
阅读量:0
MySQL基础(二)

一、表的关联关系
在关系型数据库中,表之间可以通过关联关系进行连接和查询。关联关系是指两个或多个表之间的关系,通过共享相同的列或键来建立连接。常见的关联关系有三种类型:一对多关系,多对多关系以及一对一关系。
我们以选课系统为案例带大家深入解析关系表。
1.1、一对多
(1)一对多的关系创建
- 在一对多关系中,一个表的记录可以与另一个表中的多个记录相关联,而另一个表的记录只能与一个表中的记录相关联(有且只有一个一对多)。
- 建立一对多的关系:在‘多’的表中创建关联字段
CREATE TABLE Students ( StudentID INT PRIMARY KEY AUTO_INCREMENT, StudentName VARCHAR(255) NOT NULL, gender ENUM ('男','女','保密'), Age INT, ClassName VARCHAR(255), HeadTeacher VARCHAR(255), StudentCount INT, AcademicYear VARCHAR(255) ); 插入模拟记录
INSERT INTO Students (StudentName, gender, Age, ClassName, HeadTeacher, StudentCount, AcademicYear) VALUES ('张三', '男', 18, '软件1班', '李老师', 30, '2022-2023'), ('李四', '女', 17, '软件1班', '李老师', 30, '2022-2023'), ('王五', '男', 16, '软件1班', '李老师', 30, '2022-2023'), ('赵六', '女', 18, '软件1班', '李老师', 30, '2022-2023'), ('刘七', '男', 17, '软件1班', '李老师', 30, '2022-2023'), ('陈八', '女', 16, '软件1班', '李老师', 30, '2022-2023'), ('杨九', '男', 18, '软件1班', '李老师', 30, '2022-2023'), ('周十', '女', 17, '软件1班', '李老师', 30, '2022-2023'), ('吴十一', '男', 16, '软件1班', '李老师', 30, '2022-2023'), ('郑十二', '女', 18, '软件1班', '李老师', 30, '2022-2023'), ('黄十三', '男', 17, '软件1班', '李老师', 30, '2022-2023'), ('许十四', '女', 16, '软件1班', '李老师', 30, '2022-2023'), ('曾十五', '男', 18, '软件1班', '李老师', 30, '2022-2023'), ('吕十六', '女', 17, '软件1班', '李老师', 30, '2022-2023'), ('冯十七', '男', 16, '软件1班', '李老师', 30, '2022-2023'), ('朱十八', '女', 18, '软件1班', '李老师', 30, '2022-2023'), ('江十九', '男', 17, '软件1班', '李老师', 30, '2022-2023'), ('何二十', '女', 16, '软件1班', '李老师', 30, '2022-2023'), ('魏二十一', '男', 18, '软件1班', '李老师', 30, '2022-2023'), ('孔二十二', '女', 17, '软件1班', '李老师', 30, '2022-2023'), ('曹二十三', '男', 16, '软件1班', '李老师', 30, '2022-2023'), ('秦二十四', '女', 18, '软件1班', '李老师', 30, '2022-2023'), ('许二十五', '男', 17, '软件1班', '李老师', 30, '2022-2023'), ('韩二十六', '女', 16, '软件1班', '李老师', 30, '2022-2023'), ('田二十七', '男', 18, '软件1班', '李老师', 30, '2022-2023'), ('范二十八', '女', 17, '软件1班', '李老师', 30, '2022-2023'); 在上述示例中,将班级相关的字段直接添加到学生表中会产生一些问题,比如可能会导致冗余数据。如果多个学生属于同一个班级,那么每个学生记录都会重复存储相同的班级信息。这样的冗余数据可能浪费存储空间并增加数据的不一致性和更新的复杂性。
为了解决这些问题,更好的做法是使用关联表来处理学生和班级之间的一对多关系。
-- 建立多对一的关系:在多的表中创建关联字段 CREATE TABLE Students ( StudentID INT PRIMARY KEY AUTO_INCREMENT, StudentName VARCHAR(255) NOT NULL, gender ENUM ('男','女','保密'), Age INT, ClassID INT ); CREATE TABLE Classes ( ID INT PRIMARY KEY, ClassName VARCHAR(50), HeadTeacher VARCHAR(50), StudentCount INT, AcademicYear VARCHAR(10) ); 插入模拟记录:
-- 插入班级记录 INSERT INTO Classes (ID, ClassName, HeadTeacher, StudentCount, AcademicYear) VALUES (1, '软件1班', '李老师', 30, '2022-2023'), (2, '软件2班', '王老师', 35, '2022-2023'), (3, '计算机1班', '张老师', 28, '2022-2023'), (4, '计算机2班', '刘老师', 32, '2022-2023'), (5, '电子1班', '陈老师', 31, '2022-2023'); -- 插入学生记录 INSERT INTO Students (StudentID, StudentName, gender, Age, ClassID) VALUES (1, '张三', '男', 18, 1), (2, '李思琪', '女', 17, 1), (3, '王伟', '男', 16, 1), (4, '赵雅芝', '女', 18, 1), (5, '刘德华', '男', 17, 1), (6, '陈小姐', '女', 16, 1), (7, '杨明', '男', 18, 1), (8, '周慧', '女', 17, 1), (9, '钱振华', '男', 16, 1), (10, '孙艺珍', '女', 18, 1), (11, '周润发', '男', 17, 1), (12, '吴莫愁', '女', 16, 1), (13, '郑源', '男', 18, 1), (14, '王菲', '女', 17, 1), (15, '李小龙', '男', 16, 2), (16, '张曼玉', '女', 18, 2), (17, '赵本山', '男', 17, 2), (18, '钱钟书', '女', 16, 3), (19, '孙红雷', '男', 18, 3), (20, '周杰伦', '女', 17, 3), (21, '吴京', '男', 16, 4), (22, '郑少秋', '女', 18, 4), (23, '王祖贤', '男', 17, 4), (24, '李连杰', '女', 16, 5), (25, '张学友', '男', 18, 5), (26, '赵薇', '女', 17, 5), (27, '钱飞', '男', 16, 5), (28, '孙俪', '女', 18, 5), (29, '李宇春', '男', 17, 2), (30, '王力宏', '女', 16, 3); (2)一对多的典型案例解析
部门和员工
-- 创建部门表 CREATE TABLE Departments ( ); -- 创建员工表 CREATE TABLE Employees ( );作者和博客
-- 创建作者表 CREATE TABLE Authors ( ); -- 创建博客表 CREATE TABLE Blogs ( );博客和评论
-- 创建博客表 CREATE TABLE Blogs ( ); -- 创建评论表 CREATE TABLE Comments ( );书籍和出版社
-- 创建出版社表 CREATE TABLE Publishers ( ); -- 创建书籍表 CREATE TABLE Books ( );用户和订单
-- 创建用户表 CREATE TABLE Users ( ); -- 创建订单表 CREATE TABLE Orders ( );供应商和产品
-- 创建供应商表 CREATE TABLE Suppliers ( ); -- 创建产品表 CREATE TABLE Products ( supplier_id int );
(3)一对多的子查询
子查询就是:将上一次的查询结果作为下一次的执行条件
-- 案例1: 查询李小龙的班级名称和班级人数以及班主任名字 -- 查询李小龙的班级ID SELECT ClassID FROM Students WHERE StudentName = '李小龙'; -- 使用李小龙的班级ID查询班级名称、班级人数和班主任名字 SELECT ClassName, StudentCount, HeadTeacher FROM Classes WHERE ID = (SELECT ClassID FROM Students WHERE StudentName = '李小龙'); -- 案例2:查询软件1班所有学生的姓名 SELECT StudentName FROM Students WHERE ClassID = (SELECT ID FROM Classes WHERE ClassName = '软件1班'); 子查询是 MySQL 中比较常用的查询方法,通过子查询可以实现多表关联查询。子查询指将一个查询语句嵌套在另一个查询语句中。
1.2、多对多
多对多,在数据库中也比较常见,可以理解为是一对多和多对一的组合。
- 学生和课程的多对多关系:
- 学生表(Students):存储学生的信息。
