
阅读量:0

GROUP BY 查询子句的时序语义展开,IoTDB 支持的分段方式总结!
存储的数据通过分析来发挥价值,当一组被存储的数据通过查询得到分析后的结果时,这些数据才真正在数据库中实现了价值闭环。
在关系型数据库中,GROUP BY 子句是 SQL 语言中用于将结果集按照一个或多个列分组的关键字。它通常与聚合函数一起使用,如 COUNT(), SUM(), AVG(), MIN(), MAX() 等,以便对每个分组的数据进行统计或计算。但由于关系型数据库中的数值没有时间顺序的概念,所以在分组时并不会考虑分组键前后。
如下图所示:基于值列的分组通常以数据是否等值为分组条件,分段方式较为固定。

而时序场景下,比起分组键的列值组合,我们通常更加在意时间维度前后数据的联系。基于时间列分组,可能要求不同大小的滑动窗口等符合时序语义的分段方式。

因此 IoTDB 提供了针对基于时间列的新型分段场景,支持用户使用内置简单 SQL 语句快速便捷的对时序数据进行分段,更好的提取时序数据的相关特征,帮助用户更高效的在时序场景下发掘数据价值。
01 方法一:按时间区间分段
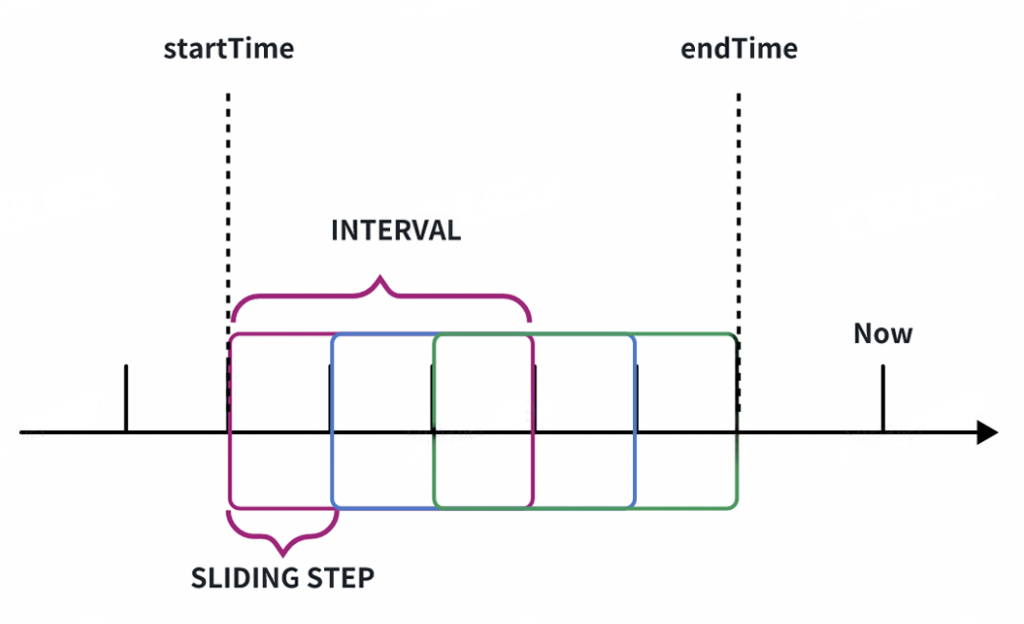
作为最基本的时间分段方式,IoTDB 可以支持基本的时间滑动窗口分段。可以指定聚合的时间间隔和滑动步长来定义窗口。其 SQL 主要包含三个参数:
[startTime, endTime): 查询的时间范围
interval: 单个分段窗口的大小
sliding step: 窗口的滑动步长
GROUP BY ([startTime, endTime), size, step)下图展示了这三个参数的含义:
02 方法二:按数据差值分段
