以下注释用于设置缓存
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = ‘httpcache’
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage’
这种方式比较适合内存比较大的主机使用,我的阿里云是最低配的,在爬取半个晚上接近27W个章节信息后,内存就用完了
2.对item实现去重
本文开头的第一种方式,实现方法是在pipelines.py中进行设置,即在持久化数据之前判断数据是否已经存在,这里我用的是mongodb持久化数据,逻辑如下
#处理书信息
def process_BookItem(self,item):
bookItemDick = dict(item)
try:
self.bookColl.insert(bookItemDick)
print(“插入小说《%s》的所有信息”%item[“novel_Name”])
except Exception:
print(“小说《%s》已经存在”%item[“novel_Name”])
#处理每个章节
def process_ChapterItem(self,item):
try:
self.contentColl.insert(dict(item))
print(‘插入小说《%s》的章节"%s"’%(item[‘novel_Name’],item[‘chapter_Name’]))
except Exception:
print(“%s存在了,跳过”%item[“chapter_Name”])
def process_item(self, item, spider):
‘’’
if isinstance(item,ChaptersItem):
self.process_ChaptersItem(item)
‘’’
if isinstance(item,BookItem):
self.process_BookItem(item)
if isinstance(item,ChapterItem):
self.process_ChapterItem(item)
return item
两种方法判断mongodb中是否存在已有的数据,一是先查询后插入,二是先设置唯一索引或者主键再直接插入,由于mongodb的特点是插入块,查询慢,所以这里直接插入,需要将唯一信息设置为”_id”列,或者设置为唯一索引,在mongodb中设置方法如下
db.集合名.ensureIndex({“要设置索引的列名”:1},{“unique”:1})
需要用什么信息实现去重,就将什么信息设置为唯一索引即可(小说章节信息由于数据量比较大,用于查询的列最好设置索引,要不然会非常慢),这种方法对于服务器的压力太大,而且速度比较慢,我用的是第二种方法,即对已爬取的url进行去重
3.对url实现去重
对我而言,这种方法是最好的方法,因为速度快,对网站服务器的压力也比较小,不过网上的资料比较少,后来在文档中发现scrapy可以自定义下载中间件,才解决了这个问题
文档原文如下
class scrapy.downloadermiddlewares.DownloaderMiddleware
process_request(request, spider) 当每个request通过下载中间件时,该方法被调用。
process_request() 必须返回其中之一: 返回 None 、返回一个 Response 对象、返回一个 Request
对象或raise IgnoreRequest 。
如果其返回 None ,Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download
handler)被调用, 该request被执行(其response被下载)。
如果其返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或
process_exception() 方法,或相应地下载函数; 其将返回该response。 已安装的中间件的