- 课程表(Courses):存储课程的信息。
- 选课表(Enrollment):作为中间表,存储学生和课程之间的关联关系。
- 作者和书籍的多对多关系:
- 作者表(Authors):存储作者的信息。
- 书籍表(Books):存储书籍的信息。
- 作者-书籍关系表(Author_Book):作为中间表,存储作者和书籍之间的关联关系。
- 用户和角色的多对多关系:
- 用户表(Users):存储用户的信息。
- 角色表(Roles):存储角色的信息。
- 用户-角色关系表(User_Role):作为中间表,存储用户和角色之间的关联关系。
- 商品和订单的多对多关系:
- 商品表(Products):存储商品的信息。
- 订单表(Orders):存储订单的信息。
- 订单-商品关系表(Order_Product):作为中间表,存储订单和商品之间的关联关系。
- 标签和文章的多对多关系:
- 标签表(Tags):存储标签的信息。
- 文章表(Articles):存储文章的信息。
- 文章-标签关系表(Article_Tag):作为中间表,存储文章和标签之间的关联关系。
当在学生表和课程表中直接使用course_id和student_id来表示多对多关系时,会导致数据冗余。这意味着课程信息将在课程表中重复存储,而每个学生选修的课程也将在学生表中重复存储。
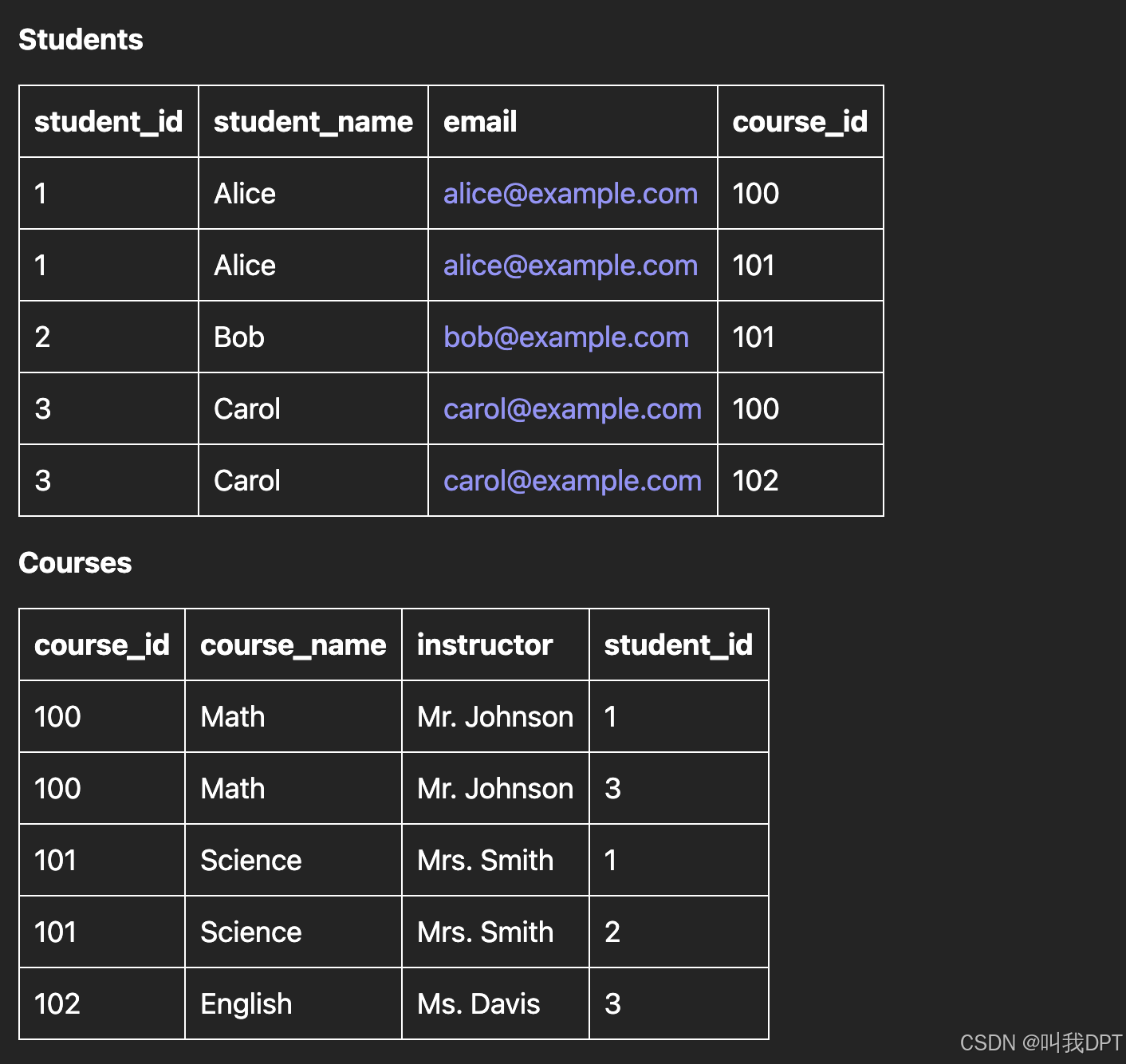
要实现多对多,一般都需要有一张中间表(也叫关联表),将两张表进行关联,形成多对多的形式。
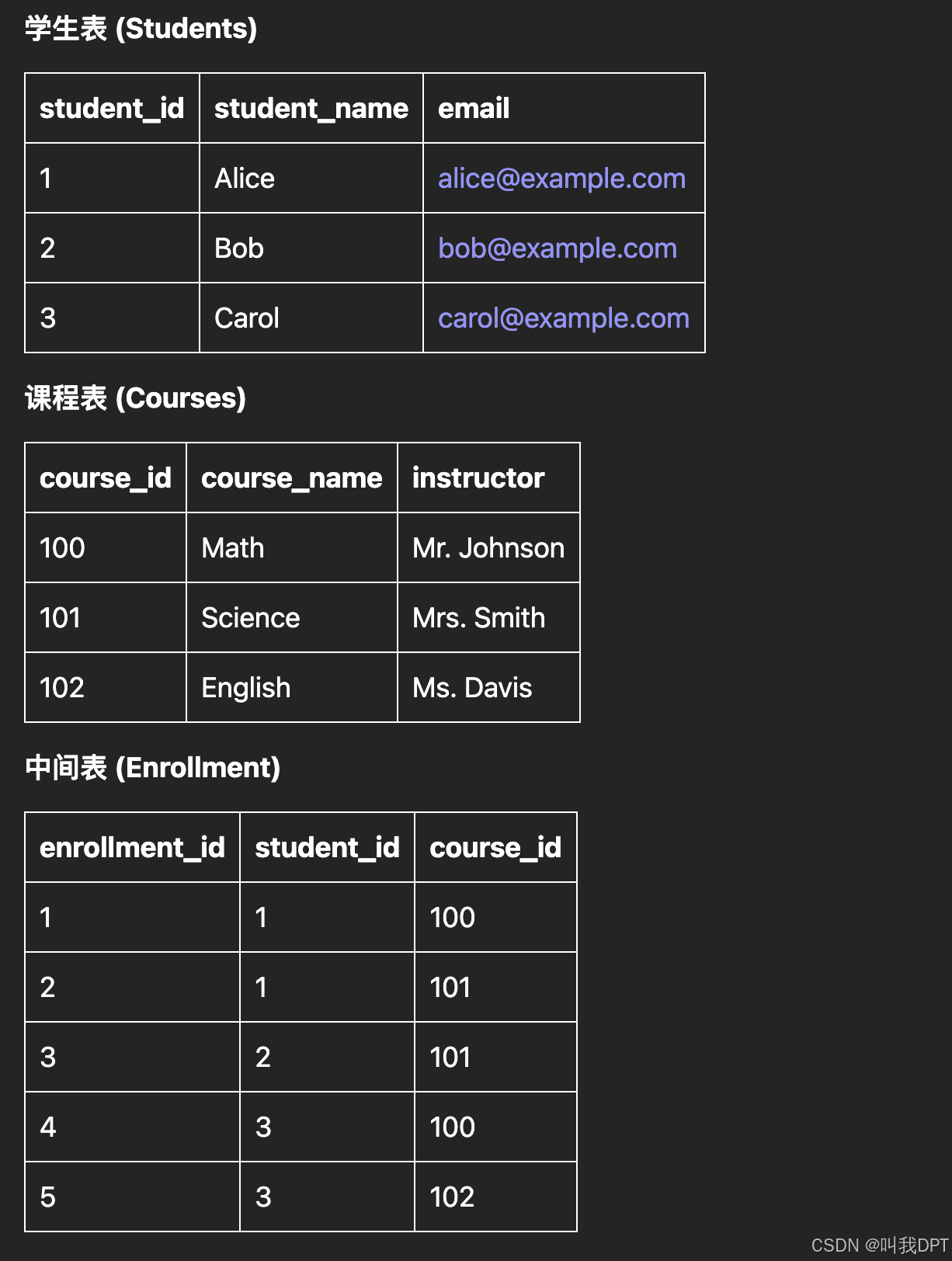
如果将学生和课程的关联关系直接存储在学生表和课程表中,那么数据将如下所示:
-- 建立多对一的关系:在多的表中创建关联字段 CREATE TABLE Students ( StudentID INT PRIMARY KEY AUTO_INCREMENT, StudentName VARCHAR(255) NOT NULL, gender ENUM ('男','女','保密'), Age INT, ClassID INT ); CREATE TABLE Courses ( CourseID INT PRIMARY KEY, CourseName VARCHAR(255), Instructor VARCHAR(255), Description VARCHAR(255), Credits INT, Classroom VARCHAR(255), Periods VARCHAR(255) ); -- 两张表各建一个关联字段数据冗余,管理低效 -- 更高效建立多对多关系的答案是第三张关系表 CREATE TABLE StudentCourses ( ID INT PRIMARY KEY AUTO_INCREMENT, StudentID INT, CourseID INT ); 添加课程记录:
-- 插入课程记录 INSERT INTO Courses (CourseID, CourseName, Instructor, Description, Credits, Classroom, Periods) VALUES (1, '高等数学', '王老师', '本课程介绍高等数学的基本概念与方法', 4, 'A101', '周一、周三 9:00-10:30'), (2, '线性代数', '李老师', '本课程介绍线性代数的基本理论与应用', 3, 'B202', '周二、周四 13:30-15:00'), (3, '计算机程序设计', '张老师', '本课程教授常用的计算机程序设计语言和方法', 3, 'C301', '周一、周三 13:30-15:00'), (4, '数据库系统', '刘老师', '本课程介绍数据库系统的原理与应用', 3, 'D402', '周二、周四 9:00-10:30'), (5, '操作系统', '陈老师', '本课程介绍操作系统的基本原理与设计', 3, 'E503', '周一、周三 10:30-12:00'), (6, '离散数学', '赵老师', '本课程介绍离散数学的基本概念与证明方法', 3, 'F604', '周二、周四 10:30-12:00'), (7, '数据结构与算法', '钱老师', '本课程介绍常用数据结构和算法的设计与分析', 3, 'G705', '周一、周三 15:00-16:30'), (8, '人工智能', '孙老师', '本课程介绍人工智能的基本原理与应用', 4, 'H806', '周二、周四 15:00-16:30'), (9, '网络技术', '周老师', '本课程介绍计算机网络的基本概念与技术', 3, 'I907', '周一、周三 16:30-18:00'), (10, '软件工程', '吴老师', '本课程介绍软件工程的基本原理与实践', 3, 'J1008', '周二、周四 16:30-18:00'); 建立多对多关系:
-- 学生John Doe选修了数学和英语课程 INSERT INTO StudentCourses (StudentID, CourseID) VALUES (1, 1); -- 学生ID为1,课程ID为1 INSERT INTO StudentCourses (StudentID, CourseID) VALUES (1, 2); -- 学生ID为1,课程ID为2 -- 学生Jane Smith选修了英语和历史课程 INSERT INTO StudentCourses (StudentID, CourseID) VALUES (2, 2); -- 学生ID为2,课程ID为2 INSERT INTO StudentCourses (StudentID, CourseID) VALUES (2, 4); -- 学生ID为2,课程ID为4 -- 学生Tom Johnson选修了数学和物理课程 INSERT INTO StudentCourses (StudentID, CourseID) VALUES (3, 1); -- 学生ID为3,课程ID为1 INSERT INTO StudentCourses (StudentID, CourseID) VALUES (3, 5); -- 学生ID为3,课程ID为5 多对多的子查询:
多对多的子查询也是通过嵌套查询实现的
-- 查询John Doe选修课程的名字和学分 SELECT StudentID FROM Students WHERE StudentName = '张三'; SELECT CourseID FROM StudentCourses WHERE StudentID = ( 1 ); SELECT CourseName, Credits FROM Courses WHERE CourseID IN ( 1,2 ); -- 查询选修英语的学名的姓名和email SELECT CourseID FROM Courses WHERE CourseName = '线性代数'; SELECT StudentID FROM StudentCourses WHERE CourseID = ( 2 ); SELECT StudentName, Age FROM Students WHERE StudentID IN ( 1,2 ); 1.3、一对一
一对一是将数据表“垂直切分”。
建立一对一的表关系,关联字段(必须唯一unique)这两个表都可以放。
但是最好将关联字段放在详情表中,因为并不是每个学生都有详情信息。如果放在主要信息表中,没有详情信息的字段还需要置空。
一对一关系(One-to-One Relationship)指的是两个实体之间存在一种对应关系,其中一个实体的每个记录只能对应另一个实体的一条记录,而另一个实体的每个记录也只能对应一个实体的记录。在一对一关系中,关联字段在每个表中都加上了唯一约束,以确保关联的唯一性。
一对一是将数据表“垂直切分”。也就是 A 表的一条记录对应 B 表的一条记录。
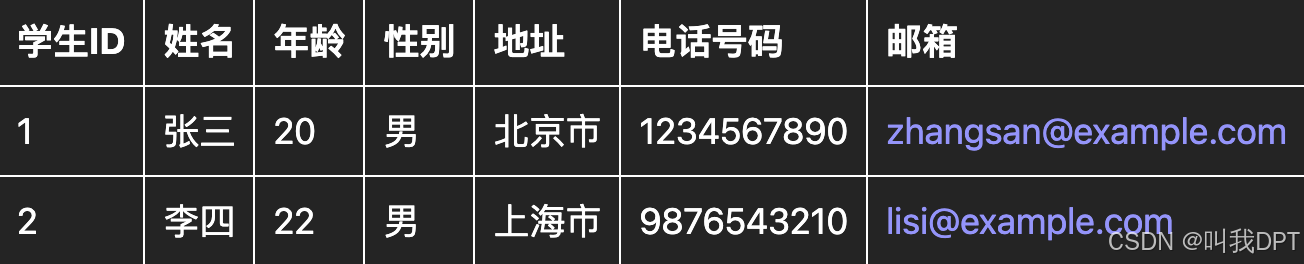
学生和学生详情的一对一关系:
- 学生(Students):存储用户的基本信息
- 学生详情表(StudentDetails):存储学生地址、联系方式等。每个学生只有一条详情记录。
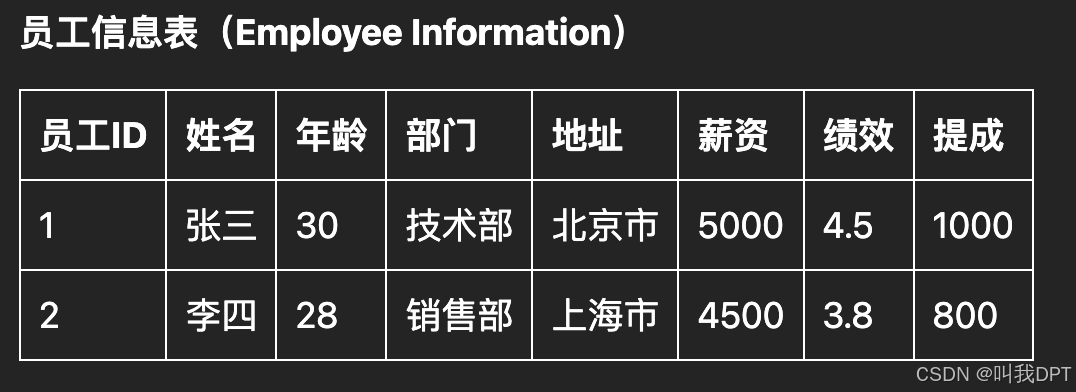
员工和薪资信息的一对一关系:
- 员工表(Employees):存储员工的基本信息,如员工号、姓名、职位等。
- 薪资信息表(Salary):存储员工的薪资信息,如基本工资、津贴等。每个员工在薪资信息表中只有一条记录,与员工表中的对应记录关联。
一对一创建表的优点:
将两个实体分开存储在不同的表中,可以更好地保持数据的规范性和完整性。每个表都可以有自己的约束和验证规则,确保数据的一致性和有效性。
使用一对一关系表,可以更容易地扩展和修改数据模型。
数据隐私和安全性
通过唯一约束的关联字段建立一对一。
/* CREATE TABLE Students ( StudentID INT PRIMARY KEY AUTO_INCREMENT, StudentName VARCHAR(255) NOT NULL, gender ENUM ('男','女','保密'), Age INT, ClassID INT );*/ -- 创建学生联系信息表 CREATE TABLE StudentDetails ( ID INT PRIMARY KEY, PhoneNumber VARCHAR(255), Email VARCHAR(255), Address VARCHAR(255), StudentID INT UNIQUE -- 区别于一对多,关联字段加唯一约束! ); 插入记录:
INSERT INTO StudentDetails (ID, PhoneNumber, Email, Address, StudentID) VALUES (1, '1234567890', '张三@example.com', '北京市朝阳区建国门外大街123号', 1), (2, '2345678901', '李思琪@example.com', '上海市黄浦区南京东路456号', 2), (3, '3456789012', '王伟@example.com', '广东省深圳市福田区华强北路789号', 3), (4, '4567890123', '赵雅芝@example.com', '四川省成都市武侯区锦江宾馆321号', 4), (5, '5678901234', '刘德华@example.com', '湖北省武汉市江汉区解放大道654号', 5); 一对一子查询:
-- 查询张三的手机号和邮箱 select Email, PhoneNumber from StudentDetails where StudentID = (select StudentID from Students where StudentName = '张三') -- 查询手机号为5678901234的学生姓名和年龄 SELECT StudentName, Age FROM Students WHERE StudentID = (SELECT StudentID FROM StudentDetails WHERE PhoneNumber = '5678901234') 二、JOIN关联查询
笛卡尔积查询会通过n*m的组合所查询的表。然后通过where过滤用来拼接表。但是where一般更喜欢去做逻辑上的过滤
SELECT * FROM Students,Classes where Students.classid=Classes.id;所以就有了join关联表查询:
通过inner join 凭借两表,通过on进行拼接表的逻辑过滤
SELECT * FROM Students INNER JOIN Classes ON Students.ClassID = Classes.ID;多对多的join是基于第三张表,然后把三张表拼接成一张大表,在进行过滤。
【1】笛卡尔积查询
笛卡尔积(Cartesian product)是指两个集合之间的所有可能的组合。在关系型数据库中,笛卡尔积是指两个表之间的所有可能的行组合。
如果有两个表A和B,每个表包含n和m行,那么它们的笛卡尔积将产生n * m行。每一行是表A中的一行与表B中的一行的组合。
SELECT * FROM Students,Classes; 【2】内连接
查询两张表中都有的关联数据,相当于利用条件从笛卡尔积结果中筛选出了正确的结果。
案例1(多对一拼接):
-- 查询两张表中都有的关联数据,相当于利用条件从笛卡尔积结果中筛选出了正确的结果。 SELECT * From Students, Classes where Students.ClassID = Classes.ID; -- OR SELECT * FROM Students INNER JOIN Classes ON Students.ClassID = Classes.ID; SELECT * FROM Classes c INNER JOIN Students s ON s.ClassID = c.ID; 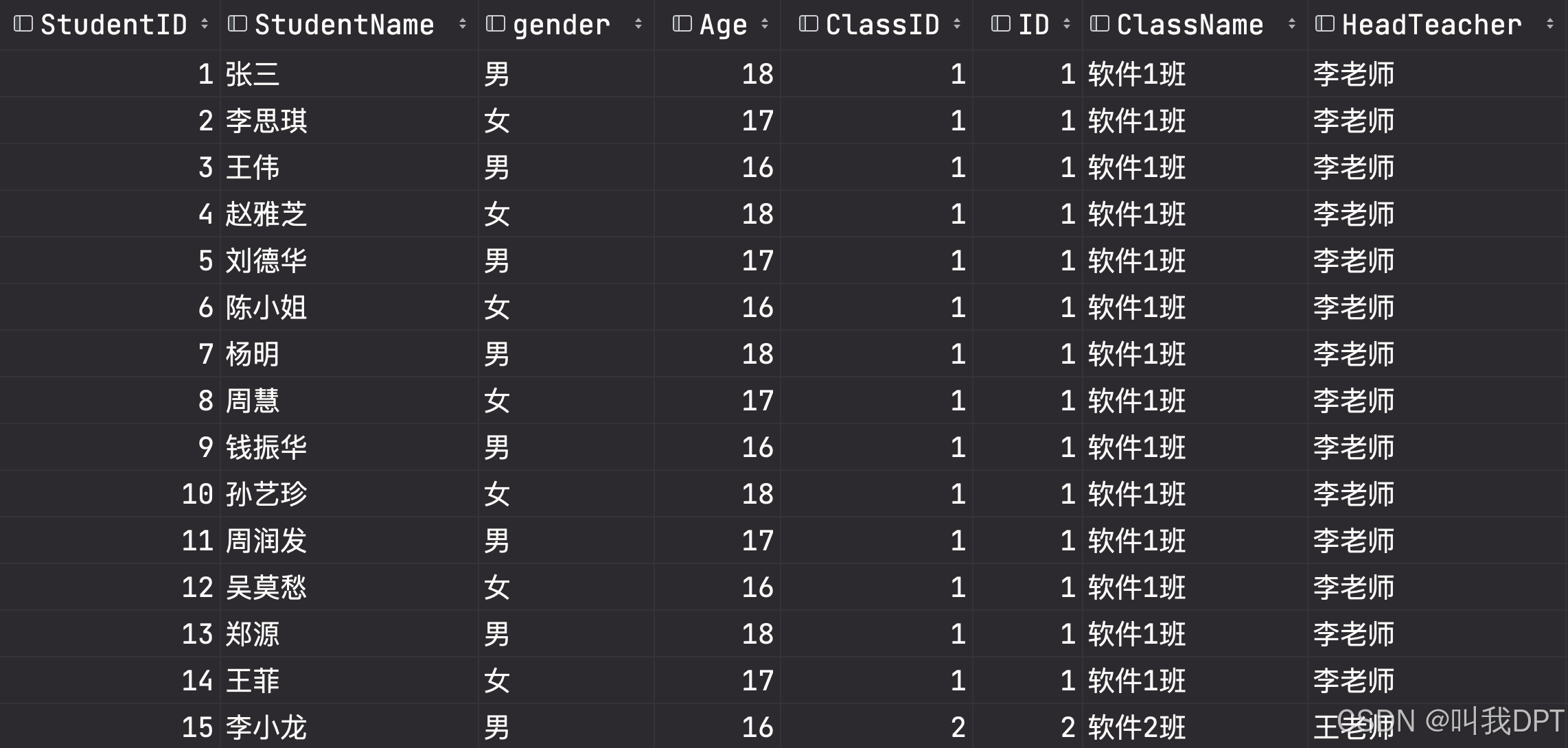
案例2(多对多拼接):
SELECT * FROM Students INNER JOIN StudentCourses ON Students.ClassID = StudentCourses.StudentID; 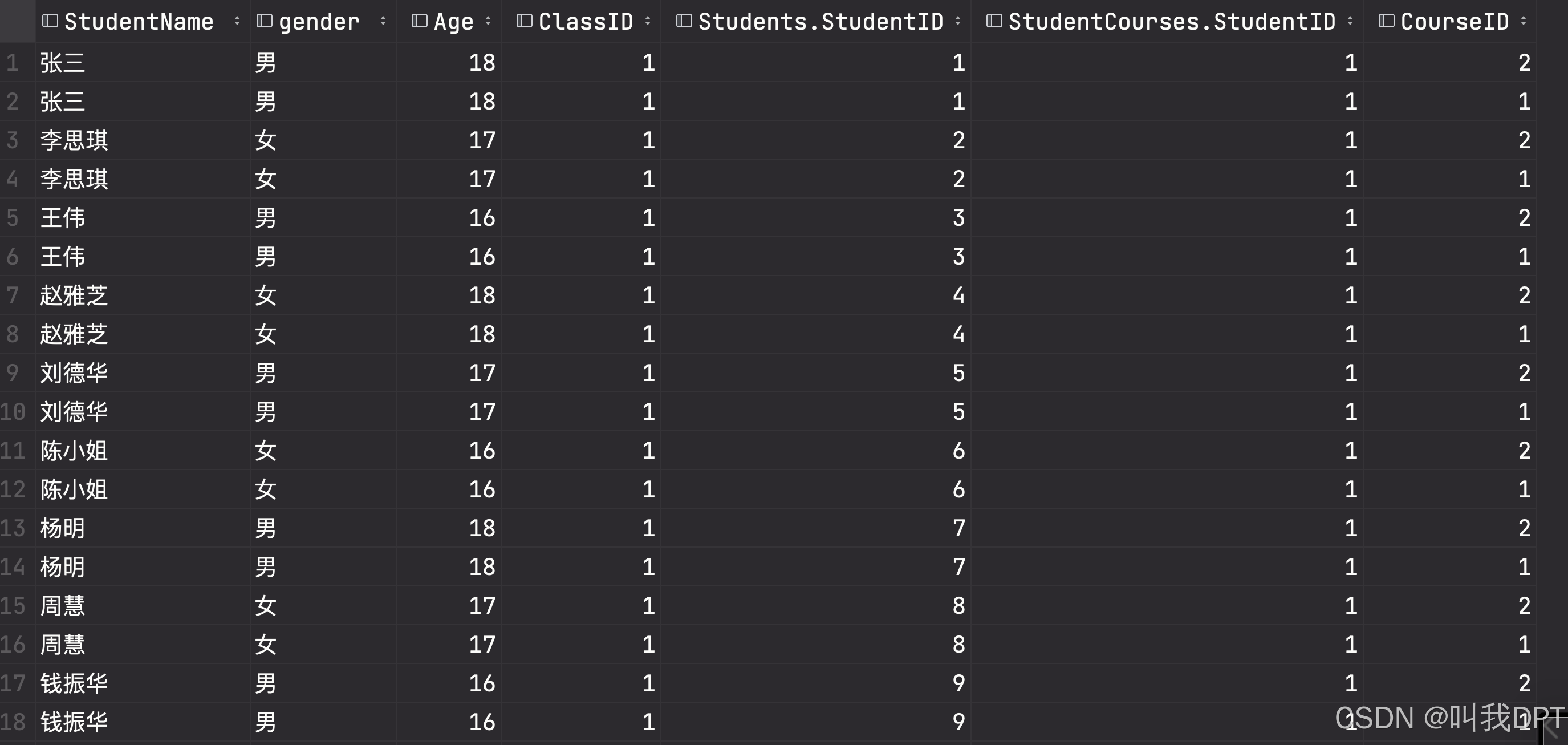
SELECT * FROM Students INNER JOIN StudentCourses ON Students.ClassID = StudentCourses.StudentID INNER JOIN Courses on StudentCourses.CourseID = Courses.CourseID; 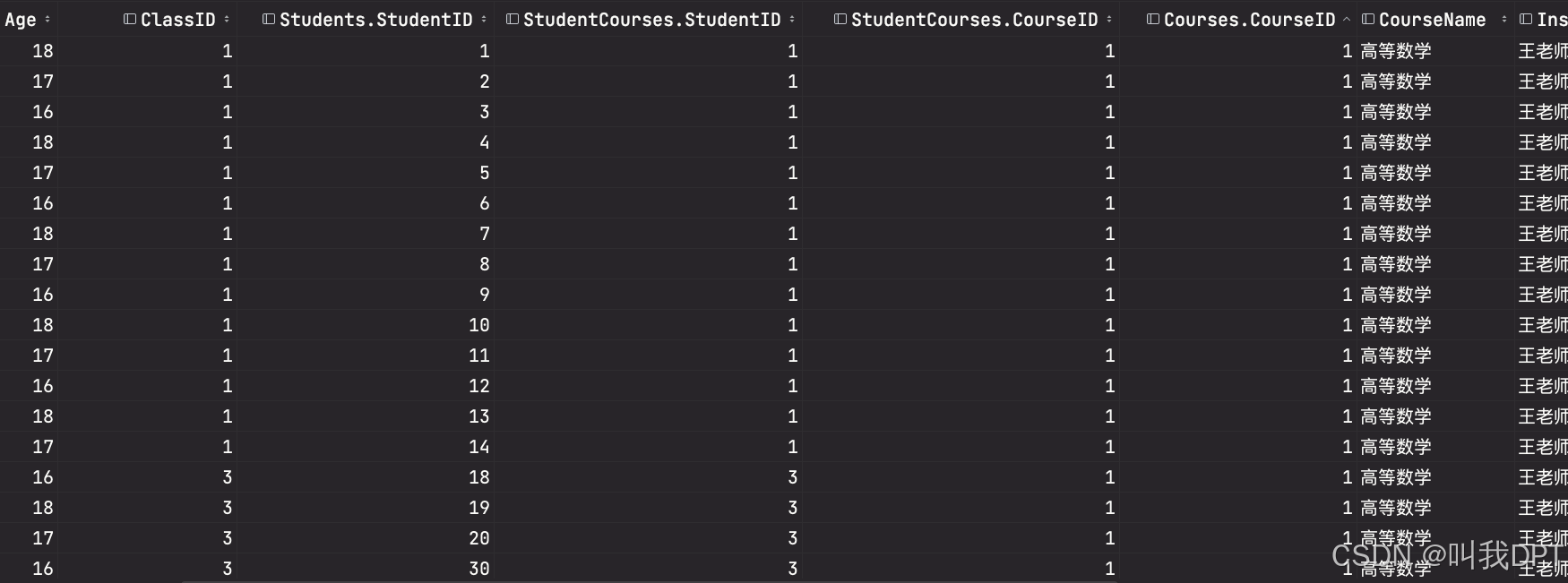
【3】左连接和右连接
这节课讲了一对多关系表下的左连接:
left join()表示以左边的表作为基表。
它与inner join的区别是:inner join会过滤掉所有不符合on语句的记录。
而left会起码保留基表的所有记录
左外连接又称为左连接,使用 LEFT OUTER JOIN 关键字连接两个表,并使用 ON 子句来设置连接条件。
SELECT * FROM 表1 LEFT JOIN 表2 ON 表1.连接字段 = 表2.连接字段; 上述语法中,“表1”为基表,“表2”为参考表。左连接查询时,可以查询出“表1”中的所有记录和“表2”中匹配连接条件的记录。如果“表1”的某行在“表2”中没有匹配行,那么在返回结果中,“表2”的字段值均为空值(NULL)。
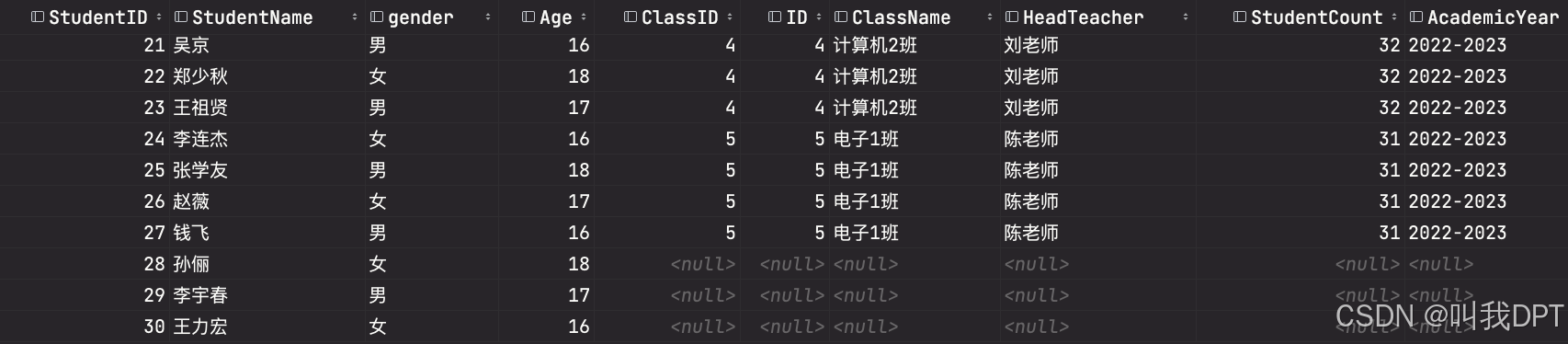
-- 将几个学生的ClassID设置为空 SELECT * FROM Students LEFT JOIN Classes ON Students.ClassID = Classes.ID; -- 将某个班级处理成没有学生 SELECT * FROM Students RIGHT JOIN Classes ON Students.ClassID = Classes.ID; SELECT * FROM Classes Left JOIN Students ON Students.ClassID = Classes.ID; select * from Students left join StudentCourses on StudentCourses.StudentID = Students.StudentID left join Courses on Courses.CourseID= StudentCourses.CourseID; select * from Courses left join StudentCourses on StudentCourses.CourseID = Courses.CourseID left join Students on Students.StudentID= StudentCourses.StudentID 右外连接又称为右连接,右连接是左连接的反向连接。使用 RIGHT OUTER JOIN 关键字连接两个表,并使用 ON 子句来设置连接条件。
