
阅读量:0
摘要:
本文基于深度学习实现水果的单个图像、批量图像以及视频的分类识别,使用的是VGG16神经网络模型,下面详细介绍一下流程。
一、模型介绍
模型训练采用VGG-16,该网络通过简单的深度卷积堆叠实现特征提取,具有高度统一的网络设计优势,容易实现,但是提高了深度特征的表达能力。VGG-16网络使用了多个3x3的卷积核来代替较大尺寸的卷积核,例如5x5或7x7。这种设计的优势在于,多个小卷积核的叠加可以增加网络的非线性表示能力,并且通过使用较小的卷积核可以减少参数数量,降低过拟合的风险,非常适合本次任务的要求。
二、数据集准备
本次任务使用到同济子豪兄的水果识别数据集,该数据集包含了81种水果:水果数据集

其中每种水果种类的图片都非常丰富,数据多样,对模型的泛化能力有很好的帮助。同时,还有一段视频作为待会测试的视频数据,该视频包含包含了三种水果,分别是猕猴桃,柠檬以及石榴,所以为了简化任务,我单独抽出以上三种水果的数据集做了一个简单的小数据集,如下图:

视频数据集在这。
然后我们需要将数据集分为训练集和测试集,在目录下创建dataset.dataset.py,代码如下:
# coding:utf8 import os from PIL import Image from torch.utils import data from torchvision import transforms as T from sklearn.model_selection import train_test_split Labels = {'mihoutao':0, 'ningmeng':1, 'shiliu':2} class SeedlingData (data.Dataset): def __init__(self, root, transforms=None, train=True, test=False): """ 主要目标: 获取所有图片的地址,并根据训练,验证,测试划分数据 """ self.test = test self.transforms = transforms if self.test: imgs = [os.path.join(root, img) for img in os.listdir(root)] self.imgs = imgs else: imgs_labels = [os.path.join(root, img) for img in os.listdir(root)] imgs = [] for imglable in imgs_labels: for imgname in os.listdir(imglable): imgpath = os.path.join(imglable, imgname) imgs.append(imgpath) trainval_files, val_files = train_test_split(imgs, test_size=0.3, random_state=42) if train: self.imgs = trainval_files else: self.imgs = val_files def __getitem__(self, index): """ 一次返回一张图片的数据 """ img_path = self.imgs[index] img_path=img_path.replace("\\",'/') if self.test: label = -1 else: labelname = img_path.split('/')[-2] label = Labels[labelname] data = Image.open(img_path).convert('RGB') data = self.transforms(data) return data, label def __len__(self): return len(self.imgs) 三、训练模型
直接上代码:
import torch.optim as optim import torch import torch.nn as nn import torch.nn.parallel import torch.utils.data import torch.utils.data.distributed import torchvision.transforms as transforms from dataset.dataset import SeedlingData from torch.autograd import Variable from torchvision.models import vgg16 import matplotlib.pyplot as plt # 设置全局参数 modellr = 1e-4 BATCH_SIZE = 32 EPOCHS = 10 DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 数据预处理 transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) ]) transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) ]) dataset_train = SeedlingData('data', transforms=transform, train=True) dataset_test = SeedlingData("data", transforms=transform_test, train=False) # 导入数据 train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False) # 实例化模型并且移动到GPU criterion = nn.CrossEntropyLoss() model_ft = vgg16(pretrained=True) model_ft.classifier = nn.Sequential( nn.Linear(512 * 7 * 7, 4096), nn.ReLU(True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(True), nn.Dropout(), nn.Linear(4096, 3), ) model_ft.to(DEVICE) # 选择简单暴力的Adam优化器,学习率调低 optimizer = optim.Adam(model_ft.parameters(), lr=modellr) def adjust_learning_rate(optimizer, epoch): #更新学习率 modellrnew = modellr * (0.1 ** (epoch // 50)) print("lr:", modellrnew) for param_group in optimizer.param_groups: param_group['lr'] = modellrnew epoch_list = [] train_loss_list = [] val_loss_list = [] train_acc_list = [] val_acc_list = [] # 定义训练过程 def train(model, device, train_loader, optimizer, epoch): model.train() sum_loss = 0 