
阅读量:0
一、 介绍
监控系统是整个运维环节,乃至整个产品生命周期中最重要的一环,事前及时预警发现故障,事后提供翔实的数据用于追查定位问题。
监控系统作为一个成熟的运维产品,业界有很多开源的实现可供选择。
当公司刚刚起步,业务规模较小,运维团队也刚刚建立的初期,选择一款开源的监控系统,是一个省时省力,效率最高的方案。
之后,随着业务规模的持续快速增长,监控的对象也越来越多,越来越复杂,监控系统的使用对象也从最初少数的几个 SRE,扩大为更多的 DEVS,SRE。
这时候,监控系统的容量和用户的“使用效率”成了最为突出的问题。
监控系统业界有很多杰出的开源监控系统。我们在早期,一直在用 zabbix,不过随着业务的快速发展,以及互联网公司特有的一些需求,现有的开源的监控系统在性能、扩展性、和用户的使用效率方面,已经无法支撑了。
因此,我们在过去的一年里,从互联网公司的一些需求出发,从各位 SRE、SA、DEVS 的使用经验和反馈出发,结合业界的一些大的互联网公司做监控,用监控的一些思考出发,设计开发了小米的监控系统:open-falcon。
二、 特点
2.1、强大灵活的数据采集
自动发现,支持 falcon-agent、snmp、支持用户主动 push、用户自定义插件支持、opentsdb data model like(timestamp、endpoint、metric、key-value tags)
2.2、水平扩展能力
支持每个周期上亿次的数据采集、告警判定、历史数据存储和查询
2.3、高效率的告警策略管理
高效的 portal、支持策略模板、模板继承和覆盖、多种告警方式、支持callback 调用
2.4、人性化的告警设置
最大告警次数、告警级别、告警恢复通知、告警暂停、不同时段不同阈值、支持维护周期
2.5、高效率的 graph 组件
单机支撑 200 万 metric 的上报、归档、存储(周期为 1 分钟)
2.6、高效的历史数据 query 组件
采用 rrdtool 的数据归档策略,秒级返回上百个 metric 一年的历史数据
2.7、dashboard
多维度的数据展示,用户自定义 Screen
2.8、高可用
整个系统无核心单点,易运维,易部署,可水平扩展
2.9、开发语言
整个系统的后端,全部 golang 编写,portal 和 dashboard 使用 python 编写。
三、 架构
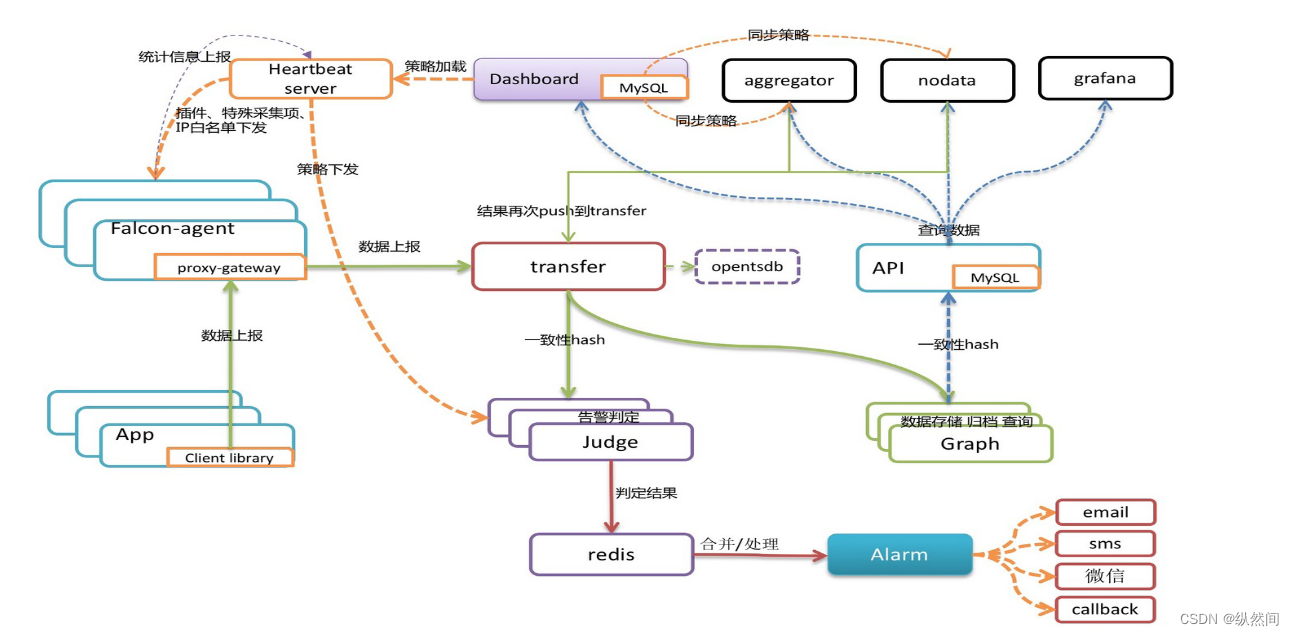
每台服务器,都有安装 falcon-agent,falcon-agent 是一个 golang 开发的 daemon 程序,用于自发现的采集单机的各种数据和指标,这些指标包括不限于以下几个方面,共计 200 多项指标。
CPU 相关
磁盘相关
IO
Load
内存相关
网络相关
端口存活、进程存活
ntp offset(插件)
某个进程资源消耗(插件)
netstat、ss 等相关统计项采集
机器内核配置参数只要安装了 falcon-agent 的机器,就会自动开始采集各项指标,主动上报,不需要用户在server 做任何配置(这和 zabbix 有很大的不同),这样做的好处,就是用户维护方便,覆盖率高。
当然这样做也会 server 端造成较大的压力,不过 open-falcon 的服务端组件单机性能足够高,同时都可以水平扩展,所以自动多采集足够多的数据,反而是一件好事情,对于 SRE和 DEV 来讲,事后追查问题,不再是难题。
另外,falcon-agent 提供了一个 proxy-gateway,用户可以方便的通过 http 接口,push 数据到本
机的 gateway,gateway 会帮忙高效率的转发到 server 端。
四、 数据模型
Data Model 是否强大,是否灵活,对于监控系统用户的“使用效率”至关重要。比如以zabbix 为例,上报的数据为 hostname(或者 ip)、metric,那么用户添加告警策略、管理告警策略的时候,就只能以这两个维度进行。
举一个最常见的场景:
hostA 的磁盘空间,小于 5%,就告警。一般的服务器上,都会有两个主要的分区,根分区和 home 分区,在 zabbix 里面,就得加两条规则;如果是 hadoop 的机器,一般还会有十几块的数据盘,还得再加 10 多条规则,这样就会痛苦,不幸福,不利于自动化(当然 zabbix 可
以通过配置一些自动发现策略来搞定这个,不过比较麻烦)。
五、 数据收集
transfer,接收客户端发送的数据,做一些数据规整,检查之后,转发到多个后端系统去
处理。在转发到每个后端业务系统的时候,transfer 会根据一致性 hash 算法,进行数据分片,来达到后端业务系统的水平扩展。
transfer 提供 jsonRpc 接口和 telnet 接口两种方式,transfer 自身是无状态的,挂掉一台或
者多台不会有任何影响,同时 transfer 性能很高,每分钟可以转发超过 500 万条数据。
transfer 目前支持的业务后端,有三种,judge、graph、opentsdb。judge 是我们开发的高性能告警判定组件,graph 是我们开发的高性能数据存储、归档、查询组件,opentsdb 是开源的时间序列数据存储服务。可以通过 transfer 的配置文件来开启。
transfer 的数据来源,一般有三种:
1、falcon-agent 采集的基础监控数据
2、falcon-agent 执行用户自定义的插件返回的数据
3、client library:线上的业务系统,都嵌入使用了统一的 perfcounter.jar,对于业务系统中
每个 RPC 接口的 qps、latency 都会主动采集并上报
说 明 : 上 面 这 三 种 数 据 , 都 会 先 发 送 给 本 机 的 proxy-gateway , 再 由 gateway 转 发 给transfer。
基础监控是指只要是个机器(或容器)就能加的监控,比如 cpu mem net io disk 等,这些监控采集的方式固定,不需要配置,也不需要用户提供额外参数指定,只要 agent 跑起来就可以直接采集上报上去; 非基础监控则相反,比如端口监控,你不给我端口号就不行,不然我上报所有 65535 个端口的监听状态你也用不了,这类监控需要用户配置后才会开始采集上报的监控(包括类似于端口监控的配置触发类监控,以及类似于 mysql 的插件脚本类监控),一般就不算基础监控的范畴了。
六、 报警
报警判定,是由 judge 组件来完成。用户在 web portal 来配置相关的报警策略,存储在
MySQL 中。heartbeat server 会定期加载 MySQL 中的内容。judge 也会定期和 heartbeat server 保持沟通,来获取相关的报警策略。
heartbeat sever 不仅仅是单纯的加载 MySQL 中的内容,根据模板继承、模板项覆盖、报警
动作覆盖、模板和 hostGroup 绑定,计算出最终关联到每个 endpoint 的告警策略,提供给
judge 组件来使用。
transfer 转发到 judge 的每条数据,都会触发相关策略的判定,来决定是否满足报警条件 ,
如果满足条件,则会发送给 alarm,alarm 再以邮件、短信、米聊等形式通知相关用户,也可以执行用户预先配置好的 callback 地址。
用户可以很灵活的来配置告警判定策略,比如连续 n 次都满足条件、连续 n 次的最大值满
足条件、不同的时间段不同的阈值、如果处于维护周期内则忽略 等等。
另外也支持突升突降类的判定和告警。
七、 API
到这里,数据已经成功的存储在了 graph 里。如何快速的读出来呢,读过去 1 小时的,过
去 1 天的,过去一月的,过去一年的,都需要在 1 秒之内返回。
这些都是靠 graph 和 API 组件来实现的,transfer 会将数据往 graph 组件转发一份,graph
收到数据以后,会以 rrdtool 的数据归档方式来存储,同时提供查询 RPC 接口。
API 面向终端用户,收到查询请求后,会去多个 graph 里面,查询不同 metric 的数据,汇
总后统一返回给用户。
八、 面板
九、 存储
对于监控系统来讲,历史数据的存储和高效率查询,永远是个很难的问题!数据量大:目前我们的监控系统,每个周期,大概有 2000 万次数据上报(上报周期为 1
分钟和 5 分钟两种,各占 50%),一天 24 小时里,从来不会有业务低峰,不管是白天和黑夜,每个周期,总会有那么多的数据要更新。
写操作多:一般的业务系统,通常都是读多写少,可以方便的使用各种缓存技术,再者
各类数据库,对于查询操作的处理效率远远高于写操作。而监控系统恰恰相反,写操作远远
高于读。每个周期几千万次的更新操作,对于常用数据库(MySQL、postgresql、mongodb)都是无法完成的。
高效率的查:我们说监控系统读操作少,是说相对写入来讲。监控系统本身对于读的要
