
阅读量:0
论文地址:https://arxiv.org/pdf/2407.15462
代码:https://github.com/bailuding/rails
这篇论文题为《Efficient Retrieval with Learned Similarities》,主要讨论了如何在推荐系统、搜索和自然语言处理等领域中,使用学习相似度函数进行高效检索。论文探讨了用近似最近邻搜索技术来实现高效的学习相似度函数检索,提出了一种基于混合逻辑(Mixture of Logits, MoL)的通用近似方法,并展示了其在推荐检索任务中的卓越表现。
以下是论文的详细分析:
摘要
- 检索在推荐系统、搜索和自然语言处理等应用中发挥着关键作用。
- 尽管点积作为相似度函数被广泛使用,但最新的检索算法已迁移到学习相似度上。
- 本文提出了一种基于MoL的近似最近邻检索技术,并证明了其在推荐检索任务中的效率和准确性。
1. 引言
- 检索要求高效地存储、索引和查询由高维向量表示的候选项目。
- 尽管点积相似度广受欢迎,但最新的检索算法已经转向多种学习相似度函数。
- 支持这些多样化的学习相似度函数的高效检索具有挑战性。
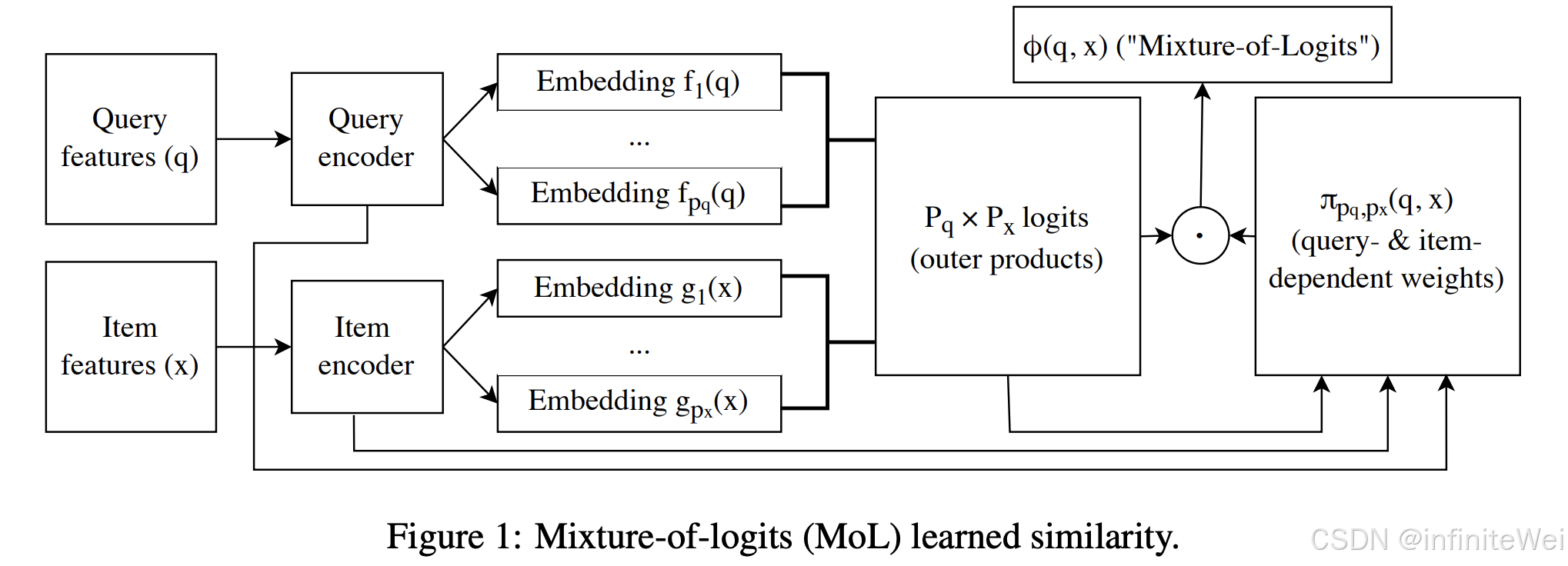
2. 混合逻辑的表达能力
- MoL是一种通用近似器,可以表示任意高秩矩阵,并因此近似所有学习相似度函数。
- 公式 (\phi(q, x) = \sum_{p=1}^P \pi_p(q, x) \langle f_p(q), g_p(x) \rangle) 描述了MoL的工作机制。
3. 检索算法
- 论文定义了基于MoL的Top-K检索问题,并描述了精确和近似算法。
- 精确算法通过两遍遍历数据来检索Top-K项目,首先获取每组嵌入的前K个项目,然后使用MoL评估这些项目的分数。
- 近似算法通过两阶段方法减少计算量,首先生成初始候选集,然后在候选集上进行详细计算。
具体细节
精确算法(Algorithm 1):
- 首先对每个嵌入组检索Top-K项目作为初始候选集。
- 评估初始候选集的MoL分数,并找到最小的相似度分数(S_{min})。
- 检索所有与查询点的距离不小于(S_{min})的项目,构建新的候选集。
- 对新的候选集进行详细计算,最终返回Top-K项目。
近似算法:
- 利用已有向量数据库的高效查询接口如Top-K查询,从而受益于现有的高效向量搜索技术。
贡献
- 证明了MoL是一个通用近似器,可以表达所有学习相似度函数。
- 提出了基于MoL的近似Top-K检索技术,显著提升了检索效率。
- 实验结果表明,本文提出的方法在推荐检索任务中达到了新的最先进水平,在延迟方面比基线算法快了最多91倍,同时实现了超过0.99的召回率。
论文在背景部分和相关工作中提到了几类相关研究。以下是一些主要的相关研究方向和工作:
1. 近似最近邻搜索 (Approximate Nearest Neighbor Search)
