
阅读量:0
深层爬取
在前面几篇的内容中,我们都是爬取网页表面的信息,这次我们通过表层内容,深度爬取内部数据。
接着按照之前的步骤,我们先访问表层页面:
- 指定url
- 发送请求
- 获取你想要的数据
- 数据解析
我们试着将以下豆瓣读书页面的书籍进一步爬取:
https://book.douban.com/tag/%E4%BA%92%E8%81%94%E7%BD%91 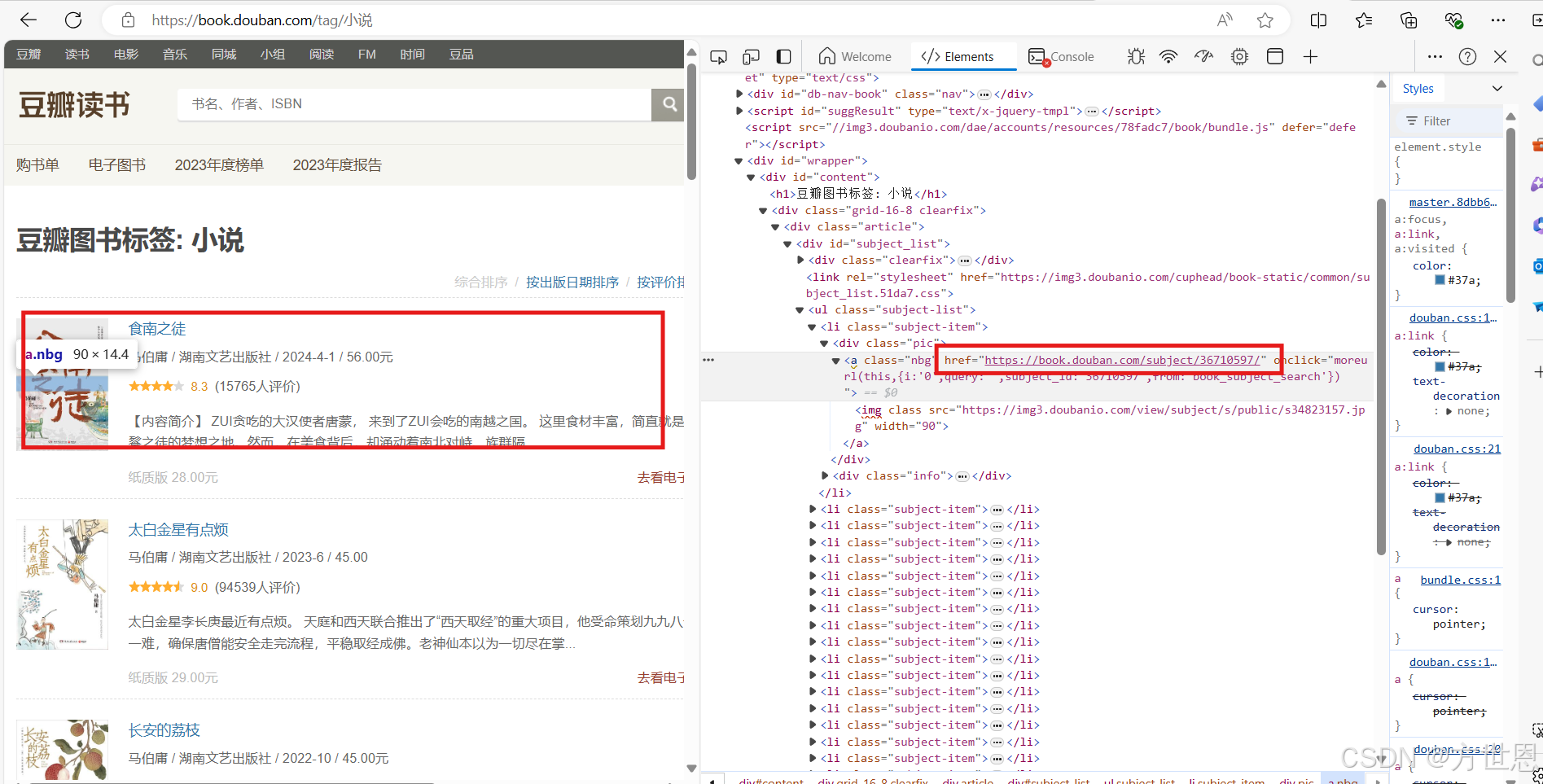
在浏览器点击这本书,我们要通过这个页面进去这本书的详细页面爬取它的详细信息,它的详细页面链接在href标签中。
爬取
指定url
url = "https://book.douban.com/tag/%E4%BA%92%E8%81%94%E7%BD%91" 发送请求
import fake_useragent import requests head = { "User-Agent": fake_useragent.UserAgent().random } resp = requests.get(url, headers=head) 获取想要的数据
from lxml import etree res_text = resp.text 数据解析
tree = etree.HTML(res_text) a_list = tree.xpath("//ul[@class='subject-list']/li/div[2]/h2/a") 定位到位置之后,我们要取到具体的href标签中的链接,再次进行访问请求:

进入深层
爬取这个详细页面的内容:
for a in a_list: # 1、url book_url = "".join(a.xpath("./@href")) # 2、发送请求 book_res = requests.get(book_url, headers=head) # 3、获取想要的信息 book_text = book_res.text # 4、数据解析 book_tree = etree.HTML(book_text) book_name = "".join(book_tree.xpath("//span[@property='v:itemreviewed']/text()")) author = "".join(book_tree.xpath("//div[@class='subject clearfix']/div[2]/span[1]/a/text()")) publish = "".join(book_tree.xpath("//div[@class='subject clearfix']/div[2]/a[1]/text()")) y = "".join(book_tree.xpath("//span[@class='pl' and text()='出版年:']/following-sibling::text()[1]")) page = "".join(book_tree.xpath("//span[@class='pl' and text()='页数:']/following-sibling::text()[1]")) price = "".join(book_tree.xpath("//span[@class='pl' and text()='定价:']/following-sibling::text()[1]")) bind = "".join(book_tree.xpath("//span[@class='pl' and text()='装帧:']/following-sibling::text()[1]")) isbn = "".join(book_tree.xpath("//span[@class='pl' and text()='ISBN:']/following-sibling::text()[1]")) 完整代码显示
