
阅读量:0
目录
settings文件中参数详解
在Scrapy框架中,settings.py文件包含一系列的配置参数,用来自定义Scrapy项目的行为,包括核心组件、扩展、管道和爬虫本身。以下是一些主要的Scrapy设置参数及其解释。
BOT_NAME
BOT_NAME是Scrapy设置中的一个参数,用于定义Scrapy项目的名称。这个名称将用于构造默认的User-Agent,除非被覆盖。例如,如果BOT_NAME被设置为"carwl_meritalk",那么默认的User-Agent将是"carwl_meritalk (+http://www.yourdomain.com)"。例如:
BOT_NAME = 'my_spider' SPIDER_MODULES
包含项目中所有spider的模块列表。例如:
SPIDER_MODULES = ["carwl_meritalk.spiders"]NEWSPIDER_MODULE
当使用scrapy genspider命令创建新spider时,spider将会放在这个模块下。 例如
NEWSPIDER_MODULE = "carwl_meritalk.spiders"USER_AGENT
USER_AGENT是Scrapy设置中的一个参数,用于定义Scrapy下载器在发送HTTP请求时使用的User-Agent。User-Agent是一个HTTP头部字段,用于标识发出请求的客户端的类型和版本信息,例如操作系统、浏览器等。服务器可以根据User-Agent来决定返回什么样的内容或者进行什么样的处理。你可以将USER_AGENT设置为模拟一个常见的浏览器,例如:
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3" ROBOTSTXT_OBEY
ROBOTSTXT_OBEY是Scrapy设置中的一个参数,用于控制Scrapy是否应遵守robots.txt规则。robots.txt是一个网站的根目录下的文本文件,用于告诉爬虫哪些页面可以爬取,哪些页面不可以爬取。 如果ROBOTSTXT_OBEY设置为True,那么Scrapy将会尊重robots.txt规则,只爬取允许爬取的页面。如果设置为False,那么Scrapy将不会考虑robots.txt规则,可能会爬取所有页面。例如:
ROBOTSTXT_OBEY = FalseCONCURRENT_REQUESTS
对任意单个域或IP的最大并行请求数,调整这个数值可以控制并发水平。例如:
#CONCURRENT_REQUESTS = 32DOWNLOAD_DELAY
DOWNLOAD_DELAY是Scrapy设置中的一个参数,用于定义两个连续请求之间的延迟时间,单位是秒。例如:
# DOWNLOAD_DELAY = 3COOKIES_ENABLED
是否启用cookies中间件。如果关闭,请求将不携带cookies。例如:
COOKIES_ENABLED = FalseDEFAULT_REQUEST_HEADERS
默认请求头。可以在这里设置浏览器默认的请求头,一些网站可能需要特定的请求头进行访问。例如:
DEFAULT_REQUEST_HEADERS = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6", } SPIDER_MIDDLEWARES
启用的爬虫中间件及其排序的字典。数值越小,组件的优先级越高。例如:
#SPIDER_MIDDLEWARES = { # "carwl_meritalk.middlewares.CarwlMeritalkSpiderMiddleware": 543, #} DOWNLOADER_MIDDLEWARES
DOWNLOADER_MIDDLEWARES在Scrapy框架中是一个重要的组件,它是一个处理下载器下载动作的中间件集合。这些中间件位于Scrapy的请求/响应处理的中心位置,可以在Scrapy发送请求到网站服务器之前或从服务器接收到响应之后执行自定义的代码。
# DOWNLOADER_MIDDLEWARES是一个字典,定义了启用的下载器中间件及其顺序。 # 数字越小,中间件越早执行。这里启用了三个中间件。 DOWNLOADER_MIDDLEWARES = { 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 543, # HttpProxyMiddleware是Scrapy内置的处理HTTP代理的中间件,如果请求的meta中设置了'proxy',这个中间件就会设置这个代理。 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, # UserAgentMiddleware是Scrapy内置的处理User-Agent的中间件,这里被设置为None,表示禁用这个中间件。 