阅读量:0
1.小故事
有一家零售连锁店,他们以其精准的市场定位和个性化的顾客服务而闻名,随着市场竞争的加剧和顾客需求的多样化,他们的管理层开始意识到,只有更加深入地了解他们的顾客群体,以便更好地满足他们的需求。
他们定使用人工智能算法帮助他们解决这个问题,他们聘请了一支由数据专家组成的团队,负责开发和实施这个项目。数据专家首先收集了大量的顾客数据,包括购物历史、偏好、地理位置、年龄和性别等。接下来,数据科专家使用了K-means聚类算法处理这些数据,并得到了几个不同的顾客群体。每个群体都具有独特的购物行为和偏好。例如,一个群体主要由年轻女性组成,她们喜欢购买时尚服饰和化妆品;另一个群体则主要由中年男性组成,他们更关注电子产品和家居用品。
有了这些聚类结果,这家零售连锁店的管理层开始重新审视他们的业务策略。他们针对每个顾客群体制定了个性化的营销策略,包括推出定制化的促销活动、优化商品陈列和提供个性化的购物建议。这些策略的实施取得了显著的效果,销售额和顾客满意度都得到了显著提升。此外,他们还利用聚类算法来改进他们的库存管理。他们根据每个顾客群体的购物习惯和偏好,预测了未来一段时间内的商品需求,并据此调整了库存水平。这不仅降低了库存积压和过期损失的风险,还确保了每个门店都能够满足其所在区域内顾客的需求。
通过深入分析顾客数据并利用聚类算法来发现顾客群体之间的相似之处和差异,这家零售连锁店成功地提高了其业务效率和顾客满意度,这证明了聚类算法在现代商业中的重要性。
2.聚类算法
定义:聚类算法是一种无监督学习方法,用于将数据集中的样本划分为若干个不相交的子集,每个子集被称为一个“类”。
无监督学习方法是一种机器学习算法,其特点是在没有标签或已知结果的数据集上进行训练和学习。这种学习方法允许机器从数据本身提取结构和规律,而无需依赖外部的监督或指导,
用于从未标记的数据集中进行分析,发现数据中的隐藏结构关系。
聚类算法是基于数据样本之间的相似性或距离进行的,使得同一簇内的数据样本尽可能相似,而不同簇之间的数据样本尽可能不同。聚类算法不需要预先标注的类别或标签,而是根据数据本身的特性进行自动分类。