# 通过表层内容 深度爬取内部数据 import time import fake_useragent import requests from lxml import etree head = { "User-Agent": fake_useragent.UserAgent().random } if __name__ == '__main__': # 1、url url = "https://book.douban.com/tag/%E4%BA%92%E8%81%94%E7%BD%91" # 2、发送请求 resp = requests.get(url, headers=head) time.sleep(5) #请求时停留5秒,不然请求太快可能会被网页拒绝 # 3、获取想要的数据 res_text = resp.text # print(res_text) # 4、数据解析 tree = etree.HTML(res_text) a_list = tree.xpath("//ul[@class='subject-list']/li/div[2]/h2/a") for a in a_list: time.sleep(3) # 1、url book_url = "".join(a.xpath("./@href")) # 2、发送请求 book_res = requests.get(book_url, headers=head) # 3、获取想要的信息 book_text = book_res.text # 4、数据解析 book_tree = etree.HTML(book_text) book_name = "".join(book_tree.xpath("//span[@property='v:itemreviewed']/text()")) author = "".join(book_tree.xpath("//div[@class='subject clearfix']/div[2]/span[1]/a/text()")) publish = "".join(book_tree.xpath("//div[@class='subject clearfix']/div[2]/a[1]/text()")) y = "".join(book_tree.xpath("//span[@class='pl' and text()='出版年:']/following-sibling::text()[1]")) page = "".join(book_tree.xpath("//span[@class='pl' and text()='页数:']/following-sibling::text()[1]")) price = "".join(book_tree.xpath("//span[@class='pl' and text()='定价:']/following-sibling::text()[1]")) bind = "".join(book_tree.xpath("//span[@class='pl' and text()='装帧:']/following-sibling::text()[1]")) isbn = "".join(book_tree.xpath("//span[@class='pl' and text()='ISBN:']/following-sibling::text()[1]")) print(book_name, author, publish, y, page, price, bind, isbn) # print(a_list) pass 总结
其实与爬取视频的操作相差不大,先定位页面位置,再找到深层页面的链接,获取想要的信息。
