
阅读量:0
1.基本定义:
语义:就是一句话的重点是什么。
自定词汇:因为语言、文字太多,自定和处理你所关心的重点词汇。
简体转繁体代码
from opencc import OpenCC text1 = "我去过清华大学" openCC = OpenCC('s2t') line = openCC.convert(text1) print(" "+text1) # 打印原文本 print("s2t;"+line) # 打印转换后的文本结果如下:

2.中文分词断词工具
在中文分词的处理方面,Python有几个第三方的程序pymmseg、smallseg和jieba,本节将介绍的是jieba。这个需要先安装。
pip install jieba原理: jieba中文分词所使用的算法是通过Trie Tree(又称前缀树或字典树)结构去创建句子,根据文字所有可能成词的情况,通过动态规划算法找出最大概率的路径,这个路径就是基于词频的最大断词结果。对于字典词库中不存在的词,则使用HMM(Hidden Markov Model,隐马尔可夫模型)及Viterbi算法来辨识出来。
一个小demo
import jieba text1="我去过清华大学" test2="小明来到了行研大厦" seg_list=jieba.cut(text1,cut_all=True,HMM=False) print("Full Mode:"+"/".join(seg_list)) seg_list=jieba.cut(text1,cut_all=False,HMM=True) print("Default Mode:"+"/".join(seg_list)) print(",".join(jieba.cut(test2,HMM=True))) print(",".join(jieba.cut(test2,HMM=False))) print(",".join(jieba.cut(test2))) print(",".join(jieba.cut_for_search(test2))) 运行结果

上面的几种模式:
Full Mode(全模式):试图将句子最精确地切开,适合文本分析,输出的是所有可能的分词组合,比如清华大学,会被分成:清华、清华大学、华大、大学。
Default Mode(精确模型):把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义,比如清华大学,只会输出清华大学。
jieba.cut_for_search(搜索引擎模式):在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
注意有些词分割不正确,可以自己进行设置jieba.load_userdict("userdict.txt")这样再次通过jieba.cut(text)切割后就会达到自己的预期了。取得词性jieba.posseg.cut(text)
3.使用TF-IDF算法的关键词计算
jieba.analyse.extract_tags(content, topK = 20, withWeight = True, allowPOS=( ))参数如下:
· content:待处理的文字。
· topK:返回关键词的数量,重要性权重TF-IDF从高到低排序,如topK=20,就是回传20个最重要的分词。
· withWeight:设置为True或False,即是否返回每个关键词的权重TF-IDF。
· allowPOS:词性过滤,为空表示不过滤。词性,如同jieba.posseg.cut所输出的内容,即n是名词、v是动词。
关键词的权重(TF-IDF)也就是这个关键词在这篇文章中所出现的比重。有很多不同的数学公式可以用来计算TF-IDF,具体公式不在详细介绍。
import sys from os import path import jieba import jieba.analyse # 取得现在的路径 d = path.dirname(__file__) # 读取文本 with open(path.join(d, "C:\\Users\\nsy\\Desktop\\test.txt"), 'r', encoding='utf-8') as f: text = f.read() # 去除不要的文字 text = text.replace("", "") # 这里假设您要替换的是一个特定的字符串,但原代码中是空的 text = text.replace("「", "") text = text.replace("」", "") text = text.replace(",", "") text = text.replace(" ", "") # 使用jieba进行分词 print('/'.join(jieba.cut(text))) # 开启HMM做分词动作 # 样例1使用自定义字典 jieba.load_userdict(path.join(d, "C:\\Users\\nsy\\Desktop\\userdict.txt.txt")) # 加载自定义字典 # 再次使用自定义字典进行分词 print('/'.join(jieba.cut(text))) # 样例2取得词性 words = jieba.posseg.cut(text) for word, flag in words: print('%s, %s' % (word, flag)) # 显示切割的词语和词性 # 样例3和样例4取得关键字 if sys.version_info > (3, 0): content = text else: content = text.decode('utf-8') keywords = jieba.analyse.extract_tags(content, topK=20, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v')) # 访问捕获结果 for item in keywords: print('%s=%f' % (item[0], item[1])) # 分别为关键词和相应的权重 print("程序执行完毕")运行结果:
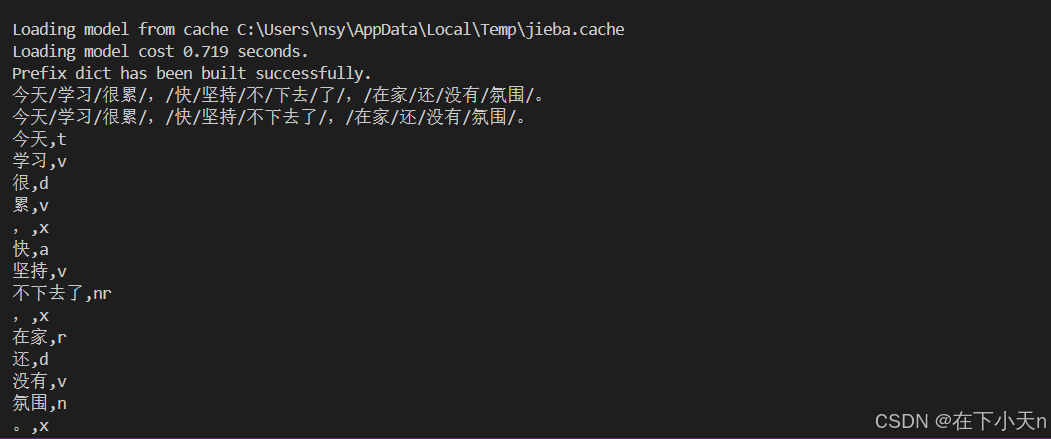
4.自定分词
jieba.load_userdict,在jieba之中,还有另一个类似的函数jieba.suggest_freq。
from os import path import jieba import jieba.analyse d=path.dirname(__file__) text="今天学习好累,还没有效率" text=text.replace(",","") print('/'.join(jieba.cut(text))) jieba.suggest_freq('还没有',True) print('/'.join(jieba.cut(text))) 取出断词位置
jieba.tokenize(文字)import sys from os import path import jieba # 获取脚本文件的目录 d = path.dirname(__file__) # 定义自定义词典的路径 userdict_path = path.join(d, "C:\\Users\\nsy\\Desktop\\userdict.txt.txt") # 加载自定义词典 jieba.load_userdict(userdict_path) # 定义要分词的文本 content = "今天学习好累,在家还没有效率" # 使用自定义词典进行精确模式分词 print('default' + '-'*40) result = jieba.cut(content, use_paddle=False) # 精确模式 for word in result: print(word) # 使用自定义词典进行搜索引擎模式分词 print('tokenize search' + '-'*40) result = jieba.cut_for_search(content) # 搜索引擎模式 for word in result: print(word)