
阅读量:0
一、介绍
随着基础模型的兴起,向量数据库的受欢迎程度也飙升。事实上,在大型语言模型环境中,向量数据库也很有用。
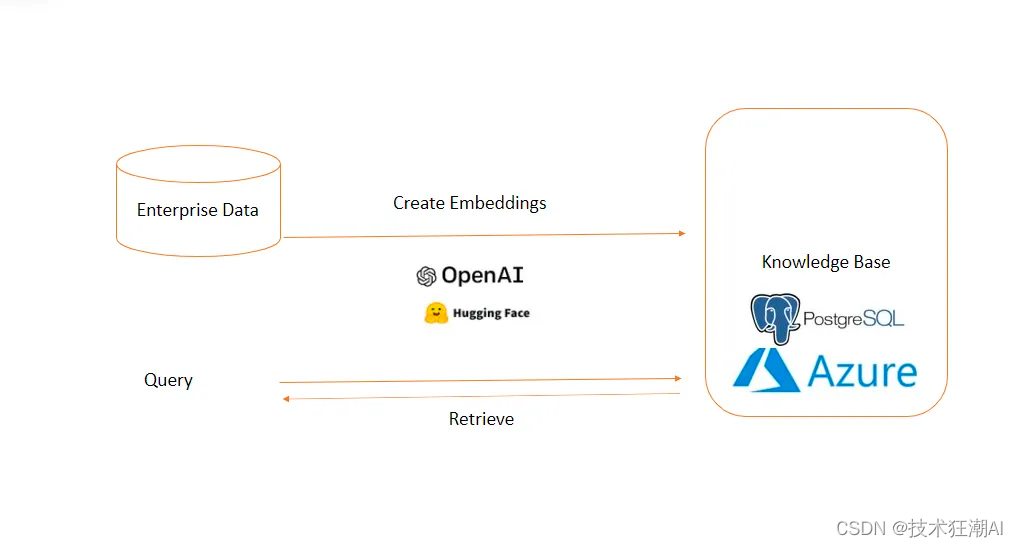
在机器学习领域,我们经常处理的是向量嵌入。向量嵌入是通过特定的机器学习模型运行对象的特征,将对象的上下文信息投射到潜在空间中来创建的。
为了在使用向量嵌入时能够表现得特别好,创建向量数据库是必要的。这方面的工作包括存储、更新和检索向量。当我们谈论检索时,通常是指检索与查询最相似的向量,这些向量与嵌入到同一潜在空间并传递到向量数据库中。这个检索过程被称为近似最近邻。
嵌入是由人工智能模型生成的,并且由于它们包含大量属性或特征,因此管理它们的表示可能很困难。在人工智能和机器学习的背景下,这些特征代表数据的许多元素,所有这些元素对于理解模式、相关性和底层结构都是必要的。
因此,我们需要专门为管理此类信息而开发的数据库。像Chroma-DB这样的向量数据库能够满足这一需求,因为它们提供了经过优化的嵌入式存储和查询功能,并且具备典型数据库所不具备的独立向量索引特性。此外,向量数据库还具备处理向量嵌入的专门能力,这是传统基于标量的数据库所不具备的。
PostgreSQL是一个强大的对象关系数据库系统,可在开源许可下使用。它已经积极开发了超过35年,这使得它在可靠性、稳健性和性能方面建立了良好的声誉。好消息是,除了外部扩展之外,PostgreSQL还支持向量。
一些流行的向量数据库包括:Pinecone、Weviate、Chroma、Milvus、Faiss。尽管Redis、Cassandra等数据库并非向量数据库,但越来越多的数据库提供商开始提供ANN搜索功能。
二、什么是向量数据库
向量数据库是一种专门用于存储、管理和搜索向量数据的数据库。它以向量的形式存储数据,其中向量是抽象实体(如图像、音频文件、文本等)的数学表示。通过存储数据向量并使用向量之间的相似度度量,向量数据库可以实现高效、准确的数据搜索和分析。
下面显示了一个非常简单的示例。虽然顶部的两个句子的含义非常相似,但底部的句子却截然不同。向量数据库能够将这些句子编码为向量,然后找到接近的句子 - 这意味着它们是相似的。
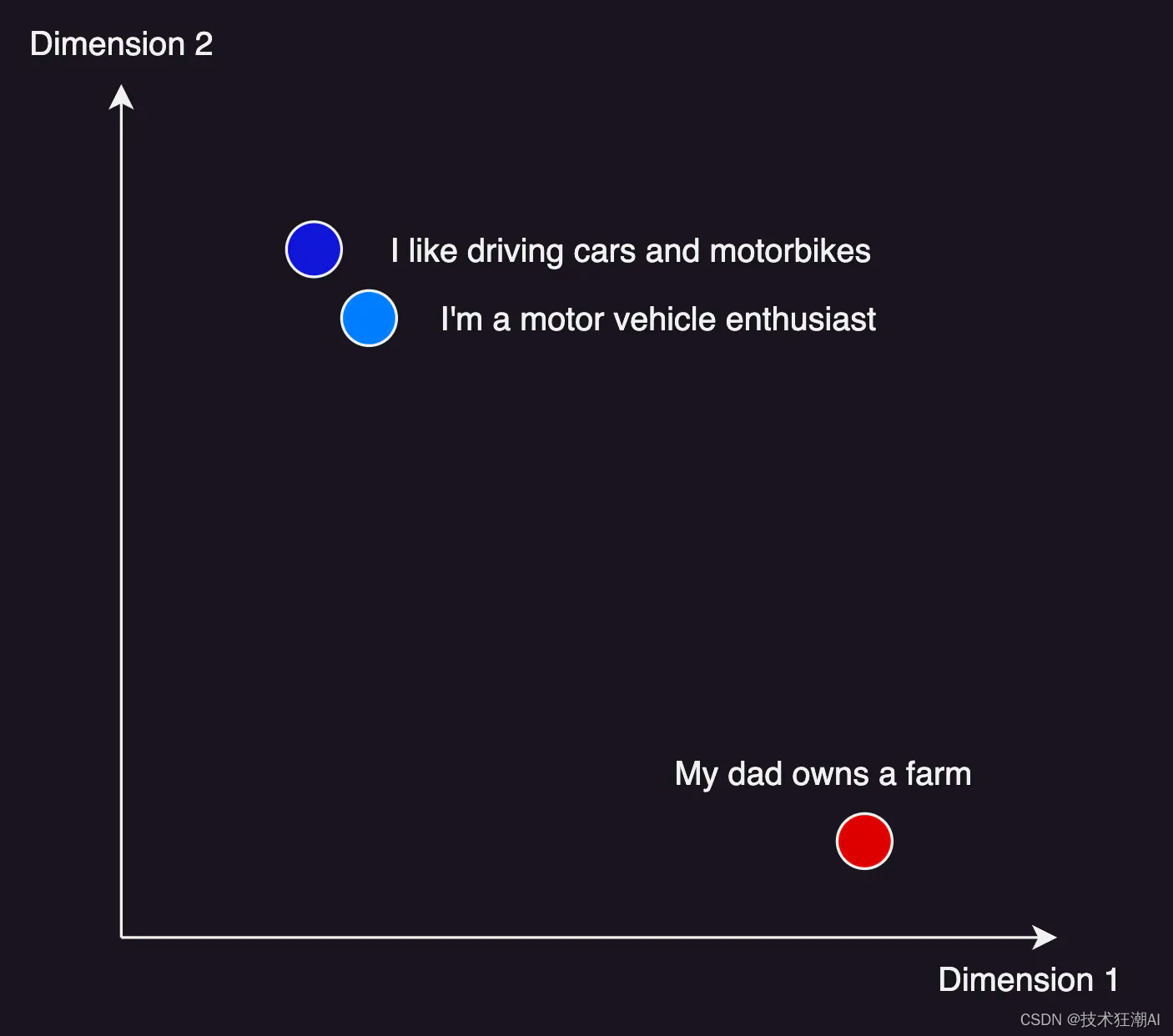
请记住,在实际应用中,我们拥有的维度远不止 2 个维度 - OpenAI 嵌入目前使用大约 1500 个维度来进行有意义的语言矢量化。
向量数据库的核心特点如下:
1)、向量表示:向量数据库将复杂的数据类型转换为向量表示,使得高维数据能够以多维空间中的点的形式表示。这种表示不仅具有高计算效率,还简化了数据点之间的比较和关联过程。
2)、基于相似性的搜索:向量数据库擅长根据向量表示来搜索与给定查询相似的数据项。它们使用欧氏距离、余弦相似度或曼哈顿距离等相似性度量来确定多维空间中数据点之间的接近程度,从而找到最相关和最相似的结果。
3)、可扩展性:向量数据库被设计成能够处理大规模的数据集,并且在数据集大小增长时能够保持高搜索精度和响应时间。此外,它们通常提供并行处理和分布式计算的机制,以满足不断增长的数据需求。
