
阅读量:0
背景:搜索引擎ElasticSearch8.X+SpringBoo3.X的用途如下
实时搜索功能:ElasticSearch是一个开源的实时分布式搜索和分析引擎,它能够实现高效的实时搜索功能。学习ElasticSearch可以帮助我们构建强大的搜索功能,提升用户体验和搜索效率,多数互联网公司里面用的技术,构建业务搜索/日志存储分析/可视化大屏
数据分析能力:ElasticSearch不仅仅可以用于搜索功能,还可以用于数据分析和数据可视化。学习ElasticSearch可以帮助我们深入了解数据分析的原理和方法,提升我们的数据分析能力。
分布式系统:ElasticSearch是一个分布式系统,可以在多个节点上分布数据和处理请求。学习ElasticSearch可以帮助我们了解分布式系统的设计和实现原理,提升我们的分布式系统开发能力。
Spring Boot和ElasticSearch的结合:Spring Boot是一个快速开发框架,可以帮助我们快速构建企业级应用程序。学习Spring Boot和ElasticSearch的结合可以帮助我们构建强大的搜索引擎应用程序,提升我们的开发效率。
有谁在用,进一线大厂(国内大厂多数都有用 ),国内:阿里、字节、腾讯 、微信、网易、虎牙、青云、新浪等;国外:谷歌、Facebook、亚马逊、苹果等;产品:维基百科、Github、StackOverFlow都是使用ElasticSearch存储数据
学完我们这个文章后的能力
ElasticStack8.X核心架构和应用场景,实战云服务器选购+Linux服务器源码安装
源码安装Kibana8.X+ES8.X常用命令操作,多案例实战Index和Document核心操作
ES8.X映射Mapping定义和IK中文分词配置Query DSL多案例 match/match_all/filter/
match高级用法多字段匹配和短语搜索案例,单词纠错Fuzzy模糊查询和搜索高亮语法实战
Agg指标metric聚合搜索sum/avg/max/Trem/Range/Date Histogram多案例实战
新版SpringBoot3.X+ElasticSearch8.X整合多案例实战
什么是Elastic Stack?
学习ElasticSearch之前,需要知道下什么是Elastic Stack?是一个开源的数据分析和可视化平台,由Elasticsearch、Logstash、Kibana和Beats组成。
很多同学听说过ELK,实际上ELK是三款软件的简称,分别是Elasticsearch、 Logstash、Kibana组成,在发展的过程中有新成员Beats的加入,所以就形成了Elastic Stack,ELK是旧的称呼,Elastic Stack是新的名字
ElasticSearch:一个分布式实时搜索和分析引擎,高性能和可伸缩性闻名,能够快速地存储、搜索和分析大量结构化和非结构化数据,基于java开发,它是Elastic Stack的核心组件,提供分布式数据存储和搜索能力。
Logstash:是一个用于数据收集、转换和传输的数据处理引擎,支持从各种来源(如文件、日志、数据库等)收集数据;基于java开发,并对数据进行结构化、过滤和转换,然后将数据发送到Elasticsearch等目标存储或分析系统。
Kibana:基于node.js开发,数据可视化和仪表盘工具,连接到Elasticsearch,通过简单易用的用户界面创建各种图表、图形和仪表盘;帮助用户快速探索和理解数据,并进行强大的数据分析和可视化
ElasticSearch8.X核心概念
在新版Elasticsearch中,文档document就是一行记录(json),而这些记录存在于索引库(index)中, 索引名称必须是小写,下面对比关系性数据库Mysql,好轻松理解相关概念
| Mysql数据库 | Elastic Search |
|---|---|
| Database | 7.X版本前有Type,对比数据库中的表,新版取消了 |
| Table | Index |
| Row | Document |
| Column | Field |
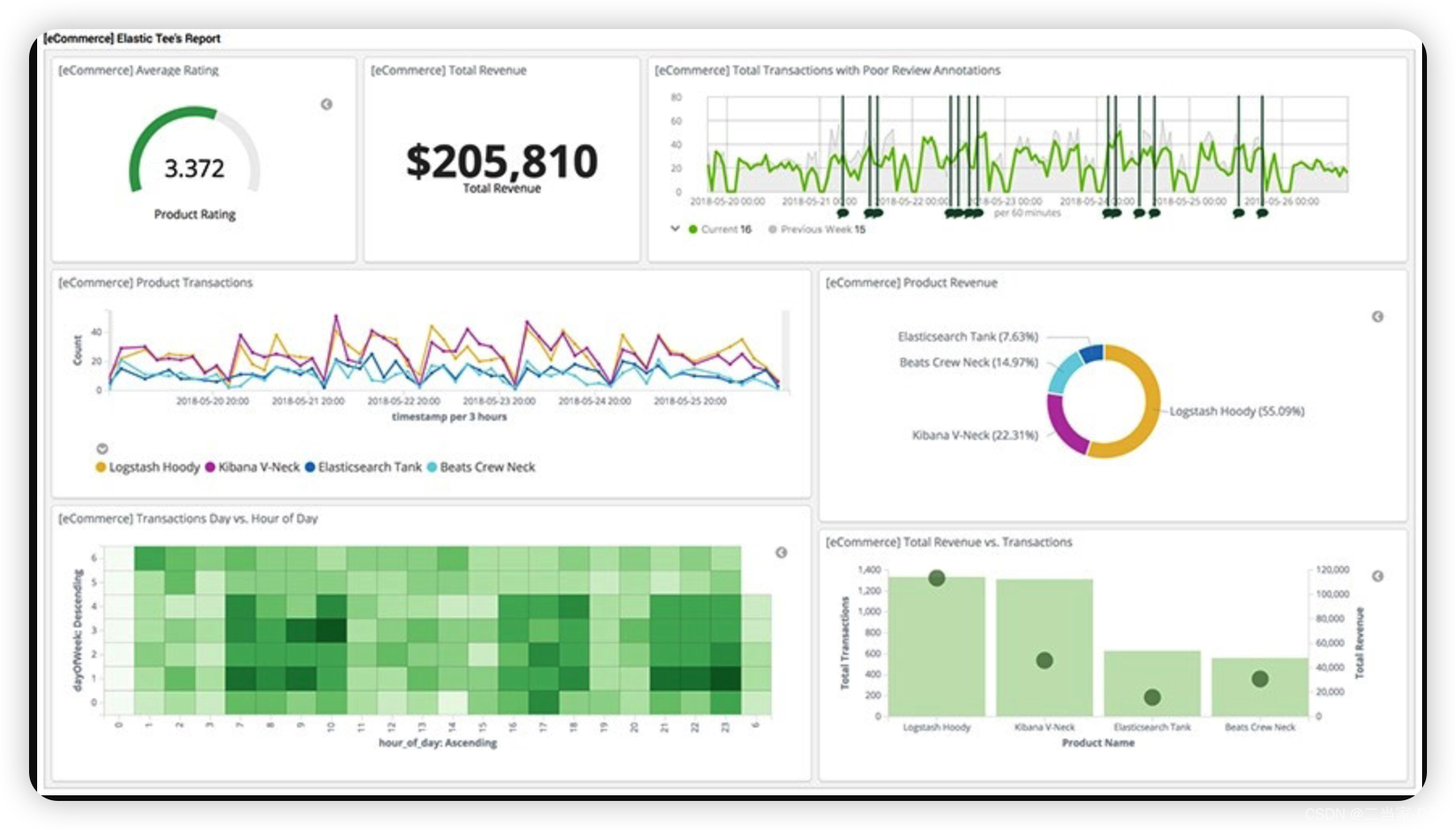
分片shards:数据量特大,没有足够大的硬盘空间来一次性存储,且一次性搜索那么多的数据,响应跟不上,2ES提供把数据进行分片存储,这样方便进行拓展和提高吞吐
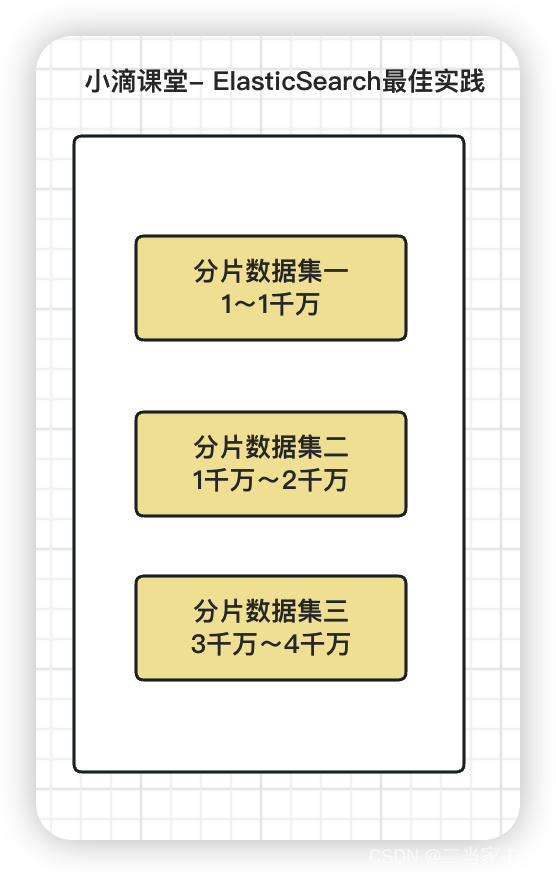
副本replicas:分片的拷贝,当主分片不可用的时候,副本就充当主分片进行使用,索引分片的备份,shard和replica一般存储在不同的节点上,用来提高可靠性
元数据:Elasticsearch中以 “ _” 开头的属性都成为元数据,都有自己特定的意思
