
阅读量:0
1. 相关概念
不理解技术的相关概念,看技术书籍或者文档时,就会变得晦涩难懂。基础不牢地动山摇。
(1)数据模型(data model)
数据模型指的是数据的定义格式,即数据是如何组织的。关系数据模型是以【二维表】来表示实体与实体之间的关系。
| 员工编号 | 姓名 | 性别 | 职位 | 部门 |
|---|---|---|---|---|
| 1 | 章三 | 男 | 软件开发经理 | 软件开发部 |
| 项目编号 | 项目名称 | 项目经理 | 研发 | 测试 | 运维 | 售后 |
|---|---|---|---|---|---|---|
| 1024 | 同花顺 | 王五 | 章三 | 李四 | 王二麻 | 陈老六 |
从这两个表中可以看出项目和员工之间存在某种关系。众多的关系表,以及表之间的关系,构成了关系数据模型,而支持关系模型的数据库管理系统则称之为【关系型数据库管理系统】。
其它模型:
XML:带有层次的数据模型,使用标签、标签值来标识信息。
<!-- Spring配置示例 --> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource"> <property name="driverClassName" value="com.mysql.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost:3306/mydb"/> <property name="username" value="root"/> <property name="password" value="password"/> </bean> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="dataSource"/> <property name="configLocation" value="classpath:mybatis-config.xml"/> <property name="mapperLocations" value="classpath*:com/example/mapper/*.xml"/> </bean> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="com.example.mapper"/> </bean> </beans> 图数据模型:它使用节点和边来描述数据之间的关系。这种模型通过将数据实体表示为节点,并将实体之间的关系表示为边,从而在图形化的方式下展示数据。图数据模型的主要特点是能够直观地展示数据之间的复杂关系,并且易于理解和分析。
(2) 模式 Schema
Schema指的是数据库管理系统支持的数据结构,不同的数据库Schema含义不同。像典型的关系型数据库,是以数据库表的形式来存储数据,数据存储在设计好的表中。【Schema就是指数据库中各种关系的结构化描述】。数据建模也就是设计数据库表及表关系的过程。
(3)结构化数据
通常指被记录的信息的类型和格式,一般可存储于关系数据库或电子表格中。结构化数据的存储往往需要预先定义好业务数据模型,确定哪些数据需要存储,存储的类型和格式,访问时的校验和处理。
(4)非结构化数据
有些信息无法用数字或统一的结构表示,如:文本、照片和图形图像、声音、视频、PDF文件、演示文稿、电子邮件、博客等等,我们称其为非结构化数据。
(5)半结构化数据
介于结构化和非结构化之间,可以看作结构化数据,但是缺少严格的数据模型,一般使用XML这种标签语言管理半结构化数据。
举例子:博客中,姓名、年龄、创作日期等是结构化数据,但是文本内容是非结构化数据。