4)、与机器学习和人工智能兼容:随着人工智能和机器学习应用的迅速增长,向量数据库的采用也在增加。将复杂数据转换为向量表示可以与这些算法无缝集成,从而获得规模化的有价值洞见和预测。
总之,向量数据库利用向量数据的特性,提供高效、准确的搜索和分析功能。它们在处理高维数据和进行相似性搜索方面具有优势,并且与机器学习和人工智能应用的兼容性使其在各个领域中变得越来越重要。
三、向量数据库的应用场景
向量数据库具有多种应用场景,以下是其中一些突出的应用领域:
自然语言处理(NLP):向量数据库可以有效处理词嵌入或文档向量,促进语义搜索和文本分析。它们可以用于文档分类、情感分析、关键词提取等任务,帮助组织理解来自社交媒体、论坛、客户互动等数据源的大量文本数据。
图像搜索和识别:图像数据库受益于向量数据库的向量表示和基于相似性的搜索功能。通过识别高维数据的相似性和模式,它们可以有效处理反向图像搜索、对象检测、人脸识别等任务。
推荐系统:强大的推荐引擎是现代电子商务和内容平台的关键组成部分之一。通过使用向量数据库,这些系统可以分析用户偏好和内容特征,实时生成个性化且高度相关的推荐。
异常检测和欺诈预防:特定领域的数据点(如金融交易或用户行为)可以转换为向量表示,进行实时分析。基于相似性的搜索功能可以快速识别异常模式或潜在欺诈,帮助组织减少风险。
基因组研究:在基因组学领域,研究人员处理复杂的生物数据,并经常需要识别相似的基因序列或结构。向量数据库的强大搜索功能可以加速这一过程,更准确地进行关键发现和进展。
多媒体内容管理:向量数据库可以通过将音频和视频转换为向量表示来处理各种内容。这种能力使得内容搜索和分析变得更加普遍,实现了基于相似性、模式识别或自动内容标记的媒体无缝检索。
除了上述应用领域,向量数据库在许多其他行业和领域中也有广泛的应用。随着对向量数据库潜力认识的增加,其在数据管理和分析方面的采用和探索将继续推动创新和发展。
四、PostgreSQL 向量扩展-pgvector
pgvector 是一个基于 PostgreSQL 的扩展,为用户提供了一套强大的功能,用于高效地存储、查询和处理向量数据。它具有以下特点:
直接集成:pgvector 可以作为扩展直接添加到现有的 PostgreSQL 环境中,方便新用户和长期用户获得矢量数据库的好处,无需进行重大系统更改。
支持多种距离度量:pgvector 内置支持多种距离度量,包括欧几里德距离、余弦距离和曼哈顿距离。这样的多功能性使得可以根据具体应用需求进行高度定制的基于相似性的搜索和分析。
索引支持:pgvector 扩展为矢量数据提供高效的索引选项,例如 k-最近邻 (k-NN) 搜索。即使数据集大小增长,用户也可以实现快速查询执行,并保持较高的搜索准确性。
易于查询语言访问:作为 PostgreSQL 的扩展,pgvector 使用熟悉的 SQL 查询语法进行向量操作。这简化了具有 SQL 知识和经验的用户使用矢量数据库的过程,并避免了学习新的语言或系统。
积极的开发和支持:pgvector 经常更新,以确保与最新的 PostgreSQL 版本和功能兼容,并且开发者社区致力于增强其功能。用户可以期待一个受到良好支持的解决方案,满足其矢量数据的需求。
稳健性和安全性:通过与 PostgreSQL 的集成,pgvector 继承了相同级别的稳健性和安全性功能,使用户能够安全地存储和管理其矢量数据。
