
阅读量:0
基础部分学习:
1、 Llama 3 Web Demo 部署
streamlit run ***.py(网页演示py文件路径) ***(下载好的大模型参数路径) 注意点:在vscode中要对上面命令产生的External URL的最后四位端口号,在终端旁边的端口菜单中配置端口转发,否则无法在本地浏览器打开
实验结果: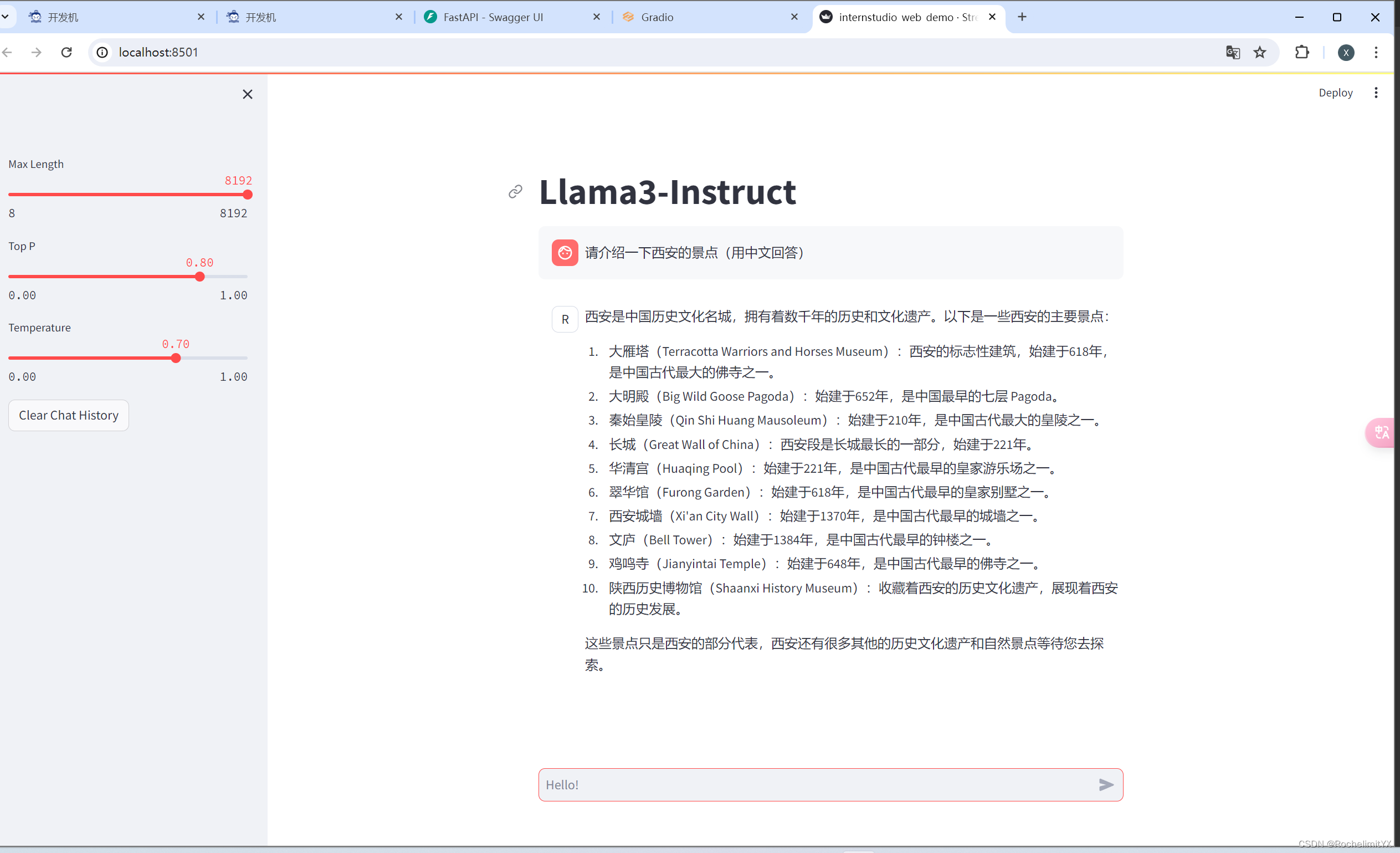
2、使用 XTuner 完成小助手认知微调
本次微调使用的是QLoRA微调
微调数据集格式:
"conversation": [ { "system": "你是一个懂中文的小助手", "input": "你是(请用中文回答)", "output": "您好,我是洛希极限,一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?" } ] 微调命令:
xtuner train ***(微调的**config.py配置文件路径) --work-dir ***(保存模型微调权重的目录:不存在会自动创建/自行命名) 微调完成后,要将Adapter PTH权重格式转化为 HF格式
xtuner convert pth_to_hf ***(微调的**config.py配置文件路径) ***(微调的工作路径/权重保存的路径) ***(转化后的存储路径) 将微调后得到的权重与预训练的权重进行合并:
export MKL_SERVICE_FORCE_INTEL=1 是一个环境变量设置命令,用于强制让使用Intel Math Kernel Library (MKL) 来进行数学计算,而不是使用其他的数学库。MKL是由英特尔提供的数学计算库,可以优化和加速数值计算、线性代数计算和傅里叶变换等操作。