现实中的数据并不是总能被固定的数据结构来描述,生活也不是整齐的小盒子。非结构化数据和半结构化数据正以惊人的速度增长,在大数据时代,非结构化和半结构化数据的提取、存储和管理一直是个难点,非结构化数据能否被有效地管理和应用,这对于企业未来的发展道路影响深远。
(6)DDL
数据定义语言(Data Definition Language,DDL)是负责数据结构定义和数据库对象定义的语言,不针对数据操作,只对数据库和表结构操作。
# 创建数据库 CREATE DATABASE mydatabase; # 创建表 CREATE TABLE users ( id INT PRIMARY KEY, username VARCHAR(50) NOT NULL, password VARCHAR(50) NOT NULL, email VARCHAR(100) ); # 修改表 ALTER TABLE users ADD age INT; # 创建索引 CREATE INDEX idx_username ON users(username); # 删除表 DROP TABLE users; # 删除数据库 DROP DATABASE mydatabase; (7)DML
数据操作语言(Data Mainpulation Language,DML)用来查询和修改数据的语言。对数据进行操作的语言。开发人员称之为CRUD。
-- 插入单条数据 INSERT INTO 表名(列1, 列2, 列3, ...) VALUES (值1, 值2, 值3, ...); -- 插入多条数据 INSERT INTO 表名(列1, 列2, 列3, ...) VALUES (值1, 值2, 值3, ...), (值1, 值2, 值3, ...), ...; -- 更新表中的数据 UPDATE 表名 SET 列1 = 值1, 列2 = 值2, ... WHERE 条件; -- 删除表中的数据 DELETE FROM 表名 WHERE 条件; -- 查询表中的数据 SELECT 列1, 列2, ... FROM 表名 WHERE 条件; 2. 数据模型相关概念
(1)结构化查询语言SQL
是一种高级的非过程化编程语言,它已经成为事实上的工业标准而被广泛使用,程序员必须掌握的标准技能。
(2)NULL
如果某个字段值未确定或者未定义,数据库会提供特殊的值NULL来表示。NULL值很特殊,在关系型数据库要小心处理。有时不会包含在查询结果中。
(3)key和索引
key用于唯一标识一个记录或者多个字段的组合。key不一定唯一标识一整个记录。(还有一些术语:索引、主键索引、唯一索引,后面谈。)
我们可以通过key或索引检索某个记录,数据库管理系统为了提高检索速度,往往会创建各种索引结构加速检索记录,或者按照表之间的关联,表之间的关联往往也是通过索引来关联的。
(4)实体与关系建模
- ER建模
全称为实体关系建模,是一种数据模型或模式图,用于描述实体之间的联系。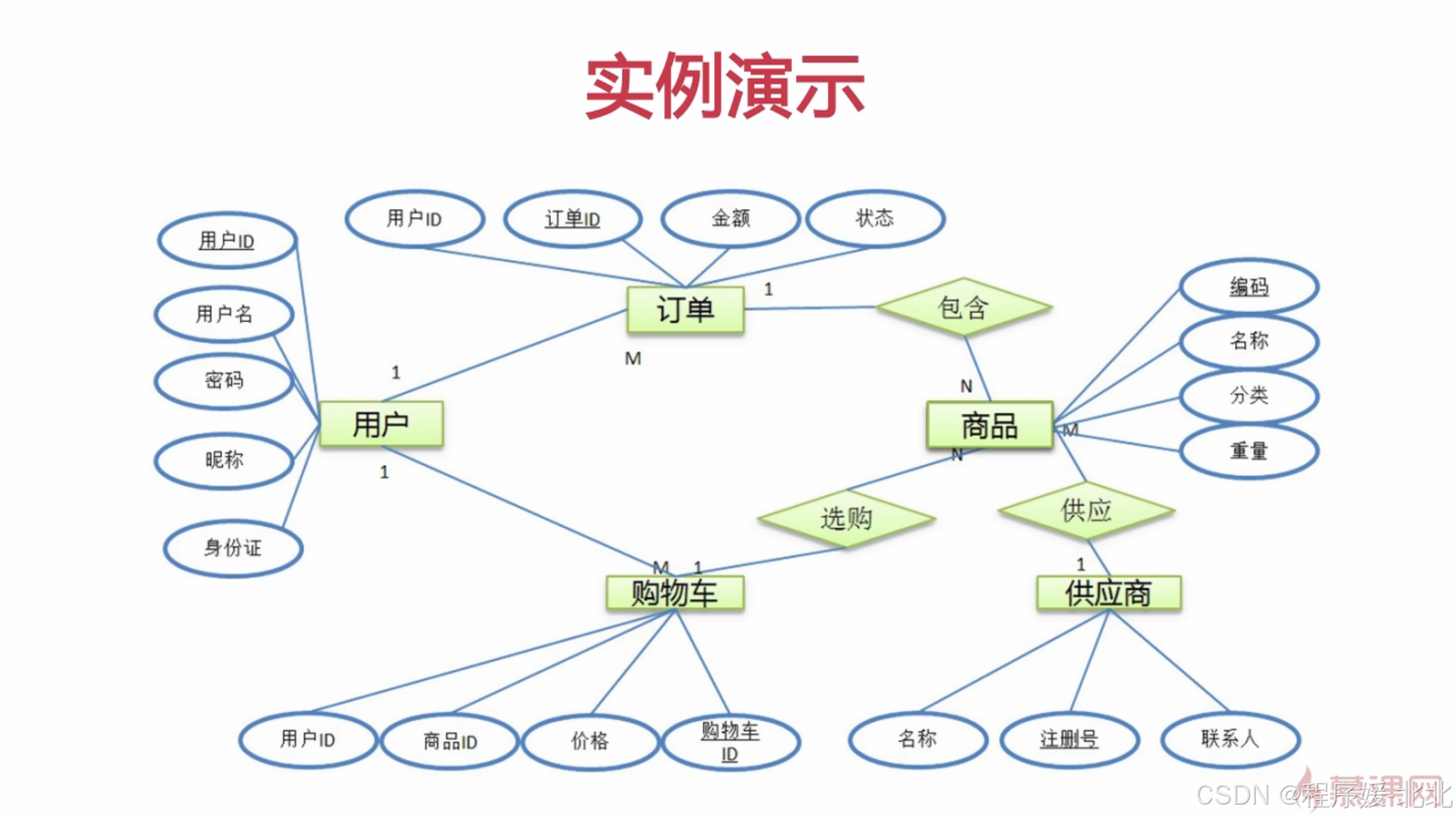
(2)UML 统一建模语言
以图形化的方式表示实体和实体之间的关系。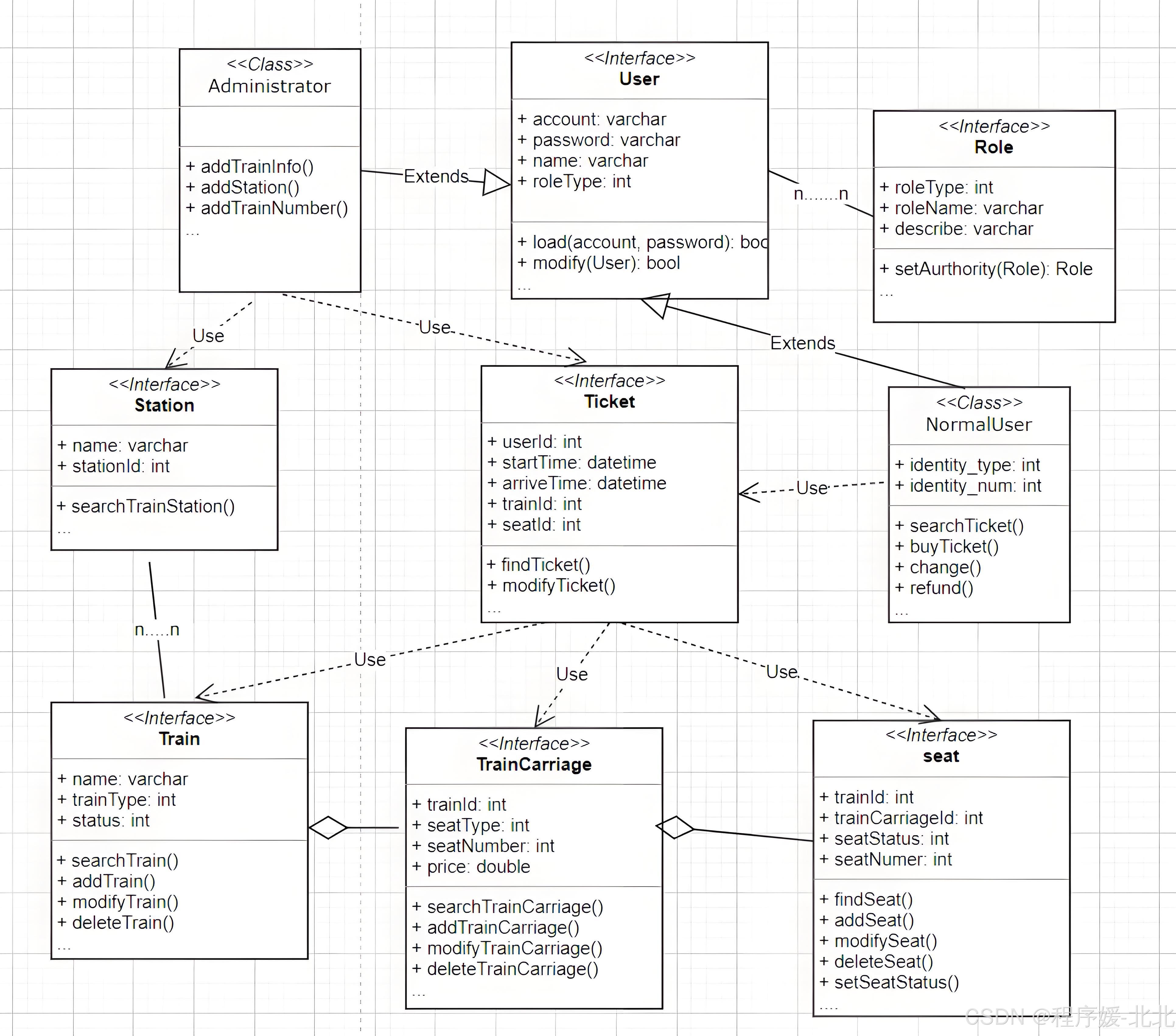
(3)XML数据模型
XML,又叫可扩展标记语言。XML被用来设计为传输和存储数据,标签描述的是数据的内容。格式与HTML很像,但是HTML是被用来显示数据的。
(4)JSON数据模型
JSON也适用于存储半结构化数据,JSON虽然出现的比XML晚,但JSON更加简洁,更符合程序语言的表达方式,因此,在互联网开发中,一般选择JSON而不是XML。事实上,JSON已经成为前端与服务端的数据交换格式,前端程序员通过Ajax发送JSON对象到后端,服务器端对JSON进行解析,将其还原成服务端对象,然后进行一些处理,再返回给前端JSO N数据。