传统的分段方式可以对相同的值进行分段,在时序语义下,由于数据可以保证按时间顺序到来,我们可以将值的变化规律作为分段的依据。
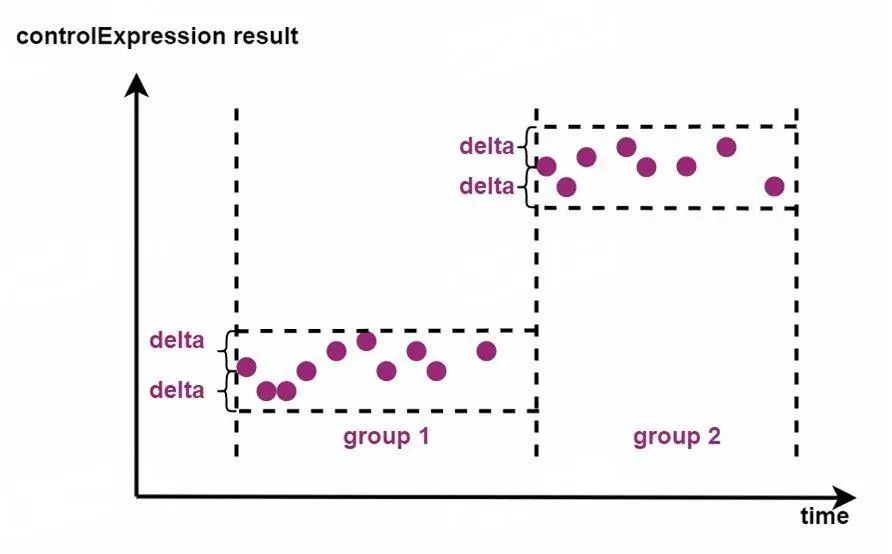
在 IoTDB 的差值分段中,我们将第一条数据作为一个时间段的基准,每个分段会按照给定表达式与基准数值行进行差值运算,如果差值小于给定的阈值则加入当前时间段;如果超过给定阈值,则分为下一个时间段。
下图解释了该分段方式:
其 SQL 与不同的参数含义如下:
GROUP BY VARIATION(controlExpression[,delta][,ignoreNull=true/false])controlExpression:分组所参照的值,可以是数据行中的某一列或是多列的表达式
delta:分组所使用的阈值,默认为 0
ignoreNull:用于指定 controlExpression 计算结果为 null 时对数据的处理方式,ignoreNull 为 true 时,则直接跳过对应的点,否则创建新的时间段。
03 方法三:按会话间隔分段
在实际场景,即使是有序的时间列,可能也并不连续。而这些时间列之间的时间间隔便可以作为分段的依据,会话分段可以将时间间隔超过一定阈值的数据切割为不同时间段。如下所示:
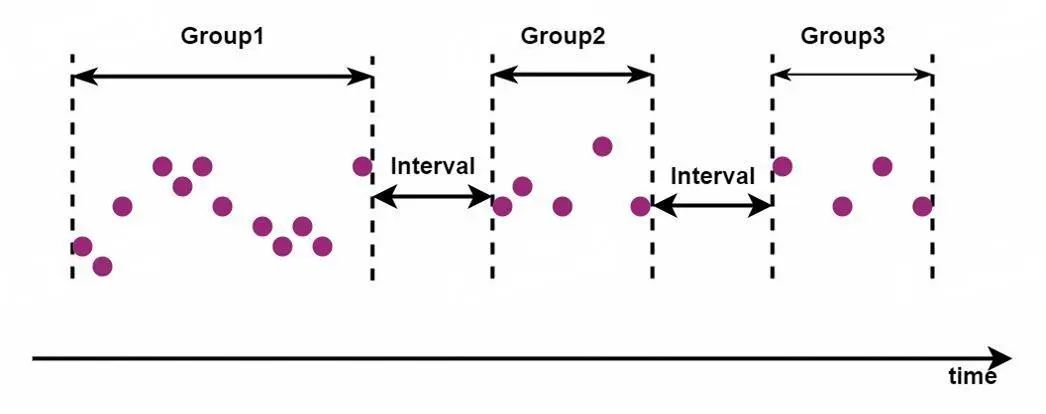
GROUP BY SESSION(timeInterval)04 方法四:按数据点数分段
在一些场景中,我们会在时序语义下基于连续的时间点数做分段,将连续的指定数量数据点分为一组。如下所示:
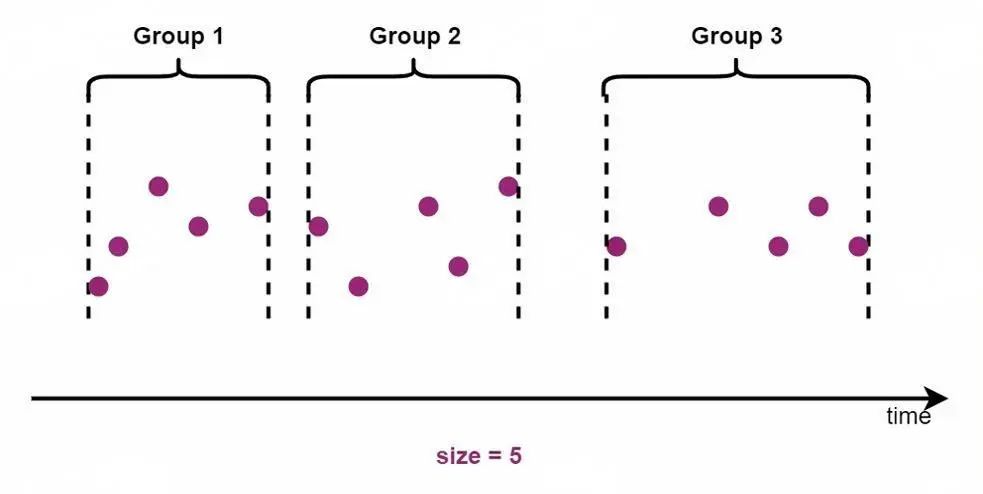
