
阅读量:0
总结StarRocks更新表的全部内容的集合(V3.2版本)
一、基本功能
- 聚合函数replace的聚合表
- 主键被主键表替代
- 采用Merge-On-Read的策略,读取时需要在线Merge多个版本的数据文件,谓词和索引无法下推至底层数据,会严重影响查询性能
创建更新表ddl
CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATETIME NOT NULL COMMENT "create time of an order", shop_id BIGINT NOT NULL COMMENT "id of shop", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, shop_id) PARTITION BY date_trunc('day', create_time) DISTRIBUTED BY HASH(shop_id) PROPERTIES ( "replication_num" = "1" ); INSERT INTO unq_orders VALUES ("2024-07-01 12:00:00", 2001, 3001, 1, 30), ("2024-07-01 13:00:00", 2001, 3002, 1, 40), ("2024-07-02 11:00:00", 2002, 3003, 1, 60), ("2024-07-03 10:00:00", 2002, 3004, 1, 10), ("2024-07-04 17:00:00", 2006, 3005, 1, 70); 注意事项
- UNIQUE KEY是更新表的标识,同时也是排序键
- 必须使用 DISTRIBUTED BY HASH 子句指定分桶键(也就是必须使用hash分桶)
二、分区(分区键必须为key键)
starrocks支持分区+分桶的数据分布,分区可以是单个分区,也可以是多个分区,分区是左闭右开的范围。
分区的方式:
- 表达式分区:自动创建分区,适用于时间范围或者枚举值分区,数据导入自动创建分区(很强大)
- Range分区:对于简单有序的数据分区(连续1天,连续6天,1-3等),动态、批量或者手动创建
- List分区:适用于枚举值分区(比如按照国家,城市分区),手动创建
List分区不支持动态和批量创建
异步物化视图暂不支持基于使用List分区的基表创建
Range分区只支持时间类型/整数类型的字段
List分区支持字符串/时间/整数/布尔值类型字段
各个分区的创建的标识
- range分区:PARTITION BY RANGE(dt) (支持日期/整型)
- list分区:PARTITION BY LIST (city) (支持多种类型)
- 时间表达式分区:PARTITION BY date_trunc/time_slice(‘day’, create_time) (支持时间)(特殊的Range分区功能)
- 列表达式分区:PARTITION BY (dt, merchant_id) (支持多种类型)(特殊的List分区功能)
2.1 手动创建Range分区(仅支持分区键的数据类型为日期和整数类型)
-- 日期 CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATE NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) PARTITION BY RANGE(create_time)( PARTITION p1 VALUES LESS THAN ("2020-01-31"), PARTITION p2 VALUES LESS THAN ("2020-02-29"), PARTITION p3 VALUES LESS THAN ("2020-03-31") ) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "3" ); --整数 CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATE NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) PARTITION BY RANGE(order_id)( PARTITION p1 VALUES LESS THAN ("4"), PARTITION p2 VALUES LESS THAN ("9"), PARTITION p3 VALUES LESS THAN ("20") ) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "1" ); --联合分区 CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATE NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) PARTITION BY RANGE(create_time, order_id)( PARTITION p1 VALUES LESS THAN ("2020-01-31", "1"), PARTITION p2 VALUES LESS THAN ("2020-02-29", "2"), PARTITION p3 VALUES LESS THAN ("2020-03-31", "3") ) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "1" ); 2.2 批量创建Range分区(仅支持分区键的数据类型为日期和整数类型)
方法:START、END 指定批量分区的开始和结束,EVERY子句指定分区增量值,时间指定单位HOUR(3.0V)、DAY、WEEK、MONTH、YEAR