3. SQL基础
SQL是一种高级查询语言,它是声明式的,只需要描述获取哪些数据,而不用管数据是怎么获取的,这个过程交给了解析器与优化器处理。(后面再谈及)
变量
SQL中的变量分为用户变量 和 系统变量。
- 用户变量 : 一个客户端定义的变量不能被其他客户端看到或使用。当客户端退出时,该客户端连接的所有变量都将自动释放。
SET @var1=0 , @var2='章三' , @var3=(SELECT min(goods_id) FROM goods); - 全局变量 : 当服务启动时,MySQL将所有全局变量设置为默认值。这些默认值可以在选中文件中或者命令行中更改;服务器启动后,也可以通过
SET GLOBAL var_name语句,可以动态修改全局变量,想修改全局变量必须有SUPER权限,影响范围也只限于当前客户端和修改后连接的客户端。如果使用了连接池或者长连接的技术,也就不会有重连的操作,可能全局变量不会被修改。
-- 设置GLOBAL变量值 SET global sort_buffer_size=value; SET @@global.sort_buffer_size=value; -- 设置session变量值 SET session sort_buffer_size=value; SET @@session.sort_buffer_size=value; SET sort_buffer_size=value; -- 不指定 global、session、local,默认为session -- 检索global SELECT @@global.sort_buffer_size; SHOW global variables like 'sort_buffer_size'; SQL常见操作
-- 查询Mysql版本和当前日期 select version(),current_date(); -- 创建数据库/显示数据库 create database company_db; show databases; -- 切换数据库/显示当前正在使用的数据库 use company_db; select database(); -- 显示当前数据库下所有表 show tables; -- 描述表结构 desc table_name; DDL 常见操作
-- CREATE INDEX创建索引 -- 在goods表goods_id上创建索引 create index id_index on goods(goods_id); -- 在goods表name上创建索引,索引使用name列前10个字符 create index name_index on goods(goods_name(10)); -- 在goods表 id、name、price创建复合索引 create index id_name_price_index on goods(goods_id,goods_name,goods_price); -- 删除索引 drop index name_index on goods; DML常见操作
(1)SQL通配符 _ 、%、[]
- _ : 匹配任意单个字符
- % : 匹配任意多个字符,包括0
- [charlist] : 匹配框中任意单一字符
- [^charlist] : 匹配未列出的任意单一字符
一般搭配LIKE或NOT LIKE
