
有道无术,术尚可求,有术无道,止于术。
本系列Redis 版本 7.2.5
源码地址:https://gitee.com/pearl-organization/study-redis-demo
文章目录
1. 概述
当 Redis 集群的某些节点出现故障时,可以自动进行故障转移,地将从节点提升为主节点,保证服务的连续性和数据的可用性。
也可以手动进行故障转移,会在集群命令篇进行讲解
2. 案例演示
当前环境中,有一个三主三从的 Redis 集群(一台机器部署),主从节点的对应关系如下:
| 主节点 | 从节点 |
|---|---|
| 192.168.56.101:6379 | 192.168.56.101:6382 |
| 192.168.56.101:6380 | 192.168.56.101:6383 |
| 192.168.56.101:6381 | 192.168.56.101:6390 |
在 192.168.56.101:6379 节点上,使用 cluster nodes 命令可以看到,当前是一个主节点:
主节点(192.168.56.101:6379)>cluster nodes 724c7b874dc0c37a462cd5ab59325203344f8008 192.168.56.101:6379@16379 myself,master - 0 1720733735000 1 connected 0-5460 直接使用 kill 命令关闭 192.168.56.101:6379 节点:
[root@localhost bin]# ps -ef | grep redis root 2586 1 1 7月11 ? 00:07:00 ./redis-server *:6379 [cluster] root 7921 7683 0 06:01 pts/2 00:00:00 grep --color=auto redis [root@localhost bin]# kill -9 2586 立即查看节点信息,可以看到 192.168.56.101:6379 节点被标记为失败状态,之前对应的从节点 192.168.56.101:6382 自动升级为主节点:

当 192.168.56.101:6379 节点再次上线后,可以看到变成了从节点:

3. 工作原理
集群中所有节点,都会包含一下两个 Epoch 信息,并在心跳数据包中进行传播,类似于 Raft 中的 term ,用于解决节点信息、配置的冲突问题。
这里简要概括下,具体在官方文档有详细说明:
Current Epoch:当多个节点提供相互冲突的信息时,用于够判断出哪个状态是最新的,值越高越新Config Epoch:翻译为配置时期、配置版本,它主要用于解决节点间配置冲突和确保配置的一致性,值越高越新
3.1 故障检测
Redis Cluster 会通过心跳检测迅速感知到节点故障,并且在节点故障时自动进行恢复,以确保数据在集群中的可用性。当心跳检测到节点不能被大多数节点访问时,会通过提升从节点为主节点来自动修复,当从节点无法升级时,集群将进入错误状态,停止接收客户端的查询操作。
每个集群节点内部都维护一个与其他已知节点相关的标记映射表,用于进行故障检测和状态管理。
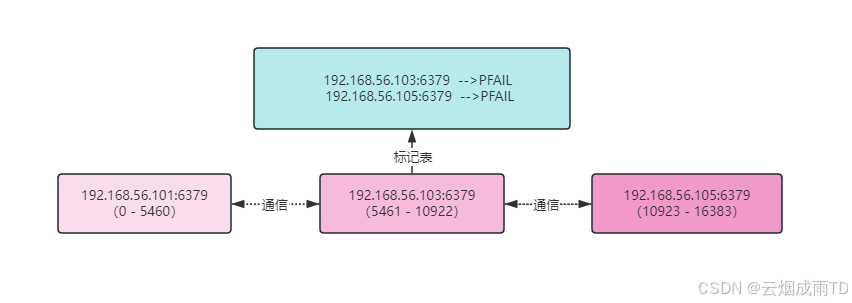
在故障检测中,使用了两个标记:
PFAIL(Possibly FAILed):可能的故障,是一种未确认的故障类型,类似于哨兵中的主观下线FAIL:真正的故障,由集群中大多数主节点确认,类似于哨兵中的客观下线
当一个节点在超过 NODE_TIMEOUT (默认为 15 秒)时间后仍然无法访问时,该节点会将另一个节点标记为 PFAIL。 检测到其他节点为 PFAIL 状态的信息首先会保存在本地,然后通过 Gossip 发送到其他所有节点,最终,每个节点,都会收到某个节点的 PFAIL 标记。
PFAIL 标记并不足以触发从节点的提升,需要升级为 FAIL 状态。例如, B 宕机后,整个状态升级过程如下:
- 当
A向B节点发送Ping后, 在15秒后还没有返回响应,则将B标记为PFAIL,并存储在本地信息文件中。 - 其他节点也检测到
B的状态,并在本地标记为PFAIL A节点通过Gossip获取到其他节点关于B节点的PFAIL状态- 在
NODE_TIMEOUT * FAIL_REPORT_VALIDITY_MULT(超时时间 * 有效性因子)时间内,比如有效性因子设置为2,那么在30秒内,大多数主节点都标记了B节点为PFAIL状态,A节点会将B升级为FAIL状态 A向所有节点发送B已经FAIL的信息,其他节点收到消息后,也将B更新为FAIL
FAIL 状态可以在以下情况下被清除:
- 节点已经可达且是从节点,因为从节点不会被故障转移。
- 节点已经可达且是主节点,但是没有分配哈希槽,因为没有槽位的主节点实际上并不参与集群,并正在等待被配置以加入集群。
3.2 排名
当主节点发生故障时,从节点会交换消息建立排名,拥有最新复制偏移量的复制节点排名为 0 ,第二新的排名为 1 ,依此类推,最新的从节点会优先尝试选举。
排名顺序并不是严格执行的(尽力而为),如果排名较高的从节点未能当选,其他从节点将很快尝试选举。
3.3 延迟等待
一旦主节点进入 FAIL 状态,从节点会在尝试选举之前等待一段短暂的时间。确保 FAIL 状态在整个集群中传播,否则某个主节点不知道其他节点的 FAIL 状态,会拒绝投票。
延迟等待时间的计算公式如下:
DELAY = 500 毫秒 + 0到500毫秒之间的随机延迟 + REPLICA_RANK * 1000毫秒 公式各部分说明如下:
- 随机延迟:用于使从节点的选举时间不同步,以免它们同时开始选举。
REPLICA_RANK:从节点在处理来自主节点的复制数据量方面的排名
3.4 投票
从节点的选举和晋升由从节点处理,并通过主节点的投票来支持从节点的升级。
从节点在满足以下条件时才会启动选举:
- 对应的主节点处于
FAIL状态 - 主节点分配了可服务的哈希槽
- 与主节点的复制连接断开的时间不超过一定的时长,以确保升级后从节点数据是相对较新的
从节点通过向集群中的每个主节点广播一个 FAILOVER_AUTH_REQUEST 数据包来请求投票,超时时间为 NODE_TIMEOUT 时间的两倍(最少 2 秒)。
主节点投票后,会通过 FAILOVER_AUTH_ACK 进行回复,并在接下来 NODE_TIMEOUT * 2 的时间内,不能为同一主节点的其他从节点投票。
3.5 上位
当某个从节点收到了大多数主节点的 ACK 回复,说明赢得了选举。如果在两倍 NODE_TIMEOUT 的时间内未达到多数,选举将被中止,然后将在 NODE_TIMEOUT * 4 后再次尝试。
赢得选举后,从节点将获得一个新的唯一递增的 configEpoch ,该值高于任何现有主节点的 configEpoch ,并通过 Ping 广播到集群中的所有节点,告知自己是主节点,并携带自己分配的哈希槽信息。
对于广播不可达的节点,还会通过心跳机制,传播到其他节点,收到消息后,发现 configEpoch 最高,所以也会及时更新本地信息。