--日期 CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATE NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) PARTITION BY RANGE(create_time)( START ("2021-01-01") END ("2021-01-04") EVERY (INTERVAL 1 DAY) ) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "1" ); --整数 CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATE NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) PARTITION BY RANGE(order_id)( START ("1") END ("5") EVERY (1) ) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "1" ); 2.3 动态创建Range分区(仅支持分区键的数据类型为日期类型)
动态分区通过PROPERTIES进行配置
表达式分区与动态分区创建分区的区别:表达式分区会根据导入数据自动创建分区,而动态分区是根据动态分区属性,定期提前创建一些分区,如果导入数据不属于任何存在的分区,则会报错。
动态分区:⾃动提前创建新的分区,删除过期分区(可以设置TTL)
--日期 CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATE NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) PARTITION BY RANGE(create_time)( PARTITION p20200321 VALUES LESS THAN ("2020-03-22"), PARTITION p20200322 VALUES LESS THAN ("2020-03-23") ) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "1", "dynamic_partition.enable" = "true", "dynamic_partition.time_unit" = "DAY", "dynamic_partition.start" = "-3", "dynamic_partition.end" = "3", "dynamic_partition.prefix" = "p", "dynamic_partition.history_partition_num" = "0" ); 表示依照当天时间为基准,删除3天前的分区,同时创建3天后的分区
dynamic_partition_check_interval_seconds:FE 配置项,动态分区检查的时间周期,默认为 600, 周期检查是否删除分区与创建分区
其他配置项见官网(动态分区)
动态分区只能创建时间类型的分区
2.4 手动创建List分区(V3.1支持)
分区键支持字符串/时间/整数/布尔值类型字段
分区键不可以为null
--列多个值放在一分区 CREATE TABLE test.unq_orders1000 ( id bigint, city varchar(20) not null, user_id bigint, recharge_money decimal(32,2), dt varchar(20) not null ) UNIQUE KEY(id,city) PARTITION BY LIST (city) ( PARTITION pCalifornia VALUES IN ("Los Angeles","San Francisco","San Diego"), -- 这些城市同属一个州 PARTITION pTexas VALUES IN ("Houston","Dallas","Austin") ) DISTRIBUTED BY HASH(`id`); --联合分区(列多个值放在一分区) CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATE NOT NULL COMMENT "create time of an order", city varchar(20) NOT NULL COMMENT "", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, city) PARTITION BY LIST (create_time, city) ( PARTITION p202204_California VALUES IN ( ("2022-04-01", "Los Angeles"), ("2022-04-01", "San Francisco"), ("2022-04-02", "Los Angeles"), ("2022-04-02", "San Francisco") ), PARTITION p202204_Texas VALUES IN ( ("2022-04-01", "Houston"), ("2022-04-01", "Dallas"), ("2022-04-02", "Houston"), ("2022-04-02", "Dallas") ) ) DISTRIBUTED BY HASH(city) PROPERTIES ( "replication_num" = "1" ); 2.5 表达式分区
- 根据表达式的值可以自动创建对应分区,不需要提前创建分区
- 基本适用于多数场景(覆盖大部分range分区与list分区功能,但是部分场景可能需要独立使用Range或者List分区)
- 自动创建分区数量上限默认为 4096
2.5.1 时间函数表达式分区
- 分区列只能有一个,而且数据类型必须是时间类型
- 分区粒度:
hour、day、month或year - 仅支持
date_trunc和time_slice函数,应用到分区列上 - 分区列值可以为
null
-- 天级别分区 CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATETIME NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) PARTITION BY date_trunc('day', create_time) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "1" ); --时间分片,7天内的放在一个分区 CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATETIME NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) PARTITION BY time_slice(create_time, INTERVAL 7 day) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "1" ); 2.5.2 列表达式分区(V3.1)
