
阅读量:0
目录
个人格言:悟已往之不谏,知来者犹可追
克心守己,律己则安!

1.思想动图
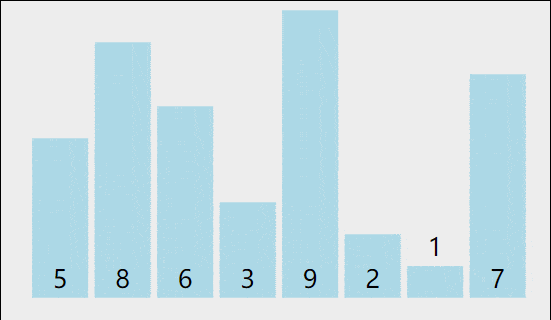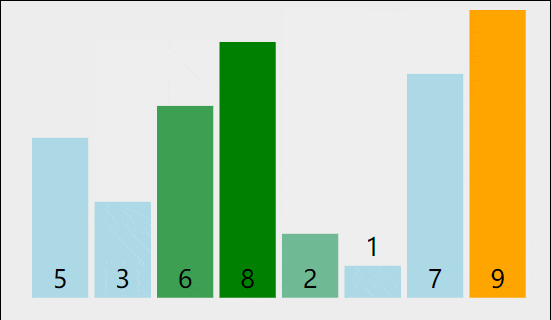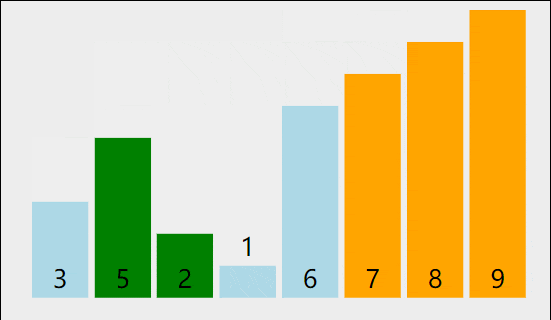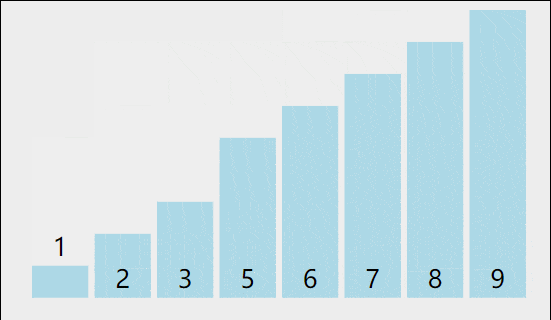
2 如何完成代码实现
2.1 一趟排序怎么排呢?
相邻元素俩俩比较,如果前面的元素大于后面,则进行交换的操作,否则(小于或等于)就不进行交换。
假设有n个元素,则一趟排序的逻辑如下:
for (int j = 0; j < n - 1; j++) { if (a[j] > a[j + 1]) { int tmp = a[j]; a[j] = a[j + 1]; a[j + 1] = tmp; } }那为什么j是小于N-1而不是n呢?
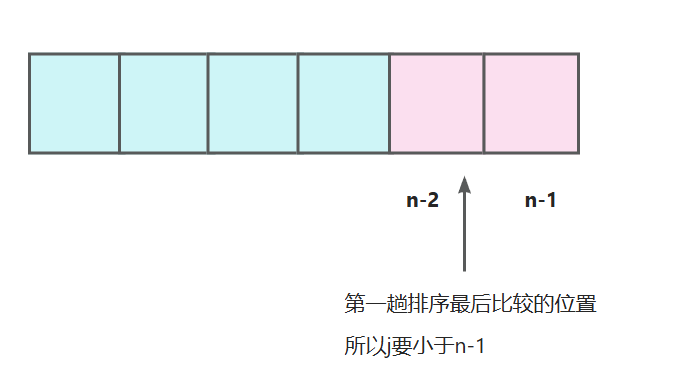
2.2 一共要排几趟呢?
我们知道第一趟排序后,最大的元素被排到最后了,也就相当于最后一个元素是有序的了,那第二趟排序之后,次大的元素就到倒数第二个位置了。
一趟排序就让一个元素有序,假设有n个元素,那我们进行n-1趟排序之后N-1个元素就有序了,那最后一个元素(也就是第一个元素)必然有序的!所以,我们只要进行N-1趟排序就足够了!
for (int i=0; i < n-1; i++) { for (int j = 0; j < n - 1; j++) { if (a[j] > a[j + 1]) { int tmp = a[j]; a[j] = a[j + 1]; a[j + 1] = tmp; } } }到这里,最简单的冒泡排序就已近完成了~
2.3 可不可以优化一下呢?
我们注意到,每一趟排序之后,就有一个元素有序,那有序的元素在下一趟排序就可以不用再比较了,那第二层循环的条件就可以改为:
for (int j = 0; j < n - 1-i; j++)我们思考一下,如果在某一趟排序时,没有发生一次交换,那是不是说明该数组是有序了呢!