- Annoy, FAISS, HNSW: 这些是高效的近似最近邻搜索库,广泛用于点积相似度和L2距离计算。它们利用不同的数据结构(如KD树、簇树和小世界图)来加速检索。
- Annoy: 适用于大规模、高维度数据的近似最近邻搜索。
- FAISS (Facebook AI Similarity Search): 提供多种索引结构和量化技术,用于高效的向量相似度搜索。
- HNSW (Hierarchical Navigable Small World): 基于小世界图的算法,支持高效的近似最近邻搜索。
2. 学习相似度函数 (Learned Similarity Functions)
- Deep Learning-Based Similarity: 深度学习模型(如Siamese Networks和Triplet Networks)通过学习数据嵌入来优化相似度函数,使其能够捕捉复杂的关系。
- Siamese Networks: 用于比较两个输入的相似性,通过共享权重的网络结构学习特征表示。
- Triplet Networks: 通过三元组损失函数(anchor, positive, negative)来优化嵌入,使得相似样本更接近,不相似样本更远离。
3. 通用近似方法 (General Approximation Methods)
- Mixture of Logits (MoL): 论文提出的MoL模型是一种通用的近似器,可以逼近任意高秩矩阵,从而适用于多种学习相似度函数。这种方法通过混合不同的逻辑回归模型来表达复杂的相似度关系。
4. 高效Top-K检索算法 (Efficient Top-K Retrieval Algorithms)
- Two-Stage Retrieval: 论文中的算法采用了两阶段的方法,首先生成初始候选集,然后在候选集上进行详细计算。这种方法兼顾了效率和准确性。
- Existing Vector Databases: 利用现有向量数据库(如Faiss)的高效查询接口,进一步减少计算量,提高检索速度。
5. 推荐系统 (Recommendation Systems)
- Collaborative Filtering: 传统的协同过滤方法(如矩阵分解、基于邻居的方法)主要使用点积相似度来预测用户偏好。
- Neural Collaborative Filtering: 基于神经网络的协同过滤方法,通过学习非线性的用户和物品嵌入,提高推荐精度。
6. 其它相关工作
- Efficient Similarity Search in High Dimensions: 研究如何在高维空间中进行高效的相似度搜索,涉及降维技术和索引结构优化。
- Learning to Rank: 排序学习方法通过学习模型来优化检索结果的排序,在搜索引擎和推荐系统中广泛应用。
论文通过在上述研究基础上,提出了基于MoL的高效检索方法,展示了其在推荐系统中的优越性能。
结论
- 本文提出的方法为高效检索提供了一种通用解决方案,并在推荐系统等实际应用中展示了其潜力。
如果您对论文的某些部分需要更详细的分析或者有特定的问题,请告诉我,我可以进一步解释或深入讨论。