ES默认为一个索引创建1个主分片和1个副本,在创建索引的时候使用settings属性指定,每个分片必须有零到多个副本
注意:索引一旦创建成功,主分片primary shard数量不可以变(只能重建索引),副本数量可以改变
Linux服务器源码安装JDK17+ElasticSearch8.X实战(结尾有安装包)
第一步:上传JDK17+ElasticSearch8.X相关安装包
第二步:安装JDK17
vim /etc/profile #增加下面内容 JAVA_HOME=/usr/local/software/elk_test/jdk17 CLASSPATH=$JAVA_HOME/lib/ PATH=$PATH:$JAVA_HOME/bin export PATH JAVA_HOME CLASSPATH 环境变量立刻生效 source /etc/profile第三步:安装ElasticSearc8.X和配置相关
#上传安装包和解压 tar -zxvf elasticsearch-8.4.1-linux-x86_64.tar.gz #新建一个用户,安全考虑,elasticsearch默认不允许以root账号运行 创建用户:useradd es_user 设置密码:passwd es_user #修改目录权限 # chmod是更改文件的权限 # chown是改改文件的属主与属组 # chgrp只是更改文件的属组。 chgrp -R es_user /usr/local/software/elk_test/elasticsearch-8.4.1 chown -R es_user /usr/local/software/elk_test/elasticsearch-8.4.1 chmod -R 777 /usr/local/software/elk_test/elasticsearch-8.4.1 # 修改文件和进程最大打开数,需要root用户,如果系统本身有这个文件最大打开数和进程最大打开数配置,则不用 在文件内容最后添加后面两行(切记*不能省略) vim /etc/security/limits.conf * soft nofile 65536 * hard nofile 65536 #修改虚拟内存空间,默认太小 在配置文件中改配置 最后一行上加上,执行 sysctl -p(立即生效) vim /etc/sysctl.conf vm.max_map_count=262144 #修改elasticsearch的JVM内存,机器内存不足,常规线上推荐16到24G内存 vim config/jvm.options -Xms1g -Xmx1g # 修改 elasticsearch相关配置 vim config/elasticsearch.yml cluster.name: my-application node.name: node-1 path.data: /usr/local/software/elk_test/elasticsearch-8.4.1/data path.logs: /usr/local/software/elk_test/elasticsearch-8.4.1/logs network.host: 0.0.0.0 http.port: 9200 cluster.initial_master_nodes: ["node-1"] xpack.security.enabled: false xpack.security.enrollment.enabled: false ingest.geoip.downloader.enabled: false配置说明
cluster.name: 指定Elasticsearch集群的名称。所有具有相同集群名称的节点将组成一个集群。 node.name: 指定节点的名称。每个节点在集群中应该具有唯一的名称。 path.data: 指定用于存储Elasticsearch索引数据的路径。 path.logs: 指定Elasticsearch日志文件的存储路径。 network.host: 指定节点监听的网络接口地址。0.0.0.0表示监听所有可用的网络接口,开启远程访问连接 http.port: 指定节点上的HTTP服务监听的端口号。默认情况下,Elasticsearch的HTTP端口是9200。 cluster.initial_master_nodes: 指定在启动集群时作为初始主节点的节点名称。 xpack.security.enabled: 指定是否启用Elasticsearch的安全特性。在这里它被禁用(false),意味着不使用安全功能。 xpack.security.enrollment.enabled: 指定是否启用Elasticsearch的安全认证和密钥管理特性。在这里它被禁用(false)。 ingest.geoip.downloader.enabled: 指定是否启用GeoIP数据库下载功能。在这里它被禁用(false)启动ElasticSearch