求很高,用户经常会有查询上百个 meitric,在过去一天、一周、一月、一年的数据。如何在 1 秒内返回给用户并绘图,这是一个不小的挑战。
open-falcon 在这块,投入了较大的精力。我们把数据按照用途分成两类,一类是用来绘
图的,一类是用户做数据挖掘的。
对于绘图的数据来讲,查询要快是关键,同时不能丢失信息量。对于用户要查询 100 个
metric,在过去一年里的数据时,数据量本身就在那里了,很难 1 秒之类能返回,另外就算返\回了,前端也无法渲染这么多的数据,还得采样,造成很多无谓的消耗和浪费。我们参考
rrdtool 的理念,在数据每次存入的时候,会自动进行采样、归档。我们的归档策略如下,历史数据保存 5 年。同时为了不丢失信息量,数据归档的时候,会按照平均值采样、最大值采样、最小值采样存三份。
十、安装
10.1 环境准备
10.1.1 Redis安装
大家可以 yum 安装,也可以下载源码安装
yum install -y redis
修改配置 redis.conf
vi /etc/redis.conf

启动 redis:
redis-server &10.1.2 安装MySQL
yum install -y mysql-server
启动 mysql:
service mysqld start
查看 mysql 状态:
service mysqld status
10.1.3 初始化 mysql 数据库表
初始化 mysql 数据库表数据默认没有设置密码,执行的时候出现输入密码,直接回车。
cd /tmp/ && git clone https://github.com/open-falcon/falcon-plus.git cd /tmp/falcon-plus/scripts/mysql/db_schema/ mysql -h 127.0.0.1 -u root -p < 1_uic-db-schema.sql mysql -h 127.0.0.1 -u root -p < 2_portal-db-schema.sql mysql -h 127.0.0.1 -u root -p < 3_dashboard-db-schema.sql mysql -h 127.0.0.1 -u root -p < 4_graph-db-schema.sql mysql -h 127.0.0.1 -u root -p < 5_alarms-db-schema.sql rm -rf /tmp/falcon-plus/设置 mysql 的 root 用户密码:
mysql –u root查看 mysql 用户和密码:
select user,host,password from mysql.user;
发现查询密码都是空,然后开始设置 root 的密码为 bigdata
set password for root@localhost=password('bigdata');退出:
mysql>exit10.1.4 下载编译后的二进制包
cd /data/program/software wget https://github.com/open-falcon/falcon-plus/releases/download/v0.2.1/open-falcon-v0.2.1.tar.gz10.2 后端服务安装并启动
10.2.1 创建工作目录
export FALCON_HOME=/home/work export WORKSPACE=$FALCON_HOME/open-falcon mkdir -p $WORKSPACE10.2.2 解压二进制包
cd /data/program/software tar -xzvf open-falcon-v0.2.1.tar.gz -C $WORKSPACE10.2.3 配置数据库账号和密码
cd $WORKSPACE grep -Ilr 3306 ./ | xargs -n1 -- sed -i 's/root:/root:bigdata/g' # 注意 root:后面默认密码为空,所以只是看到了 root:10.2.4 启动
查看目录下包括 Open-Falcon 的所有组件,我们先默认全部启动,之后我们一个一个讲解如何
分布式部署以及启动

cd $WORKSPACE ./open-falcon start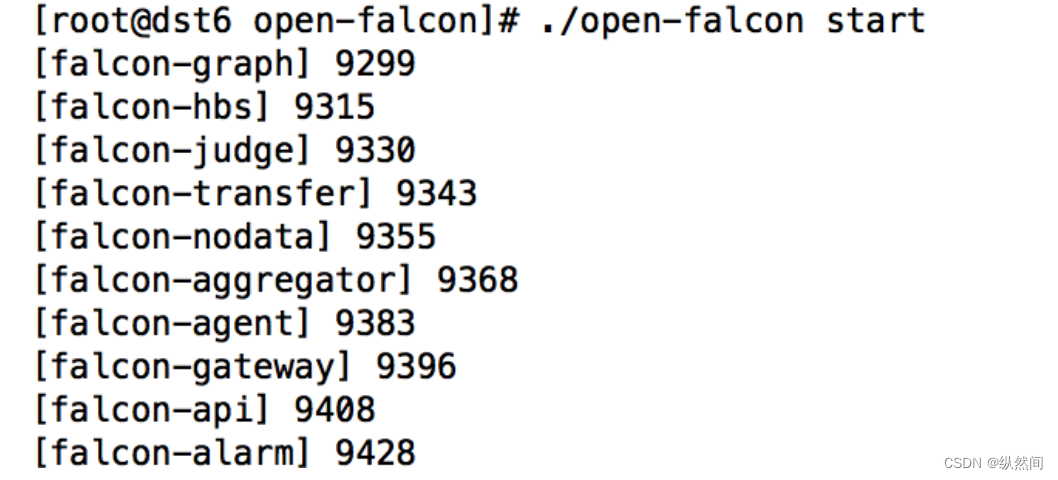
10.2.4 检查所有模块的启动状况
./open-falcon check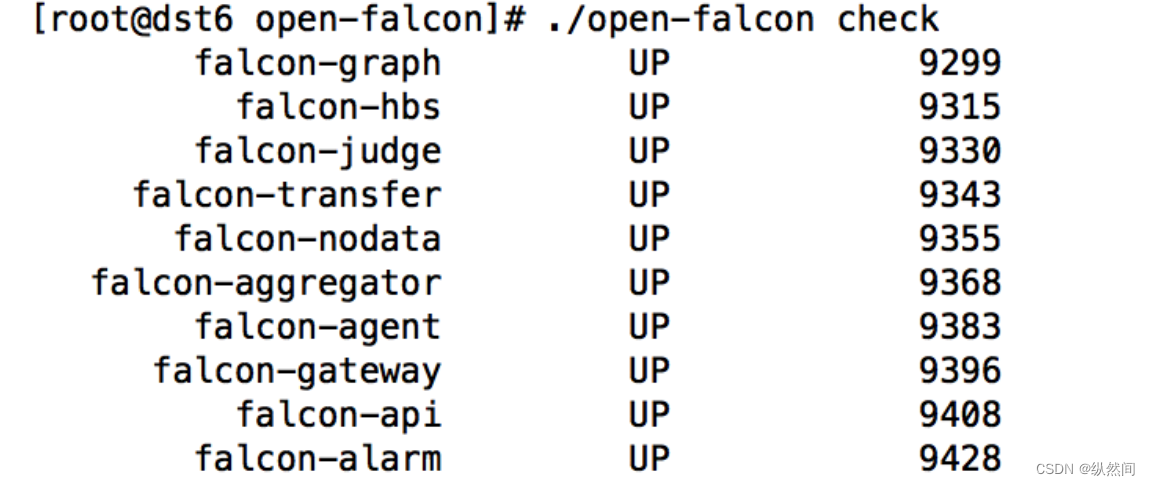
10.2.5 更多命令行工具
./open-falcon [start|stop|restart|check|monitor|reload] module ./open-falcon start agent ./open-falcon check falcon-graph UP 53007 falcon-hbs UP 53014 falcon-judge UP 53020 falcon-transfer UP 53026 falcon-nodata UP 53032 falcon-aggregator UP 53038 falcon-agent UP 53044 falcon-gateway UP 53050 falcon-api UP 53056 falcon-alarm UP 53063 For debugging #You can check $WorkDir/$moduleName/log/logs/xxx.log10.3 前端安装
10.3.1 创建工作目录
这一步在创建后端服务的时候已经建立好,所以不需要再进行操作。
export HOME=/home/work export WORKSPACE=$HOME/open-falcon mkdir -p $WORKSPACE cd $WORKSPACE10.3.2 克隆前端组件代码
cd $WORKSPACE git clone https://github.com/open-falcon/dashboard.git10.3.3 安装依赖包
yum install -y python-virtualenv yum install -y python-devel yum install -y openldap-devel yum install -y mysql-devel yum groupinstall "Development tools" cd $WORKSPACE/dashboard/ virtualenv ./env ./env/bin/pip install -r pip_requirements.txt -i https://pypi.douban.com/simple # 注意:如果执行上面有问题,就直接执行./env/bin/pip install -r pip_requirements.txt10.3.4 修改配置
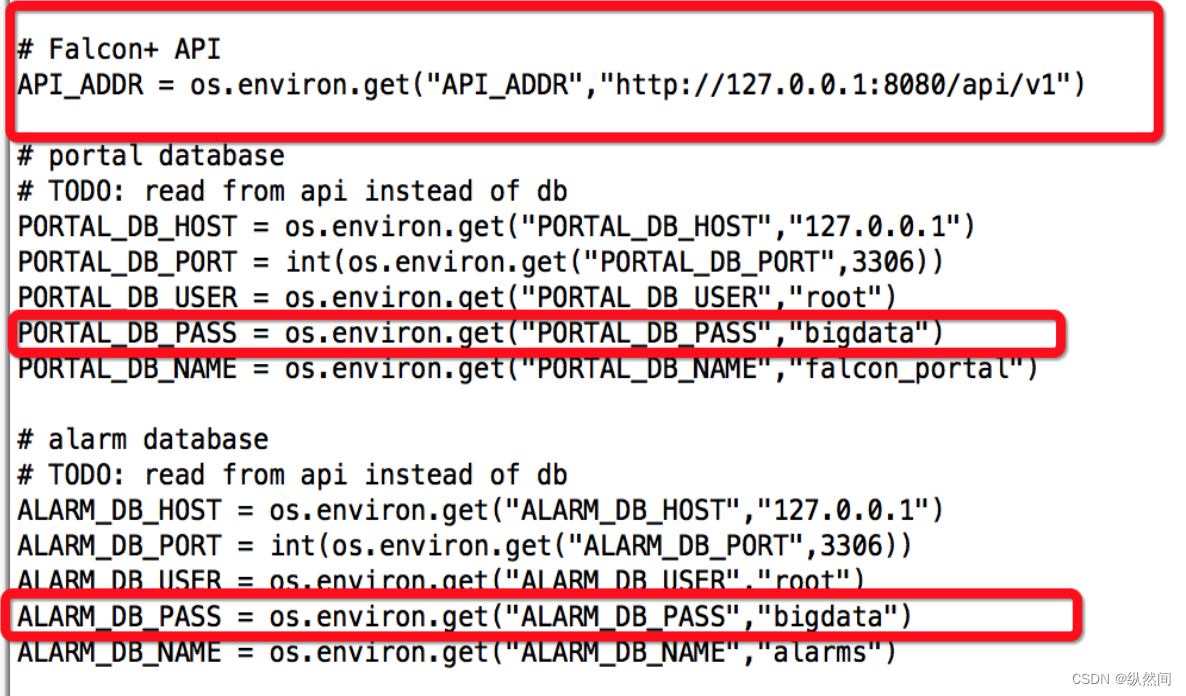
dashboard 的配置文件为: 'rrd/config.py',请根据实际情况修改
## API_ADDR 表示后端 api 组件的地址
API_ADDR = "http://127.0.0.1:8080/api/v1"
## 根据实际情况,修改 PORTAL_DB_*, 默认用户名为 root,默认密码为""
## 根据实际情况,修改 ALARM_DB_*, 默认用户名为 root,默认密码为""
10.3.5 启动
bash control start open http://127.0.0.1:8081 in your browser. # 停止 # bash control stop
10.4 安装-Agent
10.4.1 Agent 介绍
agent 用于采集机器负载监控指标,比如 cpu.idle、load.1min、disk.io.util 等等,每隔 60 秒 push给 Transfer。
agent 与 Transfer 建立了长连接,数据发送速度比较快,agent 提供了一个 http 接口/v1/push 用于接收用户手工 push 的一些数据,然后通过长连接迅速转发给Transfer。
10.4.2 Agent 部署
部署agent 需要部署到所有要被监控的机器上,比如公司有 10 万台机器,那就要部署 10 万个agent。
agent 本身资源消耗很少,不用担心。
首先找到之前后端服务的解压目录:
/home/work/open-falcon/拷贝 agent 到需要监控的服务器上面
scp -r agent/ root@dst1:/home/work/open-falcon拷贝 open-falcon 到需要监控的服务器上面