- 分区列可以多个,数据类型包括字符串、日期、整数和布尔值
- 分区值不支持
null - 每个列值都会创建一个分区
CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATE NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) PARTITION BY (create_time, order_id) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "1" ); 2.6 建表后创建分区
--Range分区批量日期 ALTER TABLE unq_orders ADD PARTITIONS START ("2021-01-10") END ("2021-01-20") EVERY (INTERVAL 1 DAY); --Range分区批量整数 ALTER TABLE unq_orders ADD PARTITIONS START ("100") END ("200") EVERY (50); --List分区不支持批量创建,只能手动单个分区 ALTER TABLE unq_orders ADD PARTITION p202205_California VALUES IN ( ("2022-05-03", "Los Angeles"), ("2022-05-03", "San Francisco"), ("2022-05-04", "Los Angeles"), ("2022-05-05", "San Francisco") ); --Range分区创建单个日期分区 ALTER TABLE unq_orders ADD PARTITION p20200130 VALUES LESS THAN ("2021-01-22") --Range分区创建单个整数分区 ALTER TABLE unq_orders ADD PARTITION p300 VALUES LESS THAN ('300'); 2.7 管理分区
2.7.1 删除分区(默认会保留一天,误删可以使用恢复分区恢复)
测试发现LIST分区无法删除 Range分区可以删除 ALTER TABLE unq_orders DROP PARTITION p1; 2.7.2 恢复分区
RECOVER PARTITION p1 FROM unq_orders; 2.7.3 查看分区
SHOW PARTITIONS FROM unq_orders; 三、分桶
3.1 哈希分桶
- 分区内部的数据按照分桶键存放数据
- 支持多个分桶键,更新表分桶键必须为key键
- 分桶键值尽量多基数,避免数据倾斜
- 分桶键支持的数据类型:整型、字符串、日期时间
- 建表后可以修改分桶键(V3.2)
CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATE NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) PARTITION BY RANGE(create_time)( PARTITION p1 VALUES LESS THAN ("2020-01-31"), PARTITION p2 VALUES LESS THAN ("2020-02-29"), PARTITION p3 VALUES LESS THAN ("2020-03-31") ) DISTRIBUTED BY HASH(create_time, order_id) PROPERTIES ( "replication_num" = "1" ); 3.2.1 哈希分桶数
- 每个分桶的数据规模最好不要超过10G
- 单个分区数据超过100G,建议手动设置分区,其他建议系统自动分桶数
--显示指定分桶数 --一个分区的原始数据量为 300 GB,则按照每 10 GB 原始数据一个 Tablet,则分区中分桶数量可以设置为 30 CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATE NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) PARTITION BY RANGE(create_time)( PARTITION p1 VALUES LESS THAN ("2020-01-31"), PARTITION p2 VALUES LESS THAN ("2020-02-29"), PARTITION p3 VALUES LESS THAN ("2020-03-31") ) DISTRIBUTED BY HASH(create_time, order_id) BUCKETS 30 PROPERTIES ( "replication_num" = "1" ); 建表后设置分桶数
-- 手动指定所有分区中分桶数量 ALTER TABLE unq_orders DISTRIBUTED BY HASH(create_time, order_id) BUCKETS 20; -- 手动指定部分分区中分桶数量 ALTER TABLE unq_orders partitions p20210102 DISTRIBUTED BY HASH(create_time, order_id) BUCKETS 30; 查看分桶数
SHOW PARTITIONS from unq_orders 三、索引
starrocks内部自动创建的索引(内部索引):前缀索引、Ordinal索引、ZoneMap 索引
需要用户手动创建的索引:Bitmap 索引和 Bloom filter 索引
3.1 Ordinal索引(列级索引)
starrocks采用列式存储,每一列数据以Date Page(64*1024 个字节,64KB)为单位分块存储,每个Date Page的起始行号作为Ordinal索引项。所以其他所有的索引都要通过Ordinal索引找到数据的物理地址。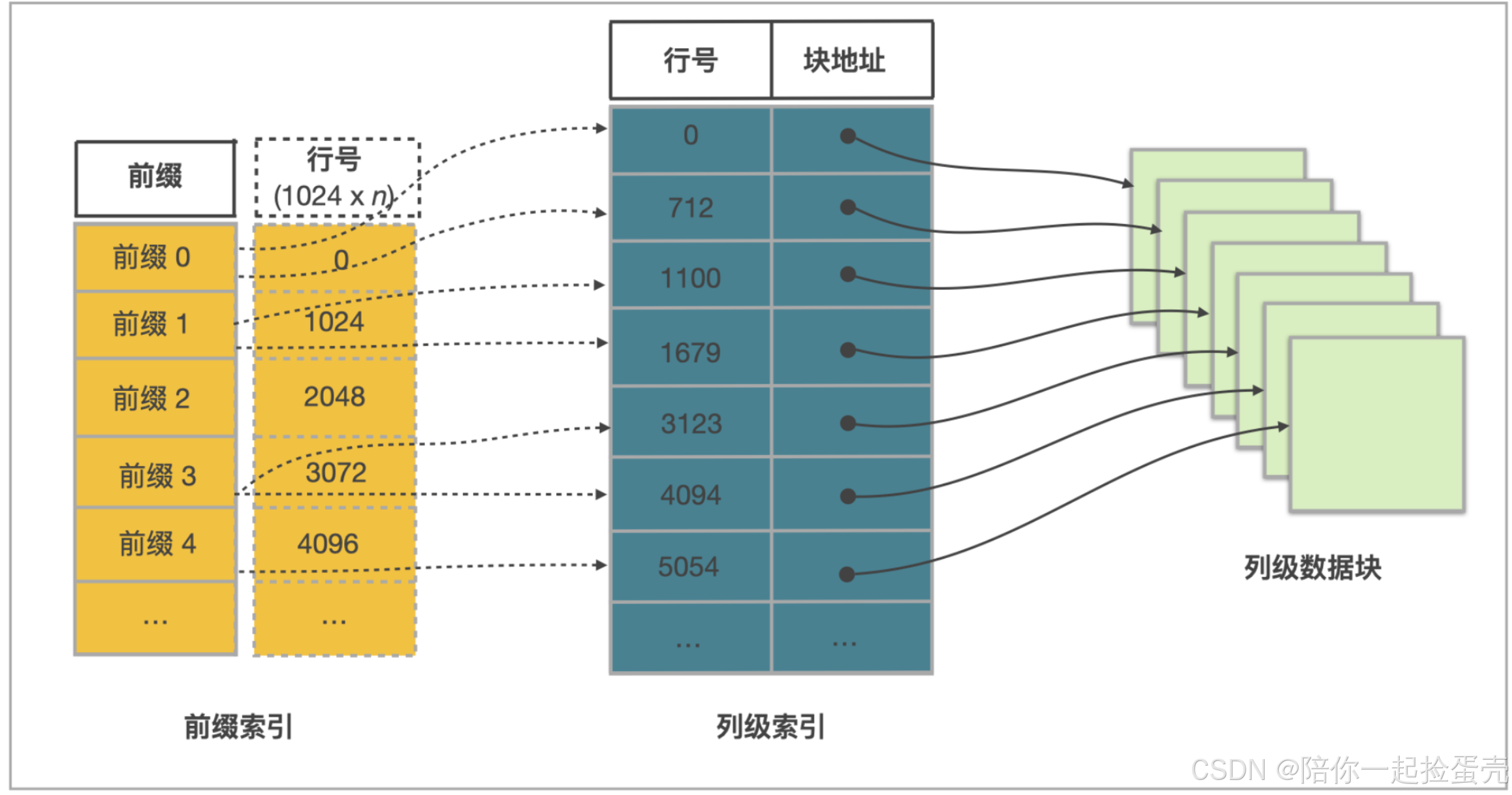