切换到es_user用户启动, 进入bin目录下启动, &为后台启动,再次提示es消息时 Ctrl + c 跳出 ./elasticsearch & #安装命令,可以检查端口占用情况 yum install lsof -y常见命令,可以用postman访问(网络安全组记得开发端口)
#查看集群健康情况 http://120.78.85.91:9200/_cluster/health #查看分片情况 http://120.78.85.91:9200/_cat/shards?v=true&pretty #查看节点分布情况 http://120.78.85.91:9200/_cat/nodes?v=true&pretty #查看索引列表 http://120.78.85.91:9200/_cat/indices?v=true&pretty常见问题
磁盘空间需要85%以下,不然ES状态会不正常 不要用root用户安装 linux内存不够 linux文件句柄 没开启远程访问 或者 网络安全组没看开放端口 有9300 tcp端口,和http 9200端口,要区分 没权限访问,重新执行目录权限分配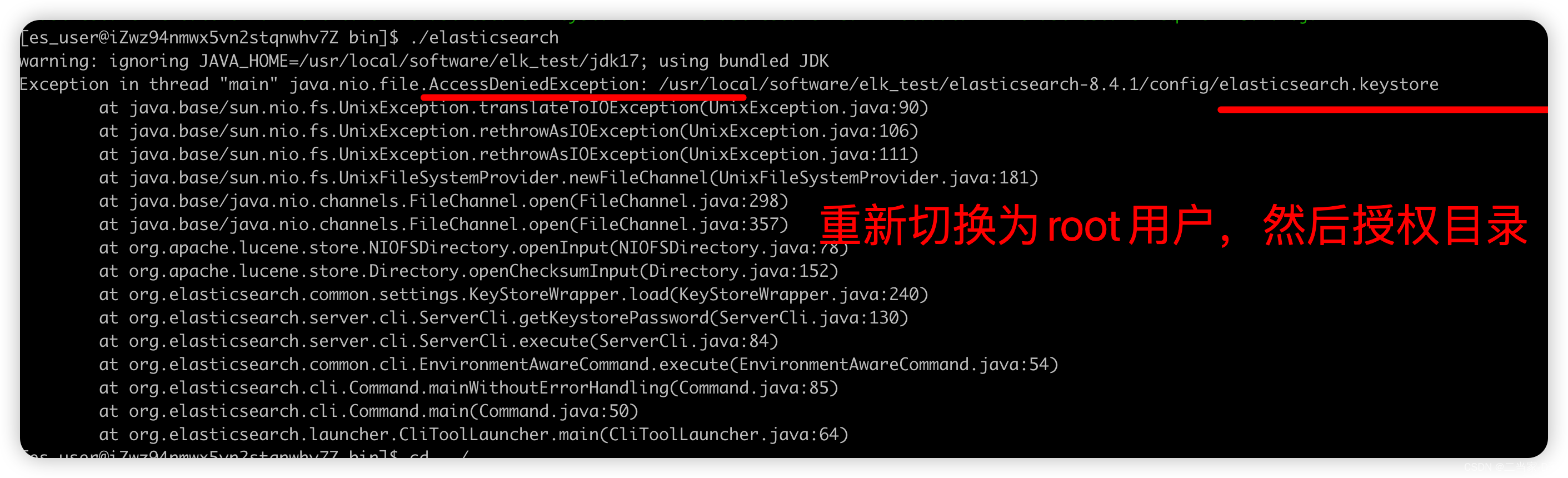
新版SpringBoot3.X整合ElasticSearch8.X
环境说明:本地 JDK17安装(SpringBoot3.X要求JDK17),没相关环境的可以去Oracle官网安装下JDK17,项目开发,快速创建 https://start.spring.io/
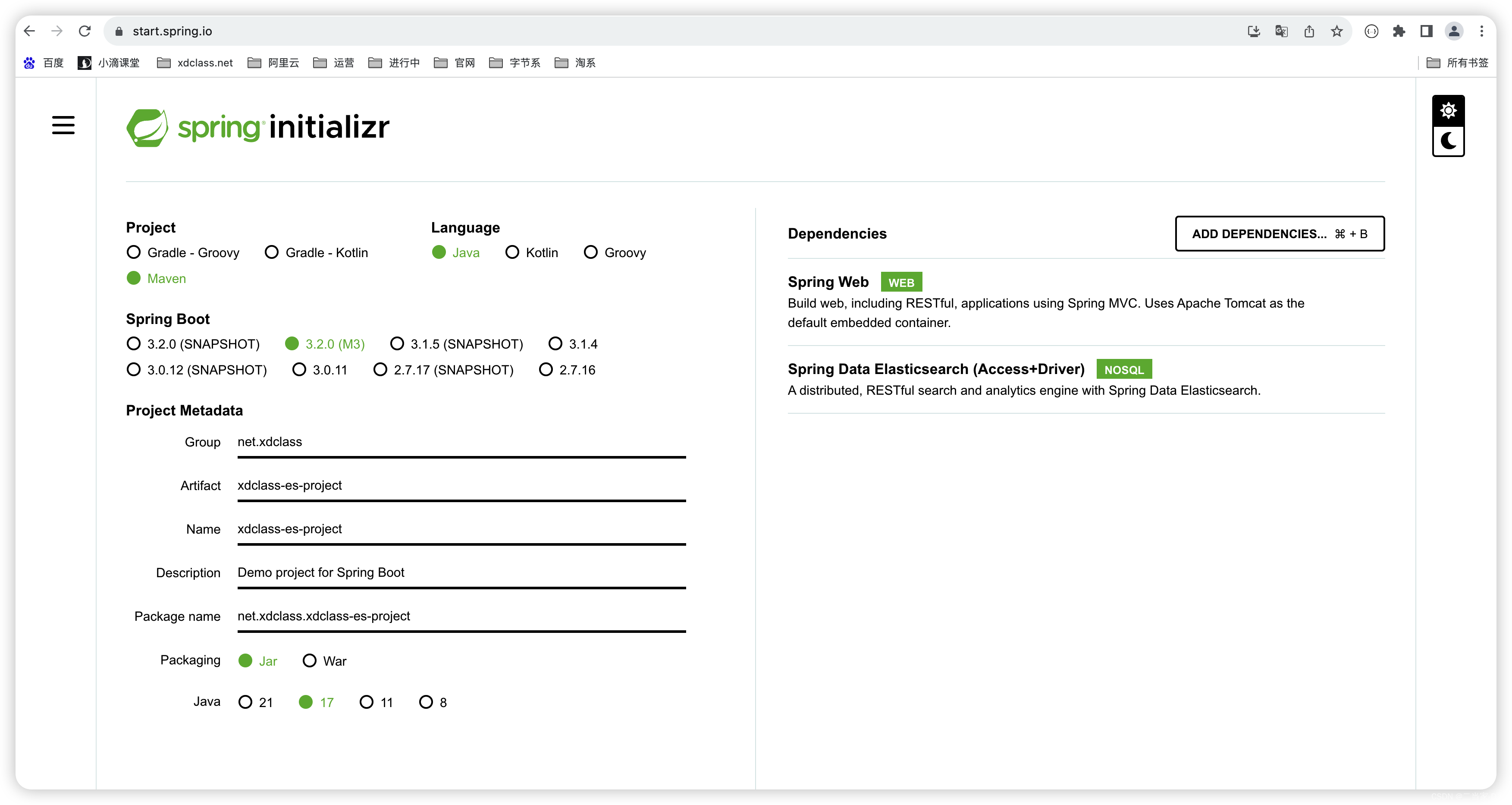
依赖包引入
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies>ES官方针对java推出多个客户端进行接入ES,也分两种
更旧版的ES会用TransportClient(7.0版本标记过期)
Java Low Level REST Client(有继续迭代维护)
基于低级别的 REST 客户端,通过发送原始 HTTP 请求与 Elasticsearch 进行通信。
自己拼接好的字符串,并且自己解析返回的结果;兼容所有的Elasticsearch版本
Java High Level REST Client(7.1版本标记过期)
基于低级别 REST 客户端,提供了更高级别的抽象,简化了与 Elasticsearch 的交互。
提供了更易用的 API,封装了底层的请求和响应处理逻辑,提供了更友好和可读性更高的代码。
自动处理序列化和反序列化 JSON 数据,适用于大多数常见的操作,如索引、搜索、聚合等。
对于较复杂的高级功能和自定义操作,可能需要使用低级别 REST 客户端或原生的 Elasticsearch REST API
Java API Client(8.X版本开始推荐使用)
Elasticsearch在7.1版本之前使用的Java客户端是Java REST Client
从7.1版本开始Elastic官方将Java REST Client标记为弃用(deprecated),推荐使用新版Java客户端Java API Client
新版的java API Client是一个用于与Elasticsearch服务器进行通信的Java客户端库
封装了底层的Transport通信,并提供了同步和异步调用、流式和函数式调用等方法
SpringBoot3.X如何整合Elastic Search
方案一:使用 Elasticsearch 官方提供的高级客户端库 - Elasticsearch Api Client
<dependency> <groupId>co.elastic.clients</groupId> <artifactId>elasticsearch-java</artifactId> <version>8.5.3</version> </dependency>方案二:使用 Spring Data Elasticsearch
<!--这个starter里面就是依赖 spring-data-elasticsearch--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> 增加配置 spring.elasticsearch.uris=http://112.74.167.42:9200SpringBoot3.X+ElasticsearchTemplate索引库操作