聚类算法简单的说就像人一样将世间的万物进行分类,下图是人类对各种“猴子”的分类。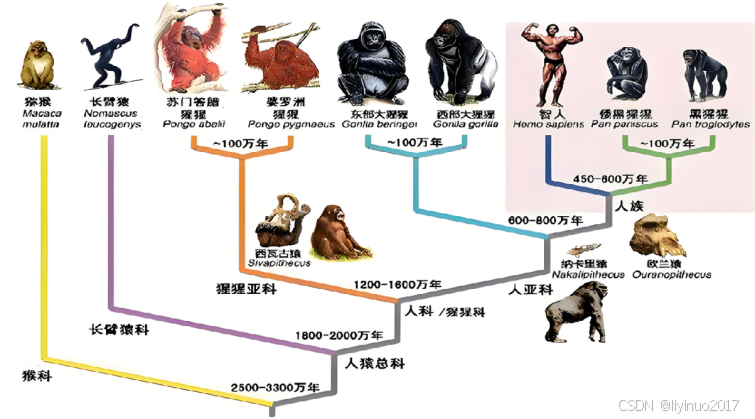
聚类算法的应用
客户分析:在市场营销和电子商务中,聚类算法可以帮助企业识别不同类型的客户,并制定相应的营销策略。
社交网络分析:通过分析社交网络中的用户数据,聚类算法可以帮助识别不同的社交群体或社区。
生物信息学:在基因表达数据分析和蛋白质功能预测中,聚类算法可以帮助识别具有相似功能的基因或蛋白质。
总的来说,聚类算法在机器学习领域扮演着重要的角色,其应用领域涵盖了众多行业和领域。
3.聚类算法分类
聚类算法不需要事先知道数据集的标签信息,它通过数据本身的特征来发现数据中的结构或模式。下面介绍几种常见的聚类算法(由于我们是从零入门,因此只需要了解以下算法既可):
K-均值聚类(K-means Clustering)
K-均值聚类通过选择K个点作为初始的聚类中心,然后将数据集中的每个点分配到最近的聚类中心,形成K个簇。之后,重新计算每个簇的聚类中心(通常是簇内所有点的均值),并重复上述过程,直到聚类中心不再发生变化或达到预设的迭代次数。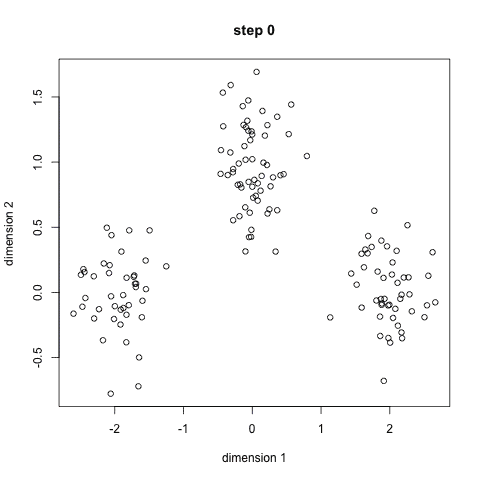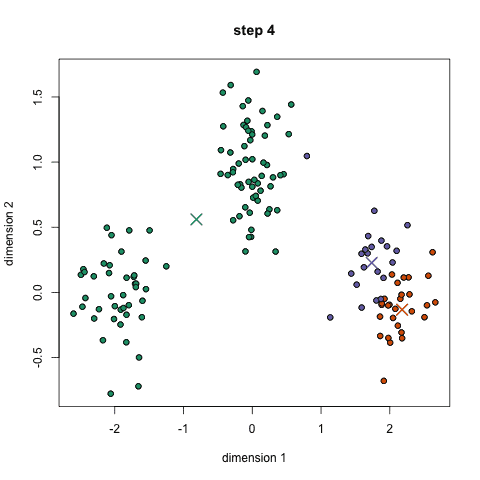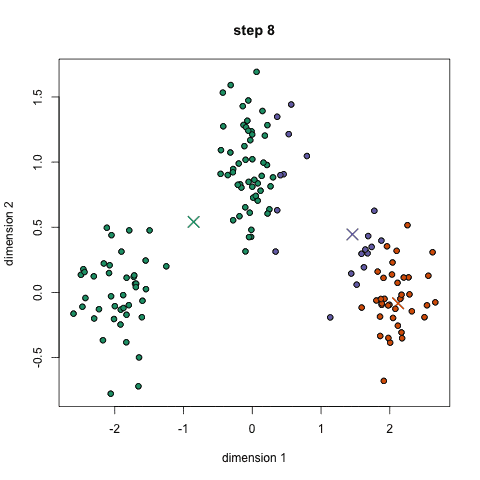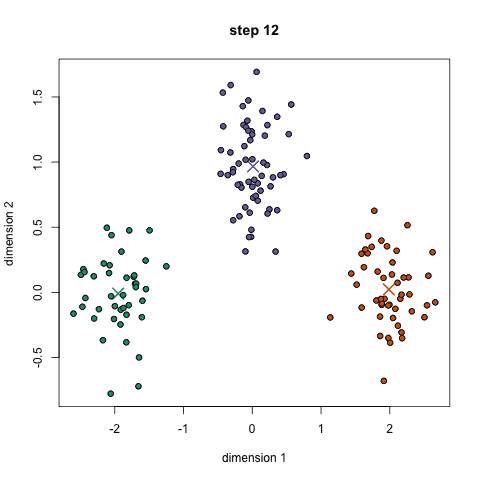
均值漂移聚类算法(Mean Shift)
均值漂移聚类算法通过计算滑动窗口中的均值来更新中心点的候选框,以此达到找到每个簇中心点的目的。然后在剩下的处理阶段中,对这些候选窗口进行滤波以消除近似或重复的窗口,找到最终的中心点及其对应的簇。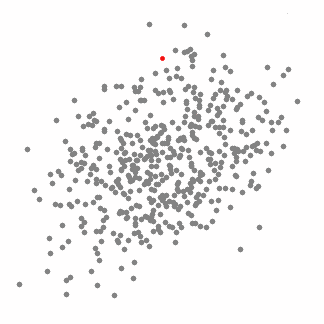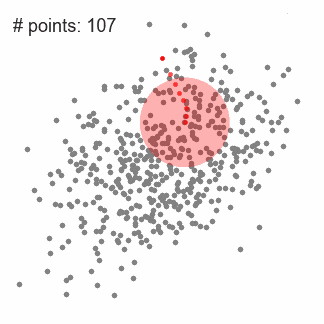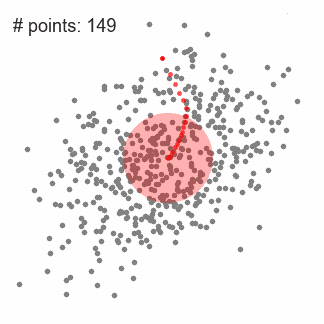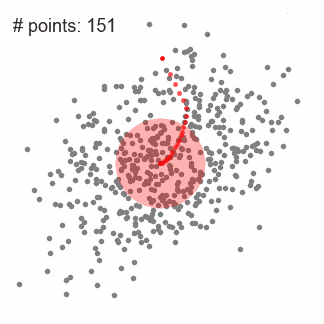
DBSCAN聚类算法