scp -r open-falcon root@dst1:/home/work/open-falcon
修改配置文件:
配置文件必须叫 cfg.json,如下参照修改
{ "debug": true, # 控制一些 debug 信息的输出,生产环境通常设置为 false "hostname": "", # agent 采集了数据发给 transfer,endpoint 就设置为了 hostname,默认通过 `hostname`获取,如果配置中配置了 hostname,就用配置中的 "ip": "", # agent 与 hbs 心跳的时候会把自己的 ip 地址发给 hbs,agent 会自动探测本机 ip,如果不想让 agent 自动探测,可以手工修改该配置 "plugin": { "enabled": false, # 默认不开启插件机制 "dir": "./plugin", # 把放置插件脚本的 git repo clone 到这个目录 "git": "https://github.com/open-falcon/plugin.git", # 放置插件脚本的 git repo 地址 "logs": "./logs" # 插件执行的 log,如果插件执行有问题,可以去这个目录看 log }, "heartbeat": { "enabled": true, # 此处 enabled 要设置为 true "addr": "127.0.0.1:6030", # hbs 的地址,端口是 hbs 的 rpc 端口 "interval": 60, # 心跳周期,单位是秒 "timeout": 1000 # 连接 hbs 的超时时间,单位是毫秒 }, "transfer": { "enabled": true, "addrs": [ "127.0.0.1:18433" ], # transfer 的地址,端口是 transfer 的 rpc 端口, 可以支持写多个 transfer 的地址,agent 会保 证 HA "interval": 60, # 采集周期,单位是秒,即 agent 一分钟采集一次数据发给 transfer "timeout": 1000 # 连接 transfer 的超时时间,单位是毫秒 }, "http": { "enabled": true, # 是否要监听 http 端口 "listen": ":1988", "backdoor": false }, "collector": { "ifacePrefix": ["eth", "em"], # 默认配置只会采集网卡名称前缀是 eth、em 的网卡流量,配置为空 就会采集所有的,lo 的也会采集。可以从/proc/net/dev 看到各个网卡的流量信息 "mountPoint": [] }, "default_tags": { }, "ignore": { # 默认采集了 200 多个 metric,可以通过 ignore 设置为不采集 "cpu.busy": true, "df.bytes.free": true, "df.bytes.total": true, "df.bytes.used": true, "df.bytes.used.percent": true, "df.inodes.total": true, "df.inodes.free": true, "df.inodes.used": true, "df.inodes.used.percent": true, "mem.memtotal": true, "mem.memused": true, "mem.memused.percent": true, "mem.memfree": true, "mem.swaptotal": true, "mem.swapused": true, "mem.swapfree": true } }10.4.3 启动
./open-falcon start agent 启动进程
./open-falcon stop agent 停止进程
./open-falcon monitor agent 查看日志
看 var 目录下的 log 是否正常,或者浏览器访问其 1988 端口。另外 agent 提供了一个--check 参数,可以检查 agent 是否可以正常跑在当前机器上
./falcon-agent --check
进入监控界面查看:
10.5 安装数据转发服务-Transfer
10.5.1 介绍
transfer 是数据转发服务。它接收 agent 上报的数据,然后按照哈希规则进行数据分片、并将分片后的数据分别 push 给 graph&judge 等组件。
10.5.2 服务部署
服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
# 修改配置, 配置项含义见下文
vim cfg.json
# 启动服务 ./open-falcon start transfer # 校验服务,这里假定服务开启了 6060 的 http 监听端口。检验结果为 ok 表明服务正常启动。 curl -s "127.0.0.1:6060/health" # 停止服务 ./open-falcon stop transfer # 查看日志 ./open-falcon monitor transfer10.5.3 配置说明
配置文件默认为./cfg.json
debug: true/false, 如果为 true,日志中会打印 debug 信息 minStep: 30, 允许上报的数据最小间隔,默认为 30 秒 http - enabled: true/false, 表示是否开启该 http 端口,该端口为控制端口,主要用来对 transfer 发送控 制命令、统计命令、debug 命令等 - listen: 表示监听的 http 端口 rpc - enabled: true/false, 表示是否开启该 jsonrpc 数据接收端口, Agent 发送数据使用的就是该端口 - listen: 表示监听的 http 端口 socket #即将被废弃,请避免使用 - enabled: true/false, 表示是否开启该 telnet 方式的数据接收端口,这是为了方便用户一行行的发送 数据给 transfer - listen: 表示监听的 http 端口 judge - enabled: true/false, 表示是否开启向 judge 发送数据 - batch: 数据转发的批量大小,可以加快发送速度,建议保持默认值 - connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认 - callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认 - pingMethod: 后端提供的 ping 接口,用来探测连接是否可用,必须保持默认 - maxConns: 连接池相关配置,最大连接数,建议保持默认 - maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认 - replicas: 这是一致性 hash 算法需要的节点副本数量,建议不要变更,保持默认即可 - cluster: key-value 形式的字典,表示后端的 judge 列表,其中 key 代表后端 judge 名字,value 代表 的是具体的 ip:port graph - enabled: true/false, 表示是否开启向 graph 发送数据 - batch: 数据转发的批量大小,可以加快发送速度,建议保持默认值 - connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认 - callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认 - pingMethod: 后端提供的 ping 接口,用来探测连接是否可用,必须保持默认 - maxConns: 连接池相关配置,最大连接数,建议保持默认 - maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认 - replicas: 这是一致性 hash 算法需要的节点副本数量,建议不要变更,保持默认即可 - cluster: key-value 形式的字典,表示后端的 graph 列表,其中 key 代表后端 graph 名字,value 代表 的是具体的 ip:port(多个地址用逗号隔开, transfer 会将同一份数据发送至各个地址,利用这个特性可以实现数据 的多重备份) tsdb - enabled: true/false, 表示是否开启向 open tsdb 发送数据 - batch: 数据转发的批量大小,可以加快发送速度 - connTimeout: 单位是毫秒,与后端建立连接的超时时间,可以根据网络质量微调,建议保持默认 - callTimeout: 单位是毫秒,发送数据给后端的超时时间,可以根据网络质量微调,建议保持默认 - maxConns: 连接池相关配置,最大连接数,建议保持默认 - maxIdle: 连接池相关配置,最大空闲连接数,建议保持默认 - retry: 连接后端的重试次数和发送数据的重试次数 - address: tsdb 地址或者 tsdb 集群 vip 地址, 通过 tcp 连接 tsdb.部署完成 transfer 组件后,请修改 agent 的配置,使其指向正确的 transfer 地址。在安装完 graph
和 judge 后,请修改 transfer 的相应配置、使其能够正确寻址到这两个组件。
10.6 安装绘图数据的组件- Graph
10.6.1 介绍
graph 是存储绘图数据的组件。graph 组件 接收 transfer 组件推送上来的监控数据,同时处理api 组件的查询请求、返回绘图数据。
10.6.2 服务部署
服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。(通知之前的一样,拷贝需要的包到指定的服务器)
# 修改配置, 配置项含义见下文 vim cfg.json # 启动服务 ./open-falcon start graph # 停止服务 ./open-falcon stop graph # 查看日志 ./open-falcon monitor graph10.6.3 配置说明
配置文件默认为./cfg.json,配置如下:
{ "debug": false, //true or false, 是否开启 debug 日志 "http": { "enabled": true, //true or false, 表示是否开启该 http 端口,该端口为控制端口,主要用来对 graph 发送控制命令、统计命令、debug 命令 "listen": "0.0.0.0:6071" //表示监听的 http 端口 }, "rpc": { "enabled": true, //true or false, 表示是否开启该 rpc 端口,该端口为数据接收端口 "listen": "0.0.0.0:6070" //表示监听的 rpc 端口 }, "rrd": { "storage": "./data/6070" // 历史数据的文件存储路径(如有必要,请修改为合适的路径) }, "db": { "dsn": "root:@tcp(127.0.0.1:3306)/graph?loc=Local&parseTime=true", //MySQL 的连接信息, 默认用户名是 root,密码为空,host 为 127.0.0.1,database 为 graph(如有必要,请修改) "maxIdle": 4 //MySQL 连接池配置,连接池允许的最大连接数,保持默认即可 }, "callTimeout": 5000, //RPC 调用超时时间,单位 ms "migrate": { //扩容 graph 时历史数据自动迁移 "enabled": false, //true or false, 表示 graph 是否处于数据迁移状态 "concurrency": 2, //数据迁移时的并发连接数,建议保持默认 "replicas": 500, //这是一致性 hash 算法需要的节点副本数量,建议不要变更,保持默认即可(必须和 transfer 的配置中保持一致) "cluster": { //未扩容前老的 graph 实例列表 "graph-00" : "127.0.0.1:6070" } } }10.6.4 备注

如果上图红框中出现同一台服务器的不同名字的配置,则进入数据库,进行如下操作:
进入数据库:mysql –u root –p
查看所有数据库:show databses;
选择数据库:use graph;
查看表:show tables;
查询表:select * from endpoint;
删除不需要的数据:delete from endpoint where id=153;
如下可以不操作:
可以一起删除 falcon_portal 库中的 host 表中的无用数据。
10.7 安装查询组件-API
10.7.1 介绍
api 组件,提供统一的 restAPI 操作接口。比如:api 组件接收查询请求,根据一致性哈希算法去相应的 graph 实例查询不同 metric 的数据,然后汇总拿到的数据,最后统一返回给用户。
10.7.2 服务部署
服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
# 修改配置, 配置项含义见下文, 注意 graph 集群的配置 vim cfg.json # 启动服务 ./open-falcon start api # 停止服务 ./open-falcon stop api # 查看日志 ./open-falcon monitor api10.7.3 服务说明
注意: 请确保 graphs 的内容与 transfer 的配置完全一致
{ "log_level": "debug", "db": { //数据库相关的连接配置信息 "faclon_portal": "root:@tcp(127.0.0.1:3306)/falcon_portal? charset=utf8&parseTime=True&loc=Local", "graph": "root:@tcp(127.0.0.1:3306)/graph?charset=utf8&parseTime=True&loc=Local", "uic": "root:@tcp(127.0.0.1:3306)/uic?charset=utf8&parseTime=True&loc=Local", "dashboard": "root:@tcp(127.0.0.1:3306)/dashboard? charset=utf8&parseTime=True&loc=Local", "alarms": "root:@tcp(127.0.0.1:3306)/alarms?charset=utf8&parseTime=True&loc=Local", "db_bug": true }, "graphs": { // graph 模块的部署列表信息 "cluster": { "graph-00": "127.0.0.1:6070" }, "max_conns": 100, "max_idle": 100, "conn_timeout": 1000, "call_timeout": 5000, "numberOfReplicas": 500 }, "metric_list_file": "./api/data/metric", "web_port": ":8080", // http 监听端口 "access_control": true, // 如果设置为 false,那么任何用户都可以具备管理员权限 "salt": "pleaseinputwhichyouareusingnow", //数据库加密密码的时候的 salt "skip_auth": false, //如果设置为 true,那么访问 api 就不需要经过认证 "default_token": "default-token-used-in-server-side", //用于服务端各模块间的访问授权 "gen_doc": false, "gen_doc_path": "doc/module.html" }备注:
部署完成 api 组件后,请修改 dashboard 组件的配置、使其能够正确寻址到 api 组件。
请确保 api 组件的 graph 列表 与 transfer 的配置 一致。
十一 心跳服务- HBS
11.1 介绍
心跳服务器,公司所有 agent 都会连到 HBS,每分钟发一次心跳请求。
Portal 的数据库中有一个 host 表,维护了公司所有机器的信息,比如 hostname、ip 等等。这个表中的数据通常是从公司 CMDB 中同步过来的。但是有些规模小一些的公司是没有 CMDB 的那此时就需要手工往 host 表中录入数据,这很麻烦。于是我们赋予了 HBS 第一个功能:agent 发送心跳信息给 HBS 的时候,会把 hostname、ip、agent version、plugin version 等信息告诉HBS,HBS 负责更新 host 表。
falcon-agent 有一个很大的特点,就是自发现,不用配置它应该采集什么数据,就自动去采
集了。比如 cpu、内存、磁盘、网卡流量等等都会自动采集。我们除了要采集这些基础信息之外,还需要做端口存活监控和进程数监控。那我们是否也要自动采集监听的端口和各个进程数目呢?
