
阅读量:0
Mindspore框架循环神经网络RNN模型实现情感分类
Mindspore框架循环神经网络RNN模型实现情感分类|(一)IMDB影评数据集准备
Mindspore框架循环神经网络RNN模型实现情感分类|(二)预训练词向量
Mindspore框架循环神经网络RNN模型实现情感分类|(三)RNN模型构建
Mindspore框架循环神经网络RNN模型实现情感分类|(四)损失函数与优化器
Mindspore框架循环神经网络RNN模型实现情感分类|(五)模型训练
Mindspore框架循环神经网络RNN模型实现情感分类|(六)模型加载和推理(情感分类模型资源下载)
Mindspore框架循环神经网络RNN模型实现情感分类|(七)模型导出ONNX与应用部署
tips:pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
一、损失函数
完成模型主体构建后,选择损失函数和优化器。本项目情感分类问题的特性,即预测Positive或Negative的二分类问题,选择nn.BCEWithLogitsLoss(二分类交叉熵损失函数)。
关于损失函数的作用意义和梯度下降,在“损失函数自动微分+梯度下降”相关博客有详细讲解,请前往查阅。
此处,直接选择二分类交叉熵损失函数:nn.BCEWithLogitsLoss。
import mindspore.nn as nn loss_fn = nn.BCEWithLogitsLoss(reduction='mean') BCEWithLogitsLoss: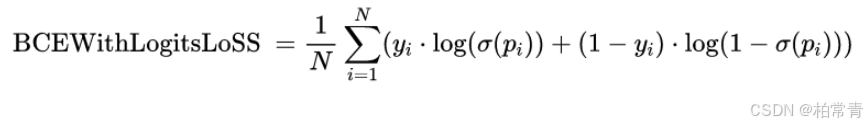
σ ( x ) = Sigmoid函数,log是自然对数。y是真实标签,p是预测值。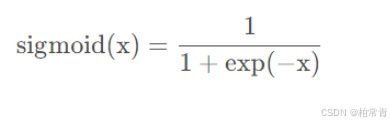
相较于BCELoss,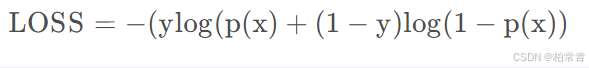
当然,BCELoss和BCEWithLogitsLoss一样,会遍历所有输出求均值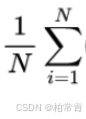
仅相差一个sigmoid函数对预测值进行处理。
所以,使用BCEWithLogitsLoss会直接计算输入值
loss_fn = nn.BCEWithLogitsLoss() loss = loss_fn (predicts, labels) 使用BCELoss,会额外调用nn.sigmoid()对p预测值进行处理。
sig = nn.Sigmoid() loss_bec = nn.BCELoss() loss = loss_bec(sig(predicts), labels) 输出损失值一样: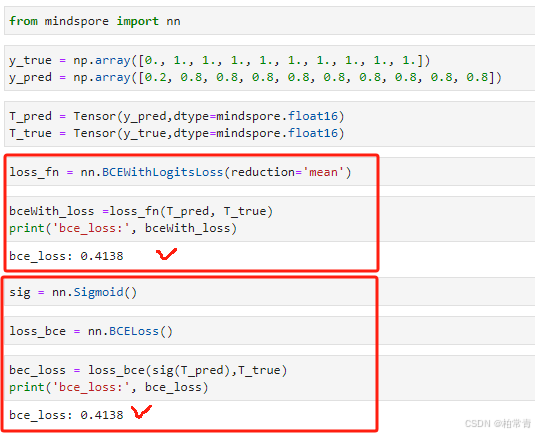
二、优化器
Adam(Adaptive Moment Estimation) :它是利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。前面我们提到损失函数和梯度下降,Loss = loss_fn (predicts, labels)=loss_fn([W(x)+b],y),x是数据,y是标签,为已知量,假设模型【w,b】组成的矩阵参数;其实损失函数loss是关于w和b的函数,我们已知了很多很多的(x,y)(即,标注的数据集),去求【w,b】的最优解。
求的方法:首先给【w,b】随机初始化一个初始值,将(x,y)一组(或者一批一批,并行)带到损失函数方程里面去求loss值;第一组loss1,计算第二组前让【w,b】变化lr(学习率),计算得到第二次loss2,要求修正【w,b】使后面的loss要越来越小;每次计算loss,都要修改一下模型参数(这是训练过程),确保loss递减,这个优化参数,修改参数的工具(算法)就是优化器。
optimizer = nn.Adam(model.trainable_params(), learning_rate=lr) 深度学习的目标是通过不断改变网络模型参数值,使得参数能够对输入做各种非线性变换拟合输出,本质上就是一个函数去寻找最优解。
为了使模型输出逼近或达到最优值,需要用各种优化策略和算法,来更新和计算影响模型训练和模型输出的网络参数。
按吴恩达老师所说的:梯度下降(Gradient Descent)就好比一个人想从高山上奔跑到山谷最低点,用最快的方式(steepest)奔向最低的位置(minimum)。
tips:你可以想象,模型参数【w,b】中的每一位参数个人,听从优化器的统一指挥。“各就位,变!”
