
阅读量:0
ChatGPT就是人机交互的一个底层系统,某种程度上可以类比于操作系统。在这个操作系统上,人与AI之间的交互用的是人的语言,不再是冷冰冰的机器语言,或者高级机器语言,当然,在未来的十来年内,机器语言的使用率仍然会比较高,以便系统更迭和交互。
1. 作为人机交互“操作系统”,ChatGPT的大模型是如何输入、学习和更新数据的呢?
ChatGPT的大模型使用的是无监督学习方法,输入数据主要是通过爬虫技术从互联网上采集大量文本数据,数据来源包括维基百科、新闻报道、社交媒体等。这些文本数据经过预处理和清洗后,被转化为文本语料库。
ChatGPT的大模型通过对这些语料库进行无监督学习,学到了自然语言的语法结构和语义表示,因此它能够高度准确和流畅地生成文本。同时,ChatGPT的大模型也可以根据用户输入的上下文信息,自动生成相关的响应文本,从而实现对话交互的功能。ChatGPT作为一种强大的语言模型,为各种人工智能应用提供了基础支持。类似于操作系统为计算机提供了运行程序和管理资源的能力,ChatGPT为开发人员和用户提供了一种强大的自然语言处理工具。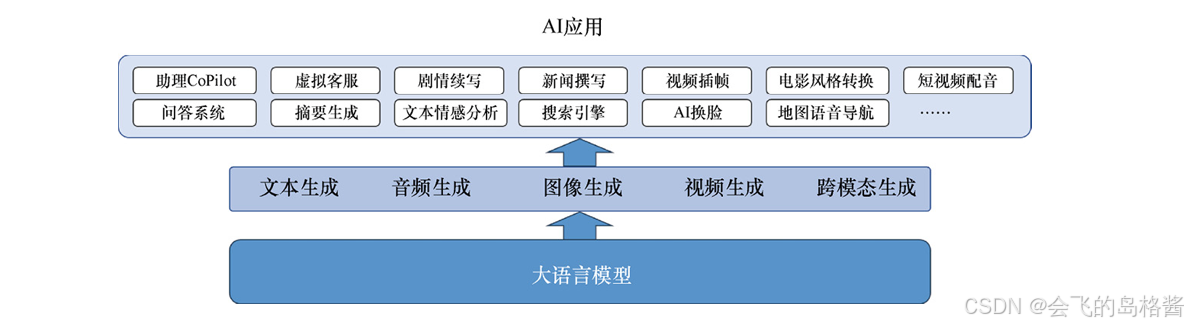
在大语言模型的基础上出现了多种生成模型,这有点类似于操作系统中的各种管理功能:进程管理、内存管理、文件系统、设备管理、人机交互和网络管理等。在此类功能之上,则是各种应用,AI应用就建立在内容生成功能层之上,类似于PC端/移动端应用和服务应用。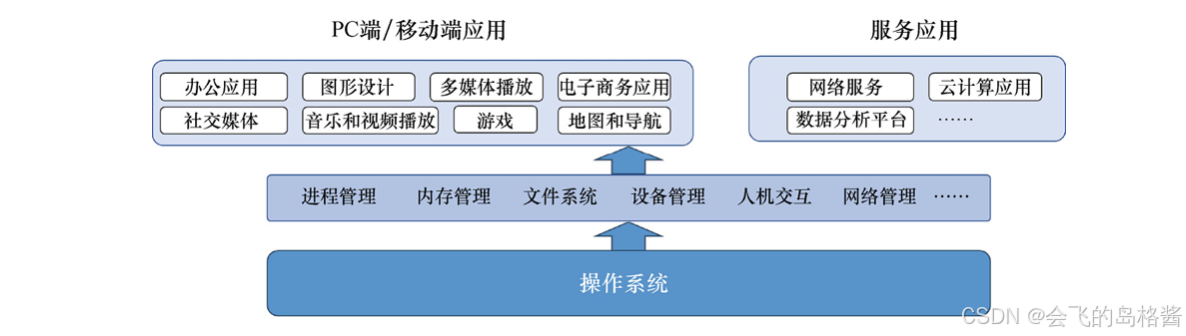
2. ChatGPT为什么能生成代码,背后的原理是什么?
大模型学习编程的方式与其学习其他知识的方式相同,都是通过大量的文本数据来学习。这些文本数据包括各种类型的文本,如新闻、书籍、网页和编程教程等。模型可以从中学习到编程的基本概念、语法规则、常见模式和最佳实践等。
我们可以输入一些与编程语言相关的提示和约束条件,使ChatGPT生成符合这些提示和条件的代码。例如,输入一段关于计算圆面积的描述,可以提示ChatGPT生成对应的Python代码。此外,ChatGPT也可以通过学习大量的开源代码库,习得代码的结构和语法规则,从而生成符合编程规范的代码。
具体来说,模型的训练过程通常包括以下步骤。
- 预训练:在这个阶段,模型会在大量的文本数据上进行训练,学习到文本的统计规律。这个过程是无监督的,也就是说,模型只需要预测下一个词是什么,而不根据需要明确的标签来进行学习。在这个步骤,模型可以学习到语言的语法和语义,以及一些基本的编程知识。
- 微调:在预训练之后,模型会在特定的任务上进行微调。这个过程是有监督的,也就是说,模型需要根据明确的标签来进行学习。例如,如果我们想让模型学习编程,我们可以在编程问题和对应的解决方案上进行微调。通过这个过程,模型可以学习到更具体和深入的编程知识。
值得注意的是,虽然大模型可以学习到一些编程知识,但它们并不能理解编程的真正含义。它们只是学习到了编程的表面规律,而没有深入地理解编程。同时,ChatGPT生成的代码并不一定总是符合正确的语义和逻辑,还需要程序员对其进行进一步的检查和调试。因此,虽然大模型可以帮助我们解决一些编程问题,但它们不能替代真正的程序员。
3. ChatGPT日均算力运营成本的推算
微软的NewBing称,ChatGPT的单次训练成本约为170万美元,若自建AI算力中心进行模型训练,训练成本有望降至约51万美元。使用云计算时,ChatGPT每处理1000个token的信息,需花费约0.177美分,自建AI算力中心有望将成本降至0.053美分左右。
而ChatGPT称,计算ChatGPT的成本需要考虑如下多个因素,包括硬件、人力和能源成本等。
- 硬件成本:ChatGPT使用的硬件是图形处理器(GPU),具体的成本取决于所使用的GPU型号、数量及供应商。以2023年4月的GPU价格为例,英伟达Tesla V100的售价约为10000美元。如果需要使用多个GPU来训练模型,则成本将进一步增加。
- 人力成本:ChatGPT的开发需要大量的人力资源,包括算法研究员、工程师、开发者和数据科学家等。这些人员的工资和福利成本会对ChatGPT的总成本产生重大影响。
- 能源成本:训练ChatGPT需要消耗大量的电力,需要考虑电费等能源成本。
根据OpenAI公司公布的消息,仅仅训练一个先进的GPT-3模型,就花费了数百万美元。除了硬件、人力和能源成本,还需要考虑到其他因素,例如数据采集、存储和管理成本等。
综合考虑,先搁置人力成本因素,只考虑硬件(TPU/存储器)成本和能源成本,核算起来会较清晰。这些因素都会对整个训练过程的费用产生影响,需要在预算和资源规划时予以充分考虑。