GROUP BY COUNT(controlExpression,size[,ignoreNull=true/false])05 方法五:按符合条件的数据点数分段
对于顺序到来的数据,我们还可以指定条件表达式来对数据行进行筛选。将符合条件的连续数据点加入时间段,如下图,将数值为 True 的数据点每三个分为一段,其分段示意图和 SQL 定义如下:
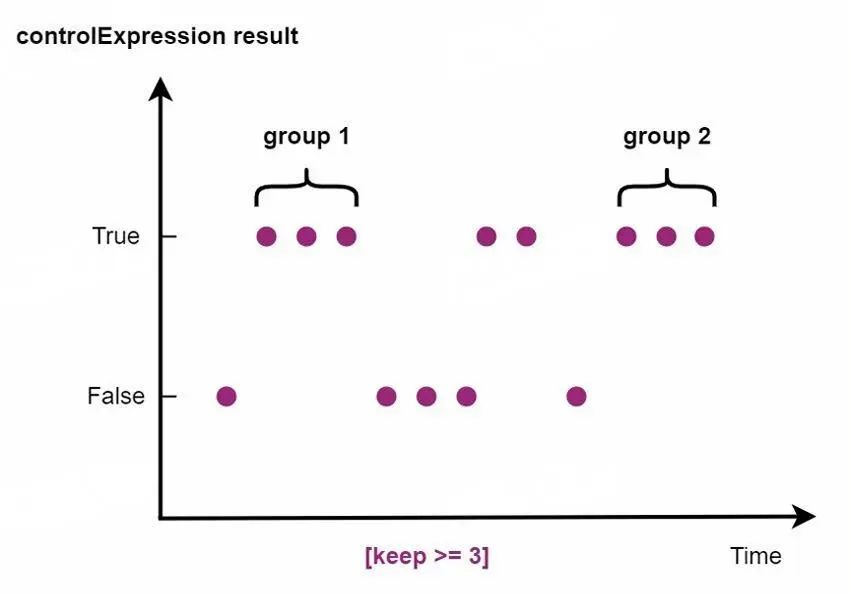
GROUP BY CONDITION(predictExpression[keep >/>=/=/<=/<]threshold[,ignoreNull=true/false])predictExpression:返回值为 boolean 数据类型的表达式,用于数据行的筛选
keep:行数满足 keep 的表达式的数据行会被加入到时间段中
ignoreNull:predictExpression 为 null 时数据行的处理方式,为 true 跳过该行,否则创建新的时间段
06 总结
本文为大家详细介绍了当前 IoTDB 中具备时序特色语义的分段方式,不同于关系型数据库的传统关系代数(针对无序集合的算子),上述分段方式均利用了时序数据天然有序的语义,大家可以通过这些便捷的语法实现自身业务的查询需求。除了这些分段方式之外,IoTDB 本身提供了一个通用的分段框架,欢迎感兴趣的朋友参与 IoTDB 社区,贡献多样的分段实现。
规上企业应用实例
能源电力:中核武汉|国网信通产业集团|华润电力|大唐先一|上海电气国轩|清安储能|太极股份|绍兴安瑞思
智慧工厂与物联:PCB 龙头企业|博世力士乐|德国宝马|京东|昆仑数据|怡养科技