DBSCAN聚类算法(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,能够发现任意形状的簇,并识别噪声点。算法通过选择样本点,检查其ε邻域内的点数是否不少于minPts,来判定该点是否为核心点,进而形成簇。
层次聚类算法
层次聚类是一种基于树状结构的聚类方法,分为自下而上(凝聚)和自上而下(分裂)两种。凝聚层次聚类从每个数据点开始为一个簇,不断合并最相似的簇;分裂层次聚类开始时将所有数据点视为一个簇,不断拆分最不相似的簇。
高斯混合模型(GMM)
高斯混合模型是一种基于概率模型的聚类方法,假设数据由多个高斯分布组成,通过期望最大化(EM)算法估计参数。模型初始化每个高斯分布的参数,然后迭代计算每个样本属于每个高斯分布的概率,并根据这些概率更新高斯分布的参数。
4.聚类和分类的误区
前几个章节我们实战了逻辑回归和决策树这两个算法,逻辑回归和决策树都是分类算法,聚类也是将不同的数据进行分类,这不是一回事吗?
误区:聚类算法可以实现数据分类,因此聚类算法和分类算法是一样的。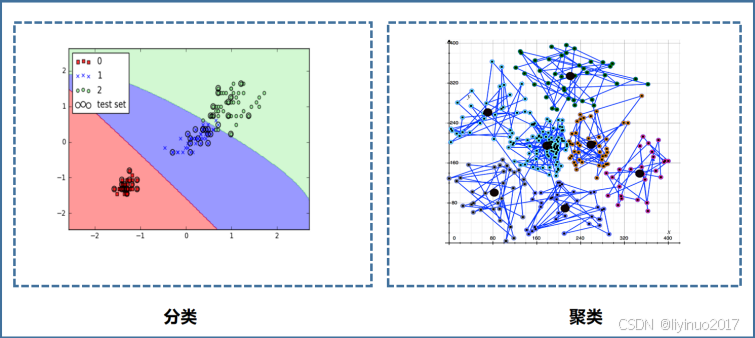
聚类和分类是数据挖掘和机器学习领域中两个重要概念,它们之间存在显著的差异。聚类是一种无监督学习方法,它不需要事先定义好的类别标签。而分类则是有监督学习,需要使用带有标签的数据集进行训练。
误区在于认为聚类可以像分类那样直接“预测”或“分配”新的数据点到已定义的类别中。实际上,聚类是在未标记数据中(没有已知结果或标签),根据数据点之间的相似性或距离来分组数据,形成自然的类别,而不是将数据点分配给预先定义的类别。
比如:在远古时代,人类就使用聚类算法将不同的物种进行分类,他们会把温和的食草动物归类为“安全动物”,会把长了4条腿的大型食肉猫科动物划分为“危险动物”。同时他们会把这个不同类型动物的特征告诉给他们的后代,后代会根据这些特征标签来对看到的动物进行分类,判断该动物是否存在危险。
从上面这个例子可知聚类算法其实就是一种抽象方法,聚类算法其可以根据事物之间的特征和关系,对未知实物进行分类定义。而分类算法是根据已有的定义和规则对事务进行分类。
分类是人!聚类是神!