我们没有这么做,因为这个数据量比较大,汇报上去之后用户大部分都是不关心的,太浪费。
于是我们换了一个方式,只采集用户配置的。比如用户配置了对某个机器 80 端口的监控,我们才会去采集这个机器 80 端口的存活性。那 agent 如何知道自己应该采集哪些端口和进程呢?向HBS 要,HBS 去读取 Portal 的数据库,返回给 agent。之后我们会介绍一个用于判断报警的组件:Judge,Judge 需要获取所有的报警策略,让 Judge 去读取 Portal 的 DB 么?不太好。因为 Judge 的实例数目比较多,如果公司有几十万机器,Judge 实例数目可能会是几百个,几百个 Judge 实例去访问 Portal 数据库,也是一个比较大的压力。
既然HBS 无论如何都要访问 Portal 的数据库了,那就让 HBS 去获取所有的报警策略缓存在内存里,然后 Judge 去向 HBS 请求。这样一来,对 Portal DB 的压力就会大大减小。
11.2 配置说明
{ "debug": true, "database": "root:password@tcp(127.0.0.1:3306)/falcon_portal?loc=Local&parseTime=true", # Portal 的数据库地址 "hosts": "", # portal 数据库中有个 host 表,如果表中数据是从其他系统同步过来的,此处配置为 sync, 否则就维持默认,留空即可 "maxIdle": 100, "listen": ":6030", # hbs 监听的 rpc 地址 "trustable": [""], "http": { "enabled": true, "listen": "0.0.0.0:6031" # hbs 监听的 http 地址 } }11.3 进程管理
# 启动 ./open-falcon start hbs # 停止 ./open-falcon stop hbs # 查看日志 ./open-falcon monitor hbs11.4 说明
如果你先部署了 agent,后部署的 hbs,那咱们部署完 hbs 之后需要回去修改 agent 的配置,把agent 配置中的 heartbeat 部分 enabled 设置为 true,addr 设置为 hbs 的 rpc 地址。
如果 hbs 的配置文件维持默认,rpc 端口就是 6030,http 端口是 6031,agent 中应该配置为 hbs 的 rpc 端口。
十二 告警判断-Judge
11.1 介绍
Judge 用于告警判断,agent 将数据 push 给 Transfer,Transfer 不但会转发给 Graph 组件来绘图还会转发给 Judge 用于判断是否触发告警。
因为监控系统数据量比较大,一台机器显然是搞不定的,所以必须要有个数据分片方案。
Transfer 通过一致性哈希来分片,每个 Judge 就只需要处理一小部分数据就可以了。所以判断告警的功能不能放在直接的数据接收端:Transfer,而应该放到 Transfer 后面的组件里。
12.2 配置说明
Judge 监听了一个 http 端口,提供了一个 http 接口:/count,访问之,可以得悉当前 Judge 实例处理了多少数据量。推荐的做法是一个 Judge 实例处理 50 万~100 万数据,用个5G~10G 内存,如果所用物理机内存比较大,比如有 128G,可以在一个物理机上部署多个 Judge 实例。
配置文件必须叫 cfg.json:
{ "debug": true, "debugHost": "nil", "remain": 11, "http": { "enabled": true, "listen": "0.0.0.0:6081" }, "rpc": { "enabled": true, "listen": "0.0.0.0:6080" }, "hbs": { "servers": ["127.0.0.1:6030"], # hbs 最好放到 lvs vip 后面,所以此处最好配置为 vip:port "timeout": 300, "interval": 60 }, "alarm": { "enabled": true, "minInterval": 300, # 连续两个报警之间至少相隔的秒数,维持默认即可 "queuePattern": "event:p%v", "redis": { "dsn": "127.0.0.1:6379", # 与 alarm、sender 使用一个 redis "maxIdle": 5, "connTimeout": 5000, "readTimeout": 5000, "writeTimeout": 5000 } } }remain 这个配置详细解释一下: remain 指定了 judge 内存中针对某个数据存多少个点,比如
host01 这个机器的 cpu.idle 的值在内存中最多存多少个,配置报警的时候比如 all(#3),这个#后
面的数字不能超过 remain-1,一般维持默认就够用了。
12.3 进程管理
# 启动 ./open-falcon start judge # 停止 ./open-falcon stop judge # 查看日志 ./open-falcon monitor judge十三 告警处理-Alarm
13.1 介绍
alarm 模块是处理报警 event 的,judge 产生的报警 event 写入 redis,alarm 从 redis 读取处理,并进行不同渠道的发送。
报警 event 的处理逻辑并非仅仅是发邮件、发短信这么简单。为了能够自动化对 event 做处理,alarm 需要支持在产生 event 的时候回调用户提供的接口;有的时候报警短信、邮件太多,对于优先级比较低的报警,希望做报警合并,这些逻辑都是在 alarm 中做的。
我们在配置报警策略的时候配置了报警级别,比如 P0/P1/P2 等等,每个及别的报警都会对
应不同的 redis 队列 alarm 去读取这个数据的时候我们希望先读取 P0 的数据,再读取 P1 的数据,最后读取 P5 的数据,因为我们希望先处理优先级高的。于是:用了 redis 的 brpop 指令。
已经发送的告警信息,alarm 会写入 MySQL 中保存,这样用户就可以在 dashboard 中查阅历史报警,同时针对同一个策略发出的多条报警,在 MySQL 存储的时候,会聚类;历史报警保存的周期,是可配置的,默认为 7 天。
13.2 部署说明
alarm 是个单点。对于未恢复的告警是放到 alarm 的内存中的,alarm 还需要做报警合并,故而alarm 只能部署一个实例。需要对 alarm 的存活做好监控。
配置文件必须叫 cfg.json:
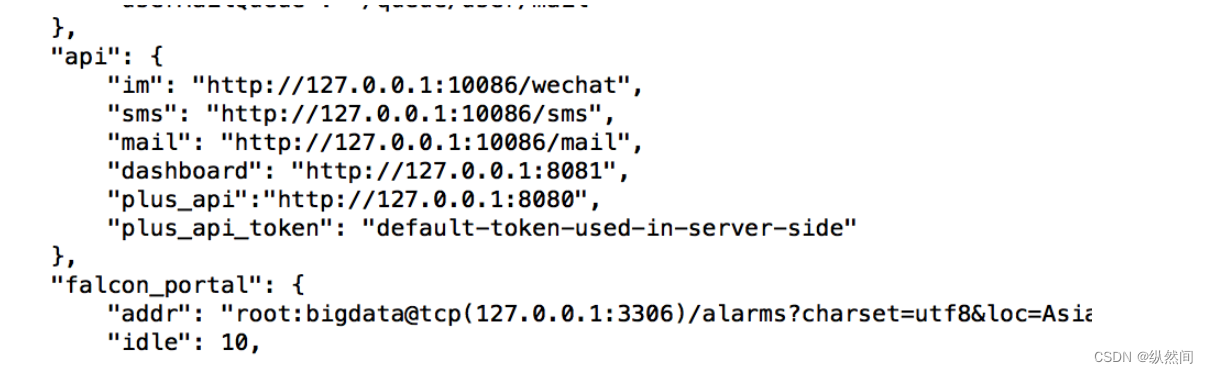
{ "log_level": "debug", "http": { "enabled": true, "listen": "0.0.0.0:9912" }, "redis": { "addr": "127.0.0.1:6379", "maxIdle": 5, "highQueues": [ "event:p0", "event:p1", "event:p2" ], "lowQueues": [ "event:p3", "event:p4", "event:p5", "event:p6" ], "userIMQueue": "/queue/user/im", "userSmsQueue": "/queue/user/sms", "userMailQueue": "/queue/user/mail" }, "api": { "im": "http://127.0.0.1:10086/wechat", //微信发送网关地址 "sms": "http://127.0.0.1:10086/sms", //短信发送网关地址 "mail": "http://127.0.0.1:10086/mail", //邮件发送网关地址 "dashboard": "http://127.0.0.1:8081", //dashboard 模块的运行地址 "plus_api":"http://127.0.0.1:8080", //falcon-plus api 模块的运行地址 "plus_api_token": "default-token-used-in-server-side" //用于和 falcon-plus api 模块服务 端之间的通信认证 token }, "falcon_portal": { "addr": "root:@tcp(127.0.0.1:3306)/alarms?charset=utf8&loc=Asia%2FChongqing", "idle": 10, "max": 100 }, "worker": { "im": 10, "sms": 10, "mail": 50 }, "housekeeper": { "event_retention_days": 7, //报警历史信息的保留天数 "event_delete_batch": 100 } }13.3 进程管理
# 启动 ./open-falcon start alarm # 停止 ./open-falcon stop alarm # 查看日志 ./open-falcon monitor alarm13.4 说明
如果某个核心服务挂了,可能会造成大面积报警,为了减少报警短信数量,我们做了报警合
并功能。把报警信息写入 dashboard 模块,然后 dashboard 返回一个 url 地址给 alarm,alarm 将这个 url 链接发给用户,这样用户只要收到一条短信(里边是个 url 地址),点击 url 进去就是多条报警内容。