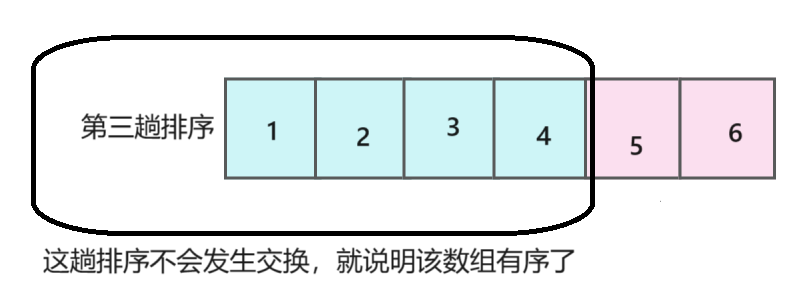
那我们就可以结束循环了!
void BubbleSort(int* a,int n) { //每趟循环进来都假设数组有序 int flag = 1;//假设数组有序flag值为1 for (int i=0; i < n-1; i++) { for (int j = 0; j < n - 1-i; j++) { if (a[j] > a[j + 1]) { int tmp = a[j]; a[j] = a[j + 1]; a[j + 1] = tmp; //一旦发生交换数组就不是有序的,flag置为0 flag = 0; } } //一趟后判断一下数组是否有序 if (flag == 1) break;//有序直接结束循环 } }3.冒泡排序的时空复杂度
>空间复杂度:冒泡排序的所有操作都是在原数组上完成的,并没有开辟使用额外的空间,所以他的空间复杂度为O(1)。
>时间复杂度:以最坏的情况为例,假设我们要将一组倒序的(元素个数为n的)数据排为升序。
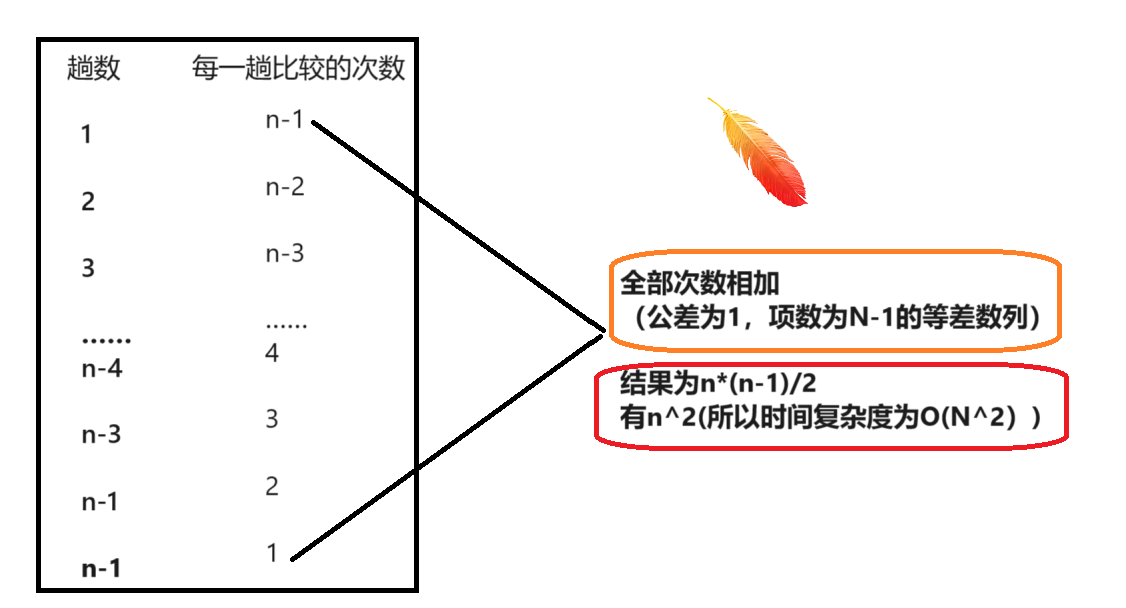
4.冒泡排序的意义
优点:
简单易懂:冒泡排序是一种非常简单的排序算法,它的思想容易理解,代码实现也相对容易。
稳定排序:冒泡排序是一种稳定的排序算法,即在排序过程中,相同大小的元素不会相互交换位置。
空间复杂度低:冒泡排序的空间复杂度为 O(1),即它只需要使用固定的额外空间来存储交换的元素,而不依赖于输入数组的大小。
缺点:
时间复杂度高:冒泡排序的时间复杂度为 O(n^2),在处理大规模数据时效率较低。
不适合大规模数据:由于冒泡排序需要进行多次比较和交换操作,对于大规模数据集,其性能可能会较差。
排序不彻底:在最坏情况下,冒泡排序可能无法将数组完全排序,例如当数组已经基本有序时。
5.总结
冒泡排序是最基础的排序算法之一,通过相邻元素的比较和交换,逐渐将最大(或最小)的元素冒泡到数列的一端。尽管冒泡排序的效率相对较低,但它的实现简单易懂,是理解排序算法的入门之选。冒泡排序适用于小规模数据和部分排序数据的情况,同时也常用于教学和理解排序算法的基本原理。
然而,在实际应用中,对于大规模数据集,我们更倾向于选择时间复杂度较低的排序算法,如快速排序、归并排序和堆排序等。这些算法能够在更短的时间内完成排序任务,提高程序的执行效率。因此,在实际开发中,我们需要根据具体情况选择合适的排序算法。
6、完结散花
好了,这期的分享到这里就结束了~
如果这篇博客对你有帮助的话,可以用你们的小手指点一个免费的赞并收藏起来哟~
如果期待博主下期内容的话,可以点点关注,避免找不到我了呢~
我们下期不见不散~~