ElasticsearchTemplate,是 Spring Data Elasticsearch 提供的一个核心类,是 ElasticsearchClient 的一个具体实现,用于在 Spring Boot 中操作 Elasticsearch 进行数据的存取和查询,提供了一组方法来执行各种操作,如保存、更新、删除和查询文档,执行聚合操作等;
ElasticsearchTemplate 的一些常用方法
- `save(Object)`: 保存一个对象到 Elasticsearch 中。 - `index(IndexQuery)`: 使用 IndexQuery 对象执行索引操作。 - `delete(String, String)`: 删除指定索引和类型的文档。 - `get(String, String)`: 获取指定索引和类型的文档。 - `update(UpdateQuery)`: 使用 UpdateQuery 对象执行更新操作。 - `search(SearchQuery, Class)`: 执行搜索查询,并将结果映射为指定类型的对象。 - `count(SearchQuery, Class)`: 执行搜索查询,并返回结果的计数ElasticsearchTemplate 常见注解配置(都是属于spring data elasticsearch)
@Id 指定主键 @Document指定实体类和索引对应关系,indexName:索引名称 @Field指定普通属性 type 对应Elasticsearch中属性类型,使用FiledType枚举快速获取。 text 类型能被分词 keywords 不能被分词 index 是否创建索引,作为搜索条件时index必须为true analyzer 指定分词器类型。案例实战
//创建DTO @Document(indexName = "video") public class VideoDTO { @Id @Field(type = FieldType.Text, index = false) private Long id; @Field(type = FieldType.Text) private String title; @Field(type = FieldType.Text) private String description; @Field(type = FieldType.Keyword) private String category; @Field(type = FieldType.Integer) private Integer duration; @Field(type = FieldType.Date, format = DateFormat.date_hour_minute_second) private LocalDateTime createTime; public VideoDTO(){} public VideoDTO(Long id, String title, String description, Integer duration,String category) { this.id = id; this.title = title; this.description = description; this.duration = duration; this.createTime = LocalDateTime.now(); this.category = category; } //省略set get方法 }//创建测试方法 @SpringBootTest class XdclassEsProjectApplicationTests { @Autowired private ElasticsearchTemplate restTemplate; /** * 判断索引是否存在索引 */ @Test void existsIndex() { IndexOperations indexOperations = restTemplate.indexOps(VideoDTO.class); boolean exists = indexOperations.exists(); System.out.println(exists); } /** * 创建索引 */ @Test void createIndex() { // spring data es所有索引操作都在这个接口 IndexOperations indexOperations = restTemplate.indexOps(VideoDTO.class); // 是否存在,存在则删除 if(indexOperations.exists()){ indexOperations.delete(); } // 创建索引 indexOperations.create(); //设置映射: 