与左连接相反,右连接以“表2”为基表,“表1”为参考表。右连接查询时,可以查询出“表2”中的所有记录和“表1”中匹配连接条件的记录。如果“表2”的某行在“表1”中没有匹配行,那么在返回结果中,“表1”的字段值均为空值(NULL)。
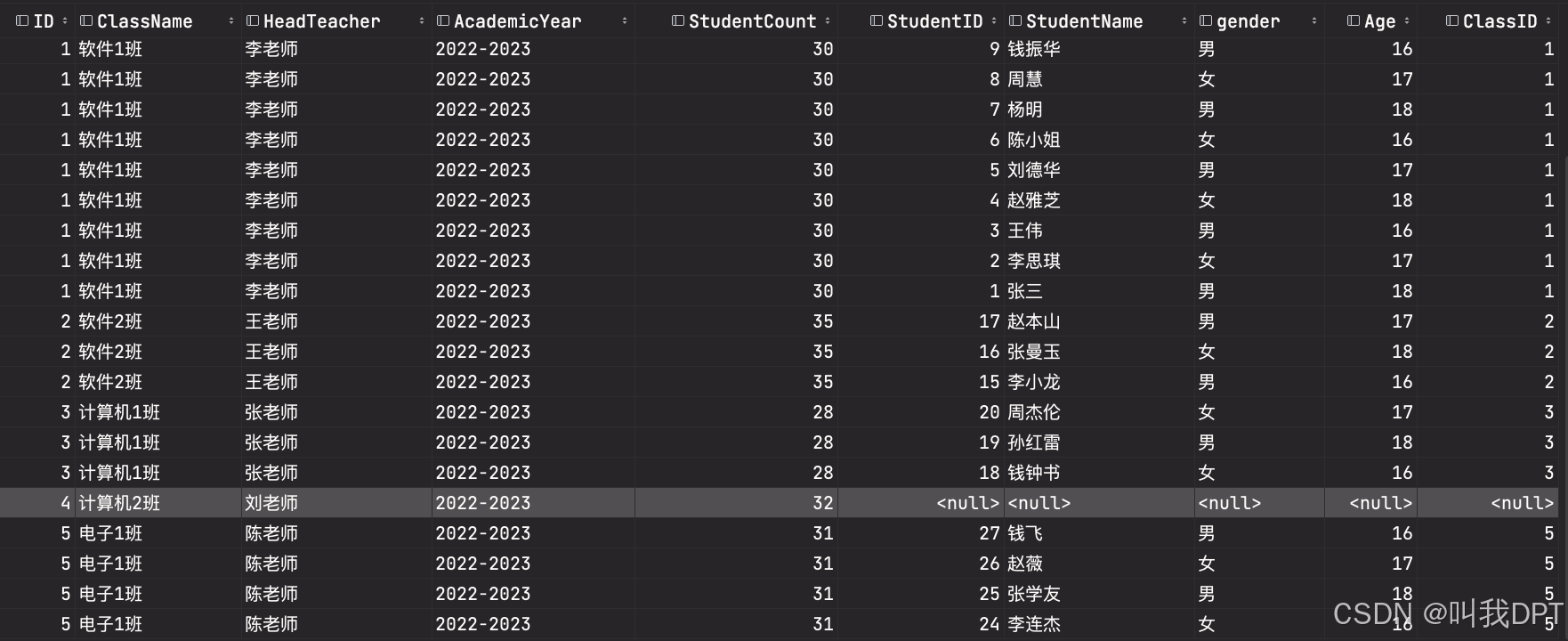
全连接(FULL JOIN): 全连接返回左表和右表中的所有行,无论是否有匹配。如果某个表的行没有匹配,结果集中对应的列将包含NULL值。
三、外键约束
外键约束是关系数据库中的一种机制,用于维护表之间的关联关系和数据完整性。外键约束经常和主键约束一起使用,用来确保数据的一致性。
外键约束(FOREIGN KEY)是表的一个特殊字段,经常与主键约束一起使用。对于两个具有关联关系的表而言,相关联字段中主键所在的表就是主表(父表),外键所在的表就是从表(子表)。
外键用来建立主表与从表的关联关系,为两个表的数据建立连接,约束两个表中数据的一致性和完整性。主表删除某条记录时,从表中与之对应的记录也必须有相应的改变。一个表可以有一个或多个外键,外键可以为空值,若不为空值,则每一个外键的值必须等于主表中主键的某个值。
比如上面的书籍管理案例,若删除一个ID=1的班级记录,没有任何影响,但是,学生表中ClassID = 1 的记录班级ID字段就没有意义了。
【1】创建表时设置外键约束
[CONSTRAINT <外键名>] FOREIGN KEY 字段名 [,字段名2,…] REFERENCES <主表名> 主键列1 [,主键列2,…] 定义外键时,需要遵守下列规则:
先有主表,再有子表。
必须为主表定义主键。
主键不能包含空值,但允许在外键中出现空值。
外键中列的数据类型必须和主表主键中对应列的数据类型相同。
例如:
CREATE TABLE Students2 ( StudentID INT PRIMARY KEY AUTO_INCREMENT, StudentName VARCHAR(255) NOT NULL, gender ENUM ('男','女','保密'), Age INT, ClassID INT, Constraint FK_Students_Classes FOREIGN KEY (ClassID) REFERENCES Classes2 (ID) ); CREATE TABLE Classes2 ( ID INT PRIMARY KEY, ClassName VARCHAR(50), HeadTeacher VARCHAR(50), StudentCount INT, AcademicYear VARCHAR(10) ); CREATE TABLE Courses2 ( ID INT PRIMARY KEY, CourseName VARCHAR(255), Instructor VARCHAR(255), Description VARCHAR(255), Credits INT, Classroom VARCHAR(255), Periods VARCHAR(255) ); CREATE TABLE StudentCourses2 ( StudentID INT, CourseID INT, CONSTRAINT FK_StudentCourses_Students FOREIGN KEY (StudentID) REFERENCES Students2 (StudentID), CONSTRAINT FK_StudentCourses_Courses FOREIGN KEY (CourseID) REFERENCES Courses2 (ID) ); 【2】添加删除外键约束
-- (1)添加外键约束 ALTER TABLE <数据表名> ADD CONSTRAINT <外键名> FOREIGN KEY(<列名>) REFERENCES <主表名> (<列名>); -- 给学生表ClassID字段添加外键约束 ALTER TABLE Students ADD CONSTRAINT class_fk FOREIGN KEY(ClassID) REFERENCES Classes(ID); SHOW CREATE TABLE Students; -- 尝试删除一个出版社记录 DELETE FROM Classes where ID = 1; -- 报错 -- (2)删除外键约束 ALTER TABLE <表名> DROP FOREIGN KEY <外键约束名>; drop index 外键约束名 on <表名>; -- 同时将索引删除 -- 将学生表ClassID字段的外键约束和索引删除 ALTER TABLE Students DROP FOREIGN KEY class_fk; Drop Index class_fk on Students; -- 同时将索引删除 【3】INNODB支持的ON语句