highQueues 中配置的几个 event 队列中的事件是不会做报警合并的,因为那些是高优先级的报警,报警合并只是针对 lowQueues 中的事件。如果所有的事件都不想做报警合并,就把所有的event 队列都配置到 highQueues 中即可
十四 邮件、短信、电话发送接口
14.1 介绍
监控系统产生报警事件之后需要发送报警邮件或者报警短信,各个公司可能有自己的邮件服务器,有自己的邮件发送方法;有自己的短信通道,有自己的短信发送方法。
falcon 为了适配各个公司,在接入方案上做了一个规范,需要各公司提供 http 的短信和邮件发送接口。
14.2 邮件配置
邮件发送 http 接口:
method: post
params:
- content: 邮件内容
- subject: 邮件标题
- tos: 使用逗号分隔的多个邮件地址代码地址:https://github.com/open-falcon/mail-provider
下载然后进行编译:
git clone https://github.com/open-falcon/mail-provider
cd mail-provider
先配置安装 go 环境:
yum install golang
配置 gopath 指向 mail-provider 的目录
export GOPATH= /data/program/software/mail-provider/
执行命令: ./control build (编译)
执行命令: ./control pack (打包)
启动 ./control start
停止 ./control stop
重启 ./control restart
状态 ./control status

测试:
curl http://127.0.0.1:4000/sender/mail -d "tos=邮箱地址&subject=xx&content=yy"14.3 短信配置
短信发送 http 接口:
method: post
params:
- content: 短信内容
- tos: 使用逗号分隔的多个手机号
目前 open-falcon 支持 LinkedSee 灵犀云通道短信/语音通知 API 快速接入,只需一个 API 即可快
速对接 Open Falcon,快速让您拥有告警通知功能,90%的告警压缩比。云通道短信/语音通知接
口接入步骤如下:
目前 open-falcon 支持 LinkedSee 灵犀云通道短信/语音通知 API 快速接入,只需一个 API 即可快
速对接 Open Falcon,快速让您拥有告警通知功能,90%的告警压缩比。云通道短信/语音通知接
口接入步骤如下:
14.3.1、 注册
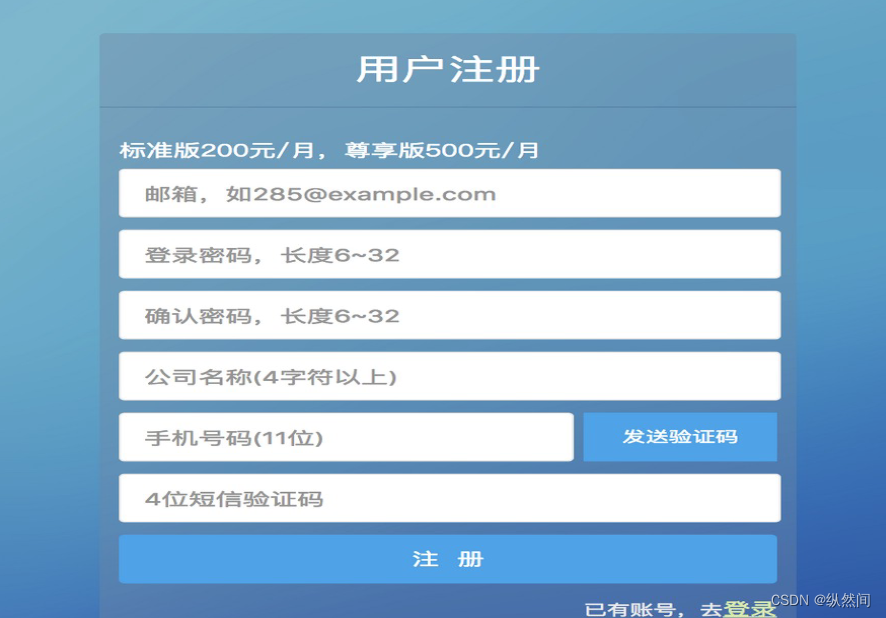
14.3.2、 新建应用
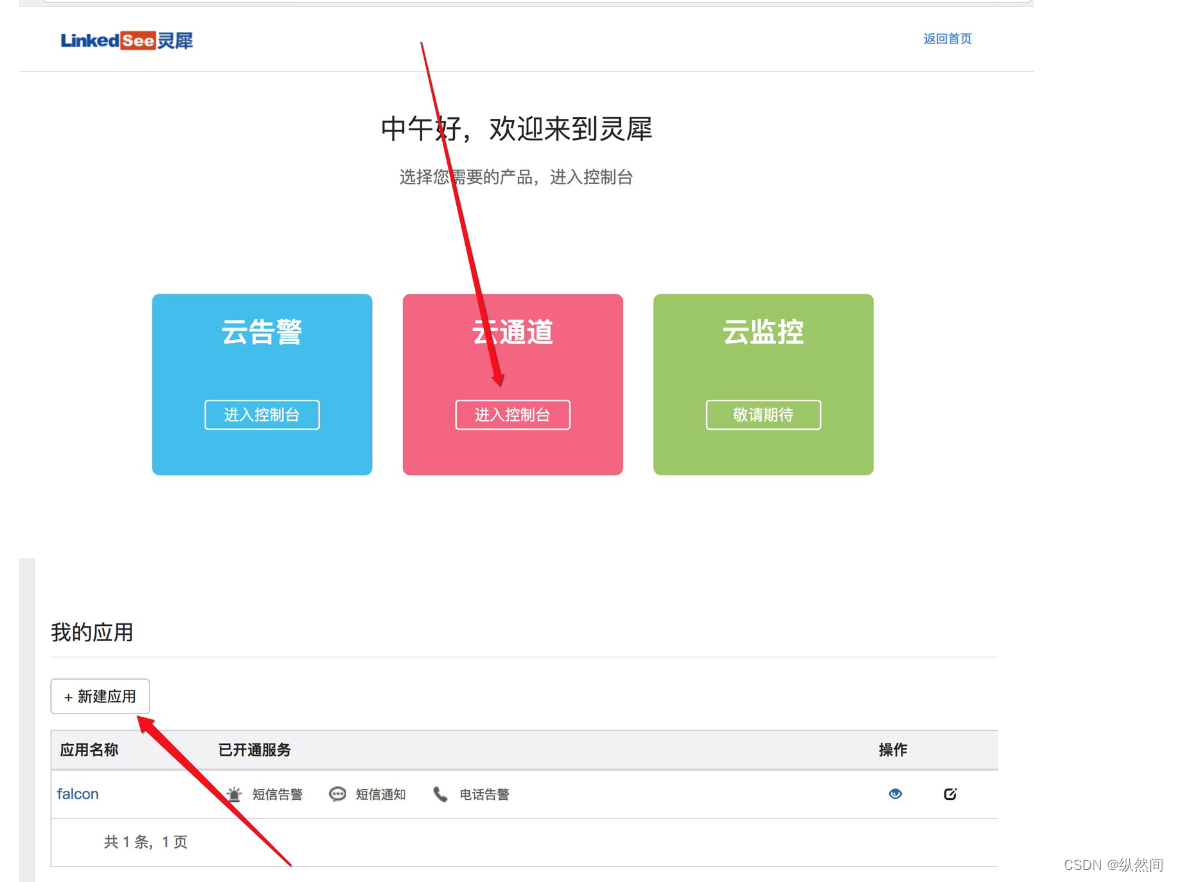
点击如下,保存 token,并且开启短信通知:
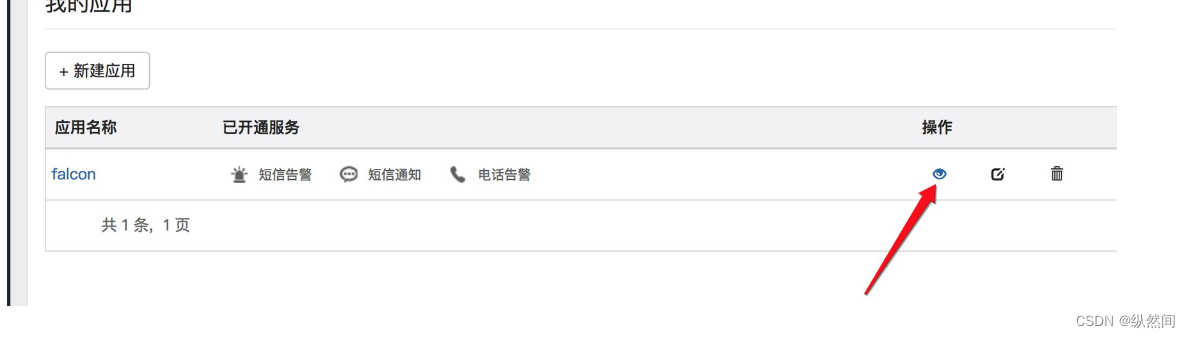
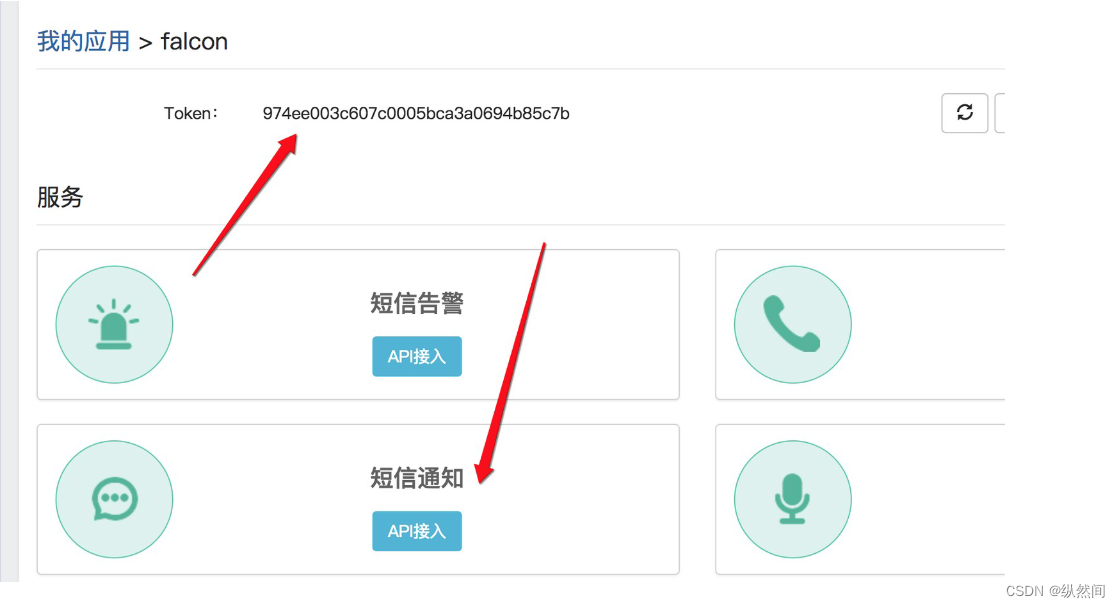
14.3.3、测试
https://www.linkedsee.com/alarm/falcon_sms/保存的 token
14.4 电话配置
类似第三步中开启语音通知,将地址改为 https://www.linkedsee.com/alarm/falcon_voice/保存的token 既可以发送语音通知。
14.5 更改 Alarm 配置
更改前:
更改后:

十五 检测监控数据上报异常- Nodata
15.1 介绍
nodata 用于检测监控数据的上报异常。nodata 和实时报警 judge 模块协同工作,过程为: 配置了 nodata的采集项超时未上报数据,nodata 生成一条默认的模拟数据;
用户配置相应的报警策略,收到 mock数据就产生报警。采集项上报异常检测,作为 judge 模块的一个必要补充,能够使 judge 的实时报警功能更加可靠、完善。
15.2 服务部署
服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
vim cfg.json # 启动服务 ./open-falcon start nodata # 停止服务 ./open-falcon stop nodata # 检查日志 ./open-falcon monitor nodata15.3 配置说明
配置文件默认为./cfg.json。
{ "debug": true, "http": { "enabled": true, "listen": "0.0.0.0:6090" }, "plus_api":{ "connectTimeout": 500, "requestTimeout": 2000, "addr": "http://127.0.0.1:8080", #falcon-plus api 模块的运行地址 "token": "default-token-used-in-server-side" #用于和 falcon-plus api 模块的交互认证 token }, "config": { "enabled": true, "dsn": "root:@tcp(127.0.0.1:3306)/falcon_portal? loc=Local&parseTime=true&wait_timeout=604800", "maxIdle": 4 }, "collector":{ "enabled": true, "batch": 200, "concurrent": 10 }, "sender":{ "enabled": true, "connectTimeout": 500, "requestTimeout": 2000, "transferAddr": "127.0.0.1:6060", #transfer 的 http 监听地址,一般形 如"domain.transfer.service:6060" "batch": 500 } }十六 集群聚合模块- Aggregator
16.1 介绍
集群聚合模块。聚合某集群下的所有机器的某个指标的值,提供一种集群视角的监控体验。
16.2 服务部署
服务部署,包括配置修改、启动服务、检验服务、停止服务等。这之前,需要将安装包解压到服务的部署目录下。
# 修改配置, 配置项含义见下文 vim cfg.json # 启动服务 ./open-falcon start aggregator # 检查 log ./open-falcon monitor aggregator # 停止服务 ./open-falcon stop aggregator16.3 配置说明
配置文件默认为./cfg.json。如下
{ "debug": true, "http": { "enabled": true, "listen": "0.0.0.0:6055" }, "database": { "addr": "root:@tcp(127.0.0.1:3306)/falcon_portal?loc=Local&parseTime=true", "idle": 10, "ids": [1, -1], "interval": 55 }, "api": { "connect_timeout": 500, "request_timeout": 2000, "plus_api": "http://127.0.0.1:8080", #falcon-plus api 模块的运行地址 "plus_api_token": "default-token-used-in-server-side", #和 falcon-plus api 模块交互的认 证 token "push_api": "http://127.0.0.1:1988/v1/push" #push 数据的 http 接口,这是 agent 提供的接口 } }十七、Mysql 监控
17.1 工作原理
在数据采集一节中我们介绍了常见的监控数据源。open-falcon 作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为 open-falcon 规范的格式就OK 了。
MySQL 的数据采集可以通过 mymon 来做。
mymon 是一个 cron,每分钟跑一次,配置文件中配置了数据库连接地址,mymon 连到该数据库,采集一些监控指标,比如 global status, global variables, slave status 等等,然后组装为 open-falcon 规定的格式的数据,post 给本机的 falcon-agent。falcon-agent 提供了一个http 接口,使用方法可以参考数据采集中的例子。比如我们有 1000 台机器都部署了 MySQL 实例,可以在这 1000 台机器上分别部署 1000 个 cron,即:与数据库实例一一对应。
17.2 配置安装
下载地址:https://github.com/open-falcon/mymon
安装:
设置$GOPATH:export $GOPATH =/src/
mkdir -p $GOPATH/src/github.com/open-falcon cd $GOPATH/src/github.com/open-falcon git clone https://github.com/open-falcon/mymon.git cd mymon go get ./... go build -o mymon echo '* * * * * cd $GOPATH/src/github.com/open-falcon/mymon && ./mymon -c etc/mon.cfg' > /etc/cron.d/mymon执行 go get ./...的时候出现如下错误:
package golang.org/x/crypto/ssh/terminal: unrecognized import path