在正式开发中,几乎不会使用框架创建索引或设置映射,这是架构或者管理员的工作,不适合使用代码实现 restTemplate.indexOps(VideoDTO.class).putMapping(); } /** * 删除索引 */ @Test void deleteIndex() { IndexOperations indexOperations = restTemplate.indexOps(VideoDTO.class); boolean delete = indexOperations.delete(); System.out.println(delete); } }SpringBoot3.X操作ES8.X文档Document案例实战
案例一 新增文档
@Test void insert(){ VideoDTO videoDTO = new VideoDTO(); videoDTO.setId(1L); videoDTO.setTitle("小滴课堂架构大课和Spring Cloud"); videoDTO.setCreateTime(LocalDateTime.now()); videoDTO.setDuration(100); videoDTO.setCategory("后端"); videoDTO.setDescription("这个是综合大型课程,包括了jvm,redis,新版spring boot3.x,架构,监控,性能优化,算法,高并发等多方面内容"); VideoDTO saved = restTemplate.save(videoDTO); System.out.println(saved); }案例二 更新文档
@Test void update(){ VideoDTO videoDTO = new VideoDTO(); videoDTO.setId(1L); videoDTO.setTitle("小滴课堂架构大课和Spring Cloud V2"); videoDTO.setCreateTime(LocalDateTime.now()); videoDTO.setDuration(102); videoDTO.setCategory("后端"); videoDTO.setDescription("这个是综合大型课程,包括了jvm,redis,新版spring boot3.x,架构,监控,性能优化,算法,高并发等多方面内容"); VideoDTO saved = restTemplate.save(videoDTO); System.out.println(saved); }案例三 批量插入
@Test void batchInsert() { List<VideoDTO> list = new ArrayList<>(); list.add(new VideoDTO(2L, "老王录制的按摩课程", "主要按摩和会所推荐", 123, "后端")); list.add(new VideoDTO(3L, "冰冰的前端性能优化", "前端高手系列", 100042, "前端")); list.add(new VideoDTO(4L, "海量数据项目大课", "D哥的后端+大数据综合课程", 5432345, "后端")); list.add(new VideoDTO(5L, "小滴课堂永久会员", "可以看海量专题课程,IT技术持续充电平台", 6542, "后端")); list.add(new VideoDTO(6L, "大钊-前端低代码平台", "高效开发底层基础平台,效能平台案例", 53422, "前端")); list.add(new VideoDTO(7L, "自动化测试平台大课", "微服务架构下的spring cloud架构大课,包括jvm,效能平台", 6542, "后端")); Iterable<VideoDTO> result = restTemplate.save(list); System.out.println(result); }案例四 根据主键查询
@Test void searchById(){ VideoDTO videoDTO = restTemplate.get("3", VideoDTO.class); assert videoDTO != null; System.out.println(videoDTO); }案例五 根据id删除
@Test void deleteById() { String delete = restTemplate.delete("2", VideoDTO.class); System.out.println(delete); }进阶SpringBoot3.X+ES8.X多案例搜索实战