总之,pgvector 是一个功能强大的 PostgreSQL 扩展,为用户提供了高效、灵活和可靠的方式来处理向量数据。它的直接集成、多种距离度量支持、索引支持和易于访问的查询语言使其成为处理矢量数据的理想选择。
4.1、如何使用 pgvector
- 在数据库服务器上安装 pgvector
cd /tmp git clone --branch v0.4.2 https://github.com/pgvector/pgvector.git cd pgvector make make install # 可能需要sudo - 在您的数据库中,运行此命令以启用扩展
CREATE EXTENSION IF NOT EXISTS vector; - 创建一个存储向量的表
CREATE TABLE items (id bigserial PRIMARY KEY, name, features vector(3)); - 添加数据的工作原理如下
INSERT INTO items (features) VALUES ('[1,2,3]'), ('[4,5,6]'); - 由于 pgvector 构建在 postgres 之上,因此许多 PG DML 可用。例如。要更新插入,您可以运行
INSERT INTO items (id, features) VALUES (1, '[1,2,3]'), (2, '[4,5,6]') 2ON CONFLICT (id) DO UPDATE SET features = EXCLUDED.features; 4.2、pgvector 查询运算符
在 pgvector 中,可以使用各种查询运算符对矢量数据进行不同的操作。这些运算符主要用于计算向量之间的相似度或距离,其中一些运算符使用不同的距离度量。以下是一些常用的 pgvector 查询运算符:
<->:该运算符计算两个向量之间的欧几里德距离。欧几里德距离是多维空间中向量表示的点之间的直线距离。较小的欧几里德距离表示向量之间的相似性较大,因此该运算符在查找和排序相似项目时非常有用。
SELECT id, name, features, features <-> '[0.45, 0.4, 0.85]' as distance 2FROM items 3ORDER BY features <-> '[0.45, 0.4, 0.85]'; <=>:该运算符计算两个向量之间的余弦相似度。余弦相似度比较两个向量的方向而不是它们的大小。余弦相似度的范围在 -1 到 1 之间,1 表示向量相同,0 表示无关,-1 表示向量指向相反方向。
SELECT id, name, features, features <=> '[0.45, 0.4, 0.85]' as similarity 2FROM items 3ORDER BY features <=> '[0.45, 0.4, 0.85]' DESC; <#>:该运算符计算两个向量之间的曼哈顿距离(也称为 L1 距离或城市街区距离)。曼哈顿距离是每个维度对应坐标差的绝对值之和。相对于欧几里德距离而言,曼哈顿距离更加强调沿着维度的较小移动。