"golang.org/x/crypto/ssh/terminal" (https fetch: Get
https://golang.org/x/crypto/ssh/terminal?go-get=1: dial tcp 216.239.37.1:443: i/o timeout)
package golang.org/x/sys/unix: unrecognized import path "golang.org/x/sys/unix" (https
fetch: Get https://golang.org/x/sys/unix?go-get=1: dial tcp 216.239.37.1:443: i/o timeout)
解决办法:
方法一:直接下载文件,然后把解压出来的文件夹放在 src 里。
下载地址:https://pan.baidu.com/s/1boVAtJp
方法二:直接从 git 上下载对应文件放到 src 下面。
mkdir -p $GOPATH/src/golang.org/x cd $GOPATH/src/golang.org/x git clone https://github.com/golang/crypto.git git clone https://github.com/golang/sys.git修改配置文件:
/src/github.com/open-falcon/mymon/etc
vi mon.cfg
[default] log_file=mymon.log # 日志路径和文件名 # Panic 0 # Fatal 1 # Error 2 # Warn 3 # Info 4 # Debug 5 log_level=4 # 日志级别 falcon_client=http://127.0.0.1:1988/v1/push # falcon agent 连接地址 #自定义 endpoint endpoint=127.0.0.1 #若不设置则使用 OS 的 hostname [mysql] user=root # 数据库用户名 password= # 数据库密码 host=127.0.0.1 # 数据库连接地址 port=3306 # 数据库端口如下图采集成功:
十八 Redis监控
18.1 介绍
Redis 的数据采集可以通过采集脚本 redis-monitor 或者 redismon 来做。
redis-monitor 是一个 cron,每分钟跑一次采集脚本 redis-monitor.py,其中配置了 redis 服务的地址,redis-monitor 连到 redis 实例,采集一些监控指标,比如 connected_clients、used_memory等等,然后组装为 open-falcon 规定的格式的数据,post 给本机的 falcon-agent。falcon-agent 提供了一个 http 接口,使用方法可以参考数据采集中的例子。
比如,我们有 1000 台机器都部署了 Redis 实例,可以在这 1000 台机器上分别部署 1000 个
cron,即:与 Redis 实例一一对应。
18.2 配置安装
下载地址:https://github.com/iambocai/falcon-monit-scripts
进入目录:/data/program/software/falcon-monit-scripts-master/redis
修改配置文件:
vi redis-monitor.py
修改对应连接到 agent 的地址(特别是红颜色部分注意修改):
#!/bin/env python
#-*- coding:utf-8 -*-
__author__ = 'iambocai'
import json
import time
import socket
import os
import re
import sys
import commands
import urllib2, base64class RedisStats:
# 如果你是自己编译部署到 redis,请将下面的值替换为你到 redis-cli 路径
_redis_cli = '/usr/local/redis/redis-cli'
_stat_regex = re.compile(ur'(\w+):([0-9]+\.?[0-9]*)\r')
def __init__(self, port='6379', passwd=None, host='127.0.0.1'):
self._cmd = '%s -h %s -p %s info' % (self._redis_cli, host, port)
if passwd not in ['', None]:
self._cmd = '%s -h %s -p %s -a %s info' % (self._redis_cli, host, port, passwd)
def stats(self):
' Return a dict containing redis stats '
info = commands.getoutput(self._cmd)
return dict(self._stat_regex.findall(info))def main():
ip = "dst6-redis"
timestamp = int(time.time())
step = 60
# inst_list 中保存了 redis 配置文件列表,程序将从这些配置中读取 port 和 password,建
议使用动态发现的方法获得,如:
# inst_list = [ i for i in commands.getoutput("find /etc/ -name 'redis*.conf'" ).split('\n') ]
insts_list = [ '/usr/local/redis/redis.conf' ]
p = []
monit_keys = [
('connected_clients','GAUGE'),
('blocked_clients','GAUGE'),
('used_memory','GAUGE'),
('used_memory_rss','GAUGE'),
('mem_fragmentation_ratio','GAUGE'),
('total_commands_processed','COUNTER'),
('rejected_connections','COUNTER'),
('expired_keys','COUNTER'),
('evicted_keys','COUNTER'),
('keyspace_hits','COUNTER'),
('keyspace_misses','COUNTER'),
('keyspace_hit_ratio','GAUGE'),
]
for inst in insts_list:
port = commands.getoutput("sed -n 's/^port *\([0-9]\{4,5\}\)/\\1/p' %s" % inst)
passwd = commands.getoutput("sed -n 's/^requirepass *\([^ ]*\)/\\1/p' %s" % inst)
metric = "redis"
endpoint = ip
tags = 'port=%s' % port
try:
conn = RedisStats(port, passwd)
stats = conn.stats()
except Exception,e:
continue
for key,vtype in monit_keys:
#一些老版本的 redis 中 info 输出的信息很少,如果缺少一些我们需要采集的 key 就
跳过
if key not in stats.keys():
continue
#计算命中率
if key == 'keyspace_hit_ratio':try:
value = float(stats['keyspace_hits'])/(int(stats['keyspace_hits']) +
int(stats['keyspace_misses']))
except ZeroDivisionError:
value = 0
#碎片率是浮点数
elif key == 'mem_fragmentation_ratio':
value = float(stats[key])
else:
#其他的都采集成 counter,int
try:
value = int(stats[key])
except:
continue
i = {
'Metric': '%s.%s' % (metric, key),
'Endpoint': endpoint,
'Timestamp': timestamp,
'Step': step,
'Value': value,
'CounterType': vtype,
'TAGS': tags
}
p.append(i)
print json.dumps(p, sort_keys=True,indent=4)
method = "POST"
handler = urllib2.HTTPHandler()
opener = urllib2.build_opener(handler)
url = 'http://127.0.0.1:1988/v1/push'
request = urllib2.Request(url, data=json.dumps(p) )
request.add_header("Content-Type",'application/json')
request.get_method = lambda: method
try:
connection = opener.open(request)
except urllib2.HTTPError,e:
connection = e
# check. Substitute with appropriate HTTP code.
if connection.code == 200:
print connection.read()
else:
print '{"err":1,"msg":"%s"}' % connection
if __name__ == '__main__':
proc = commands.getoutput(' ps -ef|grep %s|grep -v grep|wc -l ' %os.path.basename(sys.argv[0]))
sys.stdout.flush()
if int(proc) < 5:
main()
18.3 启动测试
python redis-monitor.py
将脚本加入 crontab 执行即可
查看服务状态:service crond status
编辑:crontab –e
加入命令,一分钟执行一次,然后保存。
*/1 * * * * python /data/program/software/falcon-monit-scripts-master/redis/redis-monitor.py
重启服务:service crond restart
如需增减字段,请修改 monit_keys 变量
十九 Mongodb 监控
19.1 功能支持
已测试版本: 支持 MongoDB 版本 2.4,2.6 3.0,3.2, 以及 Percona MongoDB3.0
支持存储引擎:MMAPv1, wiredTiger, RocksDB, PerconaFT 存储引擎(部分存储引擎的指标未采集完,可直接代码中添加)
支持结构: standlone, 副本集,分片集群
支持节点:mongod 数据节点,配置节点,Primary/Secondary, mongos; 不支持 Arbiter 节点
19.2 数据采集
1、存活监控: 包括 auth
2、serverStatus
3、replSetGetStatus
4、oplog.rs
5、mongos
通过 cron 每分钟采集上报,采集对 MongoDB 理论无性能影响
19.3 环境要求
操作系统: Linux
Python 2.6
PyYAML > 3.10
python-requests > 0.11
19.4 程序部署
下载地址:https://github.com/ZhuoRoger/mongomon
进入目录 cd /data/program/software/mongomon
配置当前服务器的 MongoDB 多实例(mongod,配置节点,mongos)信息,/path/to/mongomon/conf/
mongomon.conf 每行记录一个实例: 端口,用户名,密码
{port: 27017, user: "",password: ""}
配置 crontab, 修改 mongomon/conf/mongomon_cron 文件中 mongomon 安装 path; cp
mongomon_cron /etc/cron.d/
几分钟后,可从 open-falcon 的 dashboard 中查看 MongoDB metric
endpoint 默认是 hostname
19.5 测试
第四步的配置到 crontab 中。但是我们也可以自己测试一下,如下:
cd /data/program/software/mongomon/bin
python mongodb_monitor.py
如果出现如下错误:
Traceback (most recent call last):
File "mongodb_monitor.py", line 13, in <module>
from mongodb_server import mongodbMonitor
File "/data/program/software/mongomon/bin/mongodb_server.py", line 7, in <module>
import pymongo
ImportError: No module named pymongo
解决办法:pip install pymongo
然后再执行 python mongodb_monitor.py
二十 Rabbitmq 监控
20.1 介绍
在数据采集一节中我们介绍了常见的监控数据源。open-falcon 作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为 open-falcon 规范的格式就 OK 了。
RMQ 的数据采集可以通过脚本 rabbitmq-monitor 来做。
rabbitmq-monitor 是一个 cron,每分钟跑一次脚本 rabbitmq-monitor.py,其中配置了 RMQ 的用户名&密码等,脚本连到该 RMQ 实例,采集一些监控指标,比如messages_ready、messages_total 、deliver_rate 、publish_rate 等等,然后组装为 open-falcon 规定的格式的数据,post 给本机的 falcon-agent。falcon-agent 提供了一个 http 接口,使用方法可以参考数据采集中的例子。
20.2 安装配置
下载地址:https://github.com/iambocai/falcon-monit-scripts/tree/master/rabbitmq
修改配置:vi rabbitmq-monitor.py
1、根据实际部署情况,修改 15,16 行的 rabbitmq-server 管理端口和登录用户名密码
2、确认 1 中配置的 rabbitmq 用户有你想监控的 queue/vhosts 的权限
3、将脚本加入 crontab 即可
新建脚本:vi rabbitmq_cron
* * * * * root (cd /data/program/software/falcon-monit-scripts-master/rabbitmq && python rabbitmq-
monitor.py > /dev/null)
cp rabbitmq_cron /etc/cron.d/
二十一 Nginx 监控
21.1 工作原理
ngx_metric 是借助 lua-nginx-module 的 log_by_lua 功能实现 nginx 请求的实时分析,然后借助ngx.shared.DICT 存储中间结果。最后通过外部 python 脚本取出中间结果加以计算、格式化并输出。按 falcon 格式输出的结果可直接 push 到 falcon agent。
ngx_metric(Nginx-Metric) -- Open-Falcon 的 Nginx Web Server 请求数据采集工具,主要包括流量大小、响应时间、异常请求统计等。
21.2 汇报字段
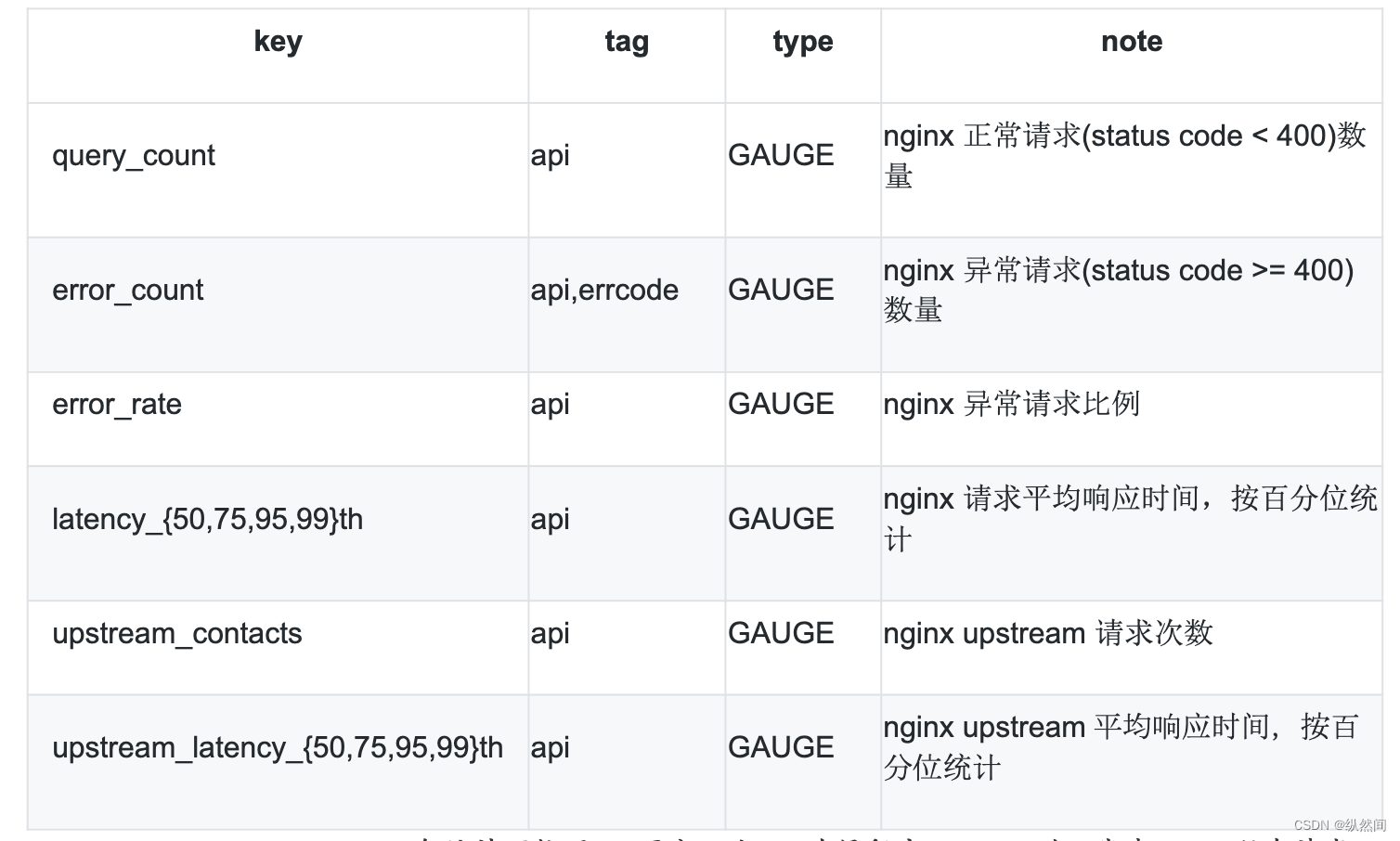
api tag: 即 nginx request uri,各统计项按照 uri 区分。当 api 为保留字__serv__时,代表 nginx 所有请求的综合统计
error_count、upstream 统计项根据实际情况,如果没有则不会输出
21.3 安装部署
下载地址:https://github.com/GuyCheung/falcon-ngx_metric
下载:cd /data/program/software
git clone https://github.com/GuyCheung/falcon-ngx_metric.git
lua 文件部署:
cd /usr/local/nginx/
mkdir modules
cp -r /data/program/software/falcon-ngx_metric/lua/* /usr/local/nginx/modules
nginx 配置文件加载:
cp /data/program/software/falcon-ngx_metric/ngx_metric.conf /usr/local/nginx/conf/conf.d
启动测试:python nginx_collect.py --format=falcon –service=dst6-nginx
将启动脚本加入到 crontab
21.4 参数解释
nginx_collect.py 脚本参数说明
python nginx_collect.py -h Usage: nginx_collect.py [options] Options: -h, --help show this help message and exit --use-ngx-host use the ngx collect lib output host as service column, default read self --service=SERVICE logic service name(endpoint in falcon) of metrics, use nginx service_name as the value when --use-ngx-host specified. default is ngx_metric --format=FORMAT output format, valid values "odin|falcon", default is odin --falcon-step=FALCON_STEP Falcon only. metric step --falcon-addr=FALCON_ADDR Falcon only, the addr of falcon push api --ngx-out-sep=NGX_OUT_SEP ngx output status seperator, default is "|"--use-ngx-host: 使用 nginx 配置里的 service_name 作为采集项的 endpoint
--service: 手动设置 endpoint 值,当指定--use-ngx-host 时,该参数无效
--format: 采集数据输出格式,对接 falcon 请使用--format=falcon
--falcon-step: falcon step 设置,请设置为 python 脚本调用频率,默认是 60
--falcon-addr: falcon push 接口设置,设置该参数数据直接推送,不再输出到终端。需要安装
requests 模块