3.2 ZoneMap索引
ZoneMap索引存储了每块数据统计信息,统计信息包括 Min 最大值、Max 最小值、HasNull 空值、HasNotNull 不全为空的信息。
在查询时,StarRocks 可以根据这些统计信息,快速判断这些数据块是否可以过滤掉,从而减少扫描数据量,提升查询速度。
ZoneMap索引有两种:一种是存每个 Segment 的统计信息,另一种是存每个 Data Page 的统计信息
3.3 前缀索引
按照UNIQUE KEY顺序建立前缀索引,也就是排序键
前缀索引每1024行数据创建一个索引项,所以前缀索引一般都可以全部加载到内存,加速查询速度。
一个表只能有一个前缀索引
更新表在建表后不能修改排序键
注意事项:
- 排序列不宜过多,一般为3个,建议不超过4个
- 前缀索引项的最大长度为36字节,超过部分会被截断
- 前缀字段中CHAR、VARCHAR、STRING类型的列只能出现一次,并且处在末尾位置,而且超过部分会被截断
3.4 Bitmap索引
原理:bitmap即为一个bit数组,一个bit的取值有两种:0或1。每一个bit对应数据表中的一行,并根据该行的取值情况来决定bit的取值是0还是1。
适用场景:
- 于较高基数列的查询
- 多个低基数列的组合查询
劣势:
- 查询时加载Bitmap索引的开销
- 写入数据可能会影响损耗性能
查询有Bitmap索引的自适应选择机制
原因:由于查询bitmap可能有性能损耗,所以建立bitmap索引是否使用,由starrocks自动控制(也可以强制使用)
原则:查询条件涉及的列值数量/基数 是否小于 1/1000
SELECT * FROM employees WHERE gender = 'male' 由于 gender 基数 只用两个,查询只查询其中一个, 1/2 > 1/1000 所以不使用对应的bitmap索引 SELECT * FROM employees WHERE gender = 'male' AND city IN ('北京', '上海'); 假设city列的基数为10000,查询条件涉及其中2个值,结合gender,则(1*2)/(2*10000) < 1/1000 所以使用对应的bitmap索引 3.4.1 创建bitmap索引
- 更新表只有Key列支持创建Bitmap索引
- 每个索引只能一个列
- 常见的数据类型都支持
CREATE TABLE IF NOT EXISTS unq_orders ( create_time DATETIME NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order", INDEX i_order_id (order_id) USING BITMAP ) UNIQUE KEY(create_time, order_id) PARTITION BY date_trunc('day', create_time) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "1" ); 3.4.2 管理bitmap索引
--创建索引 CREATE INDEX i_order_id ON unq_orders(order_id) USING BITMAP; --查看创建进度 SHOW ALTER TABLE COLUMN FROM db; --查看索引 SHOW INDEX FROM unq_orders; --删除索引 DROP INDEX i_user_id ON unq_orders; 3.5 Bloom filter索引
原理:快速判断表的数据文件中是否可能包含要查询的数据,如果不包含就跳过。
3.5.1 创建Bloom filter索引
- 更新表只有Key可以创建Bloom filter索引
- 每个索引只能一个列,可以同时创建多个索引,用
,分隔 - 常见的数据类型都支持
CREATE TABLE IF NOT EXISTS test.unq_orders ( create_time DATETIME NOT NULL COMMENT "create time of an order", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", total_price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, order_id) PARTITION BY date_trunc('day', create_time) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "1", "bloom_filter_columns" = "order_id" ); 3.5.2 管理Bloom filter索引
--创建索引 ALTER TABLE aggregate_tbl SET ("bloom_filter_columns" = "order_id,create_time"); --查看索引 SHOW CREATE TABLE aggregate_tbl; --删除索引 ALTER TABLE aggregate_tbl SET ("bloom_filter_columns" = ""); 四、同步物化视图(Rollup)
官网说明可以使用同步物化视图视图,但是操作发现不可以创建同步物化视图,
CREATE MATERIALIZED VIEW shop_id_amount AS SELECT shop_id, SUM(price) FROM test.unq_orders GROUP BY shop_id; --由于更新表,非key都是replace函数,索引不可以使用sum等其他聚合函数 The aggregation type of column[mv_sum_price] must be same as the aggregate type of base column in aggregate table 五、异步物化视图
异步物化视图优势:
- 支持外部表,多表关联查询
- 支持部分分区刷新,定时刷新与手动刷新 (异步机制)
- 支持查询改写:直接查询基表,可以自动从对应物化视图获取数据
- 支持直接查询异步物化视图
- 异步物化视图可以与其基表设置不同的分区和分桶策略,并且可以为分区指定TTL
- 异步物化视图支持分区上卷
- 支持单批次最大刷新分区数与只刷新最近N个分区
异步物化视图局限性:
- 基表发生变化,物化视图可能还没有发生变化
- 只能对有分区的基表创建异步物化视图
- 不支持List分区的基表创建物化视图,同时不能创建List分区的异步物化视图
5.1 创建异步物化视图
CREATE MATERIALIZED VIEW merchant_mv_6 PARTITION BY create_date DISTRIBUTED BY HASH(shop_id) REFRESH IMMEDIATE ASYNC START('2024-07-01 00:00:00') EVERY (interval 1 minute) PROPERTIES( "partition_ttl_number" = "5", "auto_refresh_partitions_limit" = "2", "partition_refresh_number" = "2" ) AS SELECT date_trunc('day', create_time) as create_date, shop_id, sum(price) as total_price FROM unq_orders GROUP BY create_time, shop_id; 基表的查询尽量不要使用order by 可能导致查询改写失败
5.2 设置分区
由于starrocks的range分区与表达式分区,基本都是针对时间类型的字段,而且基本都是单字段分区,所以异步物化视图的分区基本只能是时间类型的字段单分区。
物化视图分区键必须是基表的分区键
物化视图的分区字段可以是基表的String类型的时间格式字段,创建分区的时候转换成时间类型即可(str2date)
PARTITION BY str2date(datekey, '%Y-%m-%d') 增量更新:如果物化视图分区内的基表数据没有发生变化,则对应的物化视图分区数据不会刷新
partition_ttl_number: 需要保留的最近的物化视图分区数量,也就是ttl,比如上例子中"partition_ttl_number" = "5",表示保留最近5个分区,其他分区会定时删除。partition_refresh_number:表示单批次最大刷新分区数,当多个分区数据都发生变化,则会分批次刷新数据,每批次都刷新对应的分区数,避免资源过多消耗。auto_refresh_partitions_limit: 表示需要刷新的最近的物化视图分区数量,比如上例子中"auto_refresh_partitions_limit" = "2",表示只刷新最近2个分区,其他的分区数据当发生变化也不再刷新,但是在数据查询改写中,对于不刷新的分区,查询会直接查询基表的数据(有数据变化)
5.3 设置刷新模式
5.3.1 自动刷新
REFRESH ASYNC : 每当基表数据发生变化时,物化视图会自动刷新
5.3.2 定时刷新
ASYNC [START (<start_time>)] EVERY(INTERVAL <interval>)
day/hour/minute/second
--从当前时间开始 REFRESH ASYNC EVERY (interval 1 minute) --指定开始时间 REFRESH ASYNC START('2024-07-01 00:00:00') EVERY (interval 1 minute) 5.3.3 设置成手动刷新
REFRESH MANUAL: 设置成手动刷新
-- 异步调用刷新任务 REFRESH MATERIALIZED VIEW order_mv; -- 同步调用刷新任务 REFRESH MATERIALIZED VIEW order_mv WITH SYNC MODE; 5.3.4 创建异步物化视图是否立即执行刷新
IMMEDIATE:异步物化视图创建成功后立即刷新DEFERRED:异步物化视图创建成功后不进行刷新,您可以通过手动调用或创建定时任务触发刷新
5.3.4 查询异步物化视图
可以直接查询异步物化视图,同时也支持查询基表的查询改写
5.4 管理异步物化视图
5.4.1 修改异步物化视图
-- 启用被禁用的异步物化视图 ALTER MATERIALIZED VIEW order_mv ACTIVE; -- 重命名 ALTER MATERIALIZED VIEW order_mv RENAME order_total; -- 修改刷新机制 ALTER MATERIALIZED VIEW order_mv REFRESH ASYNC EVERY(INTERVAL 2 DAY); 5.4.2 查看异步物化视图
-- 查看所有的物化视图 SHOW MATERIALIZED VIEWS; -- 按条件查询 SHOW MATERIALIZED VIEWS WHERE NAME LIKE "order%"; -- 查看物化视图的创建语句 SHOW CREATE MATERIALIZED VIEW merchant_mv_3; 5.4.3 查询物化视图执行状态与异步刷新情况
-- 找到 物化视图的任务 task_name select * from information_schema.tasks order by CREATE_TIME desc -- 通过task_name 获取 物化视图执行与刷新情况 select * from information_schema.task_runs where task_name='mv-11576' order by CREATE_TIME 
5.4.4 删除物化视图
DROP MATERIALIZED VIEW order_mv; 六、数据去重
starrocks是mpp架构的引擎,所以在数据去重方面,就需要把各个BE节点上的数据进行shuffle,所以如果大规模的数据会导致计算资源紧张,所以对于数据去重,starrcoks提供两种特殊的额外的方式,但是都是有局限性的。
6.1 常规去重
对于数据集基数在百万、千万量级,并拥有几十台机器,那么您可以直接使用count distinct方式
select date_trunc('day', create_time) as create_date, count(distinct shop_id) as cnt from unq_orders group by create_date 6.2 Bitmap精确去重
更新表不支持:UNIQUE_KEYS table should not specify aggregate type for non-key column[order_id].