'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400 # RandomUserAgentMiddleware是一个第三方中间件,用于随机设置User-Agent,以防止被目标网站封禁。 } ITEM_PIPELINES
启用的item pipeline类的字典。这需要设置为一个字典,字典的键是pipeline类的路径,值是一个整数值,确定了他们的运行顺序。item通过这些pipeline,从低值到高值。当你创建scrapy项目后会默认生成一个pipeline类,你可以直接使用这个类来处理爬取的数据,你还可以新建别的pipeline类来使用不同方法来处理爬取的数据。
ITEM_PIPELINES = { # "carwl_meritalk.pipelines.CarwlMeritalkPipeline": 300, 'carwl_meritalk.pipelines.MysqlPipeline':301 }AUTOTHROTTLE_ENABLED
AUTOTHROTTLE_ENABLED是Scrapy的一个设置,用于控制是否启用AutoThrottle扩展。AutoThrottle扩展可以自动调整Scrapy的爬取速度,以防止对目标网站造成过大的负载。 如果AUTOTHROTTLE_ENABLED设置为True,那么AutoThrottle扩展将被启用,Scrapy会根据网站的响应速度和负载情况自动调整爬取速度。如果设置为False,那么AutoThrottle扩展将被禁用,Scrapy的爬取速度将由其他设置(如DOWNLOAD_DELAY和CONCURRENT_REQUESTS)控制。 请注意,启用AutoThrottle扩展可能会使爬取速度降低,但是可以降低被目标网站封禁的风险。例如:
AUTOTHROTTLE_ENABLED = True 这些设置参数中大部分都有默认值,当您需要对Scrapy爬虫的一些特定行为进行定制化时,可以通过修改settings.py文件中的相应参数来实现。
LOG_LEVEL
LOG_LEVEL是Scrapy设置中的一个参数,用于设置日志的级别。这个级别决定了将记录哪些级别的日志信息。Scrapy使用Python的内置logging模块来记录日志,所以LOG_LEVEL可以设置为任何有效的Python日志级别。 以下是一些可用的日志级别:
CRITICAL - 用于非常严重的错误,这意味着程序可能无法继续运行。
ERROR - 由于严重的问题,程序已无法执行某些功能。
WARNING - 表示有一些意外发生,或者在不久的将来可能会发生问题(例如‘磁盘空间低’)。程序仍然按预期运行。
INFO - 确认程序按预期运行。
DEBUG - 详细信息,通常只在诊断问题时有用。
用scrapy进行爬虫时最好是将LOG_LEVEL设置为INFO级别,因为你可以清楚的看到爬取的过程,以及在爬取过程中可能遇到的一些问题,便于你对程序进行调试。例如:
LOG_LEVEL = 'INFO'使用scrapy时反反爬虫常用的一些方法
网络爬虫,是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。但是当网络爬虫被滥用后,互联网上就出现太多同质的东西,原创得不到保护。于是,很多网站开始反网络爬虫,想方设法保护自己的内容。
他们根据ip访问频率,浏览网页速度,账户登录,输入验证码,flash封装,ajax混淆,js加密,图片,css混淆等五花八门的技术,来对反网络爬虫。
防的一方不惜工本,迫使抓的一方在考虑成本效益后放弃,抓的一方不惜工本,防的一方在考虑用户流失后放弃. 【百度百科】
在我们使用爬虫爬取一些网站的数据时经常会收到目标网站的反爬虫困扰导致我们不能获取到我们想要的数据,下面我将介绍一些我在遇到反爬虫时会使用到的方法,主要就是修改settings文件的一些配置参数。
1.将ROBOTSTXT_OBEY的值设为False
上边有讲述到ROBOTSTXT_OBEY是Scrapy设置中的一个参数,用于控制Scrapy是否应遵守robots.txt规则。robots.txt是一个网站的根目录下的文本文件,用于告诉爬虫哪些页面可以爬取,哪些页面不可以爬取。如果我们遵守该规则,呢么目标网站不想让我们爬取到的页面我们就爬取不到了。
2.添加请求头
在我们使用scrapy爬取网站数据时,我们可以通过添加请求头帮助服务器更好地理解和处理请求。请求头可以包含各种信息,例如请求的来源、请求者的身份、客户端的操作系统和浏览器类型、请求的内容类型等。
例如,User-Agent请求头可以告诉服务器发出请求的客户端的类型和版本信息,Accept请求头可以告诉服务器客户端可以处理哪些媒体类型,Cookie请求头可以携带客户端的会话信息等。 在Scrapy中,你可以在settings.py文件中设置DEFAULT_REQUEST_HEADERS来定义默认的请求头。例如:
DEFAULT_REQUEST_HEADERS = { "Cookie": "_gcl_au=1.1.1443158011.1708224635; _mkto_trk=id:028-JHU-645&token:_mch-meritalk.com-1708224635927-45039; viewed_cookie_policy=yes; cli_user_preference=en-cli-yes; CookieLawInfoConsent=eyJ2ZXIiOiIxIn0=; _gid=GA1.2.194144159.1708591215; _ga_3S3PX6WJC5=GS1.1.1708595410.6.0.1708595410.60.0.0; _ga=GA1.2.2052293861.1708224635; _gat=1; __gads=ID=ecfb94ecd7017e20:T=1708224611:RT=1708595409:S=ALNI_MZY-O__dfpoXV1cDB2hrHnBCD3CdQ; __gpi=UID=00000d094c21f7f9:T=1708224611:RT=1708595409:S=ALNI_Malcj-75Ij2aUydTgifADKs5Nte1A; __eoi=ID=ee0494578778fb94:T=1708224611:RT=1708595409:S=AA-AfjbOBzywJPvbT1DOqhUdb_vw", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6", }3.增加两个连续请求之间的延迟时间
上面讲述到DOWNLOAD_DELAY是Scrapy设置中的一个参数,用于定义两个连续请求之间的延迟时间,单位是秒。这个设置可以帮助你控制Scrapy的爬取速度,以防止对目标网站造成过大的负载。 例如,如果你将DOWNLOAD_DELAY设置为3甚至更长,那么Scrapy在发送一个请求后,会等待3秒才发送下一个请求。这样可以降低爬取速度,减少对目标网站的压力,也可以降低被目标网站封禁的风险。
DOWNLOAD_DELAY = 34.使用代理IP
想要突破网站的反爬虫机制,需要使用代理IP,通过换IP的方法进行多次访问。采用多线程采集时,也需要大量的IP,优先使用高匿名代理,否则目标网站检测到你的真实IP,也会影响到工作的进行。你可以在setting.py文件中加入以下代码:
HTTP_PROXY = '代理地址:代理端口号' # HTTP代理 HTTPS_PROXY = '代理地址:代理端口号' # HTTPS代理解决爬虫过程中网页url重定向的问题
我遇到的重定向问题可能和网上说的301,302重定向问题还不太一样,因为我试了网上的很多办法都没有解决问题,我的是这种,这个网站我用浏览器打开都显示这个问题,更别说爬虫了。
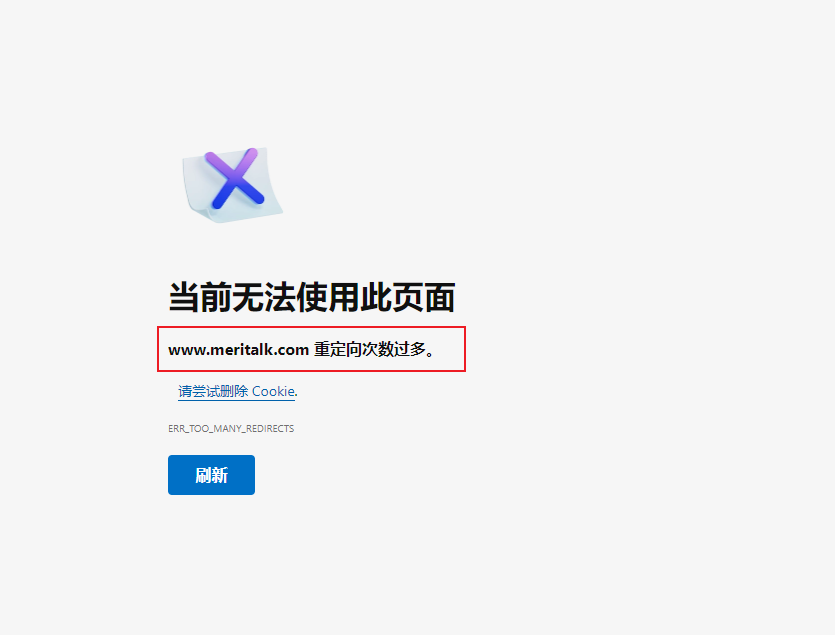
网上的解决办法都是:
在使用scrapy爬取网站数据的时候遇到了301,302重定向问题,可以在Request中添加meta参数。
yield scrapy.Request(url, callback=self.parse, meta={'dont_redirect': True, 'handle_httpstatus_list': [301,302]})
我试了一下不管用,还是爬不到数据,你们可以试一下,因为可能我们遇到的关于重定向的问题不一样。然后我按照在网上找的解决办法一个一个试,最后终于解决了,解决办法如下:
在settings.py文件里面加入如下代码:
COOKIES_ENABLED = False HTTPERROR_ALLOWED_CODES = [301, 302, 307, 308]COOKIES_ENABLED = False这行代码是用来设置Scrapy是否启用cookies。如果设置为True,Scrapy将会在发出的HTTP请求中包含cookies,这对于需要登录或者需要保持会话状态的网站是必要的。如果设置为False,Scrapy将不会在请求中包含cookies。 HTTPERROR_ALLOWED_CODES = [301, 302, 307, 308]这行代码是用来设置Scrapy应该允许哪些HTTP错误状态码。默认情况下,Scrapy在收到非200的HTTP响应时,会抛出一个异常。但是有些情况下,你可能希望Scrapy能够处理某些特定的HTTP错误状态码。例如,301、302、307和308都是重定向相关的状态码,如果你希望Scrapy能够自动处理重定向,你可以将这些状态码添加到HTTPERROR_ALLOWED_CODES列表中。
如果还不可以的话就换不同的代理尝试。
