
阅读量:0
以字符串‘你好-Hello,123_世界World,456’来介绍下
REGEXP_MATCHES()、REGEXP_REPLACE()、REGEXP_SPLIT_TO_ARRAY()、REGEXP_SPLIT_TO_TABLE() 四个函数用法
REGEXP_MATCHES()
REGEXP_MATCHES()用于在文本字符串中执行正则表达式匹配,并返回匹配的结果作为数组。
--从字符串中返回的结果只有小写英文 SELECT REGEXP_MATCHES('你好-Hello,123_世界-World,456', '[a-z]+', 'g'); 
--从字符串中返回的结果只有大写英文 SELECT REGEXP_MATCHES('你好-Hello,123_世界-World,456', '[A-Z]+', 'g'); 
--从字符串中返回的结果只有英文 SELECT REGEXP_MATCHES('你好-Hello,123_世界-World,456', '[a-zA-Z]+', 'g');
REGEXP_REPLACE()
REGEXP_REPLACE()用于在文本字符串中执行正则表达式替换,并返回替换后的字符串。
--将字符串中数字替换为'*' SELECT REGEXP_REPLACE('你好-Hello,123_世界World,456', '[0-9]', '*', 'g');
--将字符串中英文替换为'*' SELECT REGEXP_REPLACE('你好-Hello,123_世界World,456', '[a-zA-Z]', '*', 'g'); 
--将字符串中汉字替换为'*' SELECT REGEXP_REPLACE('你好-Hello,123_世界World,456', '[\u4e00-\u9fa5]', '*', 'g');
最近工作中遇到了处理字符串的问题,正好做下补充:
譬如某个字段中存在垃圾数据,数据内容应该是'abc+123'的格式,但有的数据只有一个'+',如果只用replace()替换,就可能污染了正常数据,那么就可以用REGEXP_REPLACE()
--譬如脏数据是'+',需要处理成空字符串 SELECT regexp_replace('+', '^\+$', '');
REGEXP_SPLIT_TO_ARRAY()
REGEXP_SPLIT_TO_ARRAY()用于将文本字符串按照正则表达式进行分割,并返回结果作为数组。
--以字符串中的标点符号来分割 SELECT REGEXP_SPLIT_TO_ARRAY('你好-Hello,123_世界-World,456', '[-,_]+');
REGEXP_SPLIT_TO_TABLE()
REGEXP_SPLIT_TO_TABLE()用于将文本字符串按照正则表达式进行分割,并返回结果作为表格。
--以字符串中的标点符号来分割 SELECT REGEXP_SPLIT_TO_TABLE('你好-Hello,123_世界-World,456', '[-,_]+');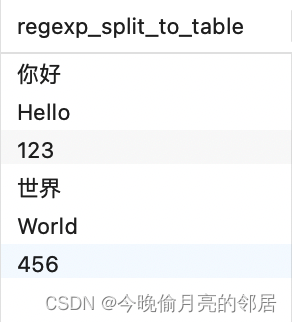
最后可以参考这篇文章学习正则表达式的语法