在 MySQL 中,InnoDB 是一种常用的存储引擎,它提供了一些 ON 语句来定义外键约束和触发器。以下是 InnoDB 支持的 ON 语句:
ON DELETE RESTRICT:如果关联的主表中的数据被删除,且从表中存在对应的数据,则禁止删除操作。ON DELETE CASCADE:当关联的主表中的数据被删除时,自动删除从表中对应的数据。ON DELETE SET NULL:当关联的主表中的数据被删除时,从表中对应的数据将被设置为 NULL。ON DELETE SET DEFAULT:当关联的主表中的数据被删除时,从表中对应的数据将被设置为默认值。ON UPDATE RESTRICT:如果关联的主表中的数据更新,且从表中存在对应的数据,则禁止更新操作。ON UPDATE CASCADE:当关联的主表中的数据更新时,自动更新从表中的对应数据。ON UPDATE SET NULL:当关联的主表中的数据更新时,从表中对应的数据将被设置为 NULL。ON UPDATE SET DEFAULT:当关联的主表中的数据更新时,从表中对应的数据将被设置为默认值。
这些 ON 语句可以在创建或修改外键约束时使用,以定义在不同操作(更新或删除)发生时,从表中的数据应该如何处理。
请注意,这些 ON 语句只适用于 InnoDB 存储引擎。
四、MySQL内置函数
MySQL内置函数是MySQL数据库提供的一组函数,用于在SQL查询中执行各种操作和计算。以下是一些常用的MySQL内置函数:
- 字符串函数:
CONCAT(str1, str2, ...):将多个字符串连接成一个字符串。UPPER(str):将字符串转换为大写。LOWER(str):将字符串转换为小写。SUBSTRING(str, start, length):返回字符串的子串。LENGTH(str):返回字符串的长度。TRIM(str):去除字符串两端的空格。REPLACE(str, old, new):将字符串中的某个子串替换为新的子串。
- 数值函数:
ABS(x):返回一个数的绝对值。ROUND(x, d):将一个数四舍五入到指定的小数位数。FLOOR(x):返回不大于给定数的最大整数。CEILING(x):返回不小于给定数的最小整数。RAND():返回一个0到1之间的随机数。
- 日期和时间函数:
NOW():返回当前日期和时间。CURDATE():返回当前日期。CURTIME():返回当前时间。DATE_FORMAT(date, format):将日期格式化为指定的格式。DATEDIFF(date1, date2):计算两个日期之间的天数差。DATE_ADD(date, INTERVAL expr unit):在日期上添加指定的时间间隔。
- 聚合函数:
COUNT(expr):计算满足条件的行数。SUM(expr):计算指定列的总和。AVG(expr):计算指定列的平均值。MIN(expr):计算指定列的最小值。MAX(expr):计算指定列的最大值。
这只是MySQL内置函数的一部分,还有许多其他函数可用于字符串处理、数值计算、日期时间操作、聚合计算等。
五、Python操作MySQL
【1】pymysql模块
python操作数据库:1.连接数据库 2.创建游标对象 3.执行操作 4.关闭游标对象 5.关闭数据库对象
安装:
pip install pymysql 基本语法
import pymysql # 连接到MySQL数据库 conn = pymysql.connect( host='localhost', user='your_username', password='your_password', database='your_database' ) # 创建游标对象 cursor = conn.cursor() # 执行SQL查询 query = "SELECT * FROM your_table" cursor.execute(query) # 获取查询结果 result = cursor.fetchall() for row in result: print(row) # 关闭游标和数据库连接 cursor.close() conn.close() 在上述示例中,首先使用pymysql.connect()函数连接到MySQL数据库。您需要提供数据库的连接参数,如主机名、用户名、密码和数据库名称。
然后,使用连接对象的cursor()方法创建一个游标对象。游标用于执行SQL查询并获取结果。
执行SQL查询时,可以使用游标对象的execute()方法传递SQL查询语句。在示例中,我们执行了一个简单的SELECT语句来获取表中的所有数据。
接下来,使用游标对象的fetchall()方法获取查询结果。fetchall()方法返回一个包含所有行的列表,每行又是一个元组。
最后,使用cursor.close()关闭游标对象,使用conn.close()关闭数据库连接。