-- 查找所有以"J"开头的姓名: SELECT * FROM Customers WHERE CustomerName LIKE 'J%'; --查找所有第二个字符为"a"的姓名: SELECT * FROM Customers WHERE CustomerName LIKE '_a%'; -- 查找所有姓名以"s"结尾的顾客: SELECT * FROM Customers WHERE CustomerName LIKE '%s'; -- 查找所有姓名不以"A"、"B"或"C"开头的顾客: SELECT * FROM Customers WHERE CustomerName LIKE '[!ABC]%'; (2)SQL逻辑操作符 and、or、not、between and 、in
-- 假设我们有一个名为 Employees 的表格,它包含以下列: -- EmployeeID, FirstName, LastName, BirthDate, Gender, HireDate, Salary, DepartmentID -- 查询 DepartmentID 为 10 的所有员工信息 SELECT * FROM Employees WHERE DepartmentID = 10; -- 查询 DepartmentID 为 20 且薪水大于 5000 的所有员工信息 SELECT * FROM Employees WHERE DepartmentID = 20 AND Salary > 5000; -- 查询 DepartmentID 为 30 或者薪水大于 6000 的所有员工信息 SELECT * FROM Employees WHERE DepartmentID = 30 OR Salary > 6000; -- 查询名字以 'J' 开头的所有员工信息 SELECT * FROM Employees WHERE FirstName LIKE 'J%'; -- 查询名字以 'son' 结尾的所有员工信息 SELECT * FROM Employees WHERE LastName LIKE '%son'; -- 查询名字包含 'e' 的所有员工信息 SELECT * FROM Employees WHERE FirstName LIKE '%e%'; -- 查询在指定日期 '2000-01-01' 之后入职的所有员工信息 SELECT * FROM Employees WHERE HireDate > '2000-01-01'; -- 查询在指定日期 '1990-01-01' 之前出生的所有员工信息 SELECT * FROM Employees WHERE BirthDate < '1990-01-01'; -- 查询薪水在 4500 到 6500 之间的所有员工信息 SELECT * FROM Employees WHERE Salary BETWEEN 4500 AND 6500; -- 查询不在指定部门(DepartmentID 不等于 10 且不等于 20)的员工信息 SELECT * FROM Employees WHERE DepartmentID NOT IN (10, 20); -- 查询薪水为 NULL 的所有员工信息 SELECT * FROM Employees WHERE Salary IS NULL; -- 查询名字为 'John' 且姓 'Doe' 的员工信息 SELECT * FROM Employees WHERE FirstName = 'John' AND LastName = 'Doe'; -- 查询名字为 'Jane' 或者 'John' 的员工信息 SELECT * FROM Employees WHERE FirstName = 'Jane' OR FirstName = 'John'; (3) order by 对结果集进行排序