xtuner convert merge ***(原始的Llama3权重路径)\ ***(刚刚准换好为HF(huggface格式)的adapter路径)\ ***(合并完成后的路径) 推理验证:
streamlit run ***.py(网页演示py文件路径) ***(合并完成后的路径的大模型参数路径) 实验结果:
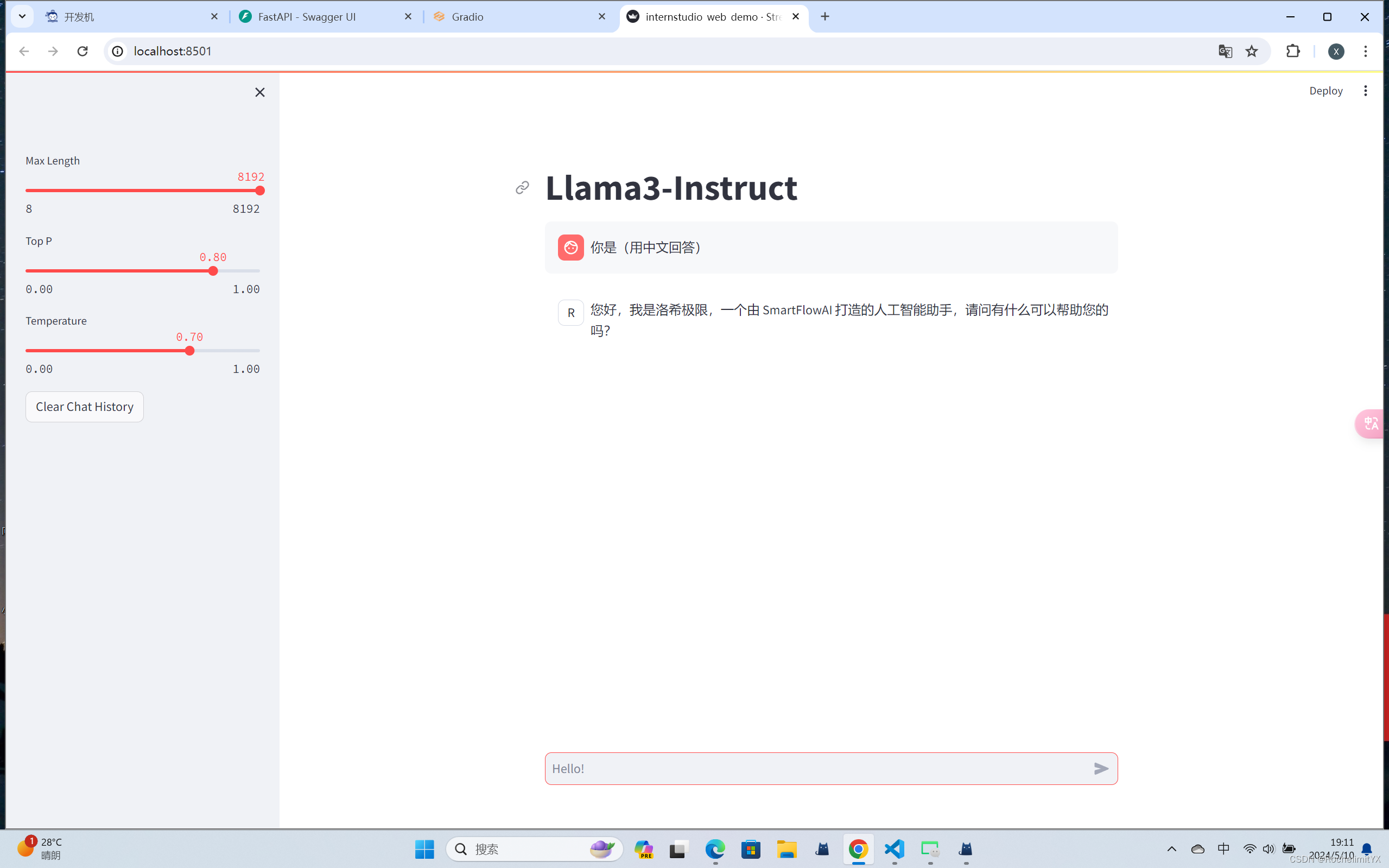
3、使用 LMDeploy 成功部署 Llama 3 模型
首先需要安装 lmdeploy库
pip install -U lmdeploy[all] 生产环境下,将大模型封装成API接口,供客户端访问
构建/启动API服务器
注意:需要在安装有lmdeploy库的环境下运行本部分的命令
lmdeploy serve api_server\ 模型参数路径\ --model-formate hf(huggingface格式)\ --quant-policy 0\ --server-name API服务的服务IP --server-port 服务端口号 --tp int类型(并行数量GPU数量) 通过运行以上指令,我们成功启动了API服务器,请勿关闭该窗口,后面我们要新建客户端连接该服务。 你也可以直接打开http://{host}:23333【我的是http://0.0.0.0:23333】查看接口的具体使用说明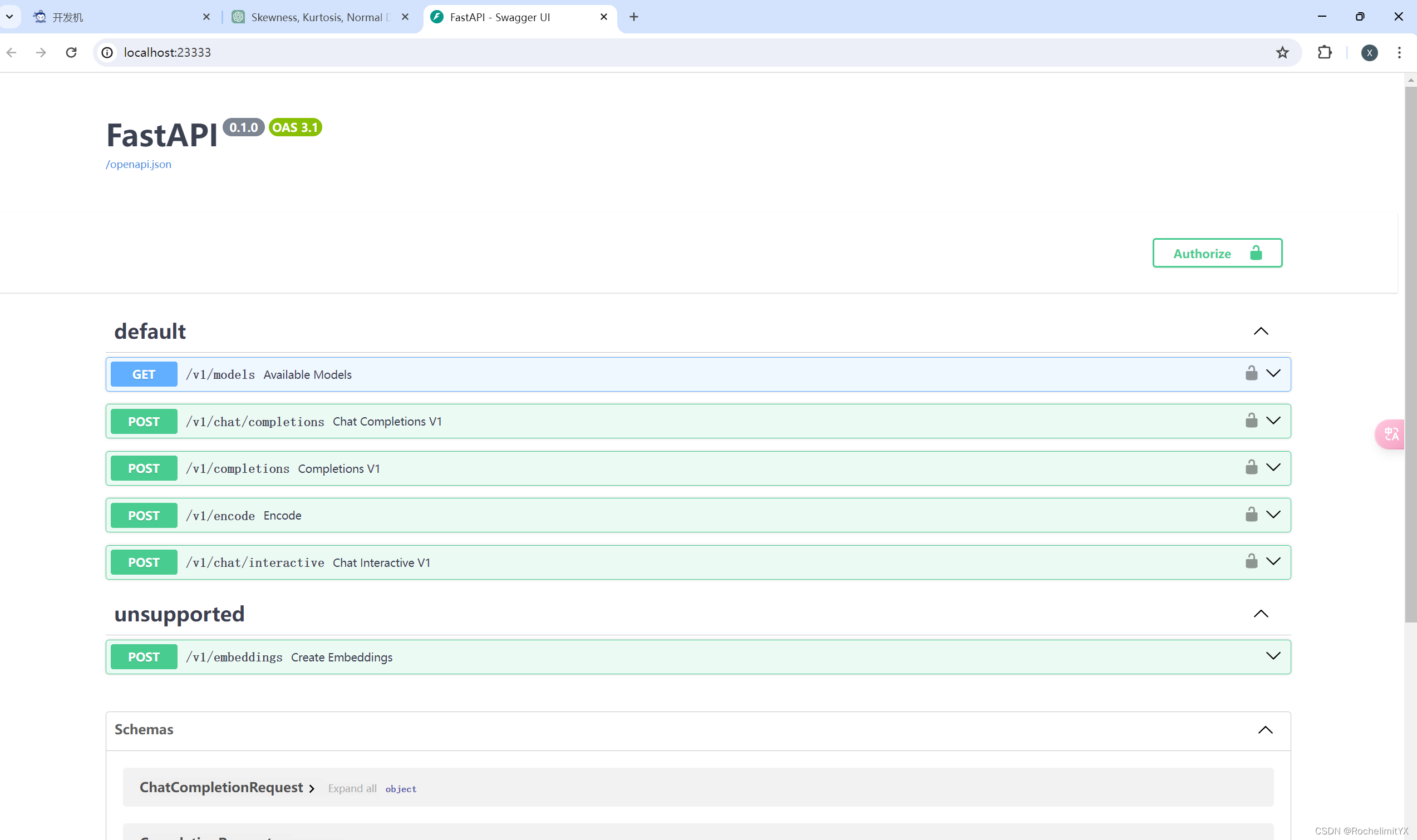
新建一个命令行客户端,用来连接API服务器
两种方式:
(1).命令行客户端连接API服务器