新版的ElasticSearch的Query接口,Query是Spring Data Elasticsearch的接口,有多种具体实现,新版官方文档缺少,这边看源码给案例实战
CriteriaQuery:创建Criteria来搜索数据,而无需了解 Elasticsearch 查询的语法或基础知识,允许用户通过简单地连接和组合,指定搜索文档必须满足的对象来构建查询
StringQuery:将Elasticsearch查询作为JSON字符串,更适合对Elasticsearch查询的语法比较了解的人,也更方便使用kibana或postman等客户端工具行进调试
NativeQuery:复杂查询或无法使用CriteriaAPI 表达的查询时使用的类,例如在构建查询和使用聚合的场景
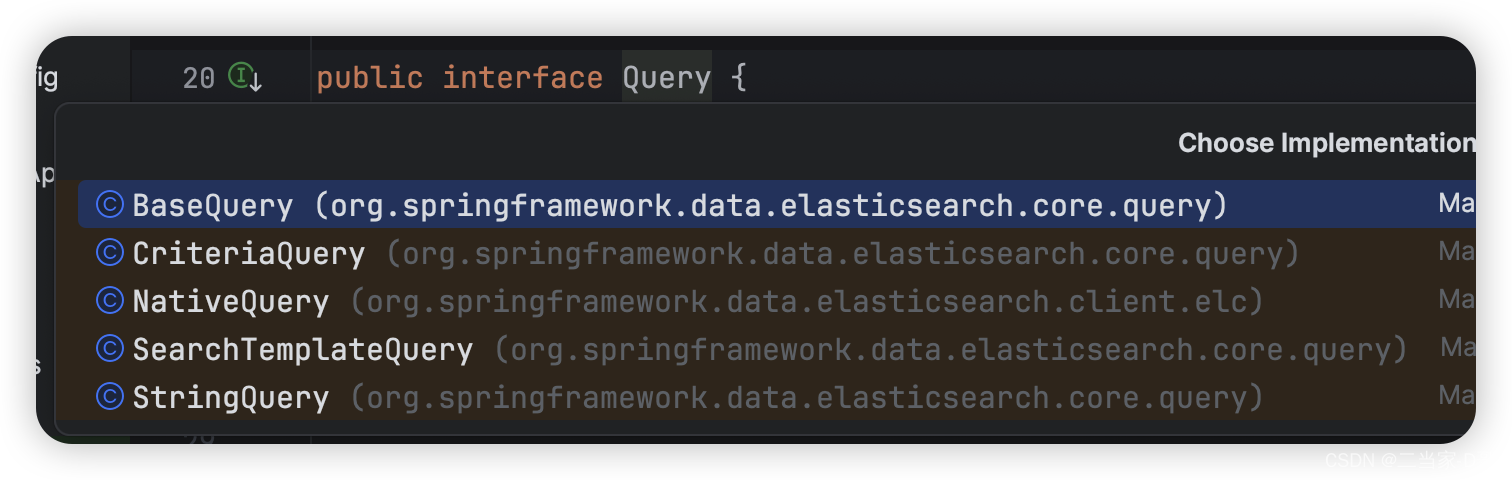
新版的搜索语法案例,查询采用新版的lambda表达式语法,更简洁
案例一:搜索全部
/** * 查询所有 */ @Test void searchAll(){ SearchHits<VideoDTO> search = restTemplate.search(Query.findAll(), VideoDTO.class); List<SearchHit<VideoDTO>> searchHits = search.getSearchHits(); // 获得searchHits,进行遍历得到content List<VideoDTO> videoDTOS = new ArrayList<>(); searchHits.forEach(hit -> { videoDTOS.add(hit.getContent()); }); System.out.println(videoDTOS); }案例二:匹配搜索
/** * match查询 */ @Test void matchQuery(){ Query query = NativeQuery.builder().withQuery(q -> q .match(m -> m .field("description") //字段 .query("spring") //值 )).build(); SearchHits<VideoDTO> searchHits = restTemplate.search(query, VideoDTO.class); // 获得searchHits,进行遍历得到content List<VideoDTO> videoDTOS = new ArrayList<>(); searchHits.forEach(hit -> { videoDTOS.add(hit.getContent()); }); System.out.println(videoDTOS); }案例三:分页搜索
/** * 分页查询 */ @Test void pageSearch() { Query query = NativeQuery.builder().withQuery(Query.findAll()) .withPageable(Pageable.ofSize(3).withPage(0)).build(); SearchHits<VideoDTO> searchHits = restTemplate.search(query, VideoDTO.class); // 获得searchHits,进行遍历得到content List<VideoDTO> videoDTOS = new ArrayList<>(); searchHits.forEach(hit -> { videoDTOS.add(hit.getContent()); }); System.out.println(videoDTOS); }案例四:搜索排序,withSort() 需要传入 Sort 对象,.by代表根据一个字段进行排序
/** * 排序查询,根据时长降序排列 */ @Test void sortSearch() { Query query = NativeQuery.builder().withQuery(Query.findAll()) .withPageable(Pageable.ofSize(10).withPage(0)) .withSort(Sort.by("duration").descending()).build(); SearchHits<VideoDTO> searchHits = restTemplate.search(query, VideoDTO.class); // 获得searchHits,进行遍历得到content List<VideoDTO> videoDTOS = new ArrayList<>(); searchHits.forEach(hit -> { videoDTOS.add(hit.getContent()); }); System.out.println(videoDTOS); }进阶SpringBoot3.X+ES8.X原始StringQuery搜索
