
阅读量:0
1.简介
Scrapy是一个用于抓取网站和提取结构化数据的应用程序框架,可用于广泛的有用应用程序,如数据挖掘、信息处理或历史档案。
尽管Scrapy最初是为网络抓取而设计的,但它也可以用于使用 API(例如Amazon Associates Web Services)或作为通用网络爬虫来提取数据。
2.安装Scrapy
Scrapy需要Python 3.6+,无论是CPython实现(默认)还是PyPy 7.2.0+实现。
我这里是在VS Code上终端使用Python包管理工具命令(pip)从PyPI(python官方的第三方库的仓库)安装Scrapy包及其依赖项:
pip install Scrapy卸载Scrapy包命令:
pip uninstall Scrapy安装指定Scrapy包版本命令:
pip install Scrapy==2.6.1如图所示:

然后可以输入如下命令查看安装是否成功:
pip list如图所示:


从如上两图可见,Scrapy包安装成功!
3.创建Scrapy项目
Scrapy是用Python编写的。如果您是该语言的新手,您可能希望从了解该语言的概念开始,以充分了解使用Scrapy。现在让我们来创建一个新的Scrapy项目。切换到您要存储代码并运行的目录:
cd D:\Project\GitHub scrapy startproject scrapy_deng_sample 通过VS Code打开scrapy_deng_sample模板项目,会看到如下目录结构: scrapy_deng_sample/ scrapy.cfg # 部署配置文件 scrapy_deng_sample/ # 项目的Python模块,您将从这里导入代码 __init__.py items.py # 项目定义文件 middlewares.py # 项目中间件文件 pipelines.py # 项目管道文件 settings.py # 项目设置文件 spiders/ # 一个目录,稍后您将在其中放置您的spider文件 __init__.py如图所示:

4.第一个蛛蛛爬虫示例
Scrapy项目创建好了,现在让我们来尝试下抓取百度热点新闻。scrapy_deng_sample\spiders目录是存放定义蛛蛛爬虫Spider文件。现在来新建一个名称叫baidu_news_board.py的Spider文件,在里面定义一个叫baidu_news_board_spider类用作爬取百度热点新闻。
请看如下代码:
import scrapy from scrapy_deng_sample.items import BaiduNewsBoardItem class baidu_news_board_spider(scrapy.Spider): name='baidu_news_board' def start_requests(self): urls=["https://top.baidu.com/board?tab=realtime"] for url in urls: yield scrapy.Request(url=url,callback=self.parse) def parse(self,response): url = response.url board_nodels = response.xpath("//div[@class='container-bg_lQ801']/div")[1].xpath(".//div[@class='category-wrap_iQLoo horizontal_1eKyQ']") print(f"热点节点数量:{len(board_nodels)}") for board_nodel in board_nodels: yield self.init_board_item(board_nodel) def init_board_item(self,board_nodel): item = BaiduNewsBoardItem() imgUrlNodel = board_nodel.xpath('a/div/img') if len(imgUrlNodel) < 1: imgUrlNodel = board_nodel.xpath('a/img') if len(imgUrlNodel) < 1: item["ImgUrl"] = '' item["ImgUrl"] = imgUrlNodel.attrib['src'] item["HotSearchIndex"] = board_nodel.xpath("div")[0].xpath("div[@class='hot-index_1Bl1a']/text()").get() item["NewsUrl"] = board_nodel.xpath("div")[1].xpath("a").attrib['href'] item["Title"] = board_nodel.xpath("div")[1].xpath("a/div/text()").get() item["Content"] = board_nodel.xpath("div")[1].xpath("div/text()").get() self.log(f'节点信息: {item}') return item在items.py项目定义文件里面定义一个新闻热点对象用来接收数据:
class BaiduNewsBoardItem(scrapy.Item): Title = scrapy.Field() Content = scrapy.Field() ImgUrl = scrapy.Field() NewsUrl = scrapy.Field() HotSearchIndex = scrapy.Field()如您所见,scrapy.Spider并定义了一些属性和方法:
●name:爬虫蜘蛛唯一标识(它在一个项目中必须是唯一的,即不能为不同的Spider设置相同的名称)。
●start_requests():返回一个可迭代的Requests(你可以返回一个请求列表或编写一个生成器函数),Spider将从中开始爬取。
●parse():处理每个请求响应的方法。
●init_board_item():初始化新闻热点对象。
要让我们的爬虫蜘蛛示例工作,请转到项目的顶级目录并运行该命令:
scrapy crawl baidu_news_board如图所示:
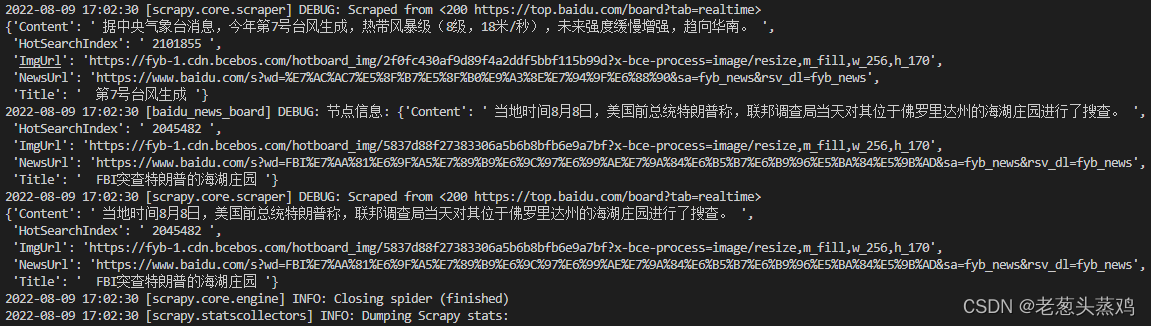
由此可见Scrapy调度了baidu_news_spider爬虫蛛蛛类的scrapy.Request(start_requests方法)返回的对象。start_requests在接收到每个对象的响应后,它会实例化Response对象并调用关联的回调parse方法作为参数传递,循环初始化新闻热点对象(init_board_item)。
5.小结
这里主要介绍Scrapy包安装、模板项目创建与爬虫示例演示,后续再来了解下Scrapy项目结构。
参考文献:
Scrapy安装指南https://docs.scrapy.org/en/latest/intro/install.html
Scrapy教程https://docs.scrapy.org/en/latest/intro/tutorial.html