total_num = len(train_loader.dataset) print(total_num, len(train_loader)) for batch_idx, (data, target) in enumerate(train_loader): data, target = Variable(data).to(device), Variable(target).to(device) output = model(data) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step() print_loss = loss.data.item() sum_loss += print_loss if (batch_idx + 1) % 10 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, (batch_idx + 1) * len(data), len(train_loader.dataset), 100. * (batch_idx + 1) / len(train_loader), loss.item())) ave_loss = sum_loss / len(train_loader) train_loss_list.append(ave_loss) print('epoch:{},loss:{}'.format(epoch, ave_loss)) # 验证过程 def val(model, device, test_loader): model.eval() test_loss = 0 correct = 0 total_num = len(test_loader.dataset) print(total_num, len(test_loader)) with torch.no_grad(): for data, target in test_loader: data, target = Variable(data).to(device), Variable(target).to(device) output = model(data) loss = criterion(output, target) _, pred = torch.max(output.data, 1) correct += torch.sum(pred == target) print_loss = loss.data.item() test_loss += print_loss correct = correct.data.item() acc = correct / total_num avgloss = test_loss / len(test_loader) val_loss_list.append(avgloss) val_acc_list.append(acc) print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( avgloss, correct, len(test_loader.dataset), 100 * acc)) # 训练 for epoch in range(1, EPOCHS + 1): adjust_learning_rate(optimizer, epoch) train(model_ft, DEVICE, train_loader, optimizer, epoch) val(model_ft, DEVICE, test_loader) torch.save(model_ft, 'model.pth') 由于数据集不是很大,训练只需经历10轮就能达到很好的效果:
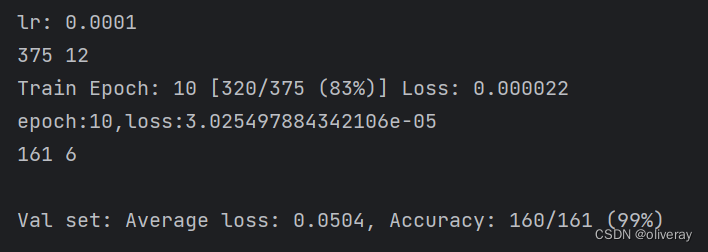
如此,我们得到了一个model.pth模型。
四、测试模型
测试分为单张图像测试,批量图像测试以及视频测试
(1)单张图像测试代码:
#单张图像分类 from PIL import Image import torch.utils.data.distributed import torchvision.transforms as transforms import cv2 classes = ('mihoutao','ningmeng', 'shiliu') transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) ]) DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model=torch.load('model.pth',map_location=DEVICE) model.eval() model.to(DEVICE) #输入图像路径 path = 'data/mihoutao/1.jpg' img = cv2.imread(path) pil_image = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) # 对图像进行预处理转换 transformed_image = transform_test(pil_image) # 添加一个维度,以符合模型的输入要求 transformed_image.unsqueeze_(0) # 将输入数据移动到GPU上 transformed_image = transformed_image.cuda() # 使用模型进行推理 with torch.no_grad(): output = model(transformed_image) # 将输出数据移动到CPU上 output = output.cpu() # 预测类别 _, pred = torch.max(output, 1) predicted_class = classes[pred.item()] # 在图像上打印分类结果 cv2.putText(img, predicted_class, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 255, 0), 2) cv2.imshow('res',img) cv2.waitKey(0) cv2.destroyAllWindows()结果会打印在图像上:opencv不接受中文名,所以我这里使用拼音

(2)、批量图像测试代码
这里我突然发现数据集中部分图像是RGBA的,这样不能用RGB的格式读出,所以我全部改成了RGB,修改图像格式的代码是这样的:
from PIL import Image import os # 定义图像文件夹路径 folder_path = 'data/mihoutao/' # 获取图像文件夹中的所有文件 file_list = os.listdir(folder_path) # 遍历图像文件列表 for file_name in file_list: # 构建图像文件的完整路径 file_path = os.path.join(folder_path, file_name) # 打开图像 img = Image.open(file_path) # 检查图像的通道数 if img.mode != 'RGB': # 如果图像不是3通道的RGB图像,则删除该文件 os.remove(file_path) print(f"Deleted {file_name} due to invalid channel: {img.mode}") #你也可以这么写: # from PIL import Image # import os # # # 定义图像文件夹路径 # folder_path = 'data/shiliu/' # # # 获取图像文件夹中的所有文件 # file_list = os.listdir(folder_path) # # # 遍历图像文件列表 # for file_name in file_list: # # 构建图像文件的完整路径 # file_path = os.path.join(folder_path, file_name) # # # 打开图像 # image = Image.open(file_path) # # # 检查图像的模式(通道数) # if image.mode == 'RGBA': # # 将RGBA图像转换为RGB图像 # image = image.convert('RGB') # # # 保存转换后的图像(覆盖原始文件) # image.save(file_path) # # print(f"Converted {file_name} from RGBA to RGB")批量预测的代码如下:
import torch.utils.data.distributed import torchvision.transforms as transforms from PIL import Image from torch.autograd import Variable import os import time classes = ('mihoutao','ningmeng', 'shiliu') transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) ]) DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model=torch.load('model.pth',map_location=DEVICE) model.eval() model.to(DEVICE) correct = 0 total = 0 path = 'data/' testList = os.listdir(path) start_time = time.time() for class_name in classes: class_path = os.path.join(path, class_name) # 获取每个类别的文件夹路径 image_list = os.listdir(class_path) for file_name in image_list: image_path = os.path.join(class_path, file_name) # 获取每张图像的路径 img = Image.open(image_path) img = transform_test(img) img.unsqueeze_(0) img = img.to(DEVICE) with torch.no_grad(): out = model(img) _, pred = torch.max(out.data, 1) total += 1 if classes[pred.item()] == class_name: correct += 1 accuracy = correct / total end_time = time.time() total_time = end_time-start_time print(f"Accuracy: {accuracy * 100:.2f}%") print(print(f"Execution Time: {total_time:.2f} seconds")) 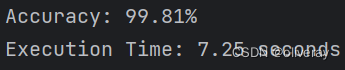
(3) 视频图像分类:这个思路是将对视频的每一帧进行分类,并在每一帧图像上打印分类结果。最后,将分类好的图像写入输出视频文件,代码如下:
import cv2 import torch from torchvision import transforms from PIL import Image # 定义类别标签 classes = ('mihoutao', 'ningmeng', 'shiliu') # 定义图像的预处理转换 transform = transforms.Compose([ transforms.Resize(224), # transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) # 加载模型并将其移动到GPU上 model = torch.load("model.pth") model = model.cuda() model.eval() # 定义视频文件路径 video_path = 'fruits_video.mp4' # 打开视频文件 video = cv2.VideoCapture(video_path) # 获取视频的帧率和尺寸 fps = video.get(cv2.CAP_PROP_FPS) width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 创建视频编写器 output_path = 'output/output.mp4' fourcc = cv2.VideoWriter_fourcc(*'mp4v') output_video = cv2.VideoWriter(output_path, fourcc, fps, (width, height)) # 遍历视频的每一帧图像 while video.isOpened(): ret, frame = video.read() if not ret: break # 将图像转换为PIL图像 pil_image = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)) # 对图像进行预处理转换 transformed_image = transform(pil_image) # 添加一个维度,以符合模型的输入要求 transformed_image.unsqueeze_(0) # 将输入数据移动到GPU上 transformed_image = transformed_image.cuda() # 使用模型进行推理 with torch.no_grad(): output = model(transformed_image) # 将输出数据移动到CPU上 output = output.cpu() # 预测类别 _, pred = torch.max(output, 1) predicted_class = classes[pred.item()] # 在图像上打印分类结果 cv2.putText(frame, predicted_class, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 255, 0), 2) # 将带有分类结果的图像写入输出视频 output_video.write(frame) # 释放视频对象和输出视频对象 video.release() output_video.release() print("Video classification and annotation completed!")结果也是正确分类了:
水果视频检测
以上就是全部内容,求点赞、收藏!感谢支持。