StringQuery,将Elasticsearch查询作为JSON字符串,更适合对Elasticsearch查询的语法比较了解的人,也更方便使用kibana或postman等客户端工具行进调试
案例一:布尔must查询,搜索标题有 架构 关键词,描述有 spring关键字,时长范围是 10~6000之间的
//原始DSL查询 GET /video/_search { "query": { "bool": { "must": [{ "match": { "title": "架构" } }, { "match": { "description": "spring" } }, { "range": { "duration": { "gte": 10, "lte": 6000 } } }] } } } //SpringBoot+SpringData查询 @Test void stringQuery() { //搜索标题有 架构 关键词,描述有 spring关键字,时长范围是 10~6000之间的 String dsl = """ {"bool":{"must":[{"match":{"title":"架构"}},{"match":{"description":"spring"}},{"range":{"duration":{"gte":10,"lte":6000}}}]}} """; Query query = new StringQuery(dsl); List<SearchHit<VideoDTO>> searchHitList = restTemplate.search(query, VideoDTO.class).getSearchHits(); // 获得searchHits,进行遍历得到content List<VideoDTO> videoDTOS = new ArrayList<>(); searchHitList.forEach(hit -> { videoDTOS.add(hit.getContent()); }); System.out.println(videoDTOS); }案例二:统计不同分类下的视频数量
/** * 聚合查询 */ @Test void aggQuery() { Query query = NativeQuery.builder() .withAggregation("category_group", Aggregation.of(a -> a .terms(ta -> ta.field("category").size(2)))) .build(); SearchHits<VideoDTO> searchHits = restTemplate.search(query, VideoDTO.class); //获取聚合数据 ElasticsearchAggregations aggregationsContainer = (ElasticsearchAggregations) searchHits.getAggregations(); Map<String, ElasticsearchAggregation> aggregations = Objects.requireNonNull(aggregationsContainer).aggregationsAsMap(); //获取对应名称的聚合 ElasticsearchAggregation aggregation = aggregations.get("category_group"); Buckets<StringTermsBucket> buckets = aggregation.aggregation().getAggregate().sterms().buckets(); //打印聚合信息 buckets.array().forEach(bucket -> { System.out.println("组名:"+bucket.key().stringValue() + ", 值" + bucket.docCount()); }); // 获得searchHits,进行遍历得到content List<VideoDTO> videoDTOS = new ArrayList<>(); searchHits.forEach(hit -> { videoDTOS.add(hit.getContent()); }); System.out.println(videoDTOS); } Elastic Search8.X常见性能优化最佳实践
