
阅读量:0
原理图
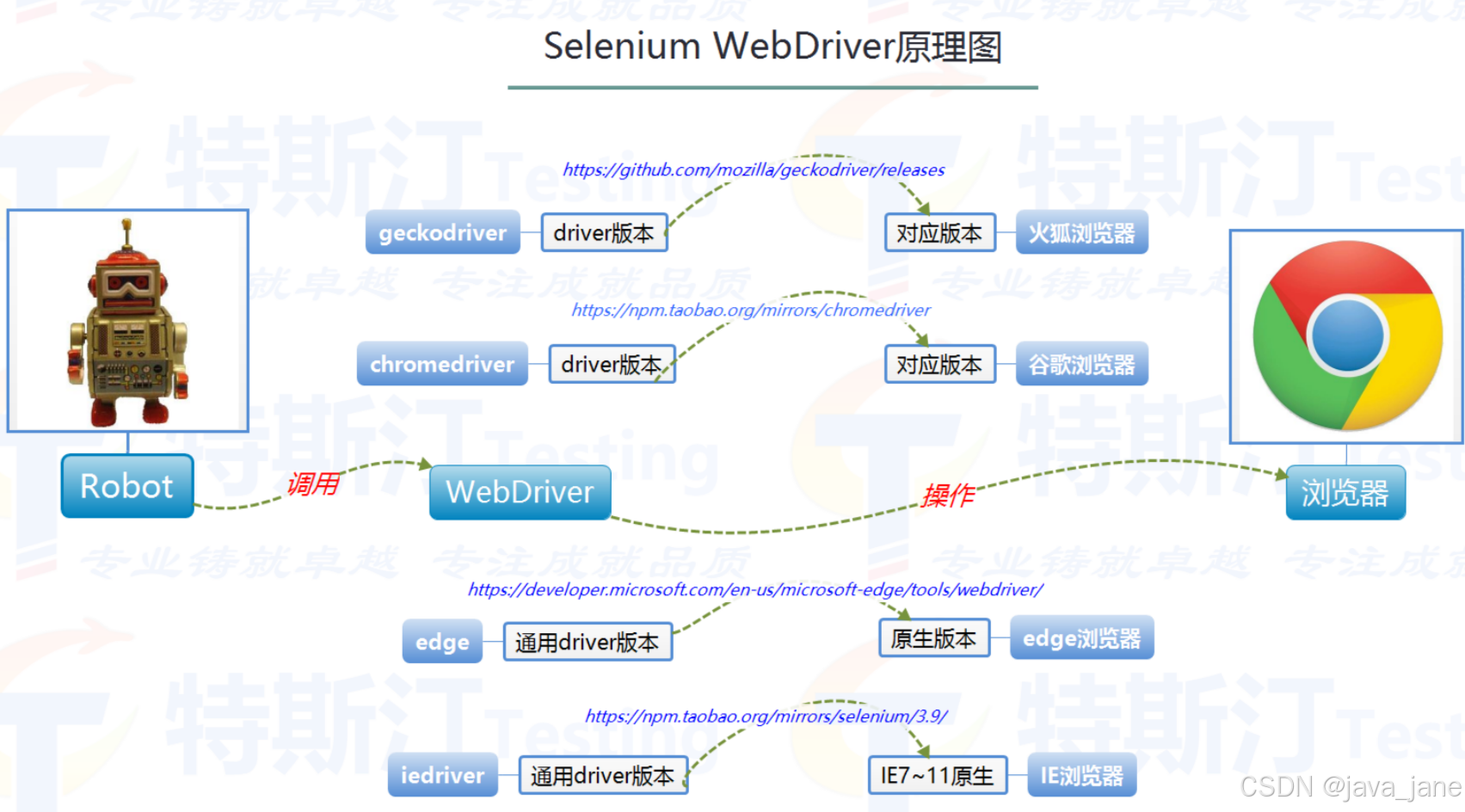
一、下载webdriver--chrome浏览器
根据本机浏览器的版本号下载对应的webdriver版本
http://chromedriver.storage.googleapis.com/index.html
二、安装selenium库
pip install selenium -i Simple Index
三、第一个Web自动化脚本
selenium实现Web自动化的基本步骤:
import time from selenium import webdriver # 打开浏览器 driver = webdriver.Chrome() # 隐式等待 driver.implicitly_wait(10) # driver对象,提供了一系列操作网页的函数(功能) driver.get('http://www.baidu.com') #定位搜索框中输入 ele = driver.find_element('id','kw') #搜索框中输入 ele.send_keys('雷军') time.sleep(2) #点击百度一下 driver.find_element('id','su').click() #延时10s后关闭driver time.sleep(10) driver.quit(); 四、知识点-定位元素
1. id:在元素里面的,id="xxx" (id是唯一的)
ele = driver.find_element('id','username')
或 ele = driver.find_element(By.ID,'username')
2. name:在元素里面的,name="xxx" (name不一定唯一)
ele = driver.find_element('name','username')
3. class name:在元素里面的,class="xxx" (class基本不唯一)
ele = driver.find_element('class name','text_cmu')
4. tag name:在元素最前面<后面这个单词,就是tagname (肯定不唯一)
ele = driver.find_element('tag name','input')
5. link text:在<a>标签中间的文本,我们叫链接文本 (不一定唯一)
ele = driver.find_element('link text','淘宝网')
6. partial link text:在<a>标签中间的文本包含某个文本就可以 (不一定唯一)
ele = driver.find_element('partial link text','淘宝')
7. css selector:在元素dom结构上,右键-copy-copy selector
ele = driver.find_element('css selector','#username')
8. xpath:在元素dom结构上,右键-copy-copy xpath
ele = driver.find_element('xpath','//*[@id="username"]')
五、知识点-操作元素
常用操作
send_keys | 输入 | driver.find_element('xpath','//*[@id="password"]').send_keys('123456') |
click | 点击 | driver.find_element('xpath','//*[@id="loginform"]/div/div[6]/a').click() |
text | 获取文本 | nickname = driver.find_element('xpath','//a[@class="red userinfo"]').text |
get_attribute | 获取属性(元素里面 属性=值,都可以通过它获取 | ele = driver.find_element('link text','淘宝网') |
一般来说,一二步骤是连写的
driver.find_element('xpath','//*[@id="password"]').send_keys('123456')
六、Web自动化报错
报错1:no such element (在网页上没找到这个元素)
原因1:页面存在跳转或者延迟加载,导致元素还没有加载完成,代码就已经跑完了
解决方案:添加隐式等待
# 添加隐式等待 driver.implicitly_wait(5)原因2:定位方式错误。比如xpath写错,classname带空格等
解决方案:更换定位方式