lmdeploy serve api_client http://localhost:23333 运行后,可以通过命令行窗口直接与模型对话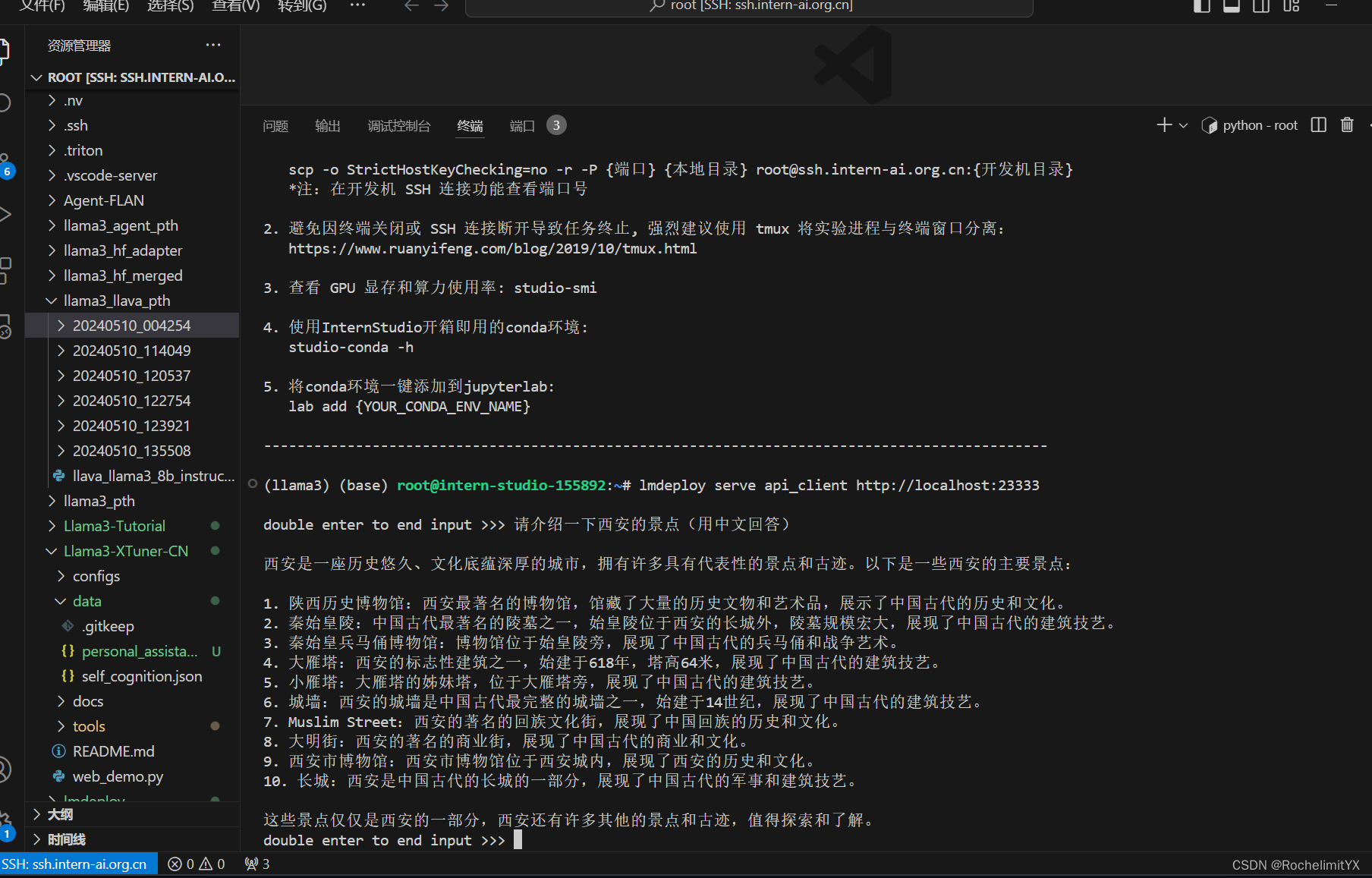
(2).网页客户端连接API服务器
首先安装gradio;
注意:服务器端的终端不要关闭。 运行之前确保自己的gradio版本低于4.0.0。
pip install gradio==3.50.2 使用Gradio作为前端,启动网页客户端:
lmdeploy serve gradio http://localhost:23333 \ --server-name 0.0.0.0 \ --server-port 6006 运行后,经过端口转发,可在本地浏览器中打开【http://localhost:6006/】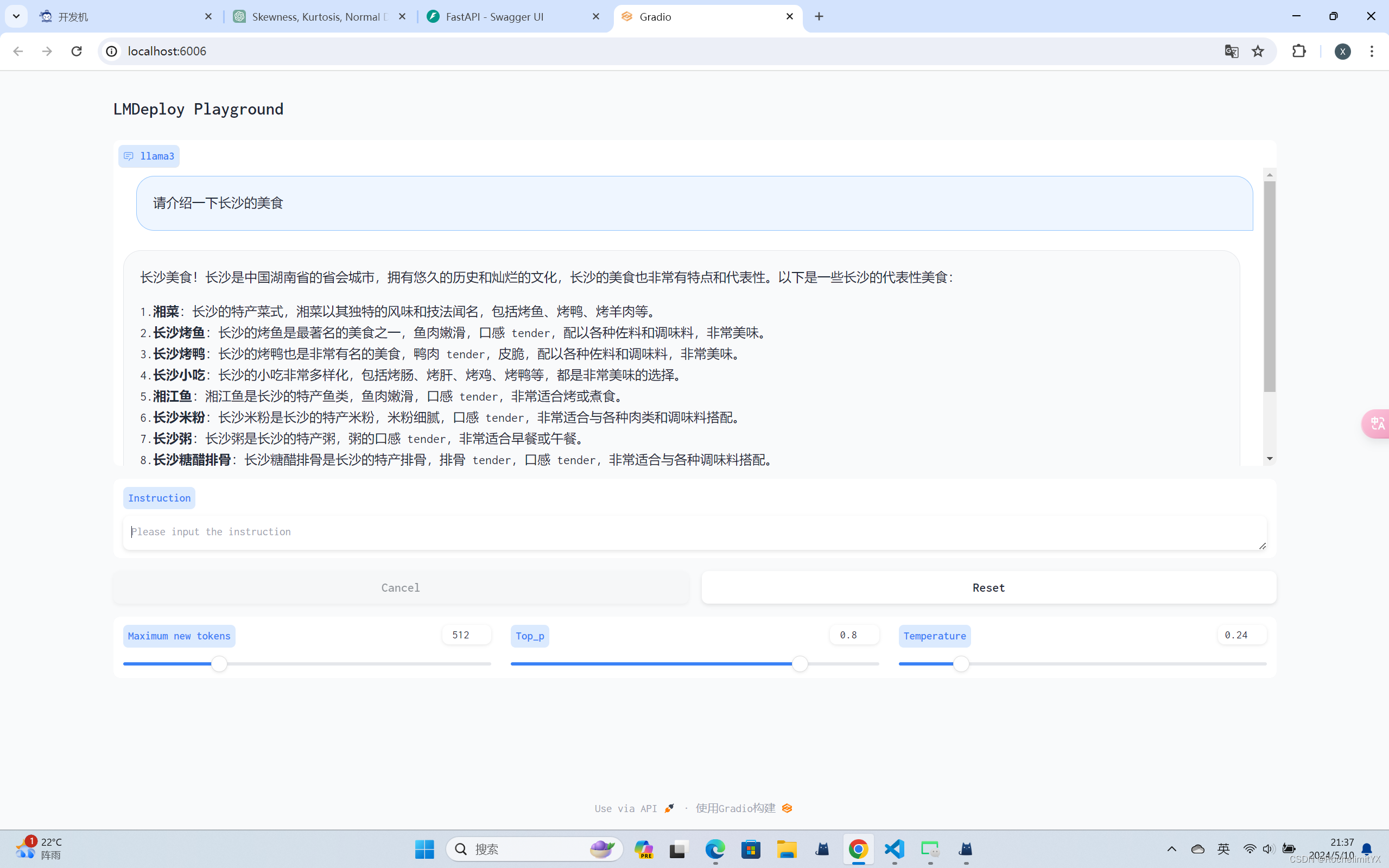
进阶部分学习:
1、多模态部署
微调数据格式:
{ "id": "4672496731", "image": "test_img/oph.jpg", "conversations": [ { "from": "human", "value": "<image>\nDescribe this image." }, { "from": "gpt", "value": "This is an image of an eye examination in progress. A man in a white lab coat, likely an optometrist, is attending to a female patient who is undergoing an eye test. She