
阅读量:0
前言
本文主要概述了Flink-CDC.
1. CDC 概述
1.1 什么是CDC?
CDC是(Change Data Capture 变更数据获取)的简称 ,在广义的概念上,只要是能捕获数据变更的技术,都可以称之为 CDC。
核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的插入INSERT、更新UPDATE、删除DELETE等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
CDC 技术的应用场景非常广泛:
- 数据同步:用于数据备份,容灾;
- 数据分发:一个数据源分发给多个下游系统;
- 数据采集:面向数据仓库 / 数据湖的 ETL 数据集成,是非常重要的数据源。
1.2 CDC的实现机制
CDC 的技术方案非常多,目前业界主流的实现机制可以分为两种:
1) 基于主动查询的 CDC:
用户通常会在数据源表的某个字段中,保存上次更新的时间戳或版本号等信息,然后下游通过不断的查询和与上次的记录做对比,来确定数据是否有变动,是否需要同步。
特点:
离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
持续的频繁查询对数据库的压力较大。
不保障实时性,基于离线调度存在天然的延迟。
2) 基于事件接收CDC:
可以通过触发器(Trigger)或者日志(例如 Transaction log、Binary log、Write-ahead log 等)来实现。当数据源表发生变动时,会通过附加在表上的触发器或者 binlog 等途径,将操作记录下来。下游可以通过数据库底层的协议,订阅并消费这些事件,然后对数据库变动记录做重放,从而实现同步。
实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
基于查询的CDC 基于Binlog的CDC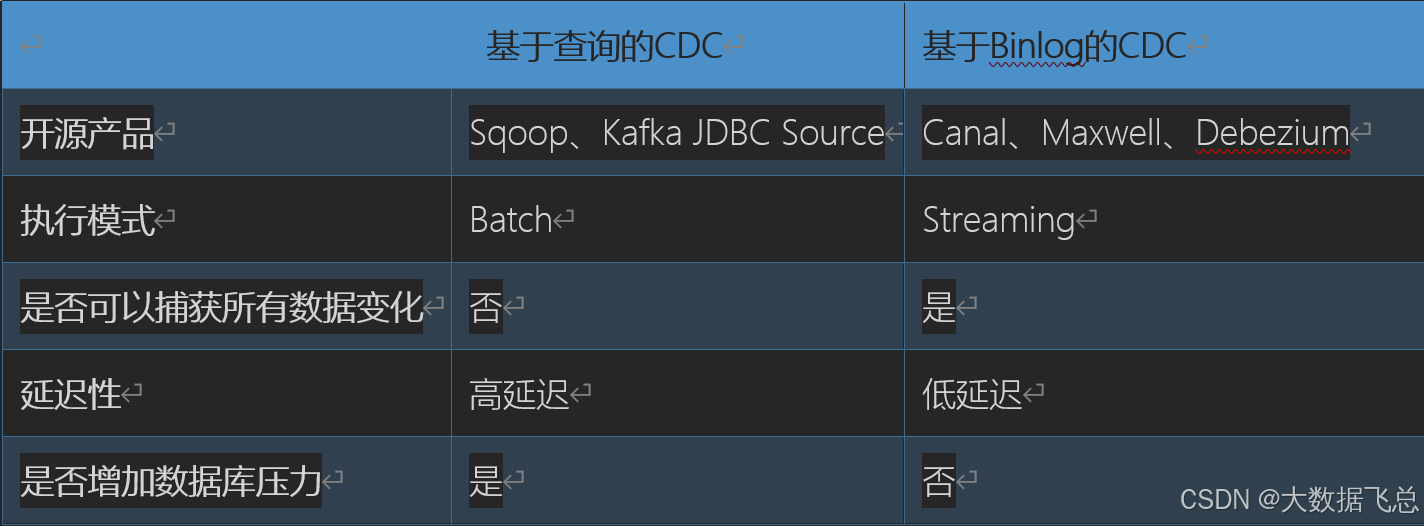
经过以上对比,可以发现基于日志CDC 有以下这几种优势:
能够捕获所有数据的变化,捕获完整的变更记录。在异地容灾,数据备份等场景中得到广泛应用,如果是基于查询的 CDC 有可能导致两次查询的中间一部分数据丢失
每次 DML 操作均有记录无需像查询 CDC 这样发起全表扫描进行过滤,拥有更高的效率和性能,具有低延迟,不增加数据库负载的优势
无需入侵业务,业务解耦,无需更改业务模型
1.3 常见的开源 CDC 方案对比全量同步能力:
基于查询或者日志的 CDC 方案基本都支持,除了 Canal(仅支持增量)。
对比全量 + 增量同步的能力,只有 Flink CDC、Debezium、Oracle Goldengate 支持较好。对比增量同步能力:
基于日志的方式,可以很好的做到增量同步;
而基于查询的方式是很难做到增量同步的。从架构角度去看:
该表将架构分为单机和分布式,这里的分布式架构不单纯体现在数据读取能力的水平扩展上,更重要的是在大数据场景下分布式系统接入能力。例如 Flink CDC 的数据入湖或者入仓的时候,下游通常是分布式的系统,如 Hive、HDFS、Iceberg、Hudi 等,那么从对接入分布式系统能力上看,Flink CDC 的架构能够很好地接入此类系统。在数据转换 / 数据清洗能力上:
当数据进入到 CDC 工具的时候是否能较方便的对数据做一些过滤或者清洗,甚至聚合。
在 Flink CDC 上操作相当简单,可以通过 Flink SQL 去操作这些数据;
DataX、Debezium 等则需要通过脚本或者模板去做,所以用户的使用门槛会比较高。在生态扩展方面:
这里指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义 connector。
