
阅读量:0

现代人工智能(AI)系统是由基础模型驱动的。本文提出了一套新的基础模型,称为Llama 3。它是一组语言模型,支持多语言、编码、推理和工具使用。我们最大的模型是一个密集的Transformer,具有405B个参数和多达128K个tokens的上下文窗口。本文对Llama 3进行了广泛的实证评价。我们发现Llama 3在大量任务上提供了与领先的语言模型(如GPT-4)相当的质量。我们公开发布了Llama 3,包括405B参数语言模型的预训练和后训练版本,以及用于输入和输出安全的Llama Guard 3模型。本文还介绍了我们通过合成方法将图像、视频和语音功能集成到Llama 3中的实验结果。我们观察到这种方法在图像、视频和语音识别任务上与最先进的方法相比具有竞争力。最终的模型还没有被广泛发布,因为它们仍在开发中。
1 Introduction 介绍
基础模型是语言、视觉、语音和/或其他模式的通用模型,旨在支持各种各样的人工智能任务。它们构成了许多现代人工智能系统的基础。
现代基础模型的发展包括两个主要阶段:(1)预训练阶段,在这个阶段,模型使用直接的任务进行大规模的训练,比如下一个单词预测或字幕;(2)后训练阶段,在这个阶段,模型被调整到遵循指令,与人类偏好保持一致,并提高特定的能力(例如,编码和推理)。
在本文中,我们提出了一套新的语言基础模型,称为Llama 3。Llama 3的模型群支持多语言、编码、推理和工具使用。我们最大的模型是具有405B个参数的密集Transformer,在多达128Ktokens的上下文窗口中处理信息。Llama 3 的每个成员列在表1中。本文给出的所有结果都是针对Llama 3.1模型的,为了简单起见,我们将其称为Llama 3。

我们相信在开发高质量的基础模型中有三个关键的杠杆:数据、规模和管理复杂性。在我们的开发过程中,我们寻求优化这三个杠杆:
•数据。与之前版本的Llama相比(Touvron等人,2023a,b),我们提高了用于预训练和后训练的数据的数量和质量。这些改进包括为训练前数据开发更仔细的预处理和管理管道,为训练后数据开发更严格的质量保证和过滤方法。我们在大约15T多语言标记的语料库上对Llama 3进行了预训练,而Llama 2的标记为1.8T。
•规模。我们以比以前的Llama模型大得多的规模训练模型:我们的旗舰语言模型使用3:8 × 1025 FLOPs进行预训练,几乎比Llama 2的最大版本多50倍。具体来说,我们在15.6T文本令牌上预训练了一个具有405B个可训练参数的旗舰模型。对于基础模型的缩放定律,我们的旗舰模型优于使用相同过程训练的较小模型。虽然我们的缩放定律表明我们的旗舰模型对于我们的训练预算来说是一个近似于计算最优的大小,但我们训练较小的模型的时间也比计算最优的时间长得多。在相同的推理预算下,所得模型比计算最优模型表现得更好。我们使用旗舰模型在后期训练中进一步提高那些较小模型的质量。
•管理复杂性。我们做出的设计选择是为了最大化我们扩展模型开发过程的能力。例如,我们选择了标准的密集Transformer模型架构(Vaswani等人,2017),并进行了较小的调整,而不是选择混合专家模型(Shazeer等人,2017),以最大限度地提高训练稳定性。同样,我们采用了一个相对简单的训练后程序,基于监督微调(SFT)、拒绝抽样(RS)和直接偏好优化(DPO;Rafailov等人(2023)),而不是更复杂的强化学习算法(Ouyang等人,2022;Schulman等人,2017),往往不太稳定,难以扩展。
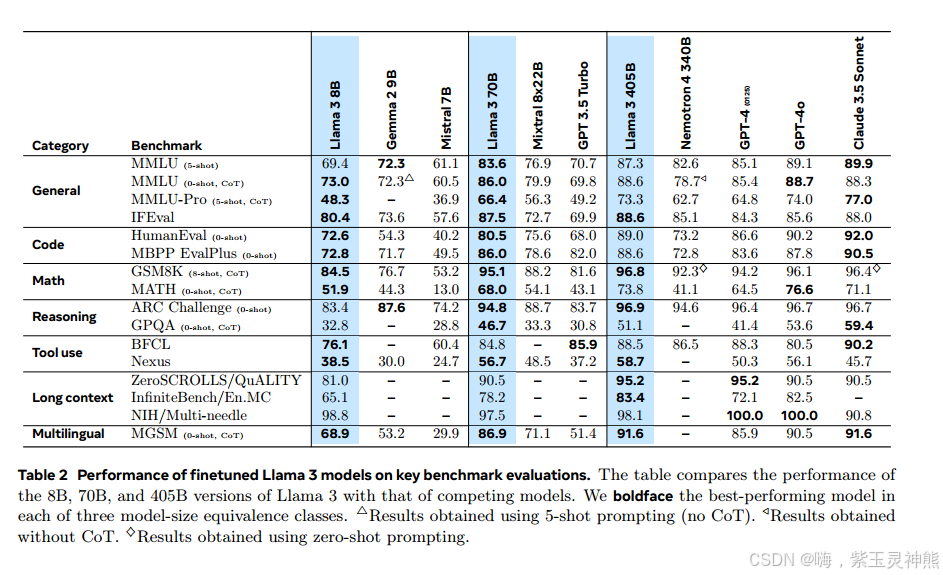
Llama 3是一组具有8B、70B和405B参数的三种多语言模型。我们在大量的基准数据集上评估了Llama 3的性能,这些数据集涵盖了广泛的语言理解任务。此外,我们进行了广泛的人类评估,将Llama 3与竞争模型进行比较。旗舰Llama 3模型在关键基准测试上的性能概述见表2。我们的实验评估表明,我们的旗舰模型在各种任务中的表现与领先的语言模型(如GPT-4 (OpenAI, 2023a))相当,并且接近于最先进的水平。我们的小型模型是同类中最好的,优于具有相似参数数量的替代模型(Bai等人,2023;Jiang et al, 2023)。Llama 3也提供了比它的前辈更好的平衡在帮助和无害(Touvron等人,2023b)。我们在第5.4节中详细分析了Llama 3的安全性。
我们将在更新版本的Llama 3社区许可下公开发布所有三款Llama 3模型;见https://llama.meta.com。这包括我们的405B参数语言模型的预训练和后训练版本,以及用于输入和输出安全的新版本的Llama Guard模型(Inan等人,2023)。
我们希望旗舰模型的公开发布将激发研究界的创新浪潮,并加速人工通用智能(AGI)发展的负责任道路。
作为Llama 3开发过程的一部分,我们还开发了模型的多模态扩展,支持图像识别、视频识别和语音理解功能。这些模型仍在积极开发中,尚未准备好发布。除了我们的语言建模结果外,本文还介绍了我们对这些多模态模型的初步实验结果。
2 General Overview 总体概述
Llama 3的模型体系结构如图1所示。我们的Llama 3语言模型的开发包括两个主要阶段:
•语言模型预训练。我们首先将大型多语言文本语料库转换为离散tokens,并在结果数据上预训练大型语言模型(LLM)以执行下一个token预测。在语言模型预训练阶段,模型学习语言的结构,从它所“阅读”的文本中获得大量关于世界的知识。为了有效地做到这一点,需要大规模地进行预训练:我们使用8K个tokens的上下文窗口,在15.6个token上预训练一个具有405B个参数的模型。这个标准的预训练阶段之后是一个持续的预训练阶段,将支持的上下文窗口增加到128K个tokens。详细信息请参见第3节。
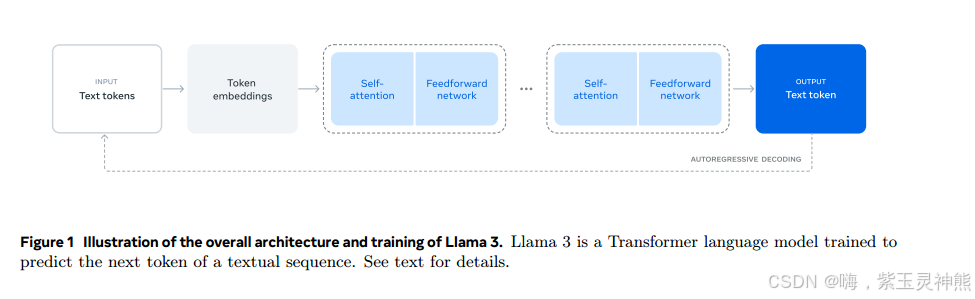
•语言模型后训练。预训练的语言模型对语言有丰富的理解,但它还没有按照我们期望的助手的方式执行指令或行为。我们将模型与人类反馈进行了几轮调整,每一轮都涉及指令调整数据的监督微调(SFT)和直接偏好优化(DPO);Rafailov et al, 2024)。在这个培训后2阶段,我们还集成了新的能力,例如工具使用,并观察到其他领域的强大改进,例如编码和推理。详细信息请参见第4节。最后,在培训后阶段也将安全缓解措施纳入模型,其细节见第5.4节。
生成的模型具有丰富的功能集。他们可以用至少八种语言回答问题,编写高质量的代码,解决复杂的推理问题,并使用部署即用的工具或以零样本的方式使用工具。
我们还进行了实验,其中我们使用合成方法为Llama 3添加图像,视频和语音功能。我们研究的方法包括图28所示的三个附加阶段:
•多模态编码器预训练。我们为图像和语音分别训练编码器。我们在大量的图像-文本对上训练图像编码器。这教会了模型视觉内容和自然语言描述内容之间的关系。我们的语音编码器是用自监督方法,屏蔽部分语音输入,并试图通过离散tokens表示重建被屏蔽的部分。因此,该模型学习语音信号的结构。关于图像编码器的详细信息参见第7节,关于语音编码器的详细信息参见第8节。
•视觉适配训练。我们训练了一个适配器,将预训练的图像编码器集成到预训练的语言模型中。适配器由一系列跨注意层组成,这些层将图像编码器表示