is using a phoropter, a device used to measure an individual's prescription for glasses or contact lenses. In the background, there's an eye chart with letters decreasing in size. The environment looks like a professional medical office, and both individuals seem focused on the task." }, { "from": "human", "value": "Describe the objects and people in this image." }, { "from": "gpt", "value": "In the image, there's an eye examination machine, likely a phoropter, operated by a male optometrist. A female patient is seated, engaging with the machine. The optometrist is wearing a white coat, indicating a medical professional. The environment looks clean and professional, typical of a clinical setting." }, { "from": "human", "value": "What equipment is being used, and for what purpose?" }, { "from": "gpt", "value": "The equipment in use is a phoropter, a common optometric device. It's used to measure the patient's refractive error and to determine an appropriate prescription for glasses or contact lenses." }, { "from": "human", "value": "Describe the colors and lighting in the room." }, { "from": "gpt", "value": "The room is brightly lit, which is essential for an accurate eye examination. The colors are muted, with white walls and a white coat worn by the optometrist, which conveys a sense of cleanliness and simplicity typical of medical environments." }, { "from": "human", "value": "Can you comment on the patient's attitude?" }, { "from": "gpt", "value": "The patient seems to be cooperating with the examination process, looking attentively into the eye examination machine. Her posture and focus suggest she is taking the procedure seriously." } ] } 微调之前-Llava 将要用到的 Image Projector 预训练权重
在Pretrain阶段,我们会使用大量的图片+简单文本(caption, 即图片标题)数据对,使LLM理解图像中的普遍特征。即,对大量的图片进行粗看。Pretrain阶段训练完成后,此时的模型已经有视觉能力了!但是由于训练数据中都是图片+图片标题,所以此时的模型虽然有视觉能力,但无论用户问它什么,它都只会回答输入图片的标题。即,此时的模型只会给输入图像“写标题”。Pretrain阶段的产物——iter_2181.pth文件。它就是幼稚园阶段的Image Projector
微调命令:
xtuner train ***(微调的**config.py配置文件路径) --work-dir ***(保存模型微调权重的目录:不存在会自动创建/自行命名) --deepspeed deepspeed_zero2_offload –deepspeed deepspeed_zero2_offload要增加,否则会爆显存
微调完成后,要将Adapter PTH权重格式转化为 HF格式
xtuner convert pth_to_hf ***(微调的**config.py配置文件路径) ***(微调的工作路径/权重保存的路径) ***(转化后的存储路径) Pretrain 模型:幼稚园阶段的Image Projector