5.工具包
本实战依赖了5个工具库:scikit-learn、pandas、matplotlib、numpy 、seaborn。
6.程序流程
本次实战代码的流程包括三个重要步骤:数据预处理、模型构建与训练、模型验证。
数据预处理阶段:完成数据的加载、转换、归一化等步骤。
模型构建与训练阶段:完成模型建立,并通过训练数据来训练模型。
模型验证阶段:评估模型的准确性,可视化结果。
7.入门程序
入门代码自动生成数据进行聚类处理。
import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import make_blobs # 生成样本数据 make_blobs用于生成模拟的聚类数据集 centers为聚类中心的数量 X, y = make_blobs(n_samples=100, centers=5, cluster_std=0.60, random_state=0) # 应用KMeans聚类模型 kmeans = KMeans(n_clusters=5) #训练数据 kmeans.fit(X) #使用模型进行预测,y_kmeans 是一个预测结果,它是一个数组,其中的每个元素对应 X 中的一个样本,表示该样本被分配到的聚类中心的索引 y_kmeans = kmeans.predict(X) #显示聚类结果 print(y_kmeans) # centers 是一个数组,其中的每个元素代表一个聚类中心的坐标 centers = kmeans.cluster_centers_ print(centers) #显示了5个聚类中心点 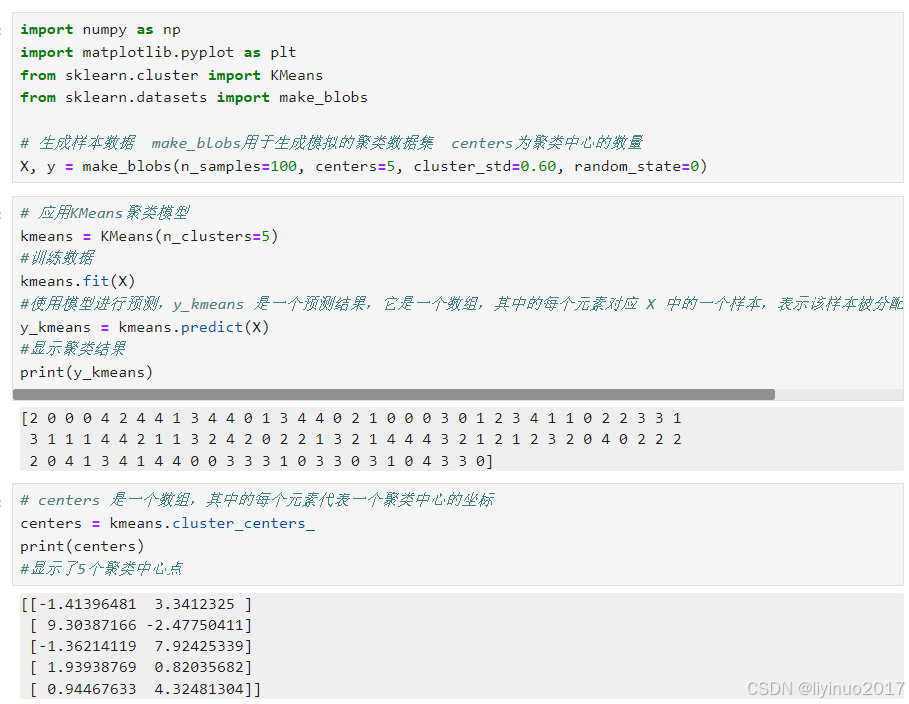
# 可视化结果 #绘制X0 X1组成的散点图,散点图中的每个点的颜色由y_kmeans 数组中的值指定, cmap='viridis' 指定了一个颜色映射表 plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis') #使用聚类中心的坐标显示聚类中心点 plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75) plt.title("KMeans Clustering") plt.xlabel("Feature 1") plt.ylabel("Feature 2") plt.show() 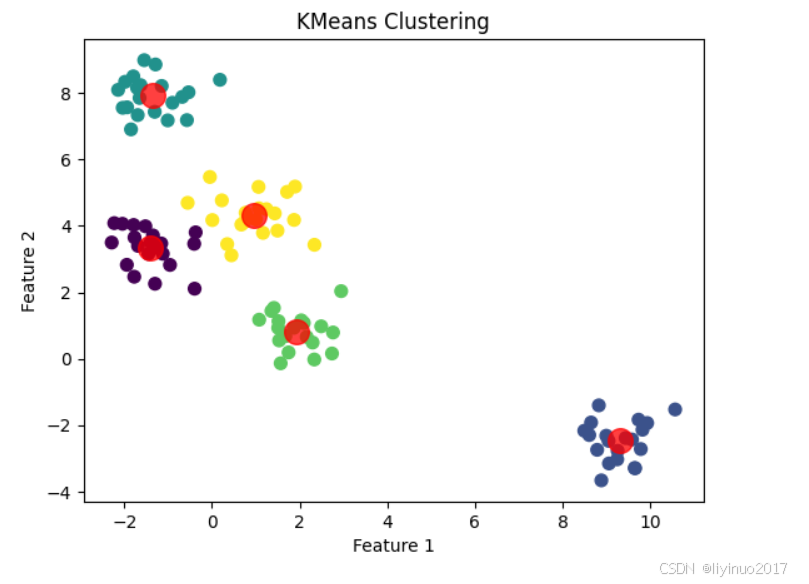
8.进阶实战