6.3 HyperLogLog近似去重
更新表不支持
七、Colocate Join
功能:Colocate Join 功能是分布式系统实现 Join 数据分布的策略之一,能够减少数据多节点分布时 Join 操作引起的数据移动和网络传输,从而提高查询性能。
原理:同一CG内,所有表的数据分布在相同一组 BE 节点上。当 Join 列为分桶键时,计算节点只需做本地 Join,从而减少数据在节点间的传输耗时,提高查询性能(把相同数据放在同一个BE上,数据本地join), 所以当数据迁移都是一起均衡操作,在数据迁移过程中,查询退回普通的join(shfflue)
条件:
- 表具有相同数据类型的分桶键(名字可以不一样),而且顺序要保持一致,桶数一致
- 表具有相同的副本数
- 查询只支持等值查询(其他比较都失效,退化成普通的join)
使用方式:在表PROPERTIES中指定属性"colocate_with" = “group_name”
如果指定的 CG 不存在,StarRocks 会自动创建一个只包含当前表的 CG,并指定当前表为该 CG 的 Parent Table。如果 CG 已存在,StarRocks 会检查当前表是否满足条件。如果满足,StarRocks 会创建该表,并将该表加入 Group。同时,StarRocks 会根据已存在的 Group 中的数据分布规则为当前表创建分片和副本。
7.1 创建Colocate Join表
CREATE TABLE pri_orders_colocate ( order_id bigint NOT NULL, create_time datetime NOT NULL, merchant_id int NOT NULL, user_id int NOT NULL, good_name string NOT NULL, cnt int NOT NULL, revenue int NOT NULL, state tinyint NOT NULL ) PRIMARY KEY (order_id, create_time, merchant_id) PARTITION BY date_trunc('day', create_time) DISTRIBUTED BY HASH (merchant_id) BUCKETS 8 ORDER BY (create_time, merchant_id) PROPERTIES ( "colocate_with" = "order_merchant_group", "enable_persistent_index" = "true" ); CREATE TABLE IF NOT EXISTS test.unq_orders_colocate ( create_time DATETIME NOT NULL COMMENT "create time of an order", shop_id INT NOT NULL COMMENT "id of shop", order_id BIGINT NOT NULL COMMENT "id of an order", order_state INT COMMENT "state of an order", price BIGINT COMMENT "price of an order" ) UNIQUE KEY(create_time, shop_id) PARTITION BY date_trunc('day', create_time) DISTRIBUTED BY HASH(shop_id) BUCKETS 8 PROPERTIES ( "colocate_with" = "order_merchant_group", "replication_num" = "1" ); ); 7.2 修改表Colocate Join组
ALTER TABLE tbl SET ("colocate_with" = "group_name"); 7.2 删除Colocate Join
-- 删除表的Colocate Join属性 ALTER TABLE tbl SET ("colocate_with" = ""); - 删除特定的Colocate Join组
