
阅读量:0
个人主页:东洛的克莱斯韦克-CSDN博客
祝福语:愿你拥抱自由的风
相关文章

目录
进程控制概述
一个进程创建了另一个进程,创建者为父进程,被创建者为子进程。
父进程可以创建多个子进程。
操作系统是一号进程,所有进程构成一颗多叉树结构。

每个父进程只对直系的子进程负责。
父进程创建子进程的一整套流程为:创建子进程——>子进程完成任务——>父进程回收子进程
创建子进程
fork函数
fork之后的父进程和子进程谁先被执行是由调度器决定 代码示例功能: 创建一个子进程
头文件: #include <unistd.h> 函数原型: pid_t fork(void); 返回值: 子进程返回0,父进程返回子进程id,出错返回-1
int main( void ) { pid_t pid; printf("Before: pid is %d\n", getpid()); if ( (pid=fork()) == -1 )perror("fork()"),exit(1); printf("After:pid is %d, fork return %d\n", getpid(), pid); sleep(1); return 0; }父子进程执行流
父进程和子进程共享代码,可以用判断语句让父进程和子进程执行不同代码块实现分流。
int main() { pid_t t = fork(); if (-1 == t) { //创建进程失败 } else if (0 == t) { //子进程代码块 } else { //父进程代码块 } return 0; }上述代码中如果在父子进程分别写一个死循环就会有个神奇的现象——在一个main函数中能同时运行两个死循环。
系统层面理解
这在语言层面是无法理解的。在系统层面,是由两个进程运行了该代码。
fork()也是一个函数,在fork函数内部实现在创建一个进程的方法,在执行fork的main函数的return的时候就已经有了两个进程,子进程的fork返回 0 ,父进程的fork 返回子进程的pid(进程唯一标识符)。
出了fork函数,父进程和子进程分别执行自己的代码块,也就有了上述一个在main函数中运行了两个死循环的现象。
在fork函数中,linux内核做了如下工作
Linux内核为子进程创建内核资源,包括task_struct(管理进程),mm_struct(管理进程地址空间),页表等,并为该子进程分配唯一标识符PID。子进程的内核资源继承于父进程。
Linux内核复制父进程的上下文,包括堆栈指针、程序计数器(PC)以及通用寄存器的状态。
Linux内核为子进程分配独立的进程地址空间
处理返回值,子进程返回 0 ,父进程返回 子进程的PID。
原理刨析
原理剖析设计进程地址空间,可参考【Linux】进程地址空间-CSDN博客
子进程的页表也是继承于父进程,这意味着子进程的地址空间在物理内存的映射是重叠的。当子进程要对父进程的数据进行写入时,会发生写时拷贝。
通过写时拷贝实现代码共享,数据隔离。
上述策略可以有效节省物理内存

常见用法
一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数(进程程序替换)出错原因
系统中进程太多
用户进程的数量超过了限制
进程退出
概述
父进程先退,子进程未退。此时子进程的父亲进程被改为1号进程(操作系统),那么该子进程被称为孤儿进程
父进程未退,子进程先退。但父进程没有读取到子进程的退出(进程等待),该子进程的状态被改为 Z 状态,Z 状态的进程被成为僵尸进程。
操作系统杀不掉僵尸进程,所以僵尸进程会造成内存泄漏
如下是维持30秒僵尸进程的代码示例
#include <stdio.h> #include <stdlib.h> int main() { pid_t id = fork(); if(id < 0){ perror("fork"); return 1; } else if(id > 0){ //parent printf("parent[%d] is sleeping...\n", getpid()); sleep(30); }else{ printf("child[%d] is begin Z...\n", getpid()); sleep(5); exit(EXIT_SUCCESS); } return 0; }场景分析
进程异常退出
异常退出的本质是因为进程出发了硬件级别的错误,操作系统给进程发送信号终止进程。
被信号杀掉的进程由于自身任务没有完成就挂掉了,所以是异常退出。
每一种信号都有自己的编号,可用下述命令查看
kill -l
用户可以输入如下指令,向进程发送信号来终止进程
kill -9 进程PID
Ctrl c
进程正常退出,结果不正确
进程退出码:进程正常结束后给外部返回一个值,来代表自己任务完成情况。
如下指令可以查看最近一次进程的退出码
echo $?? 中储存的是最近一次进程的退出码的值
退出码的值可以自己定,退出码的含义可以根据代码的需求给定
可用如下程序显示linux的退出码的含义
#include<stdio.h> #include<unistd.h> #include<errno.h> #include<string.h> int main() { int i = 0; for(i;i<134;i++) { printf("%d:,%s\n",i,strerror(i)); } return 0; }进程正常退出,结果正确
一般情况下无需关心
返回退出状态的函数
return是一种常见的退出进程方法。执行return n等同于执行exit(n),因为调用main的运行时函数会将main的返回值当做 exit的参数但如果该函数不是main函数,就需要exit函数结束进程,并返回退出状态#include <unistd.h> void _exit(int status); 参数:status 定义了进程的终止状态,父进程通过wait来获取该值
#include <unistd.h> void exit(int status); 参数:status 定义了进程的终止状态,父进程通过wait来获取该值
exit和_exit
exit 最后也会调用 _exit , 但在调用 _exit 之前,还做了其他工作: 1. 执行用户通过 atexit或on_exit定义的清理函数。 2. 关闭所有打开的流,所有的缓存数据均被写入 3. 调用_exit 如下示意图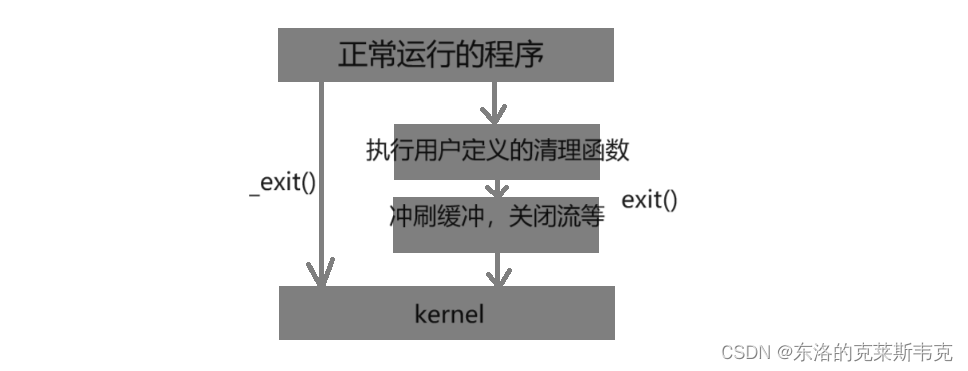
代码示例
int main() { printf("hello"); exit(0); }运行结果
[root@localhost linux]# ./a.out hello[root@localhost linux]#int main() { printf("hello"); _exit(0); }运行结果
[root@localhost linux]# ./a.out [root@localhost linux]#进程等待
概述
父进程只对直系的子进程负责,父进程创建子进程的目的是为了让子进程为自己完成一些事情。所以在子进程变成 X 状态(死亡状态)之前,有一个 Z 状态即僵尸状态。
僵尸状态是为了能让父进程读取子进程的退出信息。
退出信息:进程是否触发硬件级别的错误而被信号所杀(异常结束),进程如果没有异常结束退出码是否符合预期(结果运行的结果是否正确)
进程等待有如下场景
1.父进程等待子进程,但子进程并未退出,此时父进程可以阻塞等待,非阻塞等待,非阻塞轮询等待。
2.子进程变成僵尸进程,父进程等待子进程并读取子进程退出信息,子进程被设为 X 状态。
子进程的退出信息只能被父进程拿到——父进程只对直系子进程负责。
进程等待和 Z 状态本质是为了应对父子进程退出的各种场景,让父进程拿到子进程的退出信息
进程等待方法
wait
头文件: #include<sys/types.h> 头文件: #include<sys/wait.h> 函数原型: pid_t wait(int*status)功能:等待子进程返回值: 成功返回被等待进程pid,失败返回-1参数: 输出型参数,获取子进程退出状态,不关心则可以设置成为NULLwait函数的特性是:如果子进程为僵尸状态,直接获取子进程的退出信息,如果子进程并未退出,父进程的状态被改为 S 状态(睡眠状态,阻塞状态)——父进程一直等待子进程 参数:我们可以定义一个int类型的变量,wait用指针接收,wait去子进程中拿到退出信息就可以通过 status传递给父进程 代码示例
#include<stdio.h> #include<unistd.h> #include<sys/types.h> #include <unistd.h> #include<stdlib.h> #include <sys/wait.h> int main() { pid_t i = fork(); if (-1 == i)//创建子进程失败 { printf("创建子进程失败\n"); return 2; } else if (0 == i)//子进程 { int cat = 2; while (cat) { //eep(1); printf("我是一个子进程 %d 我的父亲是 %d\n", getpid(), getppid()); cat--; } exit(21); //return 12; } else//父进程 { int status = 0; pid_t t = wait(&status); sleep(1); printf("我是一个父进程%d,子进程退出状态为%d,子进程的退出码是%d\n", getpid(), WIFEXITED(status),WEXITSTATUS(status)); //printf("我是一个父进程%d,子进程退出状态为%p\n", getpid(),status); return 99; } }waitpid
pid_ t waitpid(pid_t pid, int *status, int options);函数原型
返回值当正常返回的时候waitpid返回收集到的子进程的进程ID; 如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0; 如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
参数pid: Pid=-1,等待任一个子进程。与wait等效。 Pid>0.等待其进程ID与pid相等的子进程。 status: 输出型参数,获取子进程退出状态,不关心则可以设置成为NULLoptions: WNOHANG: 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该子进程的ID。 如果为0:进入阻塞等待,与wait等价 如下是不同场景的代码示例
父进程只等待一次,子进程变成孤儿进程
#include<stdio.h> #include<unistd.h> #include<sys/types.h> #include <unistd.h> #include<stdlib.h> #include <sys/wait.h> int main() { pid_t i = fork(); if (-1 == i)//创建子进程失败 { printf("创建子进程失败\n"); return 2; } else if (0 == i)//子进程 { int cat = 2; while (1) { sleep(1); printf("我是一个子进程 %d 我的父亲是 %d\n", getpid(), getppid()); cat--; } exit(21); //return 12; } else//父进程 { int status = 0; pid_t t = waitpid(-1, &status, WNOHANG); sleep(1); printf("我是一个父进程%d,子进程退出状态为%d,子进程的退出码是%d\n", getpid(), WIFEXITED(status),WEXITSTATUS(status)); //printf("我是一个父进程%d,子进程退出状态为%p\n", getpid(),status); return 99; } }非阻塞轮询等待
父进程死循环等待,options的参数是WNOHANG,这种等待称为非阻塞轮询等待,等待期间父进程可以做自己的事情
#include<stdio.h> #include<unistd.h> #include<sys/types.h> #include <unistd.h> #include<stdlib.h> #include <sys/wait.h> int main() { pid_t i = fork(); if (-1 == i)//创建子进程失败 { printf("创建子进程失败\n"); return 2; } else if (0 == i)//子进程 { int cat = 2; while (1) { sleep(1); printf("我是一个子进程 %d 我的父亲是 %d\n", getpid(), getppid()); cat--; } exit(21); //return 12; } else//父进程 { int status = 0; while(1) { pid_t t = waitpid(-1, &status, WNOHANG); sleep(1); //printf("我是一个父进程%d,子进程退出状态为%d,子进程的退出码是%d\n", getpid(), WIFEXITED(status),WEXITSTATUS(status)); if (-1 == t)//等待失败 { return -1; } else if (0 == t) { sleep(1); printf("子进程还没完事\n"); } else{//等待成功 break; } //printf("我是一个父进程%d,子进程退出状态为%p\n", getpid(),status); } return 99; } }wait和waitpid是系统提供的接口,获取子进程的退出信息是由操作系统做的。为什么父进程不能直接获取,而要让操作系统介入呢? 子进程退出后,其相关数据被释放掉,退出信息被保存在内核数据结构中,一个进程在上层代表的是用户,如果一个进程可以直接拿到子进程的退出信息,那么说明该进程可以直接访问内核数据结构,换句话说用户可以通过代码访问内核数据结构,那么操作系统的安全性怎么得到保证呢?为什么要用上述两个函数来完成父进程对子进程退出信息的获取呢
父进程和子进程都代码共享了,不能在代码层面拿到退出信息吗进程是系统层面的概念,如果不用系统提供的接口,子进程的退出信息是不会反馈给父进程的代码上的。
详谈status
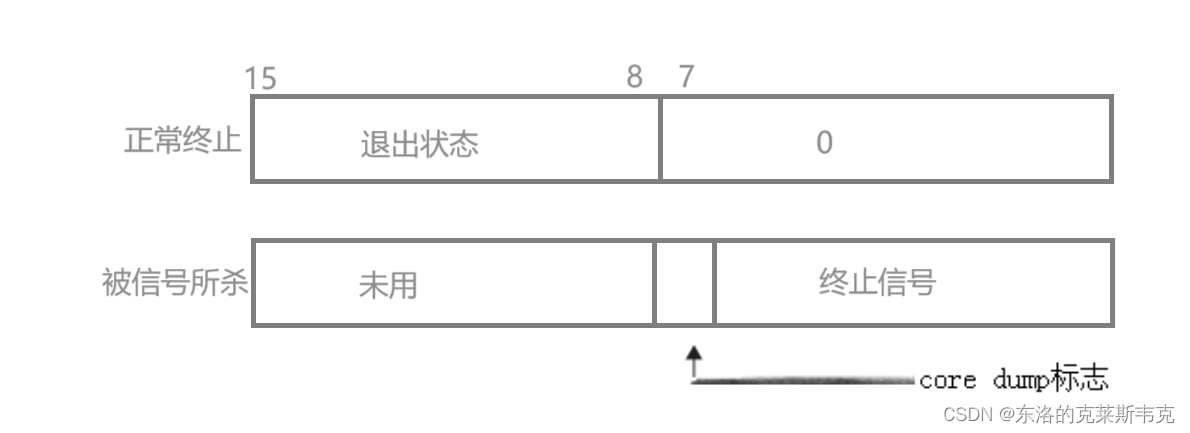
wait和waitpid,都有一个status参数,该参数是一个输出型参数,由操作系统填充。 如果传递NULL,表示不关心子进程的退出状态信息。 否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程。 status不能简单的当作整形来看待,可以当作位图来看待,具体细节如下图(只研究status低16比特位)比特位 0~6 对应了接受到的信号,注意这里还通过 127 0x7f 定义了 STOP 状态
比特位 7 用来标示是否有生成 core 文件
比特位 8~15 通过 exit() 接口退出进程,也就是意味着错误码最大为 255 ,如果是 256 那么实际上是 0 ;
头文件中提供了宏,无需进行位运算
WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出) WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)