进阶实战代码读取Mall_Customers数据,该数据为一个商城用户数据,使用聚类算法对用户进行分类。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns data = pd.read_csv('Mall_Customers.csv') print(data.shape) data.head() #性别 年龄 收入 得分 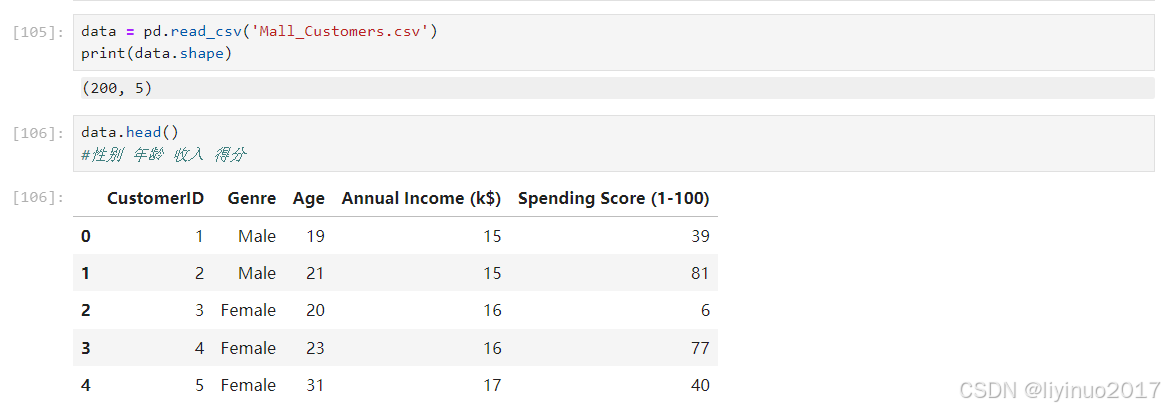
#用户ID对计算无用,去掉改行 data = data.drop('CustomerID',axis = 1 ) data.head() data.info() 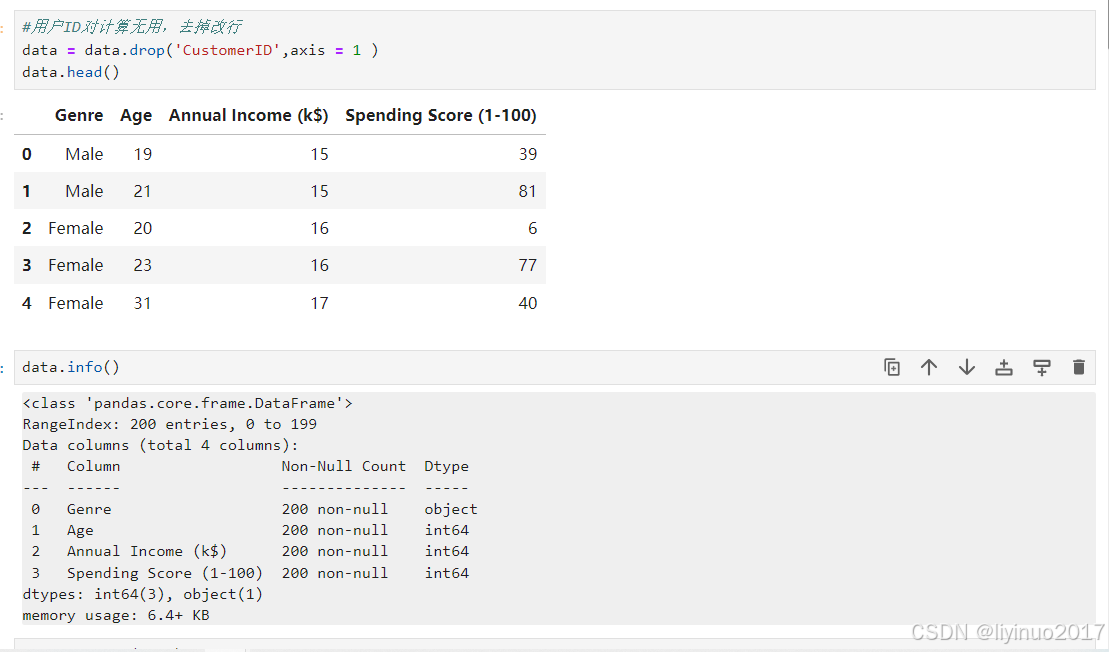
sns.pairplot(data) 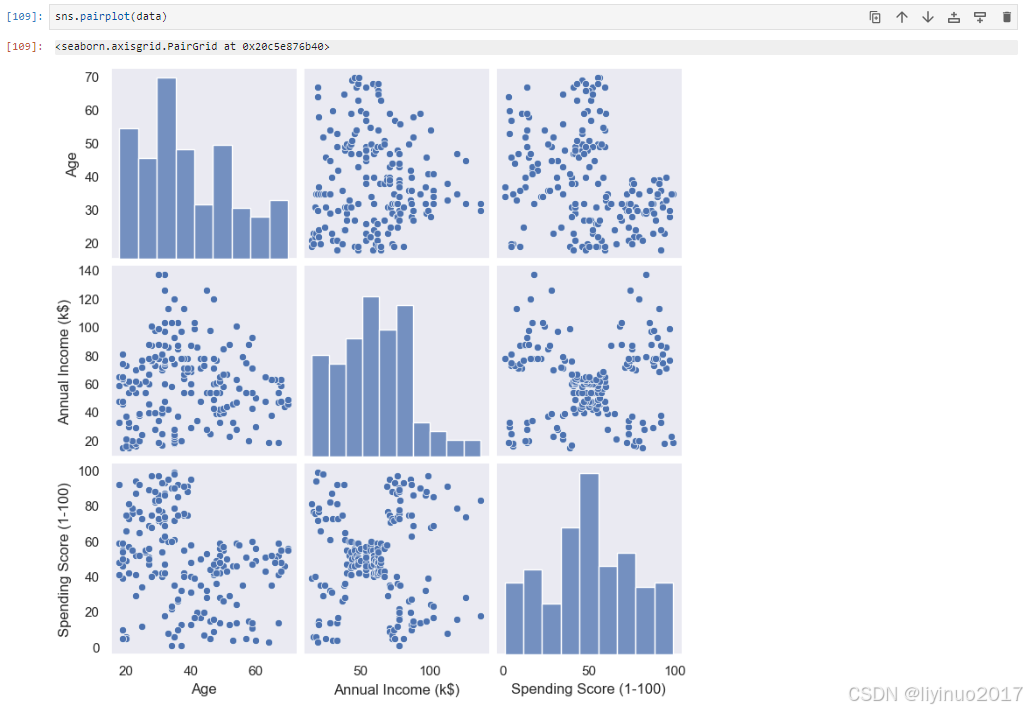
fig, axis = plt.subplots(figsize=(5, 5)) #Genre Male 转换成 1 , Female 转换成 0 data['Genre'] = data['Genre'].map({'Male': 1, 'Female': 0}) #corr() 函数计算的是皮尔逊相关系数它衡量的是两个变量之间的线性相关程度。相关系数的值范围从-1到1,其中: #1 表示完全正相关,即当一个变量增加时,另一个变量也增加。 #-1 表示完全负相关,即当一个变量增加时,另一个变量减少。 #0 表示没有线性相关。 corr = data.corr() #显示数据中的变量之间的相关程度热力图 sns.heatmap(corr, annot=True, cmap='magma', fmt=".2f", linewidths=.5) 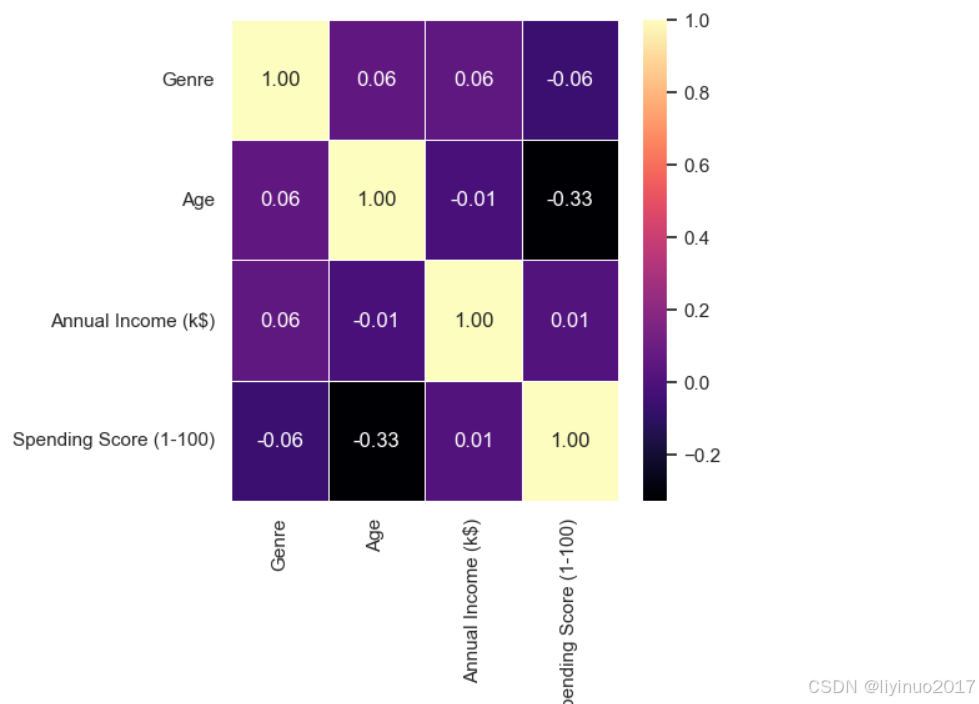
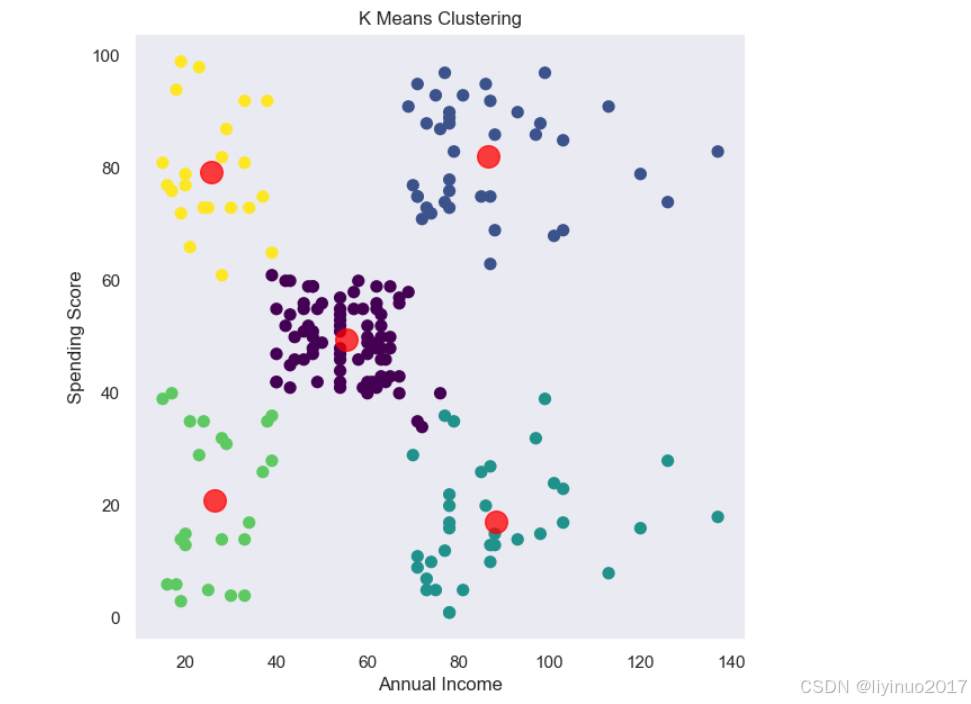
x = data.iloc[:, [2, 3]].values from sklearn.cluster import KMeans #改变聚类数K,然后进行聚类,计算损失函数,拐点处即为推荐的聚类数 (即通过此点后,聚类数的增大也不会对损失函数的下降带来很大的影响,所以会选择拐点) wcss = [] for i in range(1, 11): km = KMeans(n_clusters = i, init = 'k-means++', max_iter = 300, n_init = 10, random_state = 0) km.fit(x) wcss.append(km.inertia_) plt.plot(range(1, 