支持升序(ASC)和降序(DESC)排序。如果不指定排序方向,默认是升序排序。
-- 按照公司名称的字母顺序进行排序,同时按照订单号的数字顺序进行排序。 SELECT Company, OrderNumber FROM Orders ORDER BY Company ASC, OrderNumber ASC -- 先按公司名称排序,如果公司名称相同,再按订单号排序 SELECT Company, OrderNumber FROM Orders ORDER BY Company ASC, OrderNumber DESC 分页查询:在使用ORDER BY进行排序的同时,还可以结合使用OFFSET和FETCH子句来实现查询结果的分页,这在处理大量数据时特别有用。例如:
-- 这条语句将从第11条记录开始,获取接下来的5条记录。 SELECT * FROM Orders ORDER BY OrderNumber OFFSET 10 ROWS FETCH NEXT 5 ROWS ONLY limit 分页查询
-- 格式 SELECT * FROM 表名 LIMIT 每页数量 OFFSET 偏移量; -- 小算法,很重要 SELECT * FROM 表名 LIMIT (页码-1)*每页数量, 每页数量; SELECT * FROM users LIMIT 0, 10; -- 查询第一页的数据 SELECT * FROM users LIMIT 10, 10; -- 查询第二页的数据 distinct 获取不重复唯一值
-- 获取所有不同的部门 SELECT DISTINCT department FROM employees; -- 获取多个字段的组合的唯一值,可以在 SELECT DISTINCT 后面列出多个字段名 SELECT DISTINCT first_name, last_name FROM employees; group by分组
-- 在MySQL中,GROUP BY语句用于将结果集合中的记录分组,通常与聚合函数(如SUM(), COUNT(), MAX(), MIN()等)一起使用。 -- 格式 SELECT column_name(s) FROM table_name WHERE condition GROUP BY column_name(s); -- 假设我们有一个名为orders的表,它有order_id, product_id 和 quantity 三个字段。我们想要按product_id对订单进行分组,并计算每个产品的总订单量: SELECT product_id, SUM(quantity) as total_quantity FROM orders GROUP BY product_id; union/union all 结果集合并
union和union all都是对结果集进行合并,区别:
union实际上是union distinct ,在进行表连接后会筛选重复的记录,所以在表连接后会对产生的结果集进行排序运算,删除重复的记录再返回。而union all不管重不重复都返回合并后的记录。
-- 把会员表和管理员表合并 select * from `member` union all(select * from `admin`); JOIN连接
MySQL使用JOIN连接多个表,算法就一个 nested-loop join(嵌套循环连接),机制也很简单,就是从驱动表中选取数据作为循环基础数据,然后这些数据作为查询条件到下一个表中进行查询,如此往复。这个实现机制类似foreach函数的遍历/因此带来的问题就是连接的表越多,函数嵌套的层数就越多,算法复杂程度呈指数级增长。
因此,设计查询尽量减少连接的表的个数。