当所有的设置colocate_with的表都删除,并且真正后台清理掉后(默认保留一天),colocate_with设置的组才会真实的删掉
7.3 是否真实使用Colocate Join
-- 查看 colocation_group SHOW PROC '/colocation_group'; -- 查看特定group bucket分布的BE SHOW PROC '/colocation_group/11912.11916'; 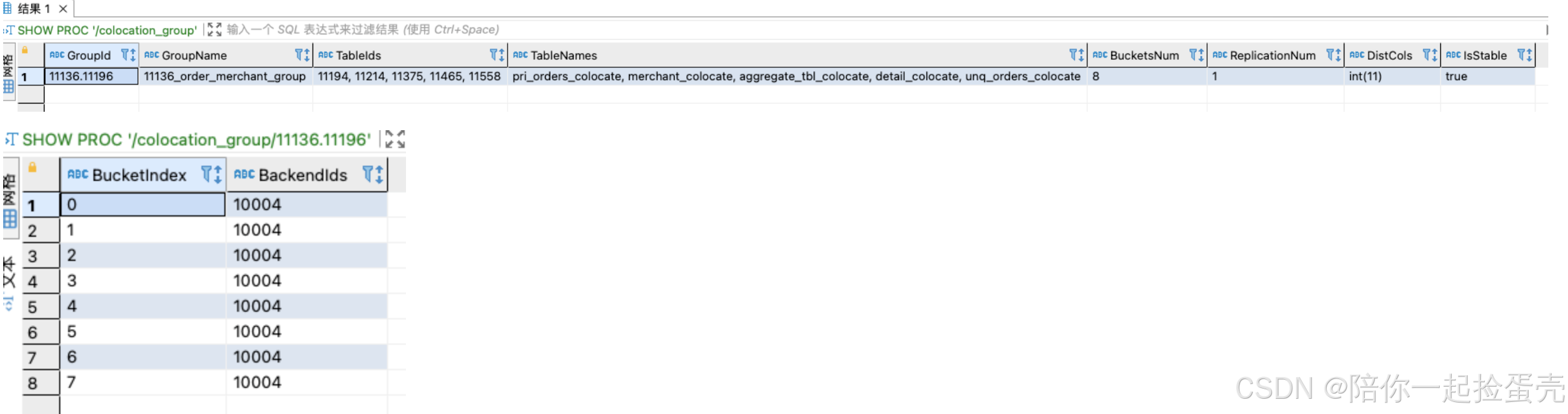
使用Colocate Join和使用普通的join是一样的,通过expain命令查看是否真实使用Colocate Join,如果Colocate Join失效或者不稳定,则会退化成普通的join查询。
explain select * from test.pri_orders_colocate as pri INNER JOIN test.unq_orders_colocate as unq on (pri.merchant_id = unq.shop_id) and pri.create_time > "2024-07-01 12:00:00" 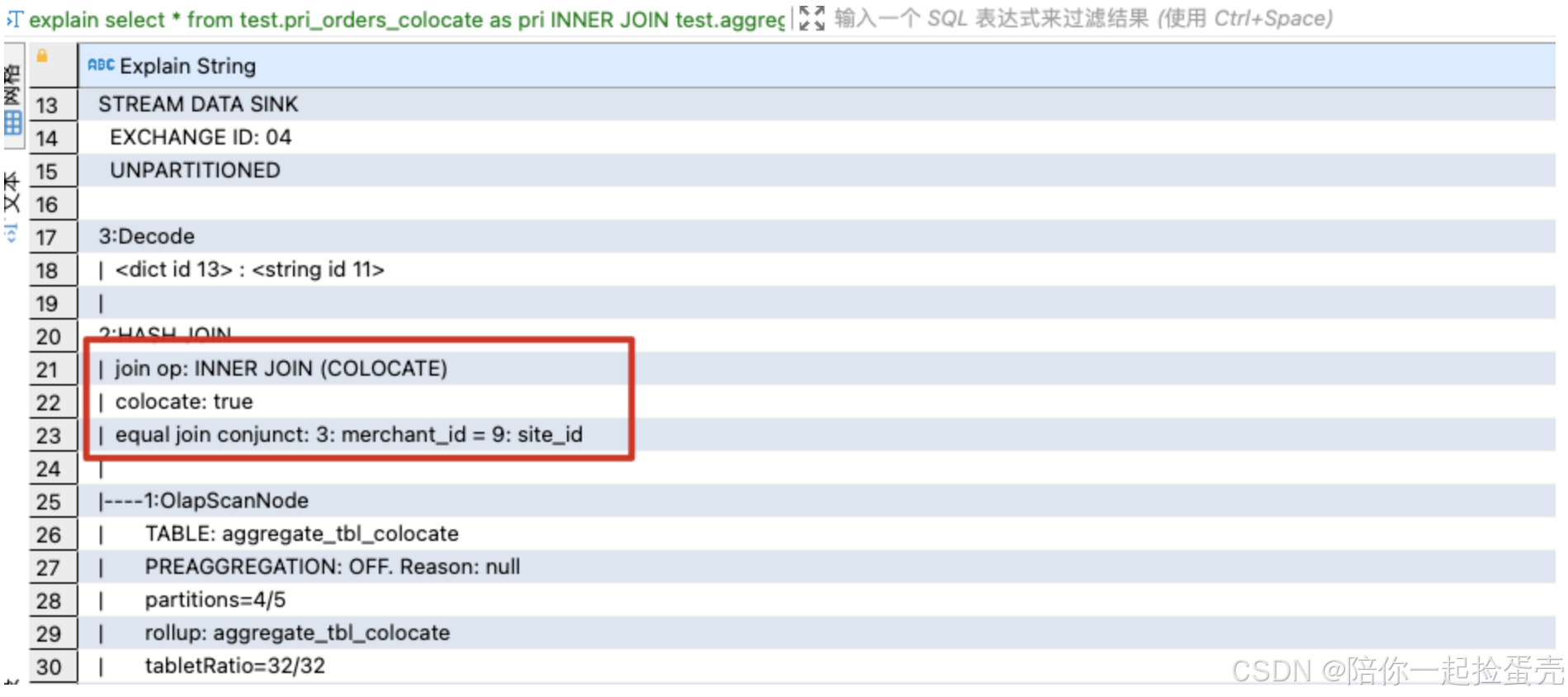
八、Query Cache
8.1、Query Cache使用场景
query cache默认是关闭的。
- 查询多为宽表模型下的单表聚合查询或星型模型下简单多表 JOIN 的聚合查询。
- 聚合查询以非 GROUP BY 聚合和低基数 GROUP BY 聚合为主。
- 查询的数据以按时间分区追加的形式导入,并且在不同时间分区上的访问表现出冷热性。
8.2、Query Cache命中高效性
会对query判断是否语义等价
- 聚合语句的第一次聚合是语义等价就判定语义等价
q1: SELECT sum(murmur_hash3_32(hour)), 0)) + sumvi AS fingerprint FROM ( SELECT date_trunc('hour', ts) AS hour, sum(v1) AS sumvi FROM t0 WHERE ts BETWEEN '2022-01-03 00:00:00' AND '2022-01-03 23:59:59' GROUP BY date_trunc('hour', ts) ) AS t; q2: SELECT date_trunc('hour', ts) AS hour, sum(v1) AS sumvi FROM t0 WHERE ts BETWEEN '2022-01-03 00:00:00' AND '2022-01-03 23:59:59' GROUP BY date_trunc('hour', ts) - 是否含有 ORDER BY 子句和 LIMIT 子句,不影响两个查询的语义等价
- where 条件的先后顺序, group by 先后顺序不影响语义等价
九、CBO 统计信息
CBO优化器(cost-based Optimizer)是查询优化的关键,CBO会统计starrcoks中表的信息,当一条Sql查询到达Starrocks后,会基于统计信息,选择一个最优的执行路径作为最终的物理查询计划。
9.1、CBO统计信息的类别(列的粒度)
CBO统计表的信息主要分为两种:
第一种是统计表的列的基础统计信息,包括:
- row_count: 表的总行数
- data_size: 列的数据大小
- ndv: 列基数,即 distinct value 的个数
- null_count: 列中 NULL 值的个数
- min: 列的最小值
- max: 列的最大值
上面的信息存储在_statistics_.column_statistics表中,是按照表的分区内各个列进行统计的。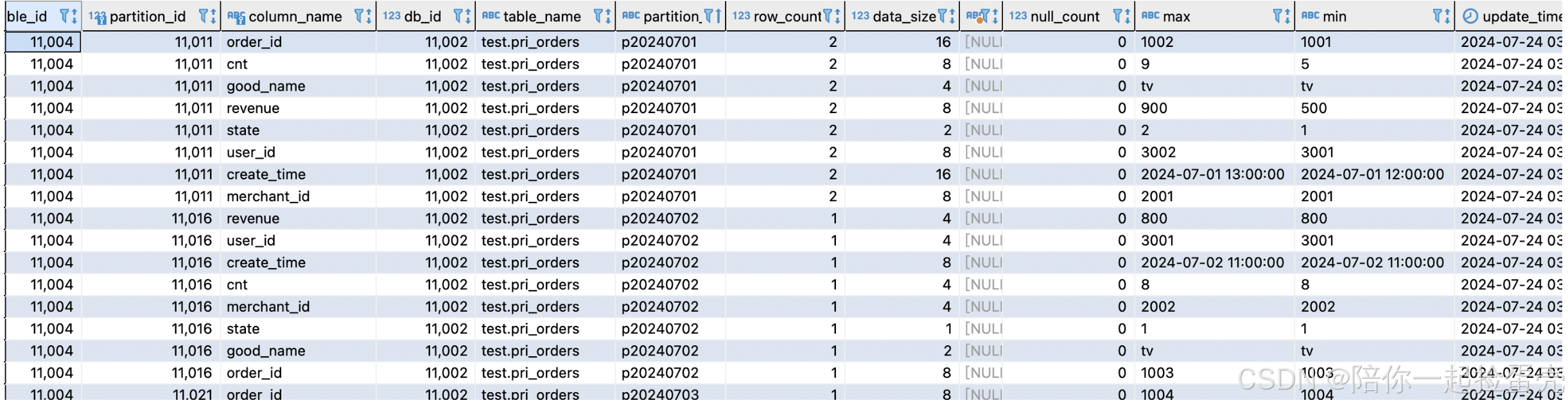
第二种是把表的列信息统计到直方图中(用直方图表达数据的情况)
直方图能方便的展示数据列的倾斜分布不均的情况。支持列的数据类型是数值类型、DATE、DATETIME 或字符串类型。
