
阅读量:0
无论是基于成本效益还是社区支持,我都坚决认为开源才是推动一切应用的动力源泉。下面推荐语音识别开源工具:Kaldi,Paddle,WeNet,EspNet。
1、最成熟的Kaldi
一个广受欢迎的开源语音识别工具,由Daniel Povey博士领导开发。Kaldi集成了多种语音识别模型,包括隐马尔可夫模型(HMM)和深度学习神经网络。它是第一个完全用C++编写的、基于加权有限状态机理论的语音识别开源软件,同时提供了Python接口,其模块化与高度可扩展性设计让Kaldi在学术界和工业界中广受好评,被认为是业界语音识别框架的基石。
Kaldi的核心设计包括特征提取(如MFCC、PLP等)、状态建模(如HMM、TDNN、LSTM等)、数据处理、训练框架(支持在线学习、多GPU训练和分布式训练)和解码器等。
1.1 如何开始使用Kaldi
安装依赖项:
安装Kaldi之前,您需要确保所有依赖项都已安装在您的系统上。这些通常包括OpenFst、Atlas(或MKL)、IRSTLM、sph2pipe等。
下载Kaldi源代码:
您可以从Kaldi的官方GitHub仓库(https://github.com/kaldi-asr/kaldi)克隆或下载源代码。
编译Kaldi:
在下载源代码后,您需要按照Kaldi的文档中的说明进行编译。这通常涉及运行一些脚本来编译Kaldi的库和可执行文件。
了解Kaldi的结构:
Kaldi的结构包括脚本、库和可执行文件。它通常按照特定的数据流和文件格式来组织。
运行示例脚本:
Kaldi提供了许多示例脚本,这些脚本展示了如何使用Kaldi进行不同的语音识别任务。您可以从运行这些示例脚本开始学习Kaldi的使用。
学习Kaldi的组件:
了解Kaldi的不同组件,如声学模型、语言模型、解码器等,以及它们是如何交互的。
处理数据和特征提取:
学习如何使用Kaldi处理音频数据,包括如何进行特征提取,以及如何准备和格式化数据以供Kaldi使用。
训练和调整模型:
使用Kaldi训练声学模型和语言模型。了解如何调整模型参数以优化性能。
解码和评估:
学习如何使用Kaldi的解码器进行语音识别,并评估识别结果的质量。
加入社区:
Kaldi有一个活跃的社区。加入邮件列表和论坛,参与讨论,获取帮助,分享经验。
1.2 如何学习使用Kaldi的高级特性
新一代 Kaldi 是一个开源的智能语音工具集,几乎涵盖了构建智能语音系统的方方面面。下图简单罗列了新一代 Kaldi 的项目矩阵,包括数据、训练到部署全链条,支持语音识别(ASR)、语音合成(TTS)、关键词检测(KWS)、话音检测(VAD)、说话人识别(Speaker identification)、语种识别(Spoken language identification) 等。
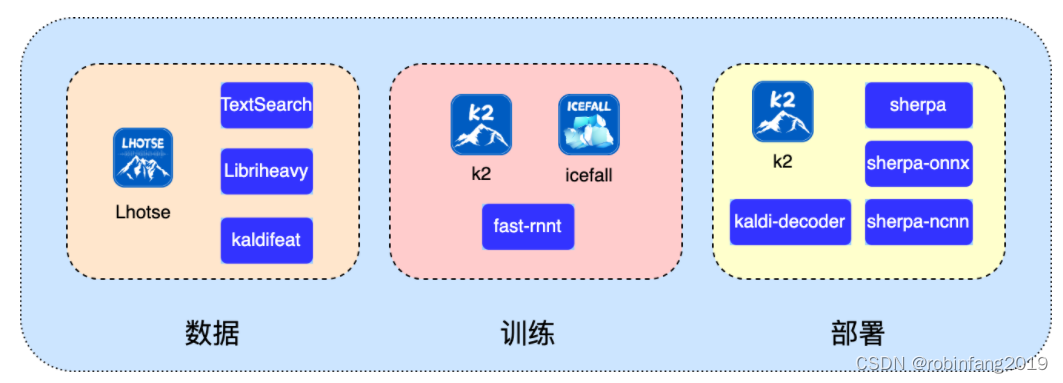
新一代Kaldi的全面资源,包括模型、演示程序、工具链等,详见新一代Kaldi,根据自身需要选择学习。
2、PaddleSpeech
百度飞桨(PaddlePaddle)开源的语音方向的模型库,它用于语音和音频中的各种关键任务的开发。PaddleSpeech 提供了丰富的、基于深度学习的前沿和有影响力的模型,适用于多种语音识别任务。支持在Windows、MacOS、Linux(包括Ubuntu、CentOS等)等多个操作系统上运行,并提供了C++和Python等多种编程语言的支持。
2.1 如何开始使用PaddleSpeech
数据准备
收集数据:收集足够的训练数据,包括音频文件和对应的文本标签。PaddleSpeech支持多种音频格式,如WAV、MP3等。
数据标注:对音频数据进行标注,生成文本标签。可以利用现成的标注工具或自行开发。
