
阅读量:0
目录
1、stream流
1.1 stream流的作用

1.2 stream流的思想

注:stream流就是流水线工作,即将数据放入流水线(
获取流对象),然后加工(中间方法),最后输出(终结方法)。
1.3 获取stream流对象

package com.itheima.stream; import java.util.*; import java.util.stream.Stream; public class StreamDemo1 { /** * 获取Stream流对象演示: * - 将数据放在流水线的传送带上 * * 1、集合获取 Stream 流对象 (使用Collection接口中的默认方法) * default Stream<E> stream() * 注意:Map集合获取Stream流对象,需要间接获取: * - map.entrySet().stream() * * 2、数组获取 Stream 流对象 (使用Array数组工具类中的静态方法) * static <T> Stream<T> stream (T[] array) * * 3、零散的数据获取Stream 流对象 (使用Stream类中的静态方法) * static <T> Stream<T> of(T... values) */ public static void main(String[] args) { //1、集合获取 Stream 流对象 //1.1 List集合获取 Stream 流对象 List<String> list = new ArrayList<>(); list.add("张三丰"); list.add("张无忌"); list.add("张翠山"); list.add("王二麻子"); list.add("张良"); list.add("谢广坤"); list.stream().forEach(s -> {System.out.println(s);}); //1.2 Set集合获取 Stream 流对象 Set<String> set = new HashSet<>(); set.add("张三丰"); set.add("张无忌"); set.add("张翠山"); set.add("王二麻子"); set.add("张良"); set.add("谢广坤"); set.stream().forEach(s -> System.out.println(s)); //1.3 Map集合获取 Stream 流对象 Map<String, Integer> map = new HashMap<>(); map.put("张三丰", 100); map.put("张无忌",98); map.put("张翠山",29); map.put("王二麻子",55); map.put("张良",68); map.put("谢广坤",70); map.entrySet().stream().forEach(s -> System.out.println(s)); //2、数组获取 Stream 流对象 int[] arr1 = {11,22,33}; double[] arr2 = {11.1,22.2,33.3}; Arrays.stream(arr1).forEach(s -> System.out.println(s)); Arrays.stream(arr2).forEach(s -> System.out.println(s)); //3、零散的数据获取Stream 流对象: 零散就是这些数既没有在集合中,也没有在数组中 Stream.of(1,2,3,4,5,6).forEach(s -> System.out.println(s)); Stream.of("11","22","33","44").forEach(s -> System.out.println(s)); } } 1.4 stream流中间操作方法

package com.itheima.stream; import java.util.ArrayList; import java.util.List; import java.util.stream.Collectors; import java.util.stream.Stream; public class StreamDemo2 { /** * Stream流的中间操作方法: * - 操作后返回Stream流对象,可以继续操作 * * Stream<T> filter(Predicate<? super T> predicate) 用于对流中的数据进行过滤 * Stream<T> limit(long maxSize) 获取前几个元素 * Stream<T> skip(long n) 跳过前几个元素 * Stream<T> distinct() 去除流中重复的元素依赖(hashCode 和 equals方法) * static <T> Stream<T> concat(Stream a, Stream b) 合并a和b两个流为一个流 * - 注意:如果流的对象消费过(使用过),就不允许再消费了。 */ public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张三丰"); list.add("张无忌"); list.add("张翠山"); list.add("王二麻子"); list.add("张良"); list.add("谢广坤"); //需求1:将集合中以【张】开头的数据 和 长度为3,过滤出来并打印在控制台 list.stream().filter(v -> v.startsWith("张")).filter(v -> v.length() == 3).forEach(e -> System.out.println(e)); System.out.println("-------------------------------------"); //需求2:取前3个数据在控制台输出 ---> limit(long maxSize) 获取前几个元素 list.stream().limit(3).forEach(e -> System.out.println(e)); System.out.println("-------------------------------------"); //需求3:跳过3个元素,把剩下的元素在控制台输出 ---> skip(long n) 跳过前几个元素 list.stream().skip(3).forEach(e -> System.out.println(e)); System.out.println("-------------------------------------"); //需求4:跳过2个元素,把剩下的元素中前2个在控制台输出 list.stream().skip(2).limit(2).forEach(e -> System.out.println(e)); System.out.println("-------------------------------------"); //需求5:取前4个数据组成一个流 Stream<String> stream1 = list.stream().limit(4); System.out.println("-------------------------------------"); //需求6:跳过2个数据组成一个流 Stream<String> stream2 = list.stream().skip(2); System.out.println("-------------------------------------"); //需求7:合并需求1和需求2得到的流,并把结果在控制台输出 Stream<String> stream3 = Stream.concat(stream1, stream2); // stream3.forEach(e -> System.out.println(e));//注意:流用过之后,不可以再用了 System.out.println("-------------------------------------"); //需求8:合并需求1和需求2得到的流,并把结果在控制台输出,要求字符串元素不能重复 stream3.distinct().forEach(e -> System.out.println(e)); System.out.println("-------------------------------------"); } } 
1.5 stream流终结操作方法

package com.itheima.stream; import java.util.ArrayList; import java.util.List; import java.util.stream.Stream; public class StreamDemo3 { /** * Stream流的终结操作方法 * - 流水线中的最后一道工序 * * public void forEach(Consumer action) 对此流的每个元素执行遍历操作 * public long count() 返回此流中的元素数 */ public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张三丰"); list.add("张无忌"); list.add("张翠山"); list.add("王二麻子"); list.add("张良"); list.add("谢广坤"); //1、forEach(Consumer action) 对此流的每个元素执行遍历操作 list.stream().forEach(e -> System.out.println(e)); //2、long count() 返回此流中的元素数 System.out.println(list.stream().count());//6 System.out.println(Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).count());//9 } } 1.6 stream收集操作
注意:
Stream不会修改原始的集合,因此在流里的操作后的结果,需要用新的集合来保存。

package com.itheima.stream; import java.util.ArrayList; import java.util.List; import java.util.Map; import java.util.Set; import java.util.function.Function; import java.util.function.Predicate; import java.util.stream.Collectors; import java.util.stream.Stream; public class StreamDemo4 { /** * Stream流的收集操作: * public R collect (Collector c):将流中的数据收集到集合 * * Collectors * public static <T> Collector toList() * public static <T> Collector toSet() * public static <T> Collector toMap(Function keyMapper,Function valueMapper) */ public static void main(String[] args) { //1、toList():将流对象收集到list集合中 List<Integer> list = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10).filter(e -> e % 2 == 0).collect(Collectors.toList()); System.out.println(list);//[2, 4, 6, 8, 10] //2、toSet():将流对象收集到set集合中 ---> 注意,收集时set还是会去重 Set<Integer> set = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10,10,10,10).filter(e -> e % 2 == 0).collect(Collectors.toSet()); System.out.println(set);//[2, 4, 6, 8, 10] //3、toMap()方法比较复杂,用一个需求来介绍: /* 需求:创建一个 ArrayList 集合,并添加以下字符串 "张三,23", "李四,24", "王五,25" 保留年龄大于等于24岁的人,并将结果收集到Map集合中,姓名为键,年龄为值 */ ArrayList<String> arrayList = new ArrayList<>(); arrayList.add("张三,23"); arrayList.add("李四,24"); arrayList.add("王五,25"); Map<String, Integer> map1 = arrayList.stream().filter(s -> Integer.parseInt(s.split(",")[1]) >= 24).collect(Collectors.toMap( new Function<String, String>() { @Override public String apply(String s) {//第一个匿名内部类 ---》指定key return s.split(",")[0]; } }, new Function<String, Integer>() { @Override public Integer apply(String s) {//第二个匿名内部类 ---》指定value return Integer.parseInt(s.split(",")[1]); } })); //上述写法可写成lambda表达式,如下: Map<String, Integer> map2 = arrayList.stream().filter(s -> Integer.parseInt(s.split(",")[1]) >= 24). collect(Collectors.toMap(s -> s.split(",")[0], s -> Integer.parseInt(s.split(",")[1]))); System.out.println(map1);//{李四=24, 王五=25} } } 1.7 stream的综合案例

package com.itheima.stream; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.stream.Collectors; import java.util.stream.Stream; public class StreamDemo5 { public static void main(String[] args) { List<String> list1 = new ArrayList<>(); list1.add("林菲菲"); list1.add("李飞飞"); list1.add("林格格"); list1.add("黄方面"); list1.add("林黛玉十"); list1.add("林黛玉"); List<String> list2 = new ArrayList<>(); list2.add("马大炮"); list2.add("猪八戒"); list2.add("唐僧"); list2.add("孙悟空"); list2.add("狗蛋蛋"); list2.add("范杰杰"); Stream<String> stream1 = list1.stream().filter(v -> v.startsWith("林")).skip(1); Stream<String> stream2 = list2.stream().filter(v -> v.length() == 3).limit(2); List<String> collect = Stream.concat(stream1, stream2).collect(Collectors.toList());//把两个流合并为一个使用concat方法 Map<String, Actor> map = new HashMap<>(); for (String s : collect) { Actor a = new Actor(s); map.put(s, a); } System.out.println(map);//{林黛玉十=Actor{name='林黛玉十'}, 林格格=Actor{name='林格格'}, 猪八戒=Actor{name='猪八戒'}, 林黛玉=Actor{name='林黛玉'}, 马大炮=Actor{name='马大炮'}} } } 未完待续。。。。。。
2、File类
2.1 File类创建文件对象
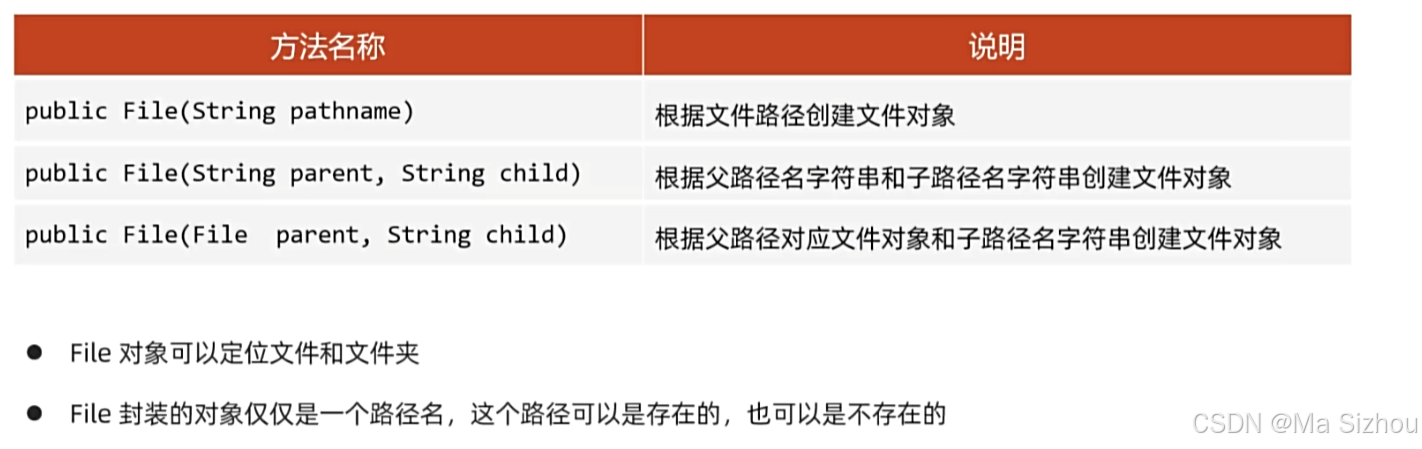
package com.itheima.file; import java.io.File; import java.io.IOException; public class FileDemo1 { /** * File类介绍 : 文件或文件夹对象 * * 构造方法 : * 1、public File(String pathname):根据传入的字符串路径封装File对象 * 2、public File(String pathname,String child):根据传入的父级路径和子级路径来封装File对象 * 3、public File(File parent, String child):根据传入的父级路径(File类型)和子级路径来封装File对象 */ public static void main(String[] args) throws IOException { //1、File(String pathname):根据传入的字符串路径封装File对象 File f1 = new File("E:\\A.txt");//读取文件对象 f1.createNewFile(); File f2 = new File("E:\\test");//读取文件夹 System.out.println(f2.exists());//存在返回true,不存在返回false //2、File(String pathname,String child):根据传入的父级路径和子级路径来封装File对象 File f3 = new File("E:\\", "test");//父路径+子路径,封装File对象 System.out.println(f3.exists());//true //3、File(File parent, String child):根据传入的父级路径(File类型)和子级路径来封装File对象 File f4 = new File(new File("E:\\"), "test"); System.out.println(f4.exists());//true } } 注意:文件夹路径有相对路径和绝对路径两种写法

package com.itheima.file; import java.io.File; import java.io.IOException; public class FileDemo2 { /** * 路径的写法: * 1、相对路径:相对于当前项目 * 2、绝对路径:从盘符根目录开始,一直到某个具体的文件或文件夹 */ public static void main(String[] args) throws IOException { //1、相对路径 File f1 = new File("A.txt"); f1.createNewFile(); //2、绝对路径 File f2 = new File("E:\\test\\A.txt"); } } 2.2 File类的常用方法
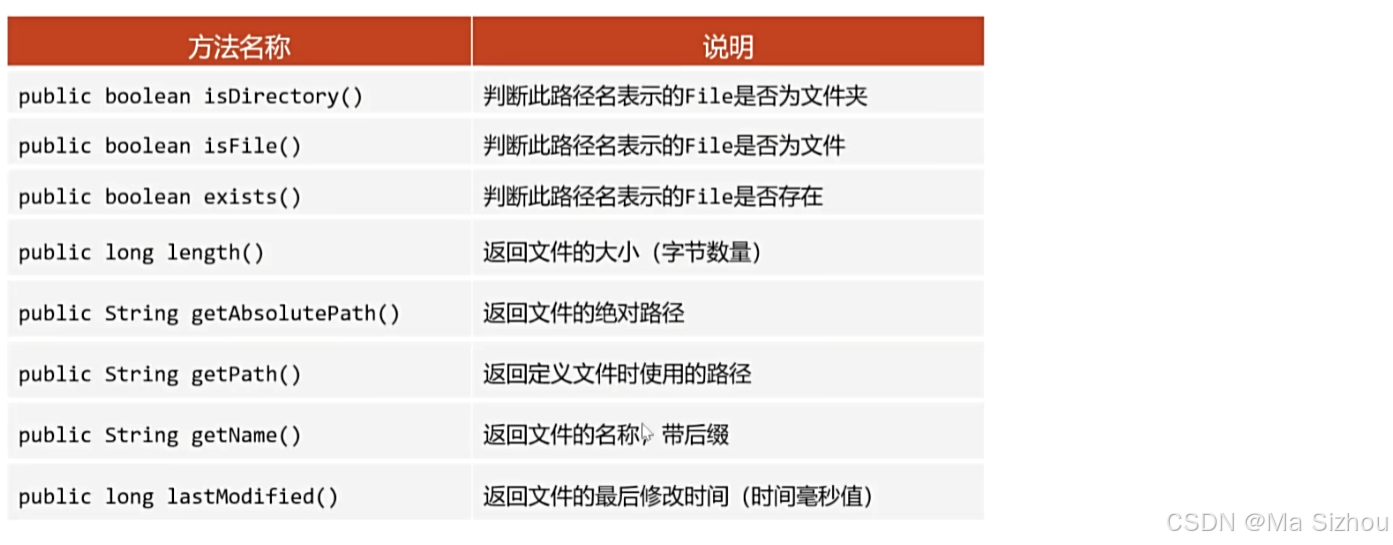
package com.itheima.file; import java.io.File; import java.time.LocalDateTime; import java.util.Date; public class FileDemo3 { /** * File类常见方法: * 1、判断相关 * public boolean isDirectory():判断是否是文件夹 * public boolean isFile():判断是否是文件 * public boolean exists():判断是否存在 * * 2、获取相关 * public long length():返回文件的大小(字节数量) * - 为文件对象时,返回正确的字节数量 * - 为文件夹对象时,返回错误的字节数量 * public String getAbsolutePath():返回文件的绝对路径 * public String getPath():返回文件使用时的路径 * public String getName():返回文件的名称,带后缀 * public long lastModified():返回文件的最后修改时间(时间毫秒值) */ public static void main(String[] args) { //1、判断相关 File f1 = new File("E:\\A.txt"); //isDirectory():判断是否是文件夹 System.out.println(f1.isDirectory()); //isFile():判断是否是文件 System.out.println(f1.isFile()); //exists():判断是否存在 System.out.println(f1.exists()); System.out.println("---------------------------------------"); //2、获取相关 File f2 = new File("E:\\GNN"); //length():返回文件的大小(字节数量) System.out.println(f1.length());//为文件对象时,返回正确的字节数量 System.out.println(f2.length());//为文件夹对象时,返回错误的字节数量 //getAbsolutePath():返回文件的绝对路径 System.out.println(f1.getAbsoluteFile());//E:\A.txt System.out.println(f2.getAbsoluteFile());//E:\GNN //getPath():返回文件使用时的路径 System.out.println(f1.getPath());//E:\A.txt System.out.println(f2.getPath());//E:\GNN //getName():返回文件的名称,带后缀 System.out.println(f1.getName());//A.txt System.out.println(f2.getName());//GNN //lastModified():返回文件的最后修改时间(时间毫秒值) System.out.println(f1.lastModified());//1721657586035 System.out.println(f2.lastModified());//1601530884989 System.out.println(new Date(f2.lastModified()));//Thu Oct 01 13:41:24 CST 2020 } } 
package com.itheima.file; import java.io.File; import java.util.Scanner; public class FileDemo4 { public static void main(String[] args) { File dir = getDir(); System.out.println(dir); } public static File getDir(){ Scanner sc = new Scanner(System.in); System.out.println("请输入文件路径:"); while (true) { String dir = sc.nextLine(); File f = new File(dir); if (!f.exists()) { System.out.println("你输入的文件路径不存在,请重新输入!"); } else if (f.isFile()) { System.out.println("你输入的是一个文件,请重新输入!"); } else { return f; } } } } 2.3 File类的创建和删除方法

package com.itheima.file; import java.io.File; import java.io.IOException; public class FileDemo5 { /** * File类的创建方法和删除方法: * public boolean createNewFile():创建文件 * public boolean mkdir():创建单极文件夹 * public boolean mkdirs():创建多极文件夹 * public boolean delete():删除文件或文件夹 * - delete 方法删除文件夹时,只能删除空的文件夹 */ public static void main(String[] args) throws IOException { //1、createNewFile():创建文件 File f1 = new File("A.txt"); System.out.println(f1.createNewFile());//不存在则创建文件并返回true,存在则返回false //2、mkdir():创建单极文件夹 File f2 = new File("aaa"); System.out.println(f2.mkdir());//不存在则创建文件夹并返回true,存在则返回false //3、mkdirs():创建多极文件夹 File f3 = new File("bbb\\ccc\\ddd"); System.out.println(f3.mkdirs());不存在则创建文件夹并返回true,存在则返回false //4、delete():删除文件或文件夹 System.out.println(f1.delete());//存在则删除并返回true,否则返回false } } 2.4 File类的遍历方法

注意:

package com.itheima.file; import java.io.File; public class FileDemo6 { /** * File类的遍历方法: * public File[] listFiles():获取当前目录下所有的 ”一级文件对象“ 返回File数组 */ public static void main(String[] args) { File f1 = new File("C:\\Users\\MSZ\\Desktop\\java_test\\dev\\day12-code"); File[] files = f1.listFiles(); for (File file : files) { System.out.println(file); } } } 练习一:
需求:键盘录入一个文件夹路径,找出这个文件夹下所有的 .java 文件
package com.itheima.file; import java.io.File; import java.util.Scanner; public class FileDemo7 { /** * 需求:键盘录入一个文件夹路径,找出这个文件夹下所有的 .java 文件 */ public static void main(String[] args) { //1、获取文件夹路径 File dir = getDir(); //2、找出文件夹下的.java文件 for (File file : dir.listFiles()) { if (file.isFile() && file.getName().endsWith(".java")){ System.out.println(file); } } } public static File getDir(){ Scanner sc = new Scanner(System.in); System.out.println("请输文件夹路径:"); while (true) { String path = sc.nextLine(); File f = new File(path); if (f.isFile()){ System.out.println("您输入的是一个文件,请重新输入!"); } else if (!f.exists()) { System.out.println("您输入的问价夹不存在,请重新输入!"); }else { return f; } } } } 上述方法如果遇到多级文件夹下还有.java文件,那就获取不到了,于是我们可以使用递归来解决这个问题:
package com.itheima.file; import java.io.File; import java.util.Scanner; public class FileDemo7 { /** * 需求:键盘录入一个文件夹路径,找出这个文件夹下所有的 .java 文件 */ public static void main(String[] args) { File dir = getDir(); printJavaFile(dir); } public static void printJavaFile(File dir){ //1、获取当前路径下的文件夹和文件的对象 File[] files = dir.listFiles(); //2、遍历数组对象 for (File file : files) { //3、如果.java文件则打印 if (file.isFile() && file.getName().endsWith(".java")){ System.out.println(file); } else if (file.isDirectory()) { //4、如果是文件夹,则递归调用自身继续找.java文件 if (file.listFiles() != null){ printJavaFile(file); } } } } public static File getDir(){ Scanner sc = new Scanner(System.in); System.out.println("请输文件夹路径:"); while (true) { String path = sc.nextLine(); File f = new File(path); if (f.isFile()){ System.out.println("您输入的是一个文件,请重新输入!"); } else if (!f.exists()) { System.out.println("您输入的问价夹不存在,请重新输入!"); }else { return f; } } } } 练习二:

package com.itheima.file; import java.io.File; import java.util.Collections; public class FileDem8 { /** * 需求:设计一个方法,删除文件夹(delete()只能删除空文件夹) */ public static void main(String[] args) { File f = new File("C:\\Users\\MSZ\\Desktop\\java_test\\dev\\test111"); deleteDir(f); } public static void deleteDir(File file){ //获取文件夹下所有的文件对象 File[] files = file.listFiles(); for (File f : files) { if (f.isFile()){ //如果是文件则直接删除 f.delete(); }else { //非空文件夹,递归删除 if (f.listFiles() != null){ deleteDir(f); } } } //循环结束了,表明已经是空文件夹了,则删除此文件夹 file.delete(); } } 练习三:

package com.itheima.file; import java.io.File; public class FileDem9 { /** * 需求:键盘录入一个二五年间加路径,统计文件夹的大小 * -length()方法只能获取文件的大小,不能获取文件夹的大小 */ public static void main(String[] args) { long dirSize = getDirSize(new File("C:\\Users\\MSZ\\Desktop\\java_test\\dev\\code")); System.out.println(dirSize); } public static long getDirSize(File file){ long length = 0L; File[] files = file.listFiles(); for (File f : files) { if (f.isFile()){ //是文件,则获取文件的大小 length += f.length(); }else { //是文件夹,则递归获取里面的文件大小 if (f.listFiles() != null){ length += getDirSize(f); } } } return length; } } 练习四:

package com.itheima.file; import java.io.File; import java.util.HashMap; import java.util.Map; public class FileDem10 { /** * 需求:键盘录入一个文件夹路径,统计文件夹中每种文件的个数并打印(考虑子文件夹) * 打印格式如下: * txt:3个 * doc:4个 * jpg:6个 */ static int count = 0;//统计没有后缀名的文件 static Map<String, Integer> map = new HashMap<>();//存放结果 public static void main(String[] args) { Map<String, Integer> fileNum = getFileNum(new File("C:\\Users\\MSZ\\Desktop\\java_test\\dev\\code")); fileNum.forEach((k, v) -> System.out.println(k + ":" + v + "个")); System.out.println("没有后缀的文件:" + count); } public static Map<String, Integer> getFileNum(File file){ //获取当前目录下所有的 ”一级文件对象“ 返回File数组 File[] files = file.listFiles(); for (File f : files) { if (f.isFile()){ //如果是文件,则对应类型的值+1 String name = f.getName(); if (name.contains(".")){//文件有后缀 String[] split = name.split("\\."); String key = split[split.length - 1]; if (map.containsKey(key)){ map.put(key, map.get(key) + 1); }else { map.put(key, 1); } }else {//文件没有后缀,单独统计 count++; } }else { //如果是文件夹,则递归获取 if (f.listFiles() != null){ getFileNum(f); } } } return map; } } 