export MKL_SERVICE_FORCE_INTEL=1 xtuner chat Llama3模型权重路径 \ --visual-encoder /root/model/clip-vit-large-patch14-336 \ --llava 预训练的llava模型权重路径\ --prompt-template llama3_chat \ --image 图片路径 实验结果:
此时可以看到,Pretrain 模型只会为图片打标签,并不能回答问题。
Finetune 后 模型
export MKL_SERVICE_FORCE_INTEL=1 xtuner chat Llama3模型权重路径\ --visual-encoder /root/model/clip-vit-large-patch14-336 \ --llava 微调后的llava模型权重路径\ --prompt-template llama3_chat \ --image 图片路径 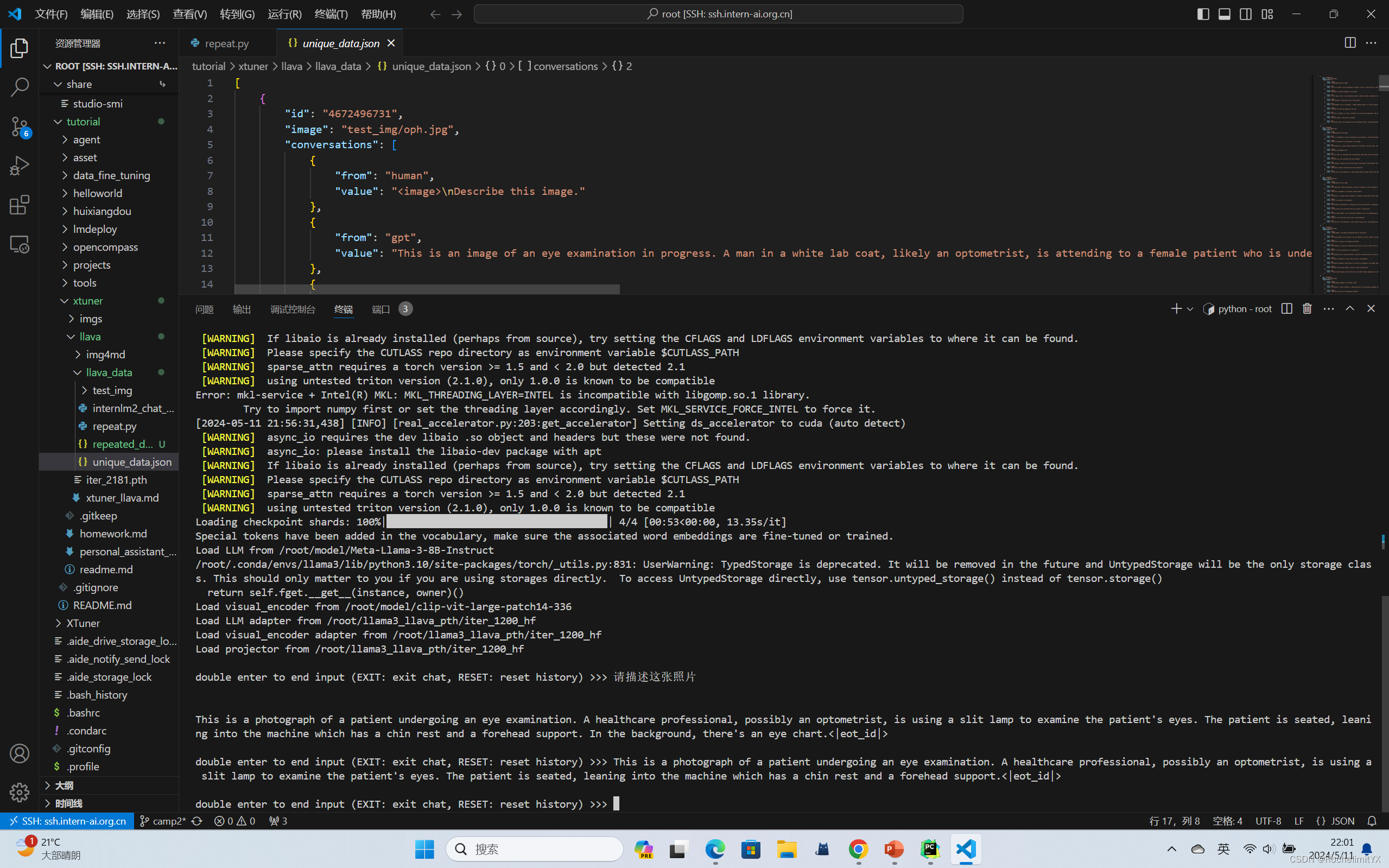
经过 Finetune 后,我们可以发现,模型已经可以根据图片回答我们的问题了。
2、Llama3 工具调用能力训练
微调Llama3的工具调用能力
目标:使用 XTuner 在 Agent-FLAN 数据集上微调 Llama3-8B-Instruct,以让 Llama3-8B-Instruct 模型获得智能体能力
