
阅读量:0
一、网络设定
我们设定一个简单的前馈神经网络,其结构如下:
输入层:节点数:2,接收输入数据,每个输入样本包含2个特征,例如
{1.0, 0.0},{0.0, 1.0}等。隐藏层:节点数:2,处理和提取输入数据的特征,
激活函数:使用 Sigmoid 激活函数
sigmoid(x) = 1 / (1 + exp(-x))权重矩阵(Weights from Input to Hidden):
float weights_input_hidden[INPUT_NODES][HIDDEN_NODES] = { {0.15, 0.25}, {0.20, 0.30} };这是一个 2x2 的权重矩阵,用于连接输入层和隐藏层。
偏置(Biases for Hidden Layer):
float bias_hidden[HIDDEN_NODES] = {0.35, 0.35};这是一个包含2个偏置值的数组,分别对应每个隐藏层节点。
每个隐藏层节点计算如下:
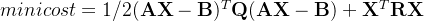
其中
是输入节点值,是权重,是偏置。
输出层:节点数:1,给出最终的预测结果。
激活函数:使用 Sigmoid 激活函数
权重矩阵:
float weights_hidden_output[HIDDEN_NODES][OUTPUT_NODES] = { {0.40}, {0.50} };这是一个 2x1 的权重矩阵,用于连接隐藏层和输出层。
偏置:
这是一个包含1个偏置值的数组,分别对应每个隐藏层节点。float bias_output[OUTPUT_NODES] = {0.60};- 输出层节点计算如下:其中 是隐藏层节点值,是权重, 是偏置。
整体网络设定如下图所示:
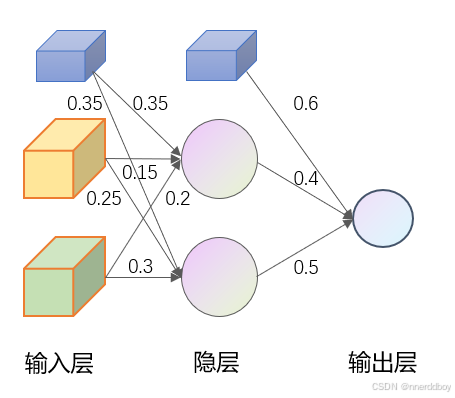
二、Arduino端代码
首先,是初始化部分(权重和偏置的定义)
float weights_input_hidden[INPUT_NODES][HIDDEN_NODES] = { {0.15, 0.25}, {0.20, 0.30} }; float weights_hidden_output[HIDDEN_NODES][OUTPUT_NODES] = { {0.40}, {0.50} }; float bias_hidden[HIDDEN_NODES] = {0.35, 0.35}; float bias_output[OUTPUT_NODES] = {0.60}; 接着,前向传播通过计算每一层的加权输入和激活输出来推断输入样本的预测值。
void forward_propagation(float input[]) { for (int i = 0; i < INPUT_NODES; i++) { input_layer[i] = input[i]; } for (int j = 0; j < HIDDEN_NODES; j++) { hidden_layer[j] = 0; for (int i = 0; i < INPUT_NODES; i++) { hidden_layer[j] += input_layer[i] * weights_input_hidden[i][j]; } hidden_layer[j] += bias_hidden[j]; hidden_layer[j] = sigmoid(hidden_layer[j]); } for (int k = 0; k < OUTPUT_NODES; k++) { output_layer[k] = 0; for (int j = 0; j < HIDDEN_NODES; j++) { output_layer[k] += hidden_layer[j] * weights_hidden_output[j][k]; } output_layer[k] += bias_output[k]; output_layer[k] = sigmoid(output_layer[k]); } } 最后,反向传播通过计算误差并根据误差调整权重和偏置,以最小化损失函数。
void backward_propagation(float input[], float target) { float output_error = target - output_layer[0]; float output_delta = output_error * sigmoid_derivative(output_layer[0]); float hidden_error[HIDDEN_NODES]; float hidden_delta[HIDDEN_NODES]; for (int j = 0; j < HIDDEN_NODES; j++) { hidden_error[j] = output_delta * weights_hidden_output[j][0]; hidden_delta[j] = hidden_error[j] * sigmoid_derivative(hidden_layer[j]); } for (int j = 0; j < HIDDEN_NODES; j++) { weights_hidden_output[j][0] += learning_rate * output_delta * hidden_layer[j]; } bias_output[0] += learning_rate * output_delta; for (int i = 0; i < INPUT_NODES; i++) { for (int j = 0; j < HIDDEN_NODES; j++) { weights_input_hidden[i][j] += learning_rate * hidden_delta[j] * input_layer[i]; } } for (int j = 0; j < HIDDEN_NODES; j++) { bias_hidden[j] += learning_rate * hidden_delta[j]; } } 定义四组输入样本及其目标输出,用于训练神经网络, 通过多次迭代训练神经网络,并在每次训练后输出当前的权重和F1-score。完整代码如下:
#include <Arduino.h> #include <cmath> // 定义神经网络结构 #define INPUT_NODES 2 #define HIDDEN_NODES 2 #define OUTPUT_NODES 1 // 定义神经网络参数 float input_layer[INPUT_NODES]; float hidden_layer[HIDDEN_NODES]; float output_layer[OUTPUT_NODES]; float weights_input_hidden[INPUT_NODES][HIDDEN_NODES] = { {0.15, 0.25}, {0.20, 0.30} }; float weights_hidden_output[HIDDEN_NODES][OUTPUT_NODES] = { {0.40}, {0.50} }; float bias_hidden[HIDDEN_NODES] = {0.35, 0.35}; float bias_output[OUTPUT_NODES] = {0.60}; float