
阅读量:0
为了简化理解,需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小32*32的黑白图像,并转换成文本格式
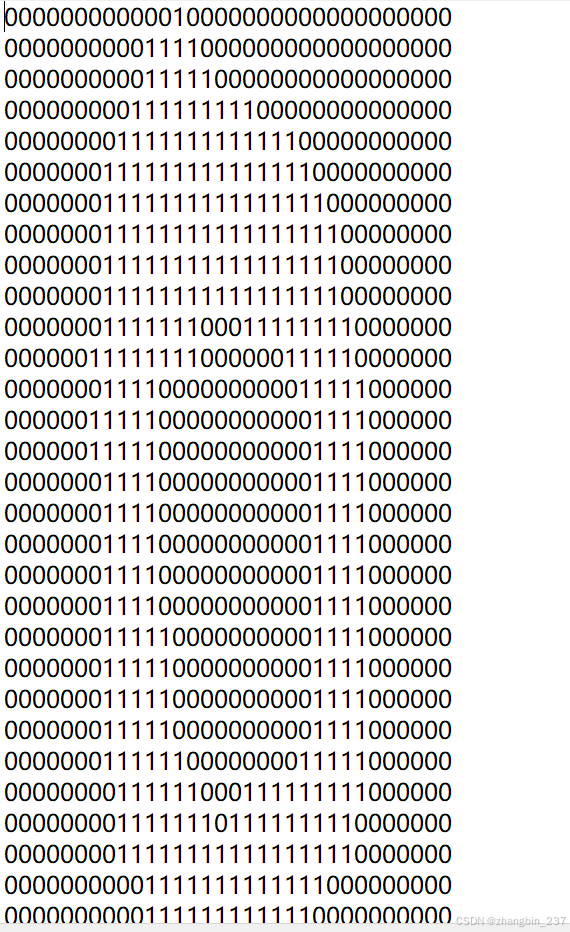
准备数据:将图像转换为测试向量
实际图像存储在trainingDigits的2000个例子和testDigits中的900个测试数据
我们使用trainingDigits目录中的数据训练分类器,使用testDigits目录中的数据测试分类器的效果。
为了使用分类器,我们必须将图像格式化处理为一个向量。我们将32*32的二进制图像矩阵转换为1*1024的向量。首先,要创建一个函数,将图像转换为向量:该函数创建一个1*1024的NumPy数组,然后打开给定的文件,循环读出文件的前32行,并将每行的头32个字符值存储在NumPy数组中,最后返回数组:
def img2vector(filename): returnVect=zeros((1,1024)) fr=open(filename) for i in range(32): lineStr=fr.readlines() for j in range(32): returnVect[0,32*i+j]=int(lineStr[j]) return returnVect测试算法:使用k-近邻算法识别手写数字
将数据输入到分类器,检测分类器的执行效果:
def handwritingClassTest(): hwLabels=[] trainingFileList=listdir('trainingDigits') m=len(trainingFileList) trainingMat=zeros((m,1024)) for i in range(m): fileNameStr=trainingFileList[i] fileStr=fileNameStr.split('.')[0] classNumStr=int(fileStr.split('_')[0]) hwLabels.append(classNumStr) trainingMat[i,:]=img2vector('trainingDigits/%s'%fileNameStr) testFileList=listdir('testDigits') errorCount=0.0 mTest=len(testFileList) for i in range(mTest): fileNameStr=testFileList[i] fileStr=fileNameStr.split('.')[0] classNumStr=int(fileStr.split('_')[0]) vectorUnderTest=img2vector('testDigits/%s'%fileNameStr) classifierResult=classify0(vectorUnderTest,trainingMat,hwLabels,3) print('识别为:%d,实际为:%d'%(classifierResult,classNumStr)) if(classifierResult!=classNumStr):errorCount=errorCount+1 print('错误数:',errorCount) print('错误率:',errorCount/float(mTest))在上述代码中,将trainingDigits目录中的文件存储在列表中,然后可以得到目录中有多少文件,并将其存储在变量m中。接着,代码创建一个m行1024列的训练矩阵,该矩阵的每行数据存储一个图像。
我们可以从文件名中解析出分类数字。该目录下的文件按照规则命名,然后我们可以将类代码存储在hwLabels向量中,使用前面的img2vector函数载入图像。
下一步中,我们对testDigits目录中的文件执行类似的操作,使用classify0()函数测试目录下的每个文件。

可以看到,错误率只有1%左右。通过改变变量k的值,修改函数的训练、测试样本的数目,都会对错误率产生影响。
实际使用这个算法时,算法的执行效率并不高,因为算法需要为每个测试向量做2000次距离计算,每个距离计算包括了1024个维度浮点运算,总共要执行900次。