数据预处理:将数据转换为PaddleSpeech所需的格式,并按照规定的目录结构组织。
模型选择
PaddleSpeech提供了多种预训练模型,包括DeepSpeech2、Conformer、Transformer等。你可以选择一个适合你数据集的模型作为起点。
模型训练
配置环境:确保已安装PaddlePaddle和PaddleSpeech,以及必要的Python库。
训练脚本:使用PaddleSpeech提供的训练脚本进行模型训练。训练脚本通常包含多种参数,如学习率、批大小、训练轮数等,可根据需求调整。
训练执行:运行训练脚本,训练过程可能需要较长时间,取决于数据集大小和计算资源。
模型评估
测试数据集:在训练完成后,使用测试脚本来评估模型性能。
性能指标:通过比较识别结果和真实文本标签,计算模型的准确率、召回率等指标。
优化和调优
结果分析:根据测试结果分析模型性能,识别模型的不足之处。
参数调整:调整模型参数,如学习率、优化器等。
数据增强:增加训练数据,使用数据增强技术提高模型的泛化能力。
模型结构:尝试更复杂的模型结构或改进现有模型结构。
社区资源:参考PaddleSpeech的官方文档和社区资源,获取优化建议和经验分享。
服务部署
服务化:PaddleSpeech支持将训练好的模型部署为服务,如流式ASR服务。
一键部署:使用PaddleSpeech提供的命令行工具一键启动服务。
客户端访问:通过客户端访问训练好的模型提供的服务。
3、新起之秀Wenet
主要针对工业落地应用的端到端语音识别工具包,由出门问问语音团队联合西北工业大学语音实验室共同开发并开源。Wenet 的设计目标是弥合端到端语音识别中研究和生产的鸿沟,有效地实现将ASR迁移到实际场景中。它主要聚焦于语音识别任务,而不提供各类模型方案的大而全的集合,这使得 Wenet 在保持简洁易用的同时,在语音识别正确率、实时率和延时性都有着非常出色的表现。
3.1 如何开始使用Wenet
环境准备
确保您的系统中安装了Python 3.6或更高版本,以及PyTorch 1.7或更高版本。
安装其他依赖项,如kaldi和sentencepiece。这些依赖项可能需要特定的库和配置。
获取Wenet源代码
您可以从Wenet的GitHub仓库(https://github.com/wenet-e2e/wenet)克隆或下载源代码。
安装Wenet
在获取源代码后,按照Wenet的文档中的说明进行安装。这可能涉及运行一些脚本来编译Wenet的库和可执行文件。
了解Wenet的结构
Wenet的结构包括用于特征提取、模型训练、解码等不同组件。熟悉这些组件及其交互方式对于使用Wenet非常重要。
运行示例脚本
Wenet提供了许多示例脚本,这些脚本展示了如何使用Wenet进行不同的语音识别任务。您可以从运行这些示例脚本开始学习Wenet的使用。
学习Wenet的组件
了解Wenet的不同组件,如声学模型、语言模型、解码器等,以及它们是如何交互的。
处理数据和特征提取
学习如何使用Wenet处理音频数据,包括如何进行特征提取,以及如何准备和格式化数据以供Wenet使用。
训练和调整模型
使用Wenet训练声学模型和语言模型。了解如何调整模型参数以优化性能。
解码和评估
学习如何使用Wenet的解码器进行语音识别,并评估识别结果的质量。
加入社区
Wenet有一个活跃的社区。加入邮件列表和论坛,参与讨论,获取帮助,分享经验。
4、多语言支持EspNet
一个端到端语音处理工具包,由CMU的Shinji Watanabe教授主导开发。这个工具包支持多种语音处理任务,包括语音识别、语音合成、语音翻译、语音前端分离与增强等。它使用PyTorch作为深度学习引擎,并遵循Kaldi的数据处理、特征提取/格式和recipe风格,为各种语音处理实验提供完整的设置。
4.1 如何开始使用ESPnet