直方图目前只支持手动采样采集,采集的数据存储zai _statistics_.histogram_statistics表中,其中mcv表示列的值出现的次数
9.2、自动(全量/抽样)采集基础信息
自动全量采集基础信息可能消耗大量的系统资源,默认5分钟一次,默认开启自动全量采集基础信息。可以配置参数statistic_auto_analyze_start_time, statistic_auto_analyze_end_time设置每天的开始结束时间。
在自动全量采集基础信息中,如果表过大或者设置的健康度达到阈值,将把自动全量采集基础信息变更为自动抽样采集基础信息。具体信息见官网。
9.3、自定义自动(全量/抽样)采集基础信息
创建自动意自动采集任务,需要先关闭自动全量采集基础信息enable_collect_full_statistic=false,采集相关参数见官网。
语法: CREATE ANALYZE [FULL|SAMPLE] TABLE tbl_name (col_name [,col_name]) [PROPERTIES (property [,property])] 例子: -- 定期全量采集所有数据库的统计信息。 CREATE ANALYZE ALL; -- 定期全量采集指定数据库下所有表的统计信息。 CREATE ANALYZE FULL DATABASE db_name; -- 定期全量采集指定表、列的统计信息。 CREATE ANALYZE TABLE tbl_name(c1, c2, c3); -- 定期抽样采集指定数据库下所有表的统计信息。 CREATE ANALYZE SAMPLE DATABASE db_name; -- 自动采集所有数据库的统计信息,不收集`db_name.tbl_name`表。 CREATE ANALYZE SAMPLE DATABASE db_name PROPERTIES ( "statistic_exclude_pattern" = "db_name.tbl_name" ); 9.4、手动(全量/抽样)采集基础信息
手动任务创建后仅会执行一次,无需手动删除。
语法: ANALYZE [FULL|SAMPLE] TABLE tbl_name (col_name [,col_name]) [WITH SYNC | ASYNC MODE] [PROPERTIES (property [,property])] 例子: -- 手动全量采集指定表的统计信息,使用默认配置。 ANALYZE FULL TABLE tbl_name; -- 手动全量采集指定表指定列的统计信息,使用默认配置。 ANALYZE TABLE tbl_name(c1, c2, c3); -- 手动抽样采集指定表的统计信息,使用默认配置。 ANALYZE SAMPLE TABLE tbl_name; -- 手动抽样采集指定表指定列的统计信息,设置抽样行数。 ANALYZE SAMPLE TABLE tbl_name (v1, v2, v3) PROPERTIES( "statistic_sample_collect_rows" = "1000000" ); 9.5、手动采集直方图信息
手动任务创建后仅会执行一次,无需手动删除。
-- 语法 ANALYZE TABLE tbl_name UPDATE HISTOGRAM ON col_name [, col_name] [WITH SYNC | ASYNC MODE] [WITH N BUCKETS] [PROPERTIES (property [,property])] 例子: -- 手动采集v1列的直方图信息,使用默认配置。 ANALYZE TABLE tbl_name UPDATE HISTOGRAM ON v1; -- 手动采集v1列的直方图信息,指定32个分桶,mcv指定为32个,采样比例为50%。 ANALYZE TABLE tbl_name UPDATE HISTOGRAM ON v1,v2 WITH 32 BUCKETS PROPERTIES( "histogram_mcv_size" = "32", "histogram_sample_ratio" = "0.5" ); 