阅读量:0
FunASR是阿里的一个语音识别工具,比SpeechRecognition功能多安装也很简单;
官方介绍:FunASR是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR提供了便捷的脚本和教程,支持预训练好的模型的推理与微调。
网址:FunASR/README_zh.md at main · alibaba-damo-academy/FunASR · GitHub
安装直接用:pip install funasr -i https://pypi.tuna.tsinghua.edu.cn/simple
读取音频需要(我没ffmpeg):pip install torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
官网说:如果需要使用工业预训练模型,安装modelscope(可选)pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
如果按照官网的代码直接使用model名,第一次使用这个model时,会自动下载对应的model,会在C:\Users\你的用户名\.cache目录里新建modelscope文件夹,将所用到的model下载到里面;
model = AutoModel(model="paraformer-zh", vad_model="fsmn-vad", punc_model="ct-punc", # spk_model="cam++" )所用到的model会在/modelscope/hub/iic/目录里找到,可以拷贝出来使用,代码里直接指定model目录;
也可以自己去他们网站下载model拿来用:FunASR/model_zoo at main · alibaba-damo-academy/FunASR · GitHub
model直接搞出来用:

语音转文字demo:
#!/usr/bin/env python3 # coding = utf-8 """ # Project: workspace_py # File: test_funasr.py # Author: XWF # Time: 2024/4/15 16:14 """ from funasr import AutoModel print('test') model_path = 'models/modelscope/hub/iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch' vad_path = 'models/modelscope/hub/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch' punc_path = 'models/modelscope/hub/iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch' model = AutoModel(model=model_path, # model_revision="v2.0.4", vad_model=vad_path, # vad_model_revision="v2.0.4", vad_kwargs={}, punc_model=punc_path, # punc_model_revision="v2.0.4", punc_kwargs={}, # device='cuda:0', device='cpu', ncpu=4, # spk_model="cam++", spk_model_revision="v2.0.4", disable_log=True, disable_pbar=True ) res = model.generate(input='test_24000_16.wav', batch_size_s=300) print(res) print(type(res), type(res[0]), res[0].get('text')) # res = model.generate(input='test_8000_16.pcm', batch_size_s=300) # print(res) # print(res[0].get('text')) with open('test_24000_16.wav', 'rb') as f: wav_data = f.read() res = model.generate(input=wav_data,batch_size_s=1) print(res) with open('test_8000_16.pcm', 'rb') as f: pcm_data = f.read() res = model.generate(input=pcm_data, batch_size_s=1) print(res)运行结果:
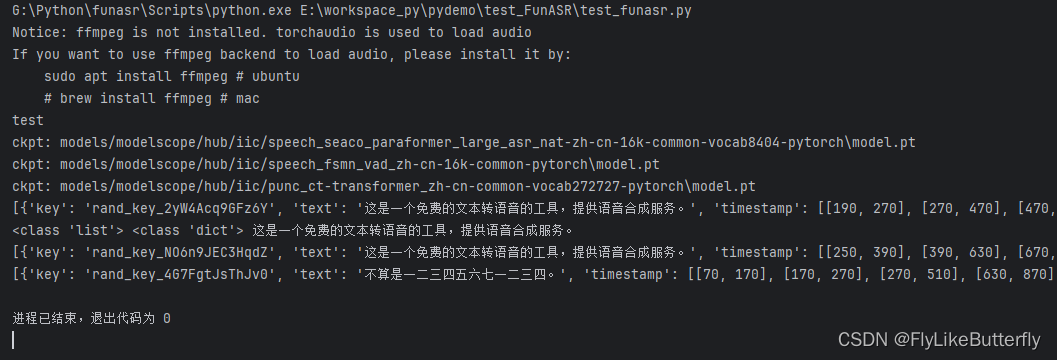
弄到model后直接使用model目录指定model就行,不用再下载了,也不用指定版本;
也可以使用各个model_version指定版本,下载的时候会使用指定的版本下载;
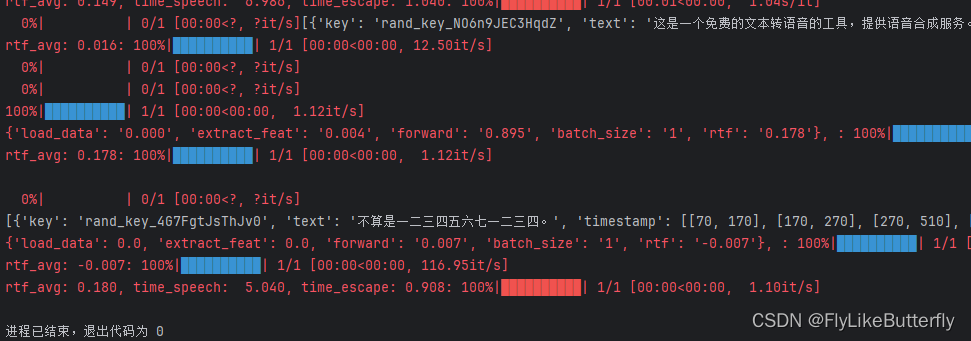
在AutoModel里使用disable_log=True和disable_pbar=True可以关闭那些红红的打印日志,不然满屏幕就会这样:
但是不知道input='test_8000_16.pcm'为啥老是找不到文件报错,跑不通,设置了fs好像也不行;
官网还有许多其他的功能可以去看看;
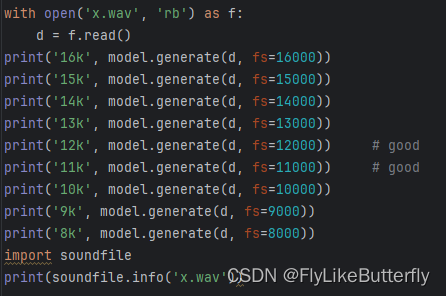
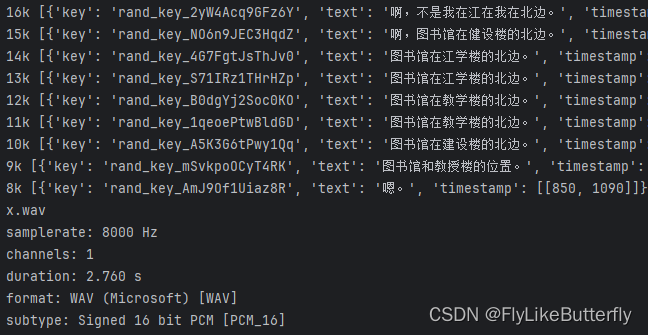
关于input直接用wav文件正确,但用wav的bytes就识别不对的问题,我去GitHup提问有人告诉我直接使用wav文件,会识别wav头重新调整采样率等信息,而使用bytes不会重新采样,所以使用非16k的会识别错误,得到的方法大概就是换用8k的模型,或者设置采样率参数;
但是设置的fs参数可能需要自己调,好像也不一定就直接是采样率,可能跟别的有关;