数据准备:首先,你需要为每种语言准备训练数据集。ESPnet支持多种语音数据格式,如Kaldi、Librispeech、CSJ等。使用ESPnet提供的脚本将数据集转换为ESPnet可以处理的格式。
模型配置:ESPnet提供了多种配置文件以适应不同的训练需求。你可以选择适当的配置文件或创建自定义配置文件来训练特定语言的模型。
训练和推理:使用ESPnet的asr.sh脚本来训练模型。在训练完成后,使用相同的脚本进行推理。ESPnet支持在多GPU上进行训练,可以加快训练过程。
结果评估:使用ESPnet的评估工具来评估模型性能,如计算词错误率(WER)和字符错误率(CER)。
预训练模型和微调:ESPnet支持使用预训练模型进行微调。这可以在有限的数据集上提高模型性能。
多语言支持:ESPnet支持多语言语音识别。你可以为不同的语言创建不同的配置文件和数据集,然后独立训练每种语言的模型。
实验配置:ESPnet遵循Kaldi的风格,使用Bash脚本来管理实验配置。这允许研究人员轻松地定制和扩展模型,以适应各种实际应用需求。
端到端处理:ESPnet提供从声学特征提取到最终结果生成的端到端自动化处理,简化了整个语音处理流程。
性能优化:ESPnet在模型压缩和量化方面做了大量工作,以保证在低延迟下的高效运行。它采用了动态图和静态图两种模式,平衡了训练速度和推理性能。
模型兼容性:ESPnet支持多种流行的深度学习框架,如TensorFlow、PyTorch和PaddlePaddle,允许开发者根据个人喜好选择合适的平台。
社区和文档:ESPnet有一个活跃的社区和详细的文档,可以帮助用户快速上手和解决遇到的问题。
5、四种语音识别开源工具的对比
特性 | Kaldi | PaddleSpeech | WeNet | EspNet |
开发背景 | MIT和微软研究院联合开发 | 百度开发 | 出门问问语音团队和西北工业大学语音实验室联合开发 | CMU的Shinji Watanabe教授主导开发 |
主要应用领域 | 语音识别、语音合成、说话人识别、语音增强等 | 语音识别、语音合成、语音翻译、语音前端分离与增强等 | 语音识别、语音合成、语音翻译等 | 语音识别、语音合成、语音翻译、语音前端分离与增强等 |
主要编程语言 | C++ | Python | Python | Python |
深度学习引擎 | 与TensorFlow或PyTorch结合使用 | 飞桨(Paddle) | PyTorch | PyTorch |
开源许可 | 遵循Apache 2.0许可,开源且免费使用 | 遵循Apache 2.0许可,开源且免费使用 | 遵循Apache 2.0许可,开源且免费使用 | 遵循Apache 2.0许可,开源且免费使用 |
社区活跃度 | 活跃,有大量的研究人员和开发者参与 | 活跃,有800万开发者基于Paddle创建了80万个模型 | 较为活跃,有大量的研究人员和开发者参与 | 活跃,有大量的研究人员和开发者参与 |
安装复杂度 | 安装过程可能较为复杂,需要安装多个依赖项 | 安装过程相对简单,用户可以根据需要选择不同的版本进行安装 | 安装过程相对复杂,需要安装PyTorch和多个依赖项 | 安装过程相对复杂,需要安装PyTorch和多个依赖项 |
模型训练与部署 | 提供丰富的工具和组件,支持多种模型训练和部署方式 | 提供丰富的工具和组件,支持多种模型训练和部署方式 | 提供一键recipe示例,支持多种模型训练和部署方式 | 提供多种模型训练和部署方式,支持多种主流的模型架构 |
不足 | 配置和编译过程相对复杂 | 在语音识别领域的应用不够广泛; 社区和文档不如Kaldi成熟 | 较新的工具,某些方面还不够成熟 | 相比于Kaldi,ESPnet在某些方面不够成熟和稳定 |