process_response() 方法则会在每个response返回时被调用。
如果其返回 Request 对象,Scrapy则停止调用
process_request方法并重新调度返回的request。当新返回的request被执行后,
相应地中间件链将会根据下载的response被调用。
如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception()
方法会被调用。如果没有任何一个方法处理该异常,
则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常,
则该异常被忽略且不记录(不同于其他异常那样)。
所以只需要在process_request中实现去重的逻辑就可以了,代码如下
class UrlFilter(object):
#初始化过滤器(使用mongodb过滤)
def init(self):
self.settings = get_project_settings()
self.client = pymongo.MongoClient(
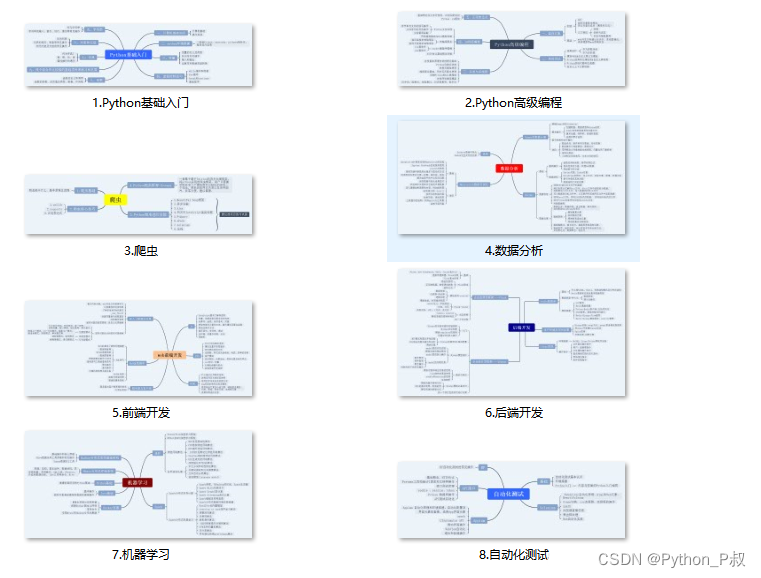
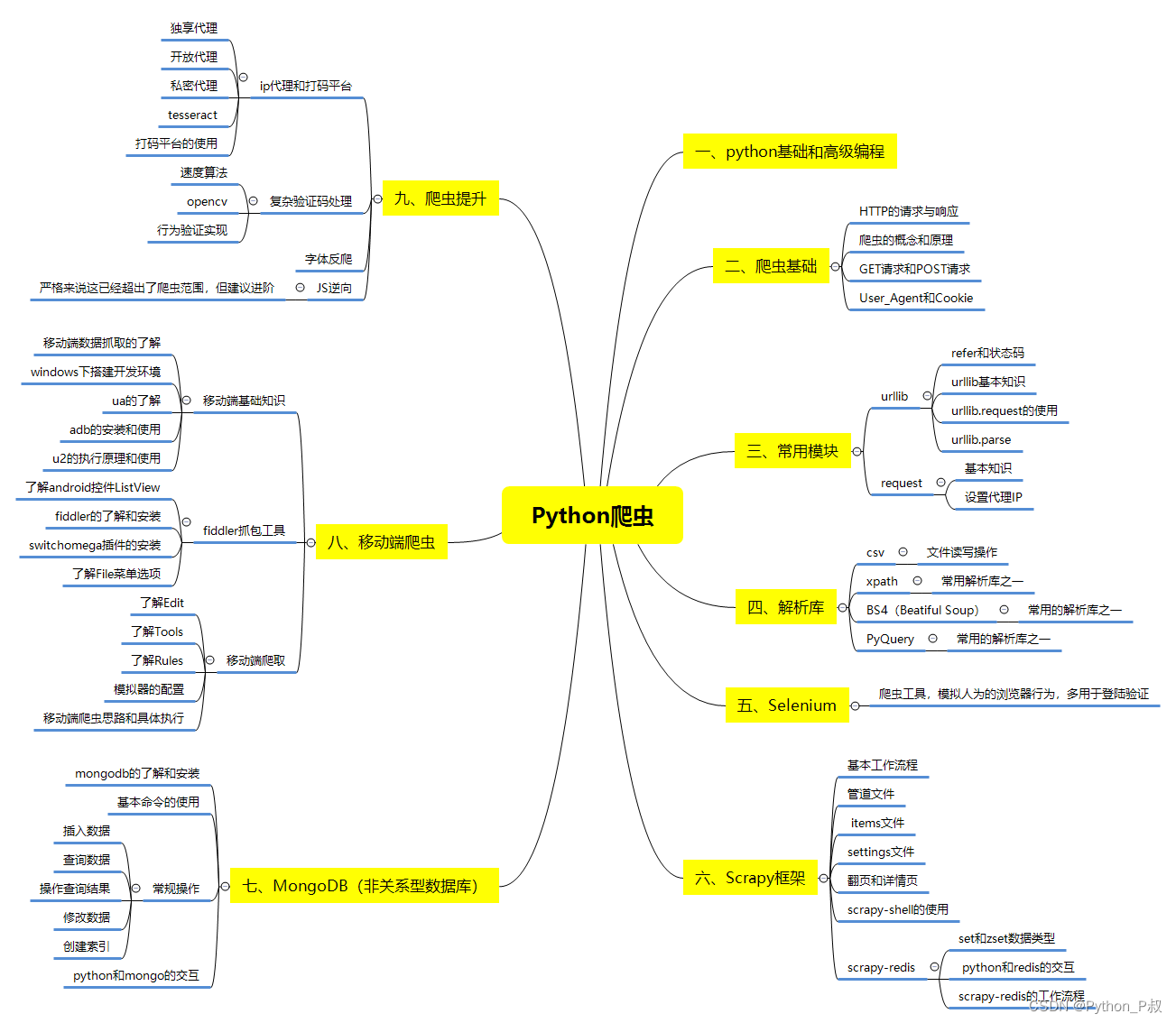
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
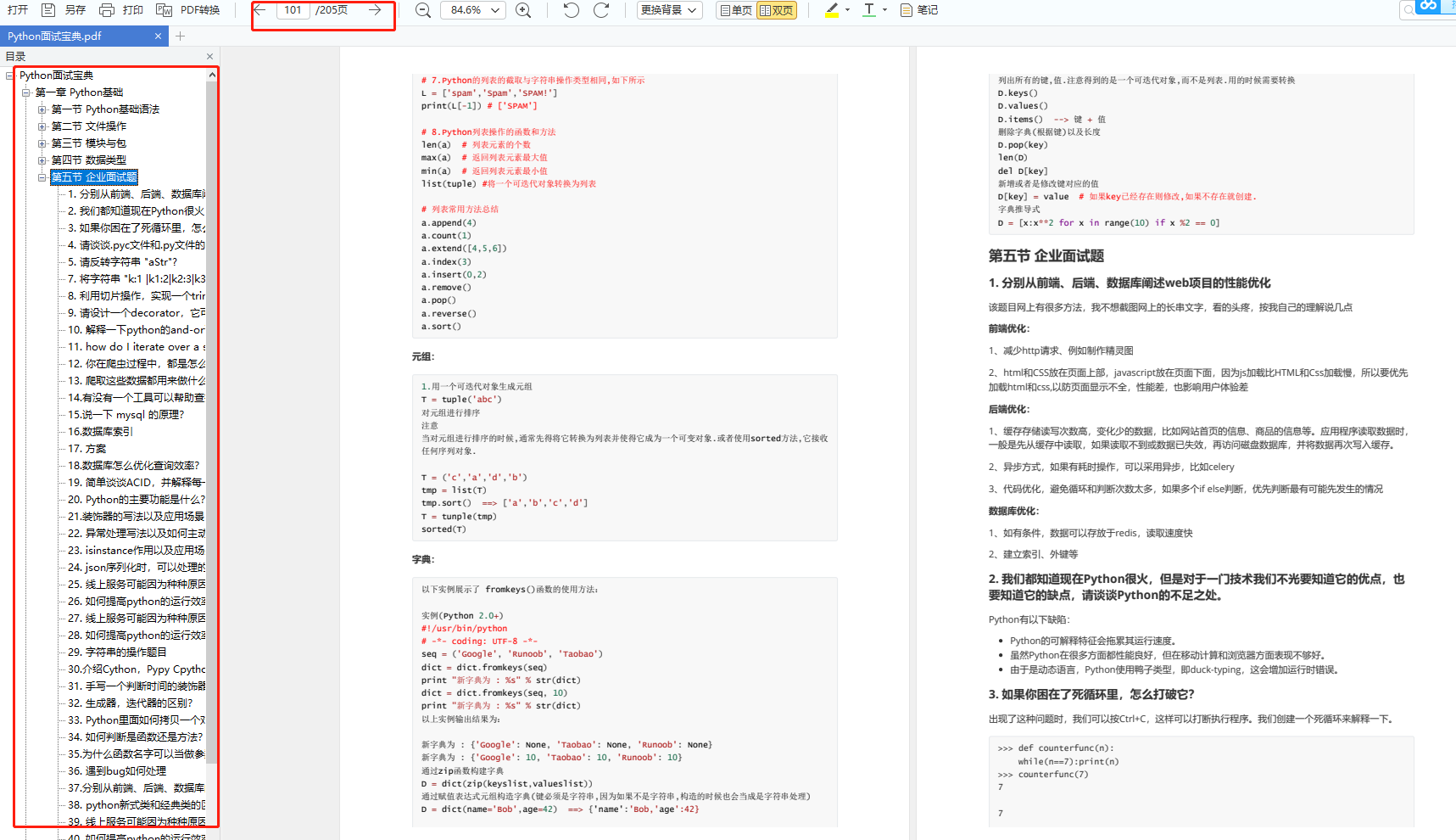
六、面试宝典
简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
5462e7df433b981dc2430bb9ad39.png)
简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-NqTJM2Yw-1713386034685)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