11), wcss) plt.title('The Elbow Method') plt.xlabel('No. of Clusters') plt.ylabel('wcss') plt.show() #拐点处为5,因此聚类数设置为5 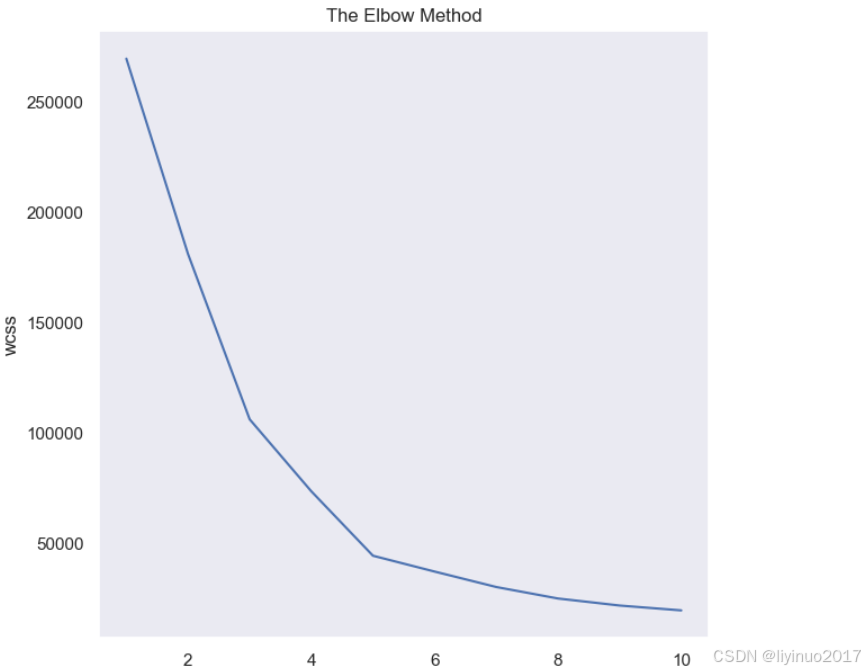
#建立聚类模型 ,聚类数设置为5 km = KMeans(n_clusters = 5, init = 'k-means++', max_iter = 300, n_init = 10, random_state = 0) y_means = km.fit_predict(x) #可视化数据 plt.scatter(x[:, 0], x[:, 1], c=y_means, s=50, cmap='viridis') plt.scatter(km.cluster_centers_[:,0], km.cluster_centers_[:,1], c='red', s=200, alpha=0.75) plt.title('K Means Clustering') plt.xlabel('Annual Income') plt.ylabel('Spending Score') plt.show()