
阅读量:0
目录
4.打开index.html就可以在前端使用此自动对对联系统了。
本文所涉及所有资源均在传知代码平台可获取。
概述
这个生成器利用预训练的BERT模型,通过微调来生成中国对联。对联是一种中文传统文化形式,通常由上下联组成,具有一定的韵律和意境。
演示效果
在这里可以插入动图展示您的程序运行效果



核心逻辑
在这里可以粘贴您的核心代码逻辑:
# start class CoupletDataset(Dataset): def __init__(self, data_path, tokenizer): self.data_path = data_path self.tokenizer = tokenizer self.inputs, self.labels = self.load_dataset() def load_dataset(self): with open(self.data_path + '/in_cut.txt', 'r', encoding='utf-8') as fin, \ open(self.data_path + '/out_cut.txt', 'r', encoding='utf-8') as fout: inputs = [line.strip() for line in fin.readlines()] labels = [line.strip() for line in fout.readlines()] return inputs, labels def __len__(self): return len(self.inputs) def __getitem__(self, index): input_text = self.inputs[index] label_text = self.labels[index] input_tokens = tokenizer.tokenize(input_text) label_tokens = tokenizer.tokenize(label_text) # 拼接成BERT模型需要的输入格式 input_tokens = ['[CLS]'] + input_tokens + ['[SEP]'] label_tokens = label_tokens + ['[SEP]'] # 将token转换为对应的id input_ids = tokenizer.convert_tokens_to_ids(input_tokens) label_ids = tokenizer.convert_tokens_to_ids(label_tokens) # 确保input_ids和label_ids的长度一致 max_length = max(len(input_ids), len(label_ids)) input_ids.extend([0] * (max_length - len(input_ids))) label_ids.extend([0] * (max_length - len(label_ids))) # 将input_ids和label_ids转换为tensor input_ids = torch.tensor(input_ids).unsqueeze(0).to(device) # 增加batch维度 label_ids = torch.tensor(label_ids).unsqueeze(0).to(device) # 增加batch维度 return input_ids, label_ids 使用方式
1.裁剪数据集
修改lines_to_read = 1000
选择你想要的数据集大小,这里采用了1000条对联
原始数据集有70万条对联,根据需求还有电脑性能选择
根据自己的需要选择
2.用couplet数据集训练模型
在终端中输入命令 python bert.py,训练模型并监控损失变化。训练完成后会生成损失图像,并将模型保存在 model 文件夹中。
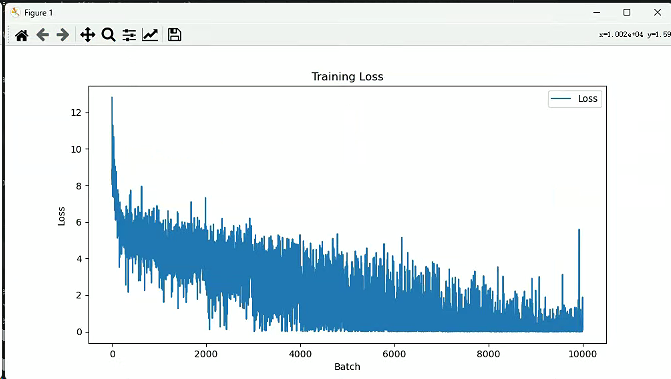
最终出来loss损失图像
模型存储在model文件夹中
3.将模型转换为ONNX格式
使用命令 python app.py 将存储的模型转换为ONNX格式,以便在前端调用。
4.打开index.html就可以在前端使用此自动对对联系统了。
在输入框中输入上联。
感觉不错,点击我,立即使用