SELECT id, name, features, features <#> '[0.45, 0.4, 0.85]' as distance 2FROM items 3ORDER BY features <#> '[0.45, 0.4, 0.85]';p 在选择适当的运算符时,您应该考虑您的应用需求和数据特性。这可能涉及保持相对距离、强调大小或方向以及关注特定维度等因素。请注意,根据您的数据和用例,运算符的选择可能会对搜索结果的质量以及最终应用程序的有效性产生重大影响。
4.3、pgvector索引
在 pgvector 中,可以通过添加索引来使用近似最近邻搜索,以提高查询性能。以下是一些关于 pgvector 索引的建议:
1)、在表中有一定数量的数据后创建索引:在创建索引之前,确保表中有足够的数据,以便索引能够提供更好的查询性能。
2)、选择适当数量的列表:可以根据表的大小来选择适当数量的列表。一般来说,可以使用表的行数除以 1000(最多 1M 行)和平方根(rows)(超过 1M 行)作为起点。
3)、指定适当的探针数量:在执行查询时,可以指定适当的探针数量来平衡查询速度和召回率。一般来说,可以使用列表数量除以 10(最多 1M 行)和平方根(lists)(超过 1M 行)作为起点。
这些建议可以帮助您在近似最近邻搜索中获得良好的准确性和性能。请注意,具体的索引配置可能需要根据您的数据和查询需求进行调整,以达到最佳性能。
BEGIN; SET LOCAL ivfflat.probes = 10; SELECT ... COMMIT; 为您要使用的每个距离函数添加一个索引。
- L2距离
CREATE INDEX ON items USING ivfflat (embedding vector_l2_ops) WITH (lists = 100); - 内积
CREATE INDEX ON items USING ivfflat (embedding vector_ip_ops) WITH (lists = 100); - 余弦距离
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100); 五、总结
在这篇文章中,我们探讨了矢量数据库在管理高维数据和其在各个行业中的应用中的重要性。我们介绍了 pgvector,这是一个功能强大的 PostgreSQL 扩展,支持矢量数据的存储和搜索,并提供了一个易于访问的矢量数据库解决方案。通过实用指南,我们演示了如何使用 pgvector 创建表、插入数据和查询相似项。此外,我们还讨论了 pgvector 中用于计算相似性度量的不同查询运算符,如欧几里得距离、余弦相似度和曼哈顿距离。
通过使用 pgvector,我们可以轻松地处理高维数据,并根据具体需求进行相似性搜索和分析。pgvector 的直接集成、索引支持和易于查询的语言使其成为处理矢量数据的理想选择。无论是新用户还是长期用户,都可以从中获得矢量数据库的好处,而无需进行重大系统改动。
在选择适当的查询运算符和索引配置时,我们应该考虑数据特性、查询需求以及平衡准确性和性能的要求。通过合理地配置和使用 pgvector,我们可以获得高效、准确且可靠的矢量数据解决方案,满足不同行业和应用的需求。
项目地址:https://github.com/pgvector/pgvector