官方数据Elastic Search最高的性能可以达到,PB级别数据秒内相应,但是很多同学公司的Elastic Search集群,里面存储了几百万或者几千万数据,但是ES查询就很慢了,记住,ES数量常规是亿级别为起点,之所以达不到官方的数据,多数是团队现有技术水平不够和业务场景不一样
Elastic Search8.X常见性能优化最佳实践
- 硬件资源优化: - 内存分配 - 将足够的堆内存分配给Elasticsearch进程,以减少垃圾回收的频率 - ElasticSearch推荐的最大JVM堆空间是30~32G, 所以分片最大容量推荐限制为30GB - 30G heap 大概能处理的数据量 10 T,如果内存很大如128G,可在一台机器上运行多个ES节点 - 比如业务的数据能达到200GB, 推荐最多分配7到8个分片 - 存储器选择 - 使用高性能的存储器,如SSD,以提高索引和检索速度 - SSD的读写速度更快,适合高吞吐量的应用场景。 - CPU和网络资源 - 根据预期的负载需求,配置合适的CPU和网络资源,以确保能够处理高并发和大数据量的请求。 - 分片和副本优化: - 合理设置分片数量 - 过多的分片会增加CPU和内存的开销,因此要根据数据量、节点数量和性能需求来确定分片的数量。 - 一般建议每个节点上不超过20个分片 - 考虑副本数量 - 根据可用资源、数据可靠性和负载均衡等因素,设置合适的副本数量 - 至少应设置一个副本,以提高数据的冗余和可用性。 - 不是副本越多,检索性能越高,增加副本数量会消耗额外的存储空间和计算资源, - 索引和搜索优化 - 映射和数据类型 - 根据实际需求,选择合适的数据类型和映射设置 - 避免不必要的字段索引,尽可能减少数据在硬盘上的存储空间。 - 分词和分析器 - 根据实际需求,选择合适的分词器和分析器,以优化搜索结果。 - 了解不同分析器的性能特点,根据业务需求进行选择 - 查询和过滤器 - 使用合适的查询类型和过滤器,以减少不必要的计算和数据传输 - 尽量避免全文搜索和正则表达式等开销较大的查询操作。 - 缓存和缓冲区优化: - 缓存大小 - 在Elasticsearch的JVM堆内存中配置合适的缓存大小,以加速热数据的访问 - 可以根据节点的角色和负载需求来调整缓存设置。 - 索引排序字段 - 选择合适的索引排序字段,以提高排序操作的性能 - 对于经常需要排序的字段,可以为其创建索引,或者选择合适的字段数据类型。 - 监控和日志优化 - 监控集群性能 - 使用Elasticsearch提供的监控工具如Elastic Stack的Elasticsearch监控、X-Pack或其他第三方监控工具 - 实时监控集群的健康状态、吞吐量、查询延迟和磁盘使用情况等关键指标。 - 集群规划和部署: - 多节点集群 - 使用多个节点组成集群,以提高数据的冗余和可用性。多节点集群还可以分布负载和增加横向扩展的能力。 - 节点类型和角色 - 根据节点的硬件配置和功能需求,将节点设置为合适的类型和角色 - 如数据节点、主节点、协调节点等,以实现负载均衡和高可用性。 - 性能测试和优化: - 压力测试 - 使用性能测试工具模拟真实的负载,评估集群的性能极限和瓶颈 - 根据测试结果,优化硬件资源、配置参数和查询操作等。 - 日常性能调优 - 通过监控指标和日志分析,定期评估集群的性能表现,及时调整和优化配置,以满足不断变化的需求。 - 升级和版本管理: - 计划升级 - 定期考虑升级Elasticsearch版本,以获取新功能、性能改进和安全修复。 - 在升级过程中,确保备份数据并进行合理的测试。 - 版本管理 - 跟踪Elasticsearch的发行说明和文档,了解新版本的特性和已知问题,并根据实际需求选择合适的版本。今天文章就先写到这里,还有很多内容下次继续,大家有任何疑惑也可以评论区留言
- SpringBoot3.X整合Elastic Search8.X集群
Elastic Search集群进行升级,不同大版本如何升级,索引读写不兼容,比如ElasticSearch5.X或6.X升级为8.X
业务一开始规划的索引分片、类型mapping分配不合理,原有数据量太大、分片数太少 ;原有数据量太小、分片数太多;ES索引分片,一旦创建,原索引是不能修改分片数量
Elasticsearch中搜索文档排序里面有个评分,表示相关性,按score得分从高到底排好序的结果集,机制上怎样的?
海量数据存储,但是有些数据很少方法,也占据比较高的存储资源,如何做冷热数据归档?
ES被称为可以实时的搜索NRT,ES索引分片写入原理是怎样的,为什么新加一条数据在下一秒就可以被搜索?
如果使用新版SpringBoot3.X+ElasticSearch8.X有任何疑惑,可以互相交流下
如果需要完整文章代码和安装包,直接获取即可
