
阅读量:0
1 图片爬虫
这里的代码转载自:http://t.csdnimg.cn/T4R4F
# 获取图片数据 import os.path import fake_useragent import requests from lxml import etree # UA伪装 head = {"User-Agent": fake_useragent.UserAgent().random} pic_name = 0 def request_pic(url): # 发送请求 response = requests.get(url, headers=head) # 获取想要的数据 res_text = response.text # 数据解析 tree = etree.HTML(res_text) li_list = tree.xpath("//div[@class='slist']/ul/li") for li in li_list: # 图片的url img_url = "https://pic.netbian.com" + "".join(li.xpath("./a/img/@src")) # 发送请求 img_response = requests.get(img_url, headers=head) # 获取想要的数据 img_content = img_response.content global pic_name with open(f"./picLib/{pic_name}.jpg", "wb") as fp: fp.write(img_content) pic_name += 1 if __name__ == '__main__': # 创建存放照片的文件夹 if not os.path.exists("./picLib"): os.mkdir("./picLib") # 网站的url url = "https://pic.netbian.com/4kdongman/" request_pic(url) for i in range(1,10): next_url = f"https://pic.netbian.com/4kmeinv/index_{i}.html" request_pic(next_url) 结果如图1-1所示:
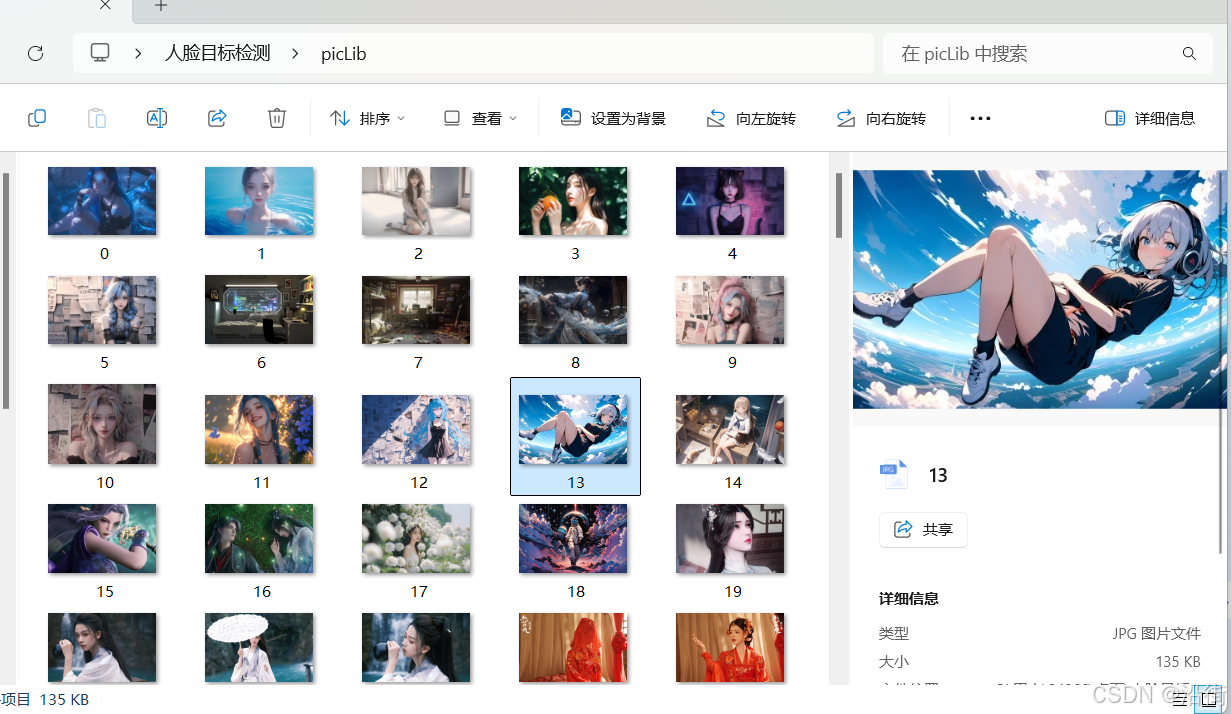
图 1-1
2 基于opencv自带分类器的人脸检测
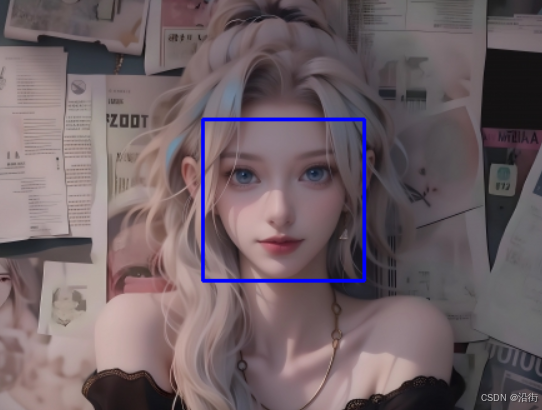
import cv2 import os import matplotlib.pyplot as plt # 定义人脸检测器的路径 face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml') # 设置图片文件夹路径 folder_path = 'picLib' # 设置要显示的图像数量 num_to_display = 5 # 例如,只显示前4张图像 # 创建一个图形和子图 fig, axs = plt.subplots(1, num_to_display, figsize=(15, 5)) # 遍历文件夹中的前几张图片 for i in range(num_to_display): file_name = f'{i}.jpg' image_path = os.path.join(folder_path, file_name) # 读取图片 img = cv2.imread(image_path) if img is None: print(f"Error loading image {file_name}") continue # 转换为灰度图 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 检测人脸 faces = face_cascade.detectMultiScale(gray, 1.3, 5) # 在原图上绘制矩形框 for (x, y, w, h) in faces: cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2) # 注意:OpenCV 图像是BGR,而Matplotlib 期望的是RGB,因此我们需要转换颜色通道 img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 显示图像 axs[i].imshow(img_rgb) axs[i].axis('off') # 关闭坐标轴 # 显示图形 plt.show() 运行结果如图2-1所示:

图 2-1
从这里可以清晰看到有1/3的图像没有成功检测到,后面我试试用Faster R-CNN模型,不过需要标注,数据量也大,这里先试着玩玩呗。