请注意,在实际使用中,可能需要根据具体情况进行错误处理、事务处理和参数化查询等操作,以确保代码的正确性和安全性。
案例:创建user表,插入用户记录:
import pymysql def create_users_table(): conn = pymysql.connect( host='localhost', user='root', password='yuan0316', database='db_day02' ) cursor = conn.cursor() # 创建表的 SQL 语句 create_table_query = ''' CREATE TABLE users ( id INT AUTO_INCREMENT PRIMARY KEY, username VARCHAR(50) NOT NULL, password VARCHAR(50) NOT NULL ) ''' # 执行创建表的 SQL 语句 cursor.execute(create_table_query) cursor.close() conn.close() def insert_user(username, password): conn = pymysql.connect( host='localhost', user='root', password='yuan0316', database='db_day02' ) cursor = conn.cursor() # 插入记录的 SQL 语句 insert_query = f"INSERT INTO users (username, password) VALUES ('{username}', '{password}')" # 执行插入记录的 SQL 语句 cursor.execute(insert_query) conn.commit() cursor.close() conn.close() # 调用创建表函数 create_users_table() # 用户输入作为参数传递给插入函数 username = input("请输入用户名:") password = input("请输入密码:") # 调用插入函数 insert_user(username, password) 【2】SQL注入
SQL注入是一种常见的安全漏洞,它发生在应用程序未正确验证和处理用户输入数据时。攻击者可以通过在输入中插入恶意的SQL代码,利用这个漏洞来执行未经授权的数据库操作。
下面是一个简单的示例,展示了一个存在SQL注入漏洞的代码:
import pymysql def login(username, password): conn = pymysql.connect( host='localhost', user='root', password='yuan0316', database='db_day02' ) cursor = conn.cursor() # 构造SQL查询语句 query = f"SELECT * FROM users WHERE username = '{username}' AND password = '{password}'" print("query:",query) # 执行SQL查询 cursor.execute(query) # 获取查询结果 result = cursor.fetchall() cursor.close() conn.close() if len(result) > 0: print("登录成功") else: print("登录失败") # 用户输入作为参数传递给登录函数 username = input("请输入用户名:") password = input("请输入密码:") login(username, password) 在上述示例中,我们定义了一个login函数,该函数接收用户名和密码作为参数。在函数内部,我们使用pymysql库连接到MySQL数据库,并构造了一个包含用户名和密码的SQL查询语句。
然而,代码中存在SQL注入漏洞。如果用户输入恶意的数据,例如在用户名输入框中输入
' or 1=1;-- ,那么构造的查询语句将变为:
SELECT * FROM users WHERE username = '' or 1=1;-- ' AND password = '111' 这将导致查询条件始终为真,绕过了实际的身份验证过程,从而允许攻击者以任意用户登录。
参数化查询
要修复SQL注入漏洞,可以使用参数化查询或输入验证来过滤和转义用户输入数据,确保它们不会被当作SQL代码执行。以下是修复SQL注入漏洞的示例代码:
# 使用参数化查询构造SQL语句 query = "SELECT * FROM users WHERE username = %s AND password = %s" params = (username, password) # 执行SQL查询 cursor.execute(query, params) 在修复后的代码中,我们使用了参数化查询的方式来构造SQL语句。将用户输入作为参数传递给execute()方法,而不是直接将它们插入到SQL查询语句中。这样可以确保用户输入的数据被正确地转义和处理,防止SQL注入攻击的发生。
若有错误与不足请指出,关注DPT一起进步吧!!!