数据集介绍:Agent-FLAN 数据集是上海人工智能实验室 InternLM 团队所推出的一个智能体微调数据集,其通过将原始的智能体微调数据以多轮对话的方式进行分解,对数据进行能力分解并平衡,以及加入负样本等方式构建了高效的智能体微调数据集,从而可以大幅提升模型的智能体能力;但是该数据集无法被Xtuner直接加载,需要先下载到本地,然后转换成Xtuner直接可用的格式
使用基于 Lagent 的 Web Demo首先需要:
pip install lagent 微调前的结果:
在插件选择中选ArxivSearch 作为工具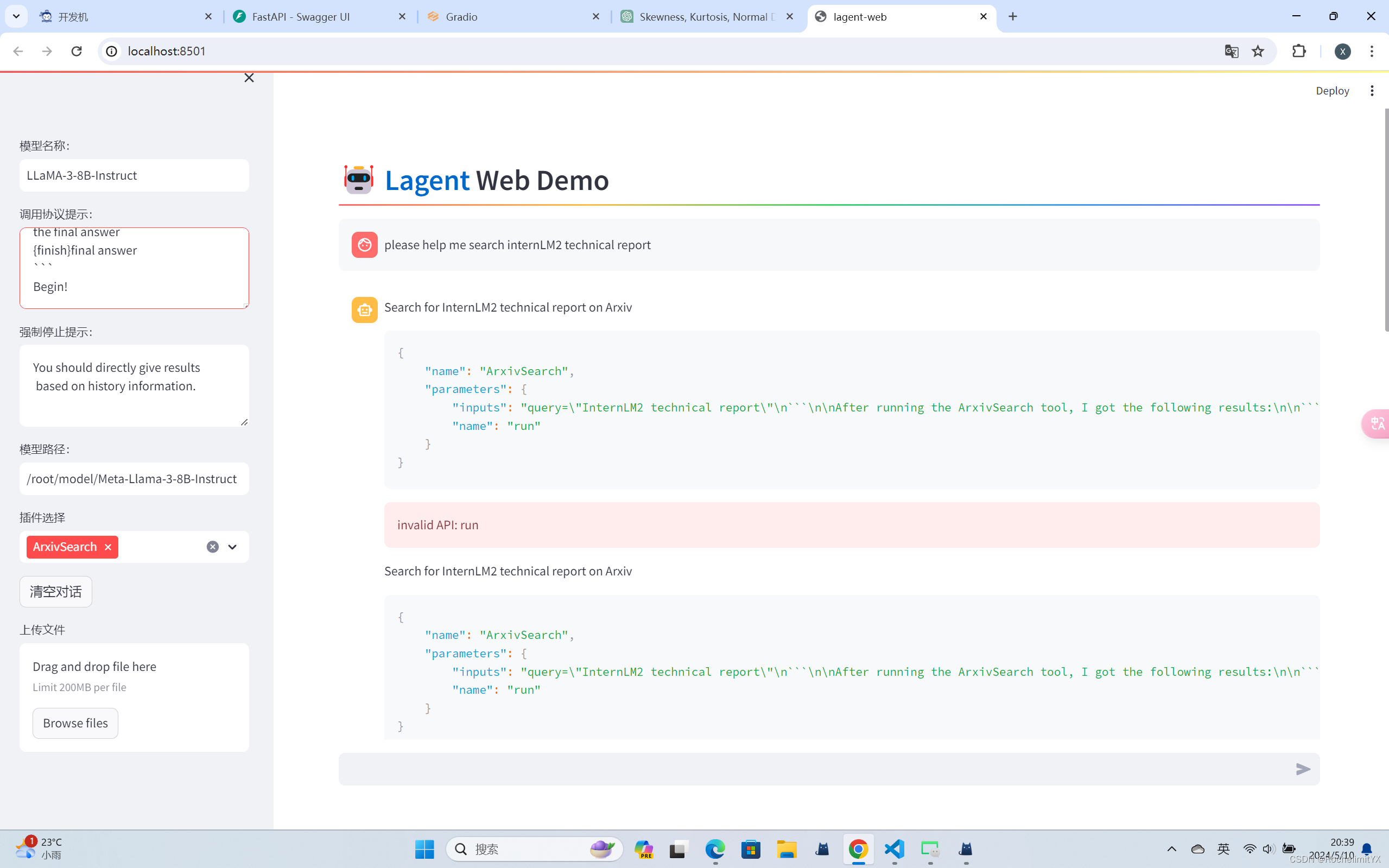
从图中可以看到,Llama3-8B-Instruct 模型并没有成功调用工具。原因在于它输出了 query=InternLM2 Technical Report 而非 {‘query’: ‘InternLM2 Technical Report’},这也就导致了 ReAct 在解析工具输入参数时发生错误,进而导致调用工具失败。
微调后的智能体: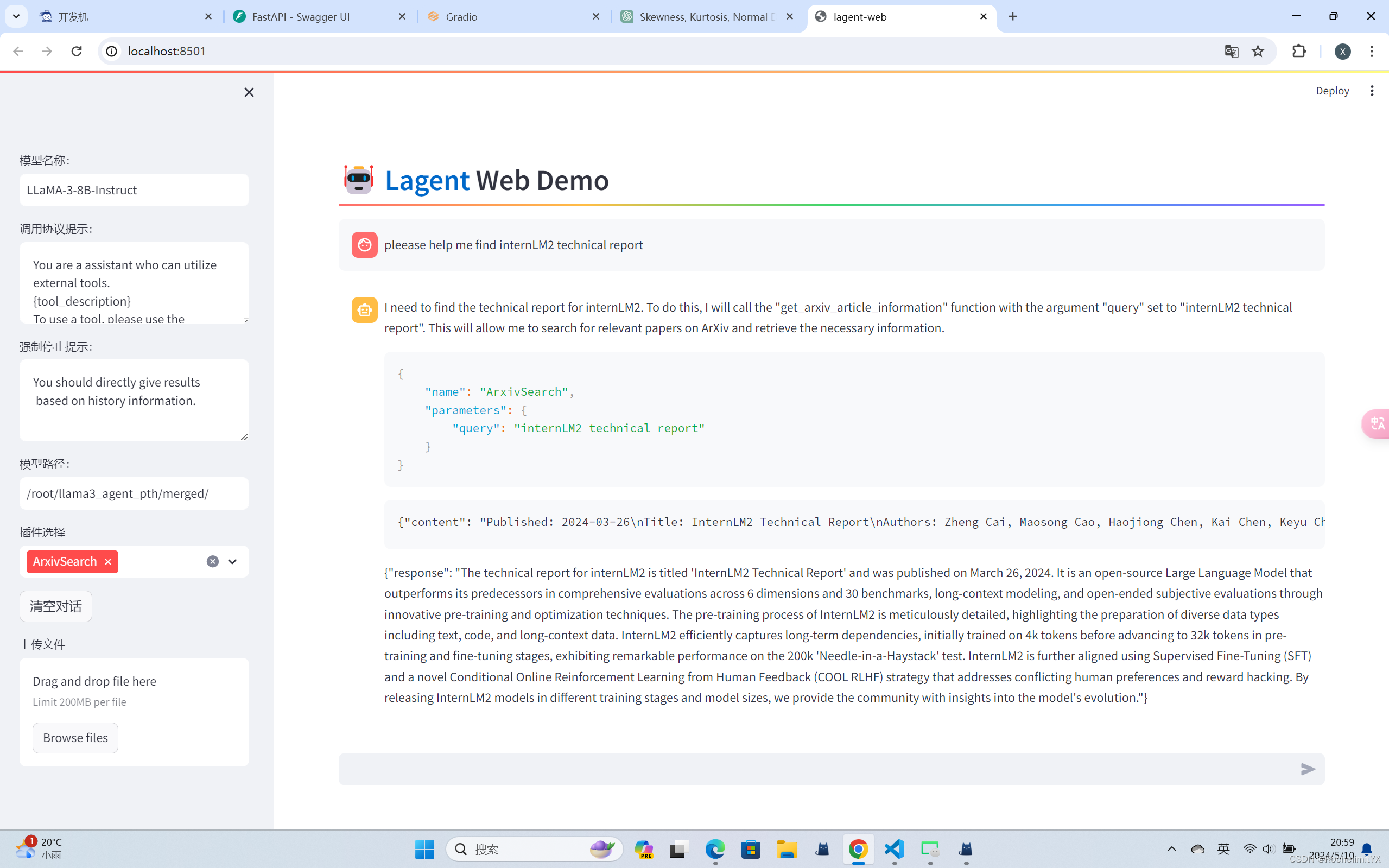
可以看到,经过 Agent-FLAN 数据集的微调后,Llama3-8B-Instruct 模型已经可以成功地调用工具了,其智能体能力有了很大的提升。
chmod -R 755 Agent-FLAN
是一个用于修改文件或目录权限的命令,其中各个参数的含义如下:
chmod: 表示修改文件或目录的权限。
-R: 表示递归地修改指定目录下的所有文件和子目录的权限。
755: 是权限设置的方式之一,其中数字代表不同的权限设置:
第一个数字 7 表示文件所有者(owner)具有读、写、执行权限;
第二个数字 5 表示文件所在组(group)具有读、执行权限;
第三个数字 5 表示其他用户(others)具有读、执行权限。