learning_rate = 0.1; // 激活函数和其导数(sigmoid) float sigmoid(float x) { return 1.0 / (1.0 + exp(-x)); } float sigmoid_derivative(float x) { return x * (1.0 - x); } // 计算预测值 void forward_propagation(float input[]) { for (int i = 0; i < INPUT_NODES; i++) { input_layer[i] = input[i]; } for (int j = 0; j < HIDDEN_NODES; j++) { hidden_layer[j] = 0; for (int i = 0; i < INPUT_NODES; i++) { hidden_layer[j] += input_layer[i] * weights_input_hidden[i][j]; } hidden_layer[j] += bias_hidden[j]; hidden_layer[j] = sigmoid(hidden_layer[j]); } for (int k = 0; k < OUTPUT_NODES; k++) { output_layer[k] = 0; for (int j = 0; j < HIDDEN_NODES; j++) { output_layer[k] += hidden_layer[j] * weights_hidden_output[j][k]; } output_layer[k] += bias_output[k]; output_layer[k] = sigmoid(output_layer[k]); } } // 更新权重和偏置 void backward_propagation(float input[], float target) { float output_error = target - output_layer[0]; float output_delta = output_error * sigmoid_derivative(output_layer[0]); float hidden_error[HIDDEN_NODES]; float hidden_delta[HIDDEN_NODES]; for (int j = 0; j < HIDDEN_NODES; j++) { hidden_error[j] = output_delta * weights_hidden_output[j][0]; hidden_delta[j] = hidden_error[j] * sigmoid_derivative(hidden_layer[j]); } for (int j = 0; j < HIDDEN_NODES; j++) { weights_hidden_output[j][0] += learning_rate * output_delta * hidden_layer[j]; } bias_output[0] += learning_rate * output_delta; for (int i = 0; i < INPUT_NODES; i++) { for (int j = 0; j < HIDDEN_NODES; j++) { weights_input_hidden[i][j] += learning_rate * hidden_delta[j] * input_layer[i]; } } for (int j = 0; j < HIDDEN_NODES; j++) { bias_hidden[j] += learning_rate * hidden_delta[j]; } } // 计算F1-score float compute_f1_score(float tp, float fp, float fn) { float precision = tp / (tp + fp); float recall = tp / (tp + fn); return 2 * (precision * recall) / (precision + recall); } void print_weights() { Serial.println("Weights Input-Hidden:"); for (int i = 0; i < INPUT_NODES; i++) { for (int j = 0; j < HIDDEN_NODES; j++) { Serial.printf("w[%d][%d] = %f ", i, j, weights_input_hidden[i][j]); } Serial.println(); } Serial.println("Weights Hidden-Output:"); for (int j = 0; j < HIDDEN_NODES; j++) { Serial.printf("w[%d][0] = %f ", j, weights_hidden_output[j][0]); } Serial.println(); } void setup() { // 初始化串口 Serial.begin(115200); while (!Serial) {} // 打印欢迎信息 Serial.println("Hello, ESP32 Neural Network with Training!"); } void loop() { // 输入样本和目标 float input[][INPUT_NODES] = {{1.0, 0.0}, {0.0, 1.0}, {1.0, 1.0}, {0.0, 0.0}}; float target[] = {1.0, 1.0, 0.0, 0.0}; // 初始化统计量 float tp = 0, fp = 0, fn = 0; // 训练 for (int epoch = 0; epoch < 1000; epoch++) { for (int i = 0; i < 4; i++) { forward_propagation(input[i]); backward_propagation(input[i], target[i]); // 更新统计量 float prediction = output_layer[0] > 0.5 ? 1.0 : 0.0; if (prediction == 1.0 && target[i] == 1.0) { tp++; } else if (prediction == 1.0 && target[i] == 0.0) { fp++; } else if (prediction == 0.0 && target[i] == 1.0) { fn++; } } // 打印权重和F1-score Serial.printf("Epoch %d\n", epoch); print_weights(); float f1_score = compute_f1_score(tp, fp, fn); Serial.printf("F1-Score: %f\n", f1_score); // 重置统计量 tp = 0; fp = 0; fn = 0; // 延迟一段时间 delay(100); } // 停止程序 while (true) {} } 部分打印结果如下:

