
阅读量:0
本人的研究方向是基于深度学习方法的作物遥感识别。经查阅目前的相关教程资料后,发现深度学习的GEE教程几乎没有,所以开始动笔写下此片文章,给后面研究这个方向的人提供一点帮助吧。
教程的背景
为什么要写这份教程?
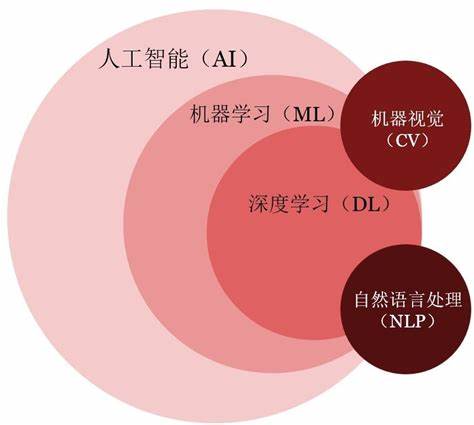
一、深度学习越来越重要了
- 数据爆炸:随着互联网的普及和各种传感器技术的发展,我们产生的数据量呈指数级增长。深度学习是处理大规模数据的有效工具,可以从海量数据中学习并提取有用的信息和模式。
- 计算能力的提升:随着计算机硬件和算力的不断提升,如图形处理器(GPU)和专用深度学习芯片(如TPU),我们能够更快、更高效地训练和运行深度学习模型。这使得深度学习在实践中更加可行和实用。
- 算法的发展:深度学习算法的不断发展和改进也是其重要性增加的原因之一。例如,卷积神经网络(CNN)在图像处理领域的成功,递归神经网络(RNN)在自然语言处理领域的应用等。这些算法的创新使得深度学习能够解决更加复杂和抽象的问题。目前,基于Transformer的ChatGPT语言大模型已经确确实实改变了我们的生活。
- 应用领域的拓展:深度学习不仅在计算机视觉和自然语言处理等传统领域取得了巨大成功,还在许多其他领域得到了广泛应用。例如,医疗诊断、金融风险评估、智能交通、地理信息处理等。深度学习的广泛应用使得它成为各行各业的重要工具。

二、Google Earth Engine(GEE)是重要的遥感信息处理工具
传统的遥感影像处理工具,如ENVI、Erdas Imagine、ArcGIS等,在传统遥感数据处理领域得到广泛应用。Google Earth Engine是由Google开发的,于2010年发布。)其是一个强大的云计算平台,旨在支持大规模地理空间数据的存储、处理、分析和可视化。它提供了丰富的遥感数据集和分析工具,使用户能够在云端高效地进行地理信息处理。
Google Earth Engine (GEE) 相较于传统工具有以下几个优势:
- 大规模数据处理能力:GEE可以处理大量的地理空间数据,包括遥感影像、地形数据、气象数据等。它利用云计算技术,将数据存储在云端,并提供高性能的计算资源,使用户能够快速处理大规模数据集。
- 丰富的数据集:GEE提供了全球范围内的多种类型的遥感数据集,包括高分辨率影像、地表温度、降雨数据等。这些数据集可以用于各种地理信息处理任务,如图像分类、时间序列分析等。
- 编程接口和算法库:GEE提供了基于JavaScript和Python的编程接口,使用户能够使用自己熟悉的编程语言进行地理信息处理。此外,GEE还提供了丰富的算法库,包括图像处理、空间分析、机器学习等领域的算法,方便用户进行各种分析和模型构建。
- 可视化和共享功能:GEE提供了强大的可视化工具,用户可以将处理结果以地图、图表等形式进行展示。此外,用户还可以将自己的数据、代码和分析结果共享给其他用户,促进合作和知识共享。
- 强大的社区支持:GEE拥有庞大的用户社区,用户可以在社区中获取帮助、分享经验和协作开发。此外,GEE还提供了丰富的文档、教程和示例代码,帮助用户快速上手和解决问题。
总之,GEE是一个功能强大、易于使用的地理信息处理平台,为我们提供了丰富的数据集、分析工具和社区支持,帮助我们高效地进行地理信息处理和分析。
三、Google Earth Engine(GEE)的深度学习教程很少
GEE的官方教程中多是机器学习的教程和案例代码,有关深度学习的教程和代码较少,只有如下几个:
但其仅有的教程在有些细节上解释的不够清楚,给初学者带来很多麻烦。
中文互联网上教程也不多,寥寥几篇,内容也不够丰富和全面。目前检索到的教程如下:
- Google Earth Engine(Tensorflow深度学习) - 知乎 (zhihu.com)
- Google Earth Engine(GEE)—TensorFlow支持深度学习等高级机器学习方法(非免费项目)
概述
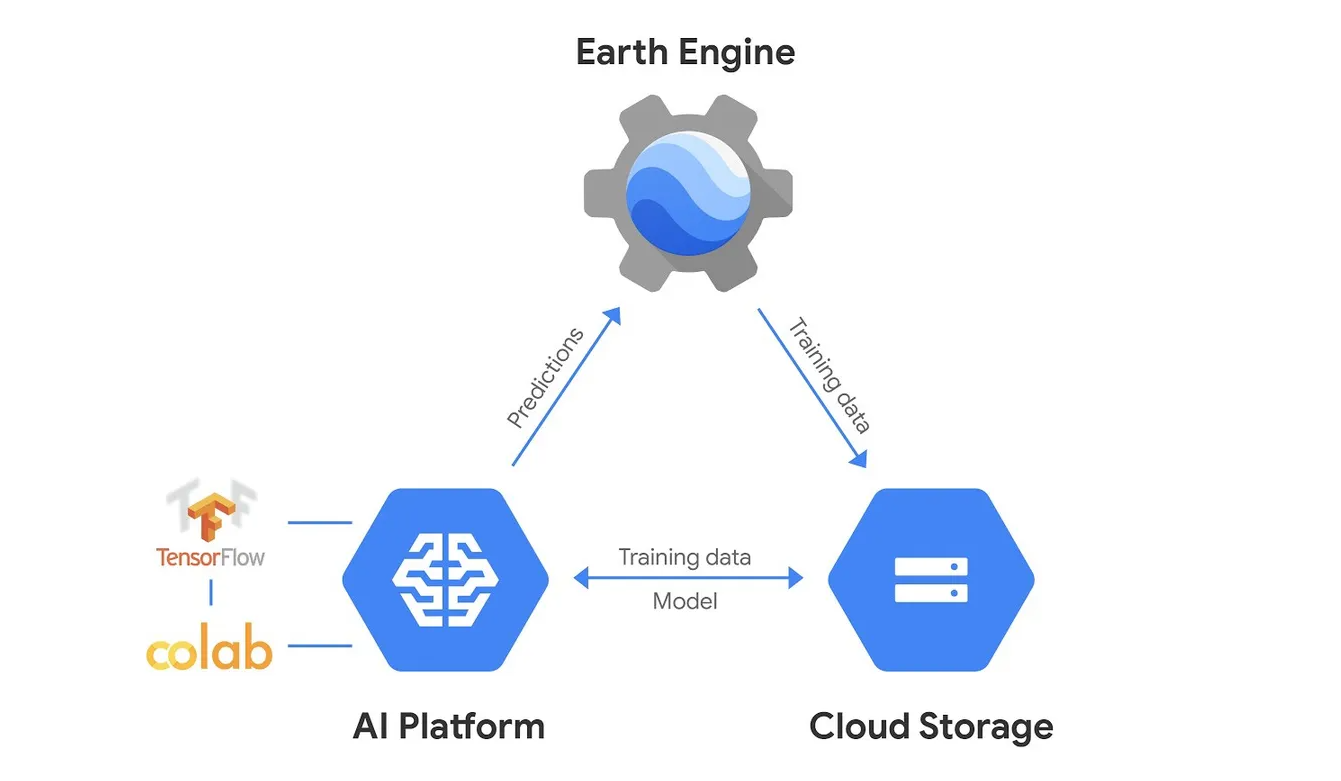
使用GEE平台做深度学习,首先我们要明白一个基础问题,GEE云平台本身不支持深度学习模型的训练,它仅支持经典机器学习算法和提供tensorflow深度模型预测的接口,我们应该将其视为一个数据预处理工具。
GEE使用深度学习方法做研究的基础流程是:
在线模型训练
- GEE预处理遥感数据导出到谷歌云存储(付费)里。
- 使用Colab Notebooks 和Vertex AI (谷歌AI云平台(付费))交互,访问谷歌云存储中的数据,租用google的TPU,基于tensorflow框架在线训练深度学习模型。
- 上传训练好的模型,在GEE端进行在线模型推理,得到大范围的推理结果。
本地模型训练
- GEE预处理遥感数据导出到谷歌云存储(付费)里。
- 下载数据到本地。
- 使用jupyter Notebooks 或pycharm读取数据,使用本地GPU,基于tensorflow框架在线训练深度学习模型。
- 上传训练好的模型,在GEE端进行模型推理,得到大范围的推理结果。或者在本地进行小范围的模型推理。
本教程是使用本地GPU进行模型训练,推理也是在本地进行的。GEE支持JS和python 2种客户端,本教程是使用的JS客户端。预计分为以下几个章节来撰写:
- 环境搭建篇
- GEE导出篇
- GEE预处理篇
- Python数据读入篇
- Python深度学习训练篇
- 官方教程解析篇
环境搭建篇
前置条件:GEE账号、GPU、本地python开发IDE、conda虚拟环境
所需条件:
- 谷歌云存储(GCS)
- tensorflow +keras+tensorboard
一、谷歌云存储(GCS)
Google Cloud Storage(GCS)是谷歌云平台(GCP)一部分, 这是一个云存储平台,旨在存储大型非结构化数据集。
我们需要在云存储创建储存桶,将GEE处理好的数据导出其中暂存。使用Python程序下载储存桶中的文件,保存本地。
1、购买付费的云存储服务
首先需要有一个谷歌账号,登录云平台,开始使用,每个新用户都免费获得 $300 赠金,在未来 90 天内试用 Google Cloud。但是账号认证需要付款信息验证,即绑定一张国外银行卡(不能使用中国银行卡、支付宝和微信付费)。
解决方案有两种:
- 想办法在网络上找代理商注册一个虚拟国外银行卡(尝试失败了)
- 找到一个有国外银行卡的同学或朋友,绑定他的(我最终采用的方法)
必须搞定这个账号,不然数据是无法导出保存的。
2、创建存储桶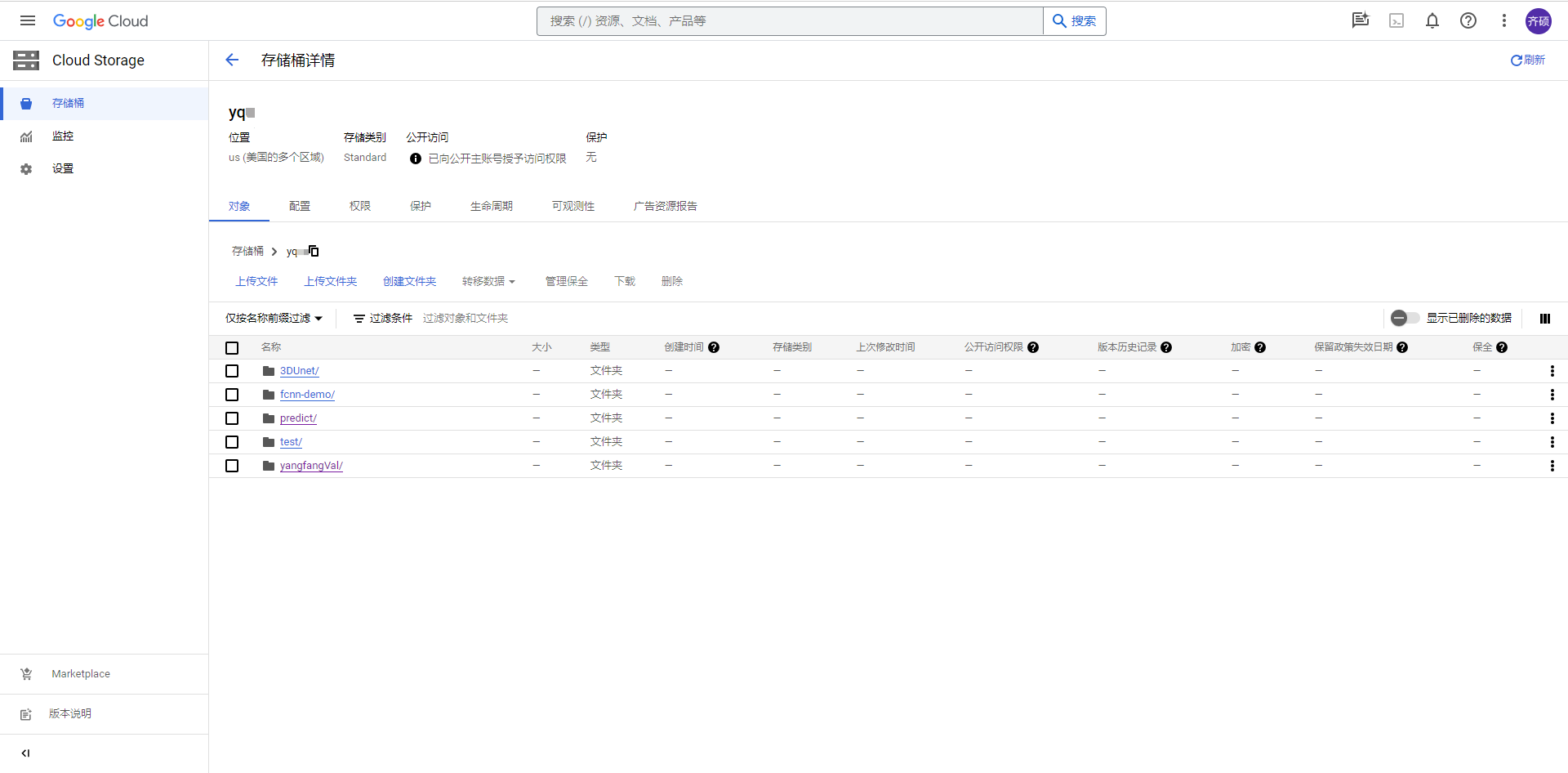
账号注册完成之后,应该需要创建一个项目,GCP中的一切都围绕着项目展开。 每个项目可以有多个存储桶,围绕它们构建Google Cloud Storage的架构。 每个存储桶可以包含任意数量的对象,可以是文件夹和/或文件。 创建存储桶时,会为其分配存储类别和地理位置。 这些设置可以在创建存储桶时指定,但以后不能更改。
存储桶具有特定的命名约定 ,必须严格遵守这些约定 ,否则GCP将不允许您创建存储桶。 存储桶名称在全球范围内是唯一的,因此需要以防止冲突的方式进行选择。 但是,删除的存储桶使用的名称可以重复使用。此外,将名称分配给存储桶后就无法更改。 如果要更改它,唯一的解决方案是使用所需名称创建一个新存储桶,将内容从前一个存储桶移动到新存储桶,然后删除前一个存储桶。
3、 Python GCS库安装
官方教程:Python client library | Google Cloud
为了方便下载云存储的文件,我们需要安装python对应的库
pip install google-cloud-storage 使用python程序访问储存桶文件需要对python客户端进行验证(即用户登录)
Google 的身份验证方法官方教程中提供了多种方法,我采用的方案是服务账号密钥,
如需创建服务账号密钥并将其提供给 ADC,请执行以下操作:
按照创建服务账号密钥中的说明,创建一个具有您的应用所需的角色的服务账号,并为该服务账号创建密钥。
或者教程可参考【GoogleDriveApi】创建Google凭据(OAuth2和Service Account)_获其中的Service Account凭据创建,导出得到json格式的凭据。
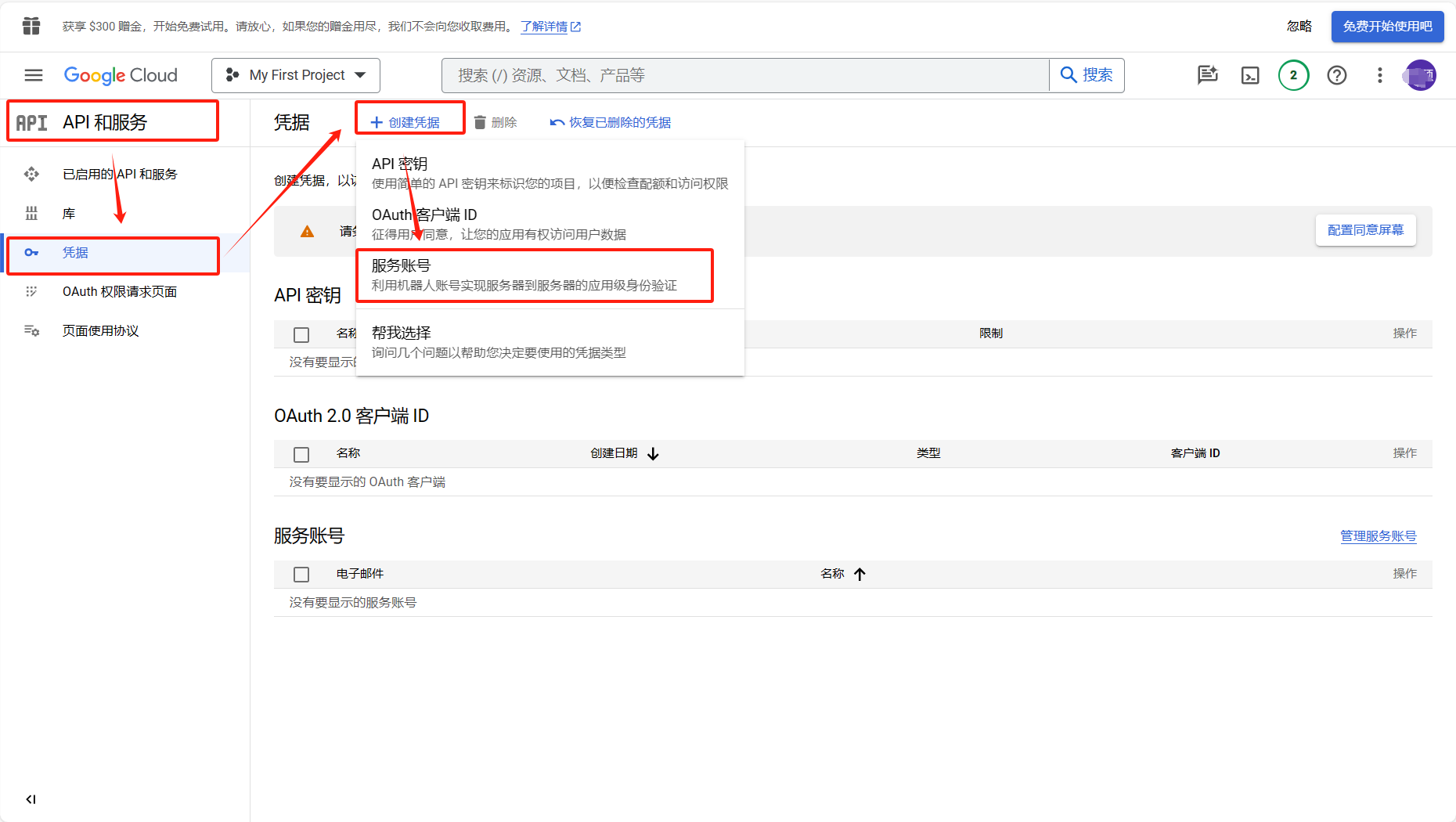
将环境变量
GOOGLE_APPLICATION_CREDENTIALS设置为包含凭据的 JSON 文件的路径。例如下图: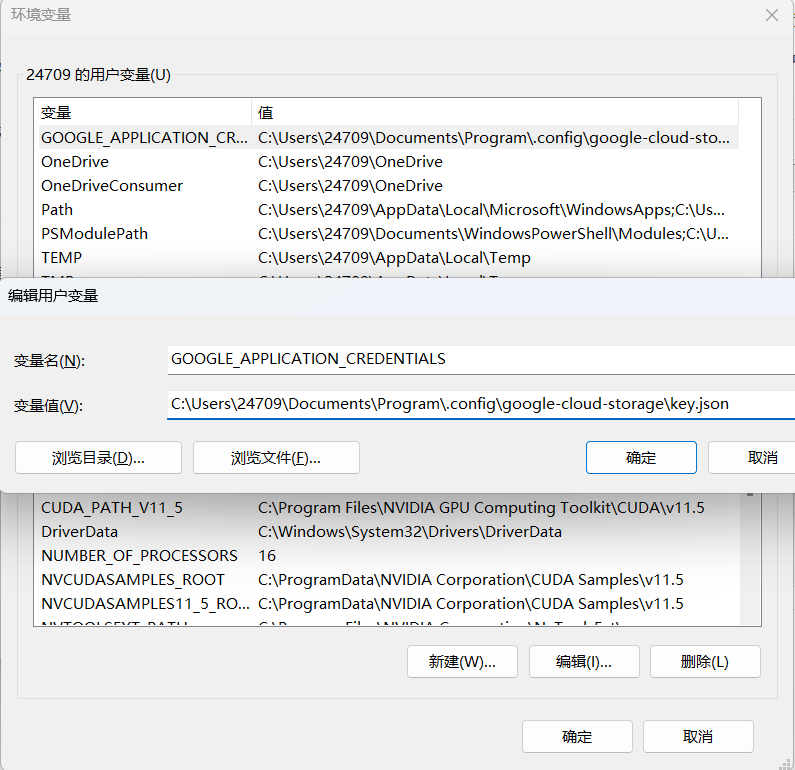
4、 Python GCS库测试
from google.cloud import storage import os # 实例化 Storage 客户端 client = storage.Client() # 指定存储桶名称 bucket_name = 'yqs' # 指定文件夹名称 folder_name = 'predict' # 得到指定存储桶的引用 bucket = client.get_bucket(bucket_name) # 列出存储桶中的所有对象 for blob in bucket.list_blobs(prefix=folder_name): print(blob.name) 如果可以正常打印的话代表你把这部分搞定了。