JOIN语句的含义是把两张以上的表,通过属性值把他们组合在一起,一般会遇到三种连接:
- 等值连接
- 左外连接
- 右外连接
(1)内连接
它基于两个或多个表中的共同字段值来返回记录。只有在两个表中都有匹配的字段值时,记录才会返回。
-- 假设我们有两个表,一个是员工表 employees 和一个是部门表 departments。 -- 查询所有员工及部门信息 SELECT employees.employee_name, departments.department_name FROM employees INNER JOIN departments ON employees.department_id = departments.department_id; (2)外连接
- 左外连接
MySQL左外连接(LEFT OUTER JOIN)是一种SQL查询操作,它返回左表(LEFT JOIN之前的表)的所有记录,以及右表(LEFT JOIN之后的表)中的匹配记录。如果右表没有匹配,则结果中右表的部分会用NULL填充。
-- 格式 SELECT columns FROM table1 LEFT JOIN table2 ON table1.column_name = table2.column_name; -- 获取所有员工的姓名以及他们所在部门的名字。如果某个员工没有对应的部门信息,也会在结果中显示,其部门名字会显示为NULL。 SELECT employees.name, departments.department_name FROM employees LEFT JOIN departments ON employees.department_id = departments.department_id; - 右外连接
回右侧表的所有记录,以及左侧表中匹配的记录。如果左侧表中没有匹配,则结果中右侧表的列将返回NULL。
-- 获取所有部门的信息以及对应的员工信息(如果有的话)。 SELECT employees.name AS employee_name, departments.name AS department_name FROM employees RIGHT JOIN departments ON employees.department_id = departments.id; 子查询
子查询是嵌套在另一个 SELECT, INSERT, UPDATE, 或 DELETE查询的 SQL 查询。子查询可以在 WHERE 子句中、FROM 子句或 SELECT 列表中出现。
-- 在 WHERE 子句中使用子查询: SELECT column_name FROM table1 WHERE column_name = (SELECT column_name2 FROM table2 WHERE condition); -- 在 FROM 子句中使用子查询(为查询返回的结果提供一个临时的表): SELECT a.column_name1, b.column_name2 FROM (SELECT column_name1 FROM table1 WHERE condition1) AS a JOIN (SELECT column_name2 FROM table2 WHERE condition2) AS b ON a.column_name1 = b.column_name2; -- 在 SELECT 列表中使用子查询 SELECT (SELECT column_name FROM table2 WHERE table2.column_name = table1.column_name) AS column_name_alias FROM table1; 