下面附上GCS的下载代码:
from google.cloud import storage import os def download_blob(bucket_name, source_blob_name, destination_file_name): """ 下载 GCS 存储桶中指定的文件。 """ # 初始化 GCS 客户端 storage_client = storage.Client() # 获取指定的存储桶和文件 bucket = storage_client.bucket(bucket_name) blob = bucket.blob(source_blob_name) # 下载文件 blob.download_to_filename(destination_file_name) print(f"File {source_blob_name} has been downloaded to {destination_file_name}.") def download_folder(bucket_name, folder_name, destination_folder): """ 下载 GCS 存储桶中指定文件夹下的所有文件。 """ storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) # 列出指定路径下的所有文件 blobs = bucket.list_blobs(prefix=folder_name) for blob in blobs: # 获取文件名 file_name = blob.name.split("/")[-1] # 设置过滤规则,例如非gz格式的不下载 if file_name[-2:] != 'gz': continue # 检查目标文件夹中是否已经存在同名的文件,如果存在,则不再下载 if os.path.isfile(f"{destination_folder}/{file_name}"): print(f"File {blob.name} already exists in {destination_folder}.") else: print(f"File {blob.name} is downloading to {destination_folder}/{file_name}.") blob.download_to_filename(f"{destination_folder}/{file_name}") print(f"File {blob.name} has been downloaded to {destination_folder}/{file_name}.") # # 下载指定路径下的文件夹到本地文件夹 download_folder("yqs", "yangfangVal", "data/yangfang") # 下载指定路径下的文件到本地 #download_blob("yqs", "yangfangVal/eval_patches_g0.tfrecord.gz", "data/yangfang/eval_patches_g0.tfrecord.gz") 通过这段代码可以批量下载存储桶中的文件,而不需要手动在浏览器一个一个下载。
二、本地深度学习环境
首先罗列出所需下载的东西(window环境下):
- 显卡支持:CUDA 、cuDNN
- python虚拟环境:Anaconda
- 深度学习底层框架:tensorflow-gpu
- 高层框架:Keras
- IDE:Jupyter Lab、Pycharm 或其他
- 数据可视化:tensorboard
提供作者的一个硬件配置及软件版本参考:
| 项目 | 内容 |
|---|---|
| 中央处理器 | Intel® Xeon® Gold 6248R CPU @ 3.00GHz |
| 内存 | 192GB |
| 显卡 | NVIDIA Quadro P4000 |
| 操作系统 | Windows 10 |
| CUDA | Cuda10.4 |
| IDE | Jupyter Lab 3.6 |
| 软件平台及框架 | Python3.9、Tensorflow2.10、Keras2.10 |
至于这些环境的安装教程,网络上已经有太多了,本文不赘述:
提供参考:
