
阅读量:0
本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:大模型技术内参:39 种提示工程 在 29 种 NLP 任务精度对比
大语言模型(LLMs)在许多不同的自然语言处理(NLP)任务中表现出色。提示工程需要编写称为提示的自然语言指令,以结构化方式从LLMs中提取知识。与以往的最新技术(SoTA)模型不同,提示工程不需要根据给定的NLP任务进行广泛的参数重新训练或微调,因此仅依赖于LLMs的嵌入知识。
《在不同自然语言处理任务中的提示工程方法调查》
https://arxiv.org/pdf/2407.12994
在本文中,我们阅读并总结了44篇研究论文,这些论文讨论了39种不同的提示方法和29种不同的NLP任务。我们细说明了这些提示策略在各种数据集上的表现。
提示词工程
方法 1:基础/标准/普通提示
基础提示指的是直接向LLM提出查询的方法,而无需进行任何工程改进以提升LLM的性能,这是大多数提示策略背后的核心目标。基础提示在不同的研究论文中也被称为标准提示或普通提示。
方法 2:思维链提示 (Chain-of-Thought, CoT)
在CoT提示策略中,前将其分解为更小、更易处理的子问题的思路进行研究。类似地,作者调查了通过产生一系列思维链或中间推理步骤,如何内在地增强LLMs进行复杂推理的能力。
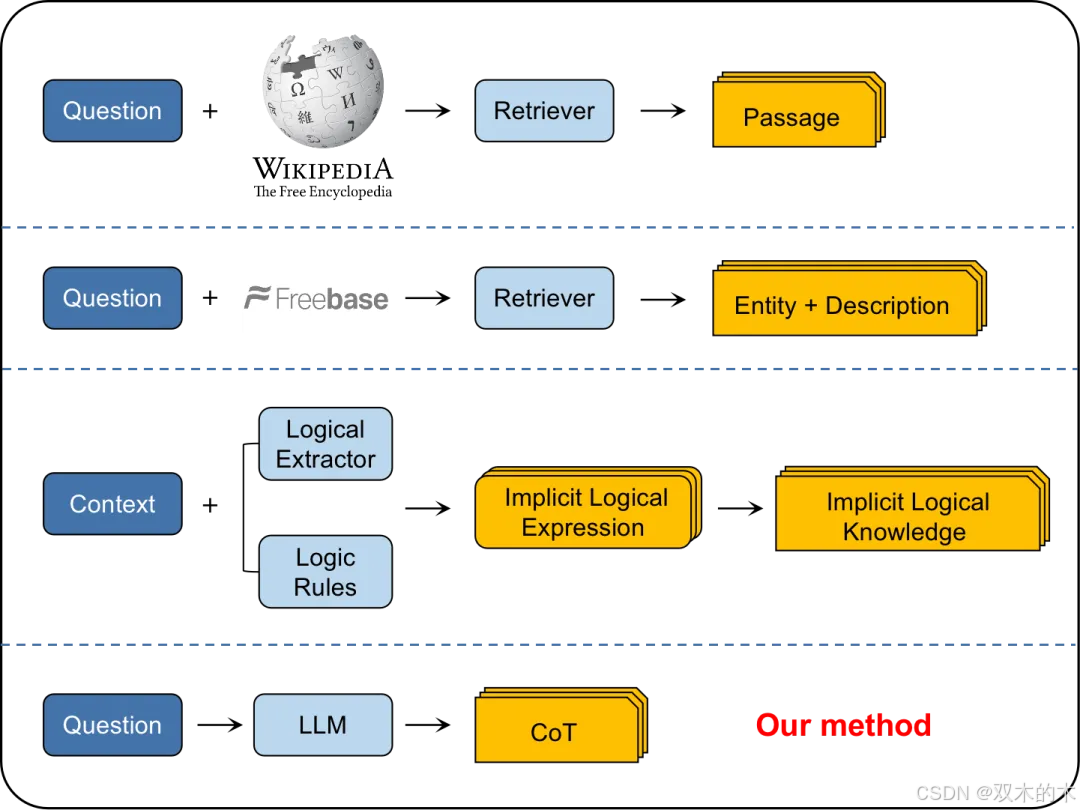
结果表明,与基础提示相比,CoT提示显示出显著的性能提升。例如,在数学问题解决任务中,CoT提示与基础提示的性能差异最大可达约39%,而在常识推理任务中则可达约26%。这项研究为提示工程领域开辟了新的研究方向。
方法 3:自我一致性 (Self-Consistency)
自我一致性提示可以通过多种方式解决,因此正确答案可以通过不同的推理路径达到的直觉。自我一致性使用了一种新颖的解码策略,不同于CoT使用的贪心策略,包含三个重要步骤。
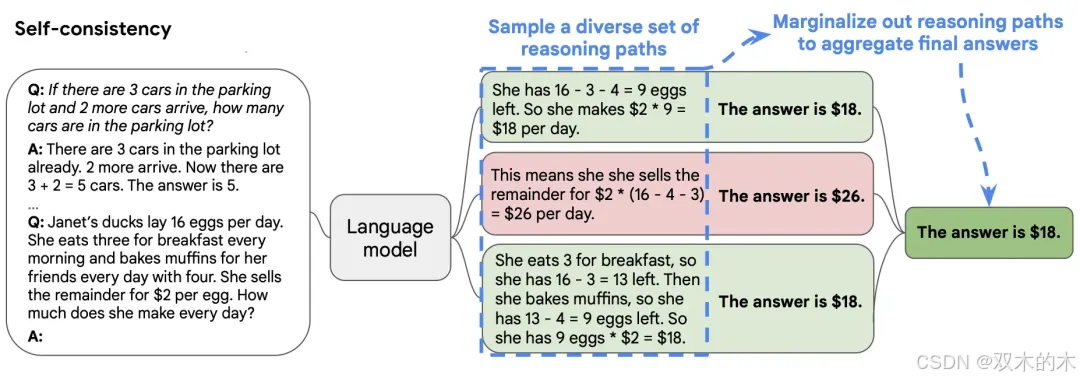
首先是使用CoT提示LLM,其次是从LLM的解码器中抽取多样化的推理路径,最后是选择在多个推理路径中最一致的答案。与CoT相比,自我一致性在数学问题解决任务上平均提升11%,在常识推理任务上提升3%,在多跳推理任务上提升6%。
方法 4:集成精炼 (Ensemble Refinement, ER)
集成精炼提示方法基于CoT和自我一致性方法进行改进。ER包含两个阶段。首先,给定一个少样本的CoT提示和一个查询,LLM通过调整其温度生成多个回答。每个生成的回答都包含一个推理过程和一个答案。
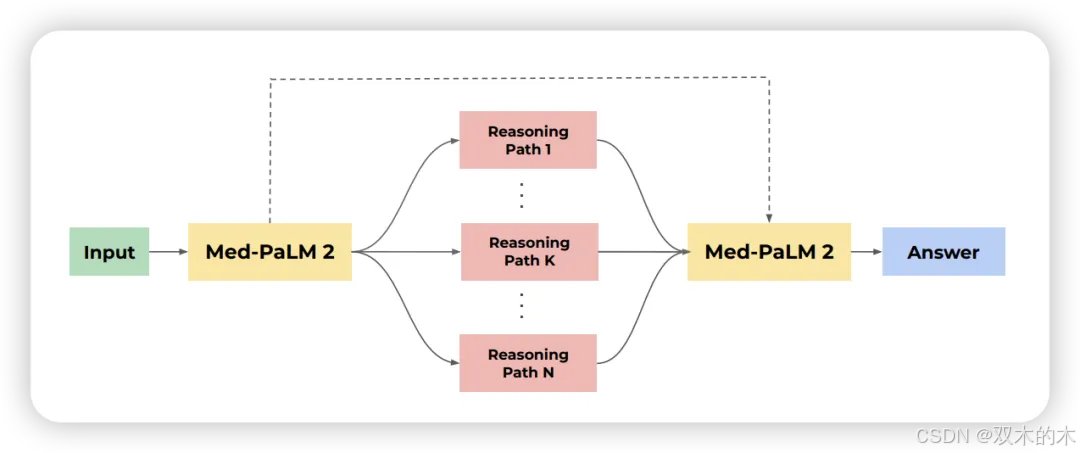
接下来,LLM根据原始提示、查询和前一阶段的所有生成结果生成更好的解释和答案。这一过程重复多次,然后对这些第二阶段生成的答案进行多数投票,类似于自我一致性的方法,以选择最终答案。ER在许多属于上下文无关问答任务的数据集上表现优于CoT和自我一致性方法。
方法 5:自动思维链 (Automatic Chain-of-Thought, Auto-CoT)
Auto-CoT解决了少样本CoT或手动CoT需要高质量训练数据点的问题。Auto-CoT包含两个主要步骤。首先,将给定数据集的查询划分为几个簇。其次,从每个簇中选择一个代表性查询,然后使用零样本CoT生成其对应的推理链。
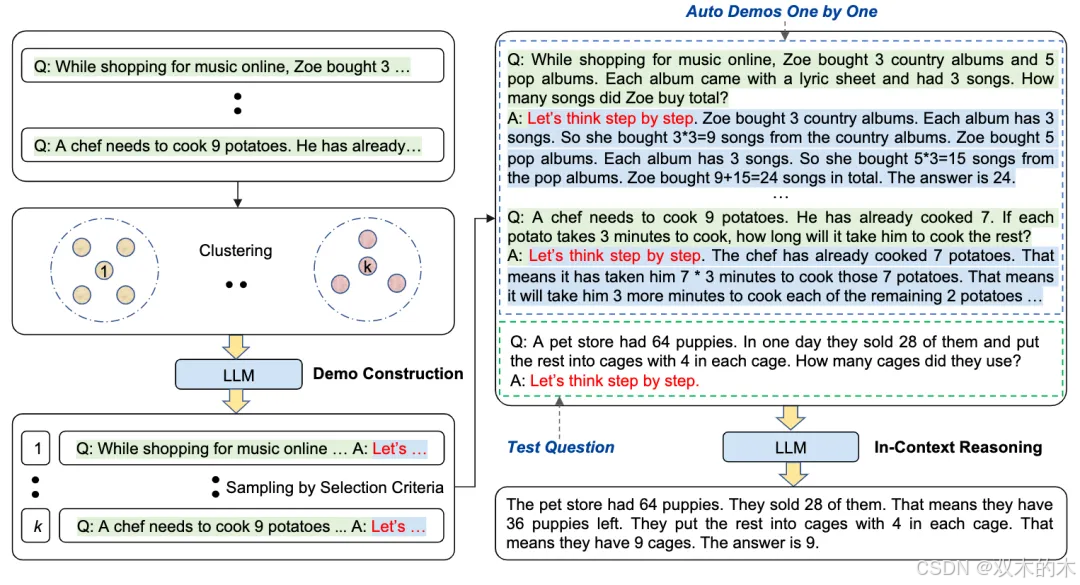
作者声称,Auto-CoT在数学问题解决、多跳推理和常识推理任务中要么超越了少样本CoT,要么表现相当。这表明可以省去少样本或手动CoT对训练数据点的策划步骤。
方法 6:复杂思维链 (Complex CoT)
Complex CoT在选择复杂的数据点提示而非简单的。这里定义数据点的复杂性是根据其涉及的推理步骤数量。作者假设,使用复杂数据点作为上下文训练示例可以提高LLMs的推理性能,因为它们已经包含了较简单的数据点。

除了使用复杂数据点作为训练示例外,复杂思维链在解码过程中,类似于自我一致性方法,从N个采样推理链中选择前K个最复杂链中的多数答案作为最终答案。该论文中还引入了一种基线提示方法,称为随机思维链(Random CoT),其中数据点随机采样,而不考虑其复杂性。复杂思维链在数学问题解决、常识推理、基于表格的数学问题解决和多跳推理任务的各种数据集上平均提高了5.3%的准确性,最高可提高18%的准确性。
方法 7:思维程序 (Program-of-Thoughts, PoT)
与CoT不同的是,PoT生成Python程序,从而将计算部分委托给Python解释器。这项研究认为,减少LLM的责任使其在数值推理方面更准确。PoT在数学问题解决、基于表格的数学问题解决、上下文问答和对话上下文问答任务上,平均性能比CoT高出约12%。

方法 8:从简到繁 (Least-to-Most)
从简到繁提示旨在解决CoT无法准确解决比提示示例更难的问题。它包括两个阶段。首先,提示LLM将给定问题分解为子问题。接下来,提示LLM依次解决子问题,任何子问题的答案都依赖于前一个子问题的答案。
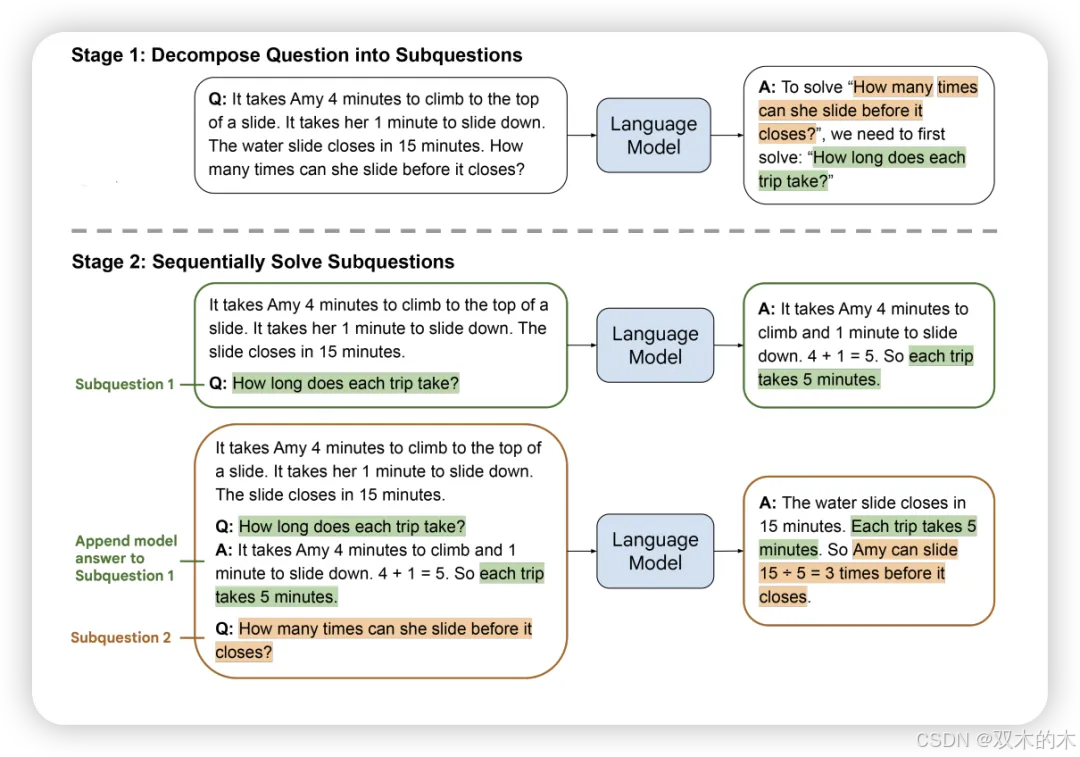
作者表明,从简到繁提示在常识推理、基于语言的任务完成、数学问题解决和上下文问答任务上显著优于CoT和基础提示方法。
方法 9:符号链 (Chain-of-Symbol, CoS)
在传统的CoT中,中间的推理链步骤用自然语言表示。虽然这种方法在许多情况下表现出色,但也可能包含错误或冗余信息。
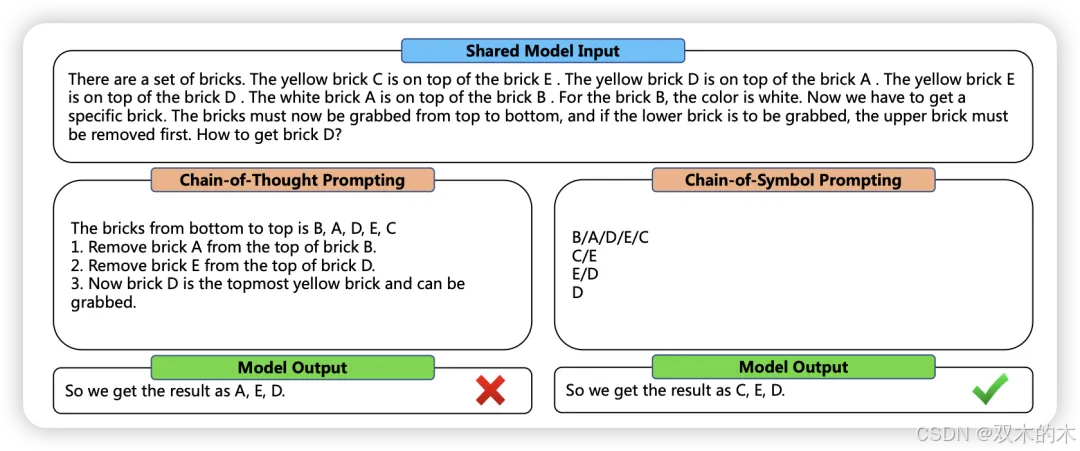
作者提出假设,空间描述难以用自然语言表达,从而使LLM难以理解。相反,使用符号在单词序列中表示这些关系可能是LLM更好的表达形式。CoS在空间问答任务中将准确率提高了高达60.8%。
方法 10:结构化思维链 (Structured Chain-of-Thought, SCoT)
SCoT直觉是使用程序结构(如顺序、分支和循环)来结构化中间推理步骤,比在传统CoT中用自然语言表示中间推理步骤更能生成准确的代码。

作者声称,这种方法比后者更接近人类开发者的思维过程,最终结果也证实了这一点,SCoT在代码生成任务上比CoT高出高达13.79%。
方法 11:计划与解决 (Plan-and-Solve, PS)
PS尝试解决CoT的三个缺点:计算错误、缺失步骤错误和语义理解错误。PS包含两个组件,第一个需要制定一个计划,将整个问题分解为更小的子问题,第二个需要根据计划执行这些子问题。

改进版的PS+增加了更详细的指示,有助于提高推理步骤的质量。在零样本设置下,PS提示方法在几乎所有数学问题解决任务的数据集上比CoT提高了至少5%的准确率。同样,对于常识推理任务,PS在零样本设置下始终比CoT高出至少5%,而在多跳推理任务中,其准确率提高了约2%。
方法 12:数学提示器 (MathPrompter)
MathPrompter尝试解决CoT在数学问题解决任务中的两个关键问题:
CoT用于解决问题的步骤的有效;
LLM对其预测的信心如何。
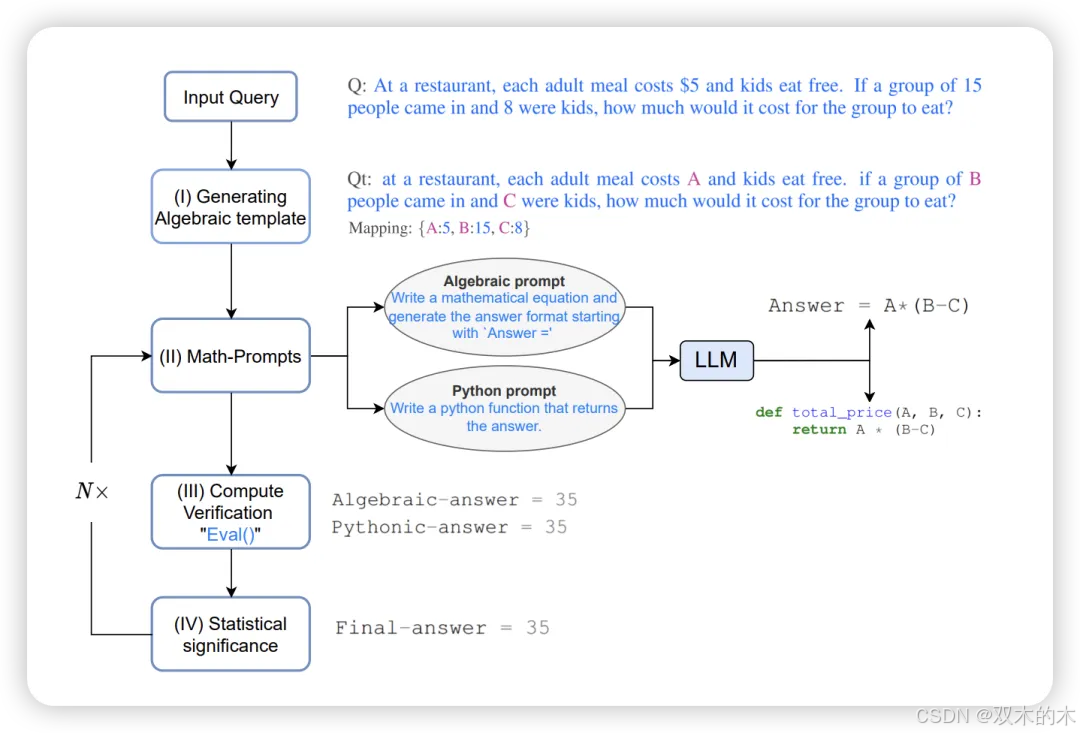
MathPrompter提示策略总共包含四个步骤:
给定查询,第一步需要生成一个代数表达式,将数值替换为变量;
接下来,提示LLM通过推导代数表达式或编写Python函数来解析查询;
第三步,通过为变量分配不同的值来解决第(I)步中的查询;
如果第(III)步中的解决方案在N次迭代中是正确的,则最终将变量替换为原始查询值并计算答案。如果不是,则重复步骤(II)、(III)和(IV)。
方法 13:对比思维链/对比自我一致性 (Contrastive CoT/Contrastive Self-Consistency)
对比思维链或对比自我一致性是CoT或自我一致性的通用增强方法。这种提示方法的灵感来源于人类可以从正面和负面示例中学习的方式。类似地,在这种提示技术中,同时提供正面和负面示例,以增强LLM的推理能力。

对比思维链在数学问题解决任务上平均比传统CoT提高了10%,对比自我一致性在数学问题解决任务上比传统自我一致性提高了超过15%。对于多跳推理任务,对比思维链和对比自我一致性都比其传统对应方法提高了超过10%。
方法 14:联邦相同/不同参数自我一致性/思维链 (Federated Same/Different Parameter Self-Consistency/CoT, Fed-SP/DP-SC/CoT)
联邦思维链核心思想是通过使用同义词众包查询来提高LLMs的推理能力。这种提示方法有两个稍有不同的变体。第一个是Fed-SP-SC,其中众包查询是原始查询的释义版本,但参数相同。参数在这里可以指数学问题解决任务数据点中的数值。
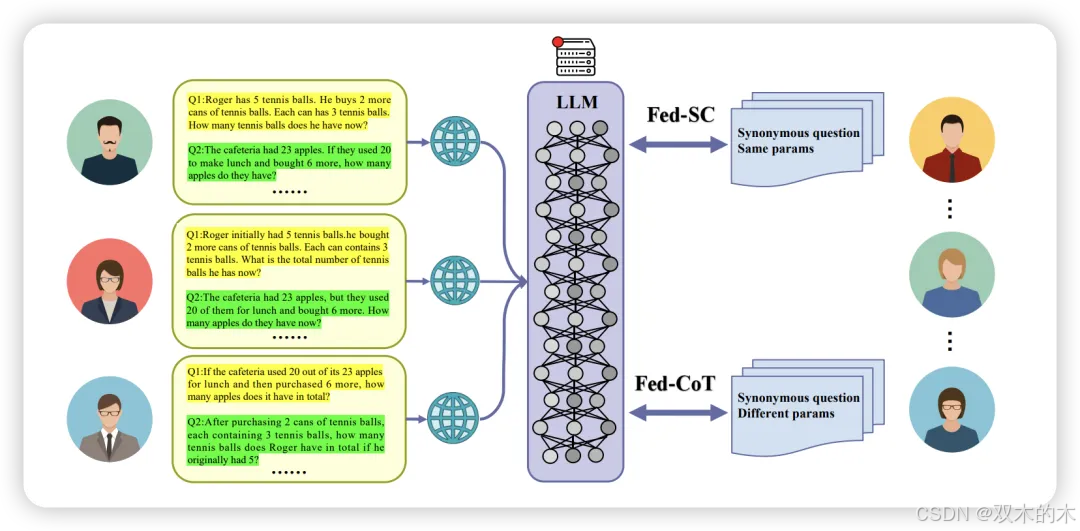
对于Fed-SP-SC,首先直接生成答案,然后应用自我一致性。另一个是Fed-DP-CoT。在Fed-DP-CoT中,首先使用LLM生成不同查询的答案,然后通过形成思维链来为LLMs提供提示。数学问题解决任务的结果显示,这些方法比传统CoT至少提高了10%,最高可提高20%。
方法 15:类比推理 (Analogical Reasoning)
作者从心理学概念类比推理中汲取灵感,人们使用相关的先前经验来解决新问题。在LLMs的领域中,作者首先提示它们生成类似于原始问题的示例,然后解决这些示例,接着回答原始问题。

结果表明,类比推理在数学问题解决、代码生成、逻辑推理和常识推理任务中比CoT平均提高了4%的准确率。
方法 16:合成提示 (Synthetic Prompting)
Synthetic Prompting使用LLMs生成合成示例,这些示例与现有的手工制作示例一起用于传统的少样本设置。该提示方法涉及两个步骤:
反向步骤,LLM根据自生成的推理链合成查询;
前向步骤,LLM为合成查询生成推理链,从而使推理链更准确。
最后,为选择最佳示例,该工作使用簇内复杂度,并在推理链最长的最复杂示例中进行推断。结果显示,合成提示在不同的数学问题解决、常识推理和逻辑推理任务数据集中,绝对收益高达15.6%。

方法 17:思维树 (Tree-of-Thoughts, ToT)
ToT提示技术源于这样一个想法:任何问题解决都需要在一个组合空间中进行搜索,该空间表示为一个树结构,其中每个节点代表部分解决方案,每个分支对应修改它的操作。选择哪个分支的决定由帮助导航问题空间的启发式方法决定,指导问题解决者朝着解决方案前进。
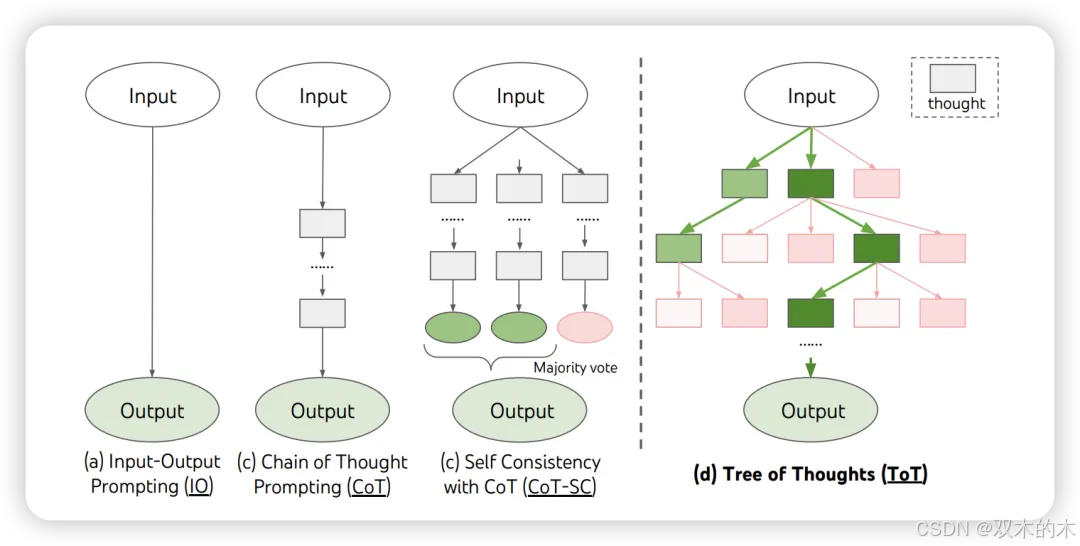
基于这一思想,作者提出了ToT,该方法主动维护一个思维树,其中每个思维是一连贯的语言序列,作为解决问题的中间推理步骤。这一框架允许LLMs在尝试解决问题时评估思维产生的进展。ToT进一步结合了如广度优先搜索或深度优先搜索等搜索技术与模型生成和评估思维的能力。
ToT在数学问题解决任务上比CoT的成功率提高了65%,在不同逻辑推理任务数据集上成功率提高了约40%。在自由回答任务中,ToT的连贯性得分为7.56,而CoT的平均得分仅为6.93。
方法 18:逻辑思维 (Logical Thoughts, LoT)
除了允许LLM逐步推理外,LoT还允许LLM根据反证法原则逐步验证,并在需要时修改推理链以确保有效推理。
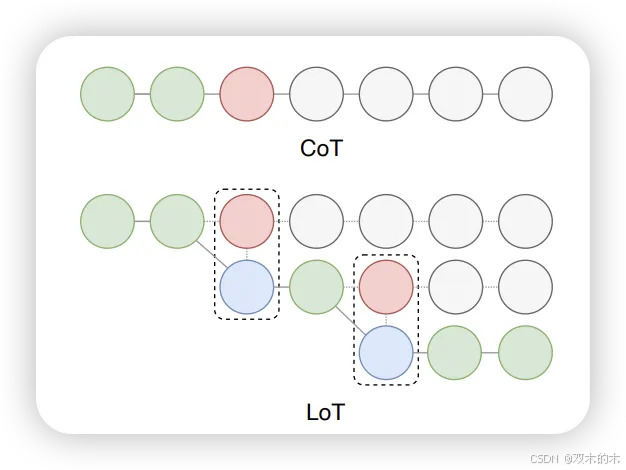
LoT在数学问题解决任务中比CoT最多高出3.7%,在常识推理任务中最多高出16.2%,在逻辑推理任务中最多高出2.5%,在因果推理任务中最多高出15.8%,在社会推理任务中最多高出10%的准确率。
方法 19:产婆术提示 (Maieutic Prompting)
产婆术提示的生成过程形成了生成命题的树结构,其中一个命题为另一个命题的正确性奠定逻辑基础。最终,为推断原始查询的答案,衡量LLM对每个命题的信任程度和命题之间的逻辑联系。
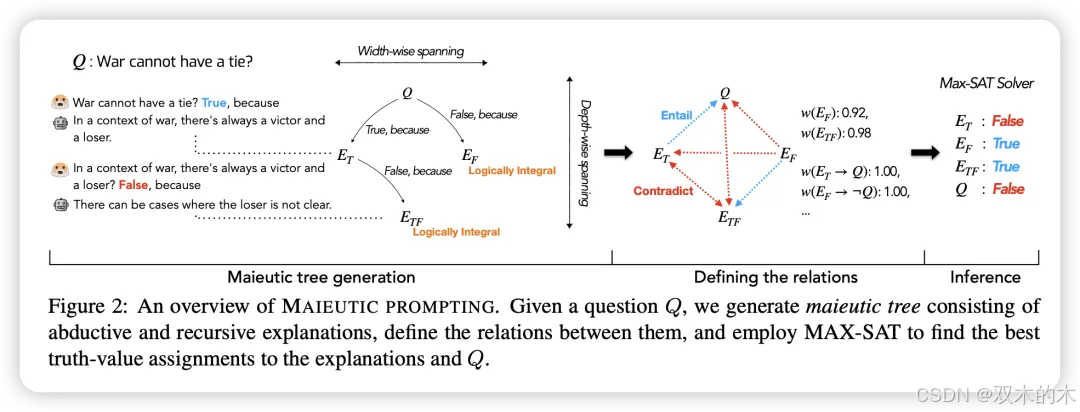
在常识推理任务中,产婆术提示比基本提示、CoT和自我一致性方法提高了多达20%的准确率,同时在与监督模型的竞争中表现良好。
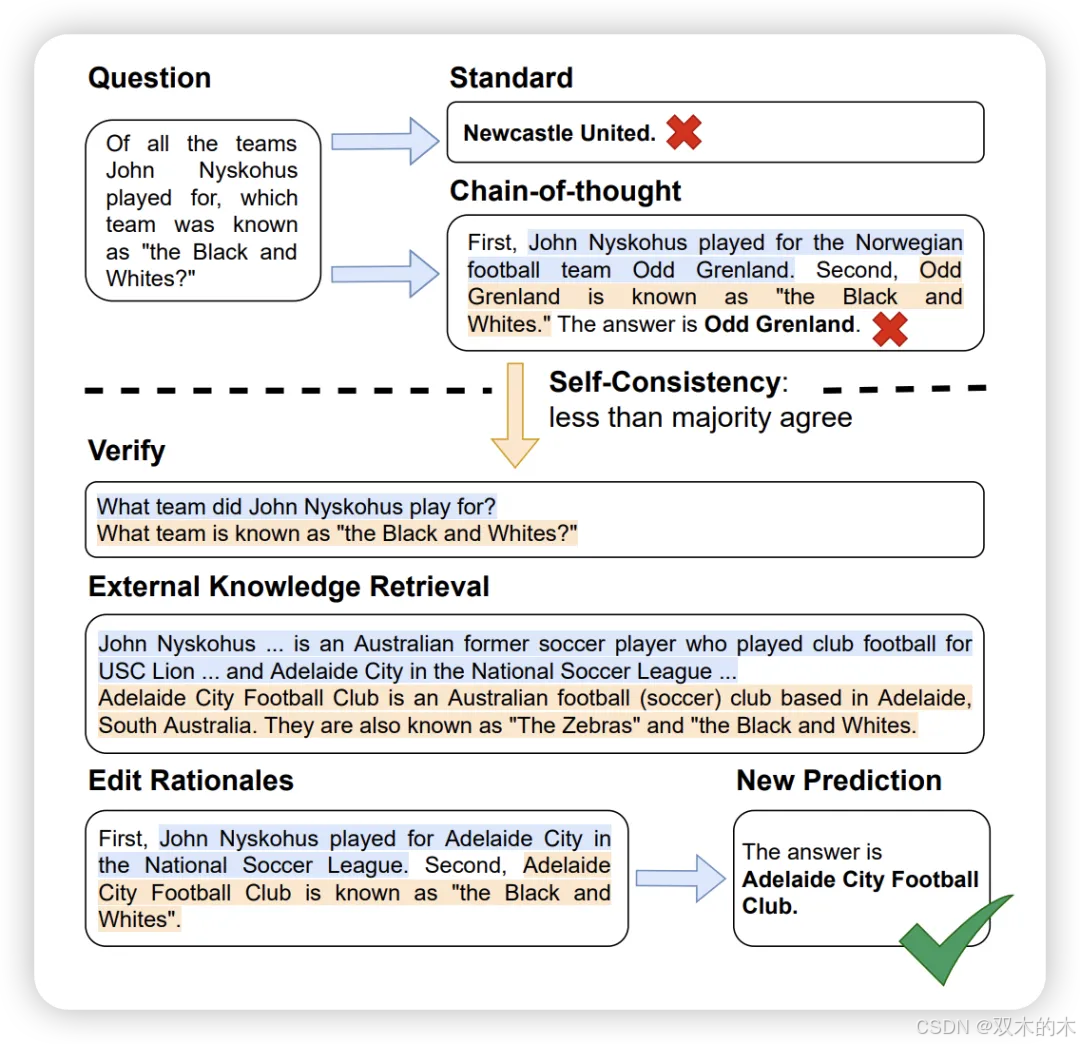
方法 20:验证与编辑 (Verify-and-Edit, VE)
由CoT生成的推理链,以获得更符合事实的输出。该方法包括三个阶段:
何时编辑阶段,作者使用自我一致性找出不确定的输出;
如何编辑推理阶段,作者通过搜索外部知识来源的支持事实编辑不确定输出的CoT推理链;(
推理阶段,使用前一阶段编辑的推理链得出最终答案。
VE在多跳推理任务上比CoT、自我一致性和基本提示高出多达10%,在真实性任务上高出多达2%。
方法 21:推理与行动 (Reason + Act, ReAct)
ReAct将推理与行动结合在一起,利用LLMs解决各种语言推理和决策任务。为了使模型能够执行动态推理以构建和修改行动的高层计划(推理到行动),ReAct提示LLMs以交替方式生成与任务相关的口头推理轨迹和行动。
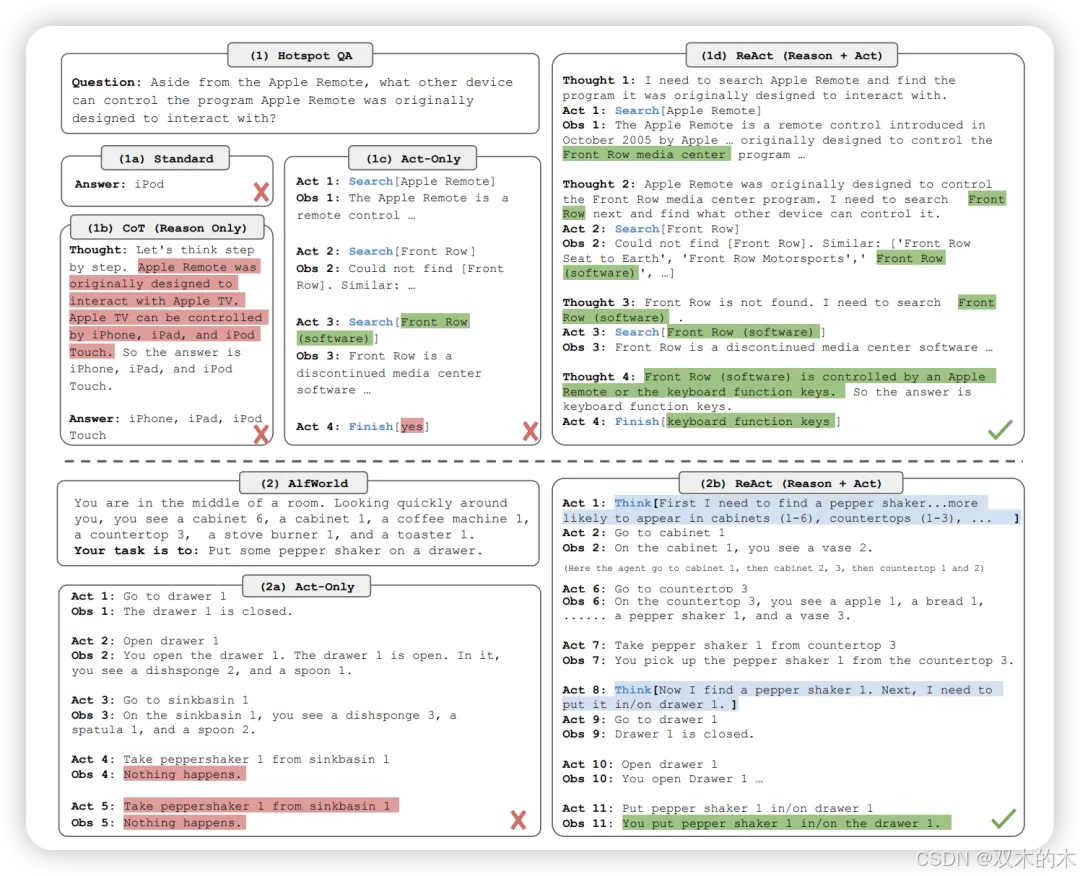
当ReAct与CoT或自我一致性结合时,能获得比CoT更好的结果。在基于语言的任务完成任务中,ReAct在不同数据集上的成功率比强化学习方法提高了超过10%的绝对值。
方法 22:主动提示 (Active-Prompt)
Active-Prompt帮助LLMs通过识别最相关的数据点来适应不同任务,并在少样本设置中将其用作示例。
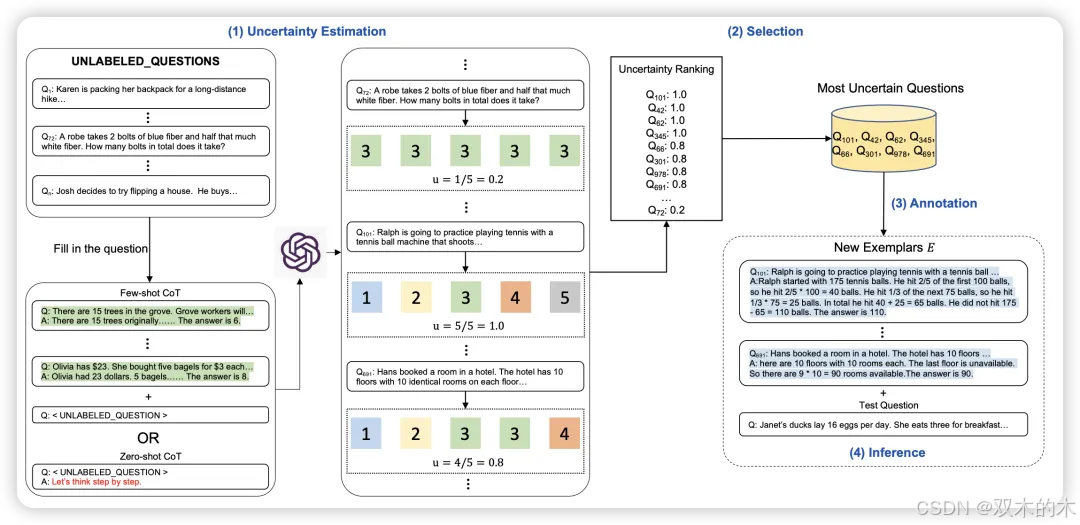
Active-Prompt是一种四步技术:
第一步,提示LLM对训练集中的每个查询进行k次提示,生成k个可能的答案及其对应的推理链。
第二步,需要基于第一步生成的答案计算不确定性指标。第三步,选择不确定性最高的前n个查询,并由人工注释。
最后一步,使用新的注释示例对测试数据进行少样本提示。
结果显示,Active-Prompt在数学问题解决、常识推理、多跳推理和常识推理任务的多个数据集上,比自我一致性、CoT、Auto-CoT和随机CoT获得更好的结果。
方法 23:思维线 (Thread-of-Thought, ThoT)
ThoT核心理念是,人们在处理大量信息时会保持一种连续的思维流动,从而能够选择性地提取相关数据并拒绝不相关的内容。这种对文档各部分的注意力平衡对于准确解读和回应提供的信息至关重要。
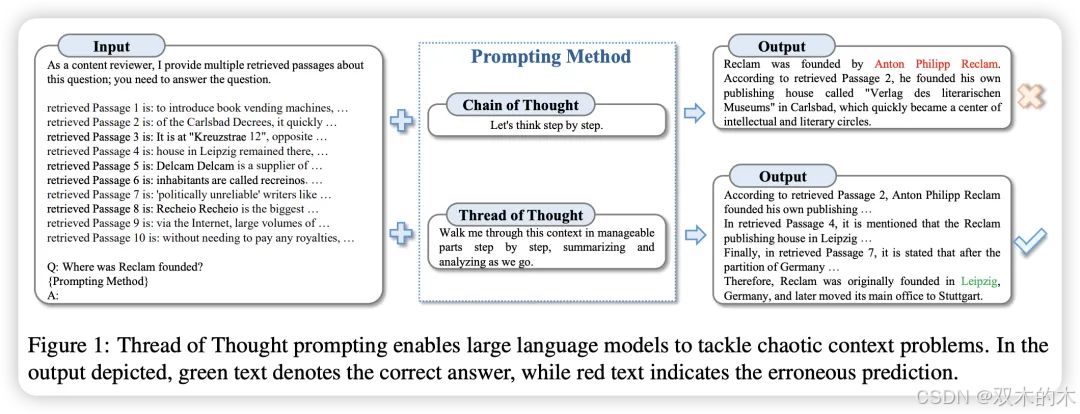
ThoT分为两个步骤。第一步要求LLM分析和总结上下文的不同部分。第二步,LLM根据第一步的输出回答所提出的查询。在上下文无关问答任务中,ThoT取得了约0.56的精确匹配得分,超过了CoT和基本提示技术。在对话系统任务中,ThoT获得了3.8的最高平均分,再次超越了其他提示技术。
方法 24:隐式检索增强生成 (Implicit Retrieval Augmented Generation, Implicit RAG)
与传统的RAG不同,Implicit RAG 要求LLM自行从给定的上下文中检索重要部分,然后继续回答提出的查询。此技术需要调整两个超参数。第一个是提取的部分数量,第二个是每个部分的词数。
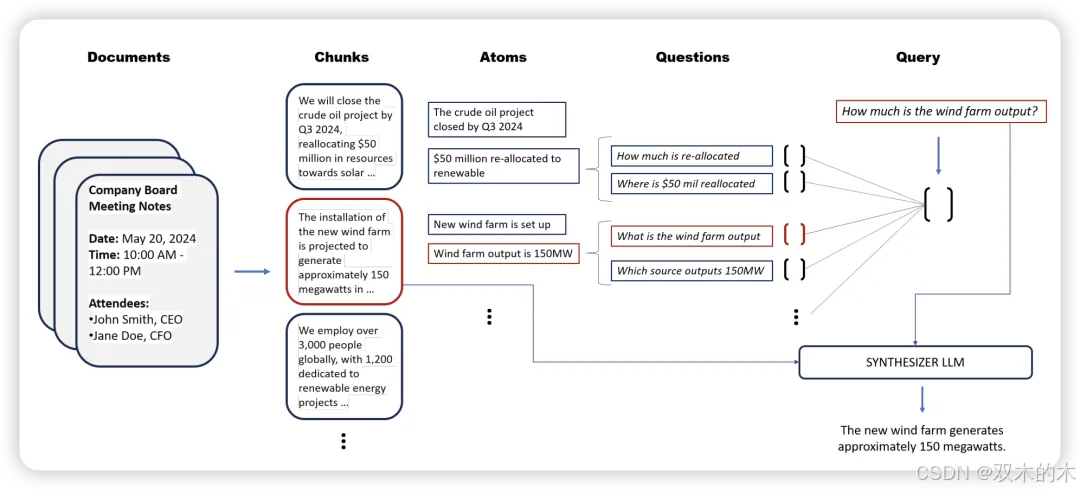
在患者病例报告数据集的上下文问答任务中,Implicit RAG达到了最先进的结果,同时在生物医学上下文问答任务数据集中也达到了最先进或接近最先进的结果。
方法 25:系统2注意力 (System 2 Attention, S2A)
当面对不相关的上下文时,LLMs往往会做出错误的判断。S2A尝试通过两步提示策略解决这个问题。第一步指示LLM重新生成一个给定的上下文,使重新生成的版本不包含可能对输出产生不利影响的不相关部分。第二步指示LLM使用第一步的重新生成的上下文生成最终响应。
结果显示,S2A在不同的真实性任务数据集上比基本、CoT以及指示性提示表现更好。
方法 26:指示性提示 (Instructed Prompting)
Instructed Prompting尝试解决LLMs被不相关上下文分心的问题。它只有一个步骤,即明确指示语言模型忽略问题描述中的不相关信息。指示性提示在真实性任务中获得了88.2的标准化微准确率,超过了包括CoT、Least-To-Most、程序提示和自我一致性在内的所有对比方法。
方法 27:验证链 (Chain-of-Verification, CoVe)
LLMs容易生成事实错误的信息,即幻觉。CoVe执行四个核心步骤。首先,LLM生成给定查询的基线响应。其次,使用原始查询和第一步的基线响应生成一系列验证查询,检查基线响应中是否有错误。第三,生成对所有验证查询的回答。第四,纠正第三步检测到的基线响应中的所有错误,并生成修订后的响应。
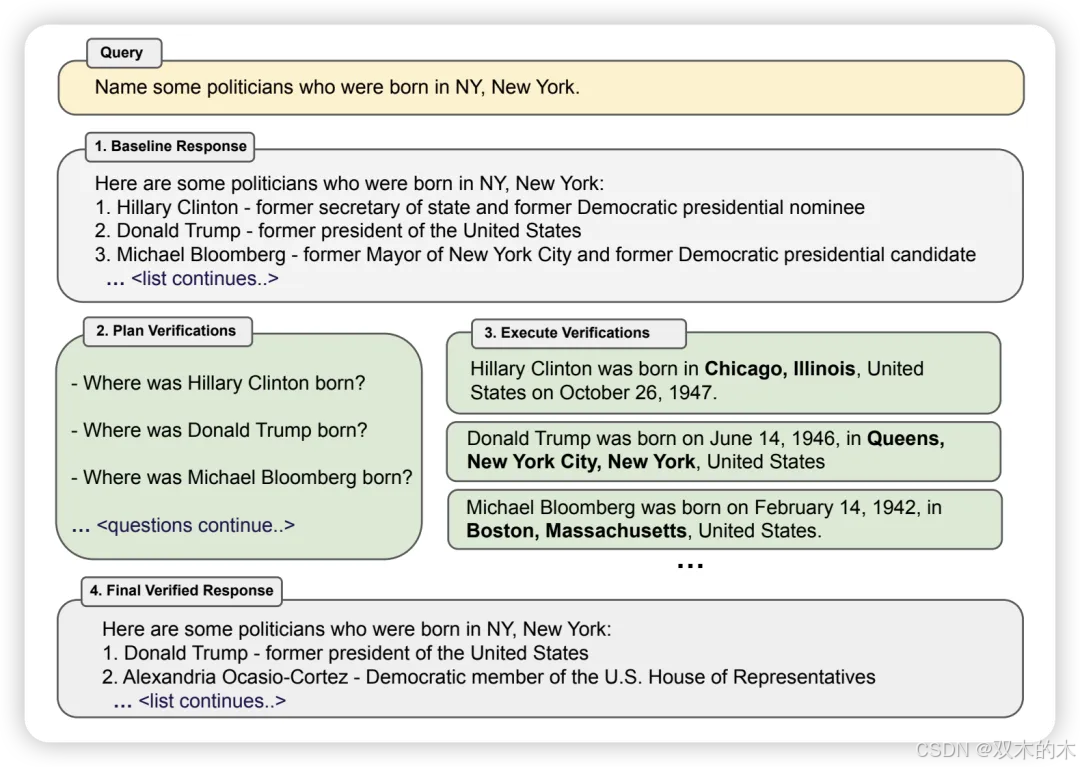
结果显示,CoVe在上下文无关问答、上下文问答和自由回答任务中,比CoT和基本提示高出至少10%。
方法 28:知识链 (Chain-of-Knowledge, CoK)
CoK是一种三阶段的提示技术。第一阶段是推理准备,给定一个查询,CoK准备若干初步推理和答案,同时识别相关知识领域。第二阶段是动态知识适应,如果答案之间没有多数共识,CoK通过从第一阶段识别的知识领域中逐步适应知识来纠正推理。第三阶段是答案整合,使用第二阶段的这些纠正推理作为更好的基础来整合最终答案。
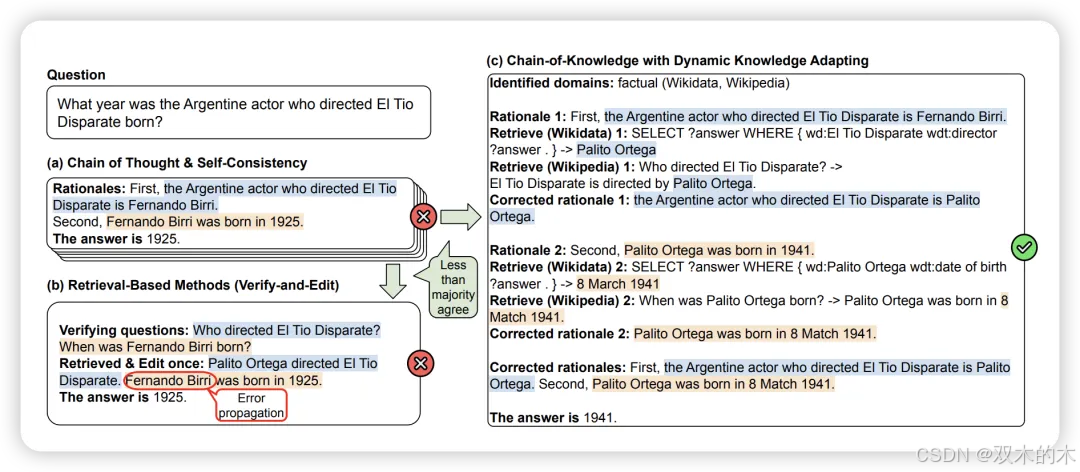
CoK在上下文无关问答、表格问答、多跳推理和真实性任务中超越了CoT、自我一致性、VE和基本提示,分别显示了至少3%、3%、1%和1%的改进。
方法 29:代码链 (Chain-of-Code, CoC)
在这里,LLM不仅为程序编写代码,还通过生成某些代码行的预期输出来选择性地模拟解释器,这些代码行无法由解释器实际执行。主要思路是激励LLMs将程序中的语义子任务格式化为灵活的伪代码,这些伪代码可以在运行时显式捕获并传递给LLM进行模拟。

实验表明,CoC在推荐系统、因果推理、常识推理、空间问答、情感理解、机器翻译、逻辑推理、表格数学问题解决和数学问题解决等各种任务中超过了CoT和其他基线。
方法 30:程序辅助语言模型 (Program-Aided Language Models, PAL)
PAL使用LLM读取自然语言问题,并生成交替的自然语言和编程语言语句作为推理步骤。最后,使用Python解释器执行编程语句以获得答案。结果显示,PAL在数学问题解决、表格数学问题解决、常识推理和逻辑推理等多项NLP任务中,比其对比方法如CoT和基本提示表现更好。

方法 31:绑定器 (Binder)
Binder是一种无需训练的神经符号技术,它将输入映射到一个程序,该程序(I)允许绑定LLM功能的单个API到Python或SQL等编程语言,以增加其语法覆盖范围并处理更广泛的查询;(II)使用LLM作为底层模型以及执行期间的程序解析器;(III)只需要少量上下文样本注释。
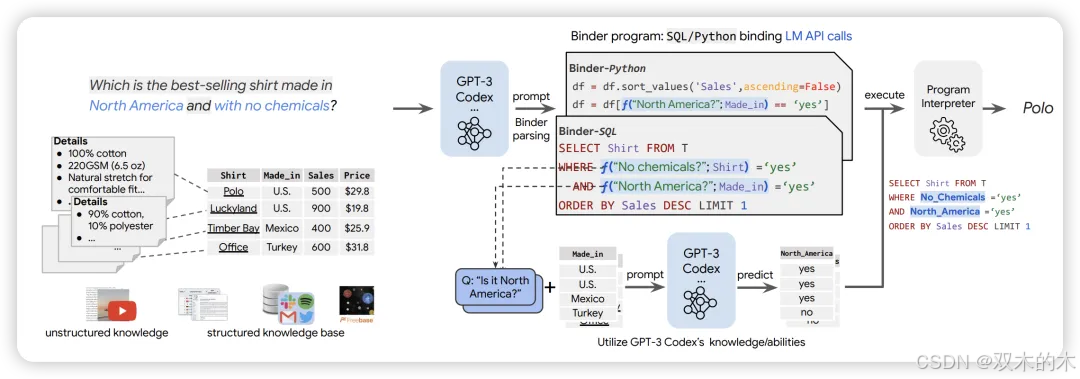
Binder管道有两个阶段。首先,在解析阶段,LLM根据查询和知识来源将输入映射到一个程序。其次,在执行阶段,LLM以选择的编程语言返回值,并最终使用解释器运行程序。Binder在需要明确训练或微调的表格真实性和表格问答任务中,比之前的方法获得了更好的准确性。
方法 32:DATER
DATER探索了使用LLMs进行少样本学习的方法,以分解证据和查询以进行高效的表格推理。该提示策略包括三个重要步骤。首先,根据查询将一个大表分解为相关的较小子表。接下来,使用SQL编程语言将复杂的自然语言查询分解为逻辑和数值计算。最后,使用前两个步骤中的子表和子查询在少样本设置中得出最终答案。
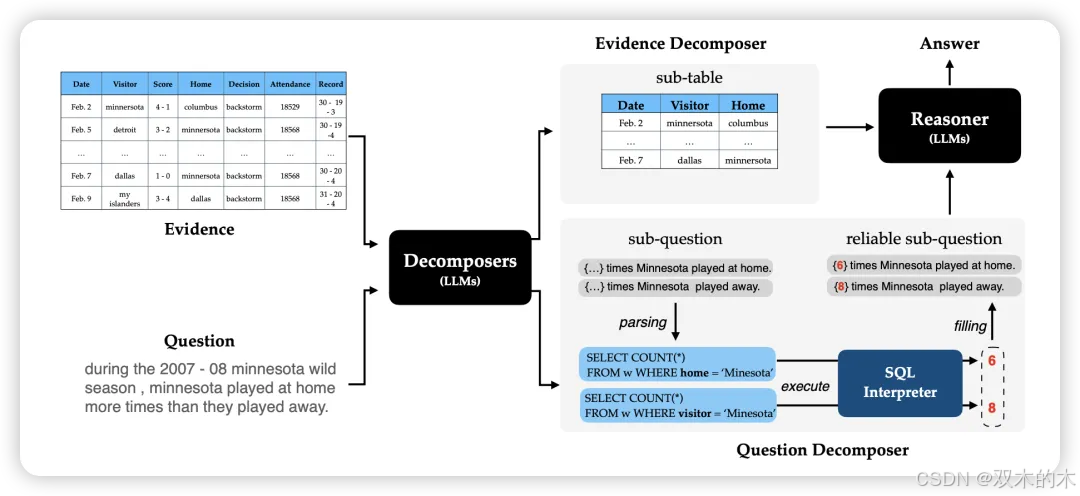
结果显示,Dater在表格真实性任务中比需要明确微调的之前方法高出至少2%。同样,在表格问答任务中,它比这些方法高出至少1%。Dater在这两个任务中也优于Binder。
方法 33:表链 (Chain-of-Table, CoT)
表链是一种三步骤的提示技术。第一步指示LLM通过上下文学习动态规划下一步表操作。这里的操作可以是从添加列到排序行的任何操作。第二步为选择的表操作生成参数。前两步帮助转换表并创建各种中间表表示,以回答原始查询。最后一步,使用前两步生成的最后一个表表示最终回答查询。表链在表格问答和表格真实性任务中达到了最先进的性能。
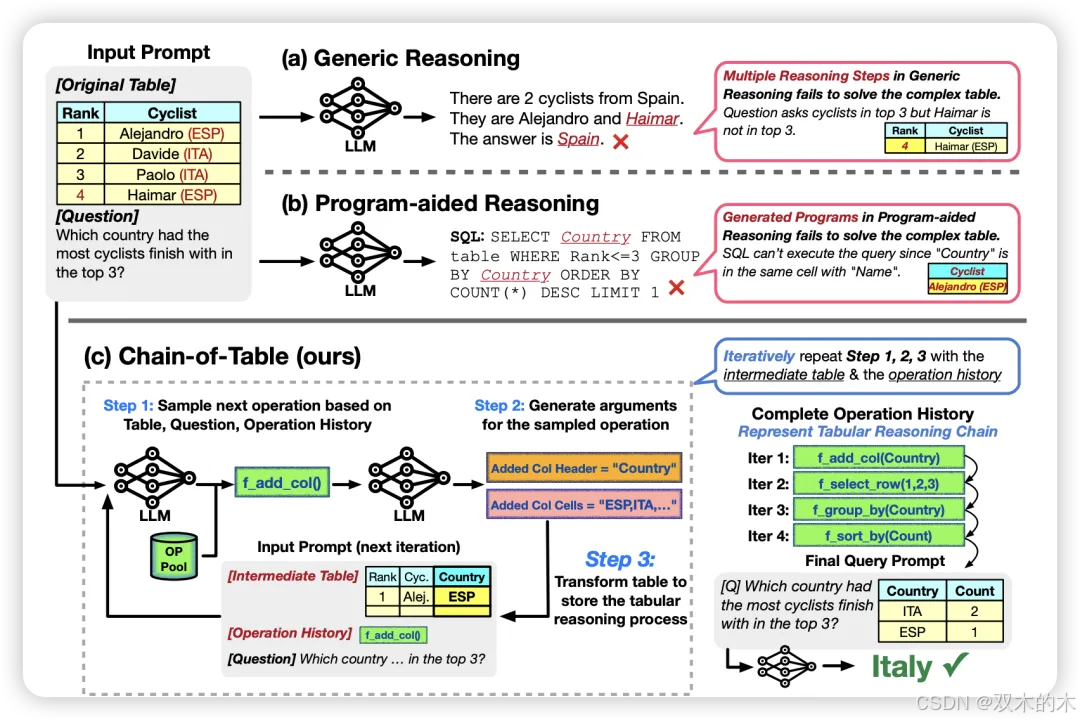
对于表格问答任务,它的平均性能提高了约3%,而对于表格真实性任务,它的平均性能提高了约1.5%,与之前的最先进结果相比。
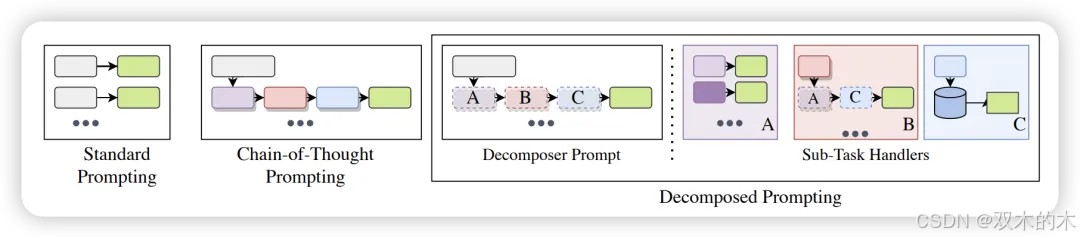
方法 34:分解提示 (Decomposed Prompting, Decomp)
DecomP技术将复杂问题分解为更简单的子问题,然后将这些子问题委派给具有各自提示和分解器的子问题特定LLMs。这些分解器可以通过层次分解、递归分解或进行外部API调用来解决子问题。在常识推理任务中,DecomP在精确匹配方面比CoT和Least-to-Most平均提高了25%。在多跳推理任务中,DecomP在四个不同的数据集上轻松超越了CoT。
方法 35:三跳推理 (Three-Hop Reasoning, THOR)
THOR模拟人类在情感/情绪理解任务中的推理过程。THOR包括三个步骤。第一步,要求LLM识别给定查询中提到的方面。接下来,根据上一步的输出和原始查询,要求LLM详细回答查询中嵌入的底层意见。最后,将上述所有信息结合起来,要求LLM推断与给定查询相关的情感极性。THOR在多个情感/情绪理解任务数据集上显著超越了之前的最先进监督和零样本模型。

方法 36:元认知提示 (Metacognitive Prompting, MP)
元认知概念涉及个体对其认知过程的意识和自我反思。它包括五个阶段:1)理解输入文本,2)做出初步判断,3)批判性地评估这一初步分析,4)得出最终决定并附上推理解释,5)评估整个过程的信心水平。
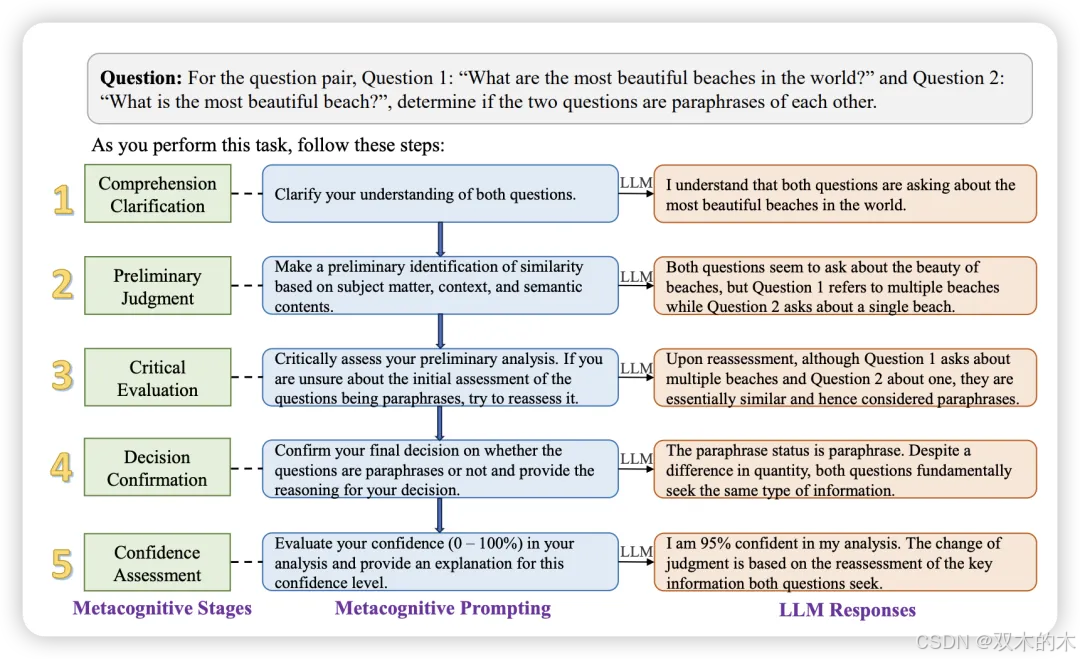
结果显示,MP在包括释义、自然语言推理、上下文问答、词义消歧、命名实体识别、关系抽取和多标签文本分类在内的众多NLP任务中,始终优于CoT和PS。
方法 37:事件链 (Chain-of-Event, CoE)
CoE有四个连续步骤。第一步专注于特定事件提取。接下来,分析和概括第一步提取的事件,使其更简洁和精炼。第三步,过滤上一步概括的事件,只选择那些覆盖大部分文本的事件。最后一步,根据事件的重要性顺序整合第三步选择的事件。结果显示,在两个摘要数据集上,CoE在rouge评分方面比CoT表现更好,同时更简洁。
方法 38:基本提示加术语定义 (Basic with Term Definitions)
在这种方法中,基本提示指令通过添加医学术语定义得以增强,基于这样一种假设,即添加这些定义将帮助LLM在回答查询时获得更多上下文。但结果显示,这些术语定义并没有真正起作用,可能是因为它们的知识范围狭窄,可能与LLM的更大知识库相冲突。
方法 39:基本+基于注释指南的提示+基于错误分析的提示 (Basic + Annotation Guideline-Based Prompting + Error Analysis-Based Prompting)
该提示策略包含三个不同的组件。基本组件告知LLM有关任务的基本信息以及LLM应输出结果的格式。注释指南组件包含根据注释指南提取的实体定义和语言规则。错误分析组件在使用训练数据进行LLM输出错误分析后,加入了额外的指令。
作者还通过创建上述组件的不同组合实验了不同版本的这种提示方法。该提示方法在属于命名实体识别任务的多个数据集上平均获得了0.57的精确匹配F1分数。
NLP 任务评测
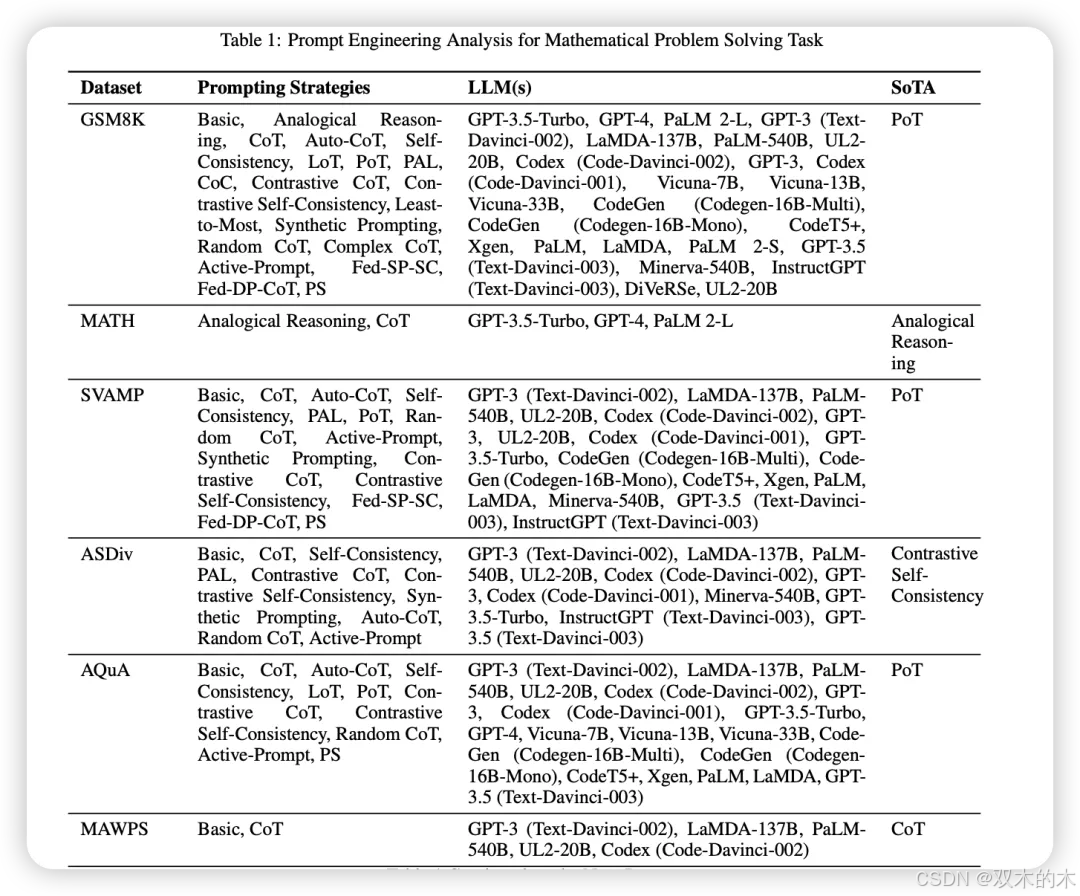
数学问题解决
衡量模型在非表格环境中执行任何数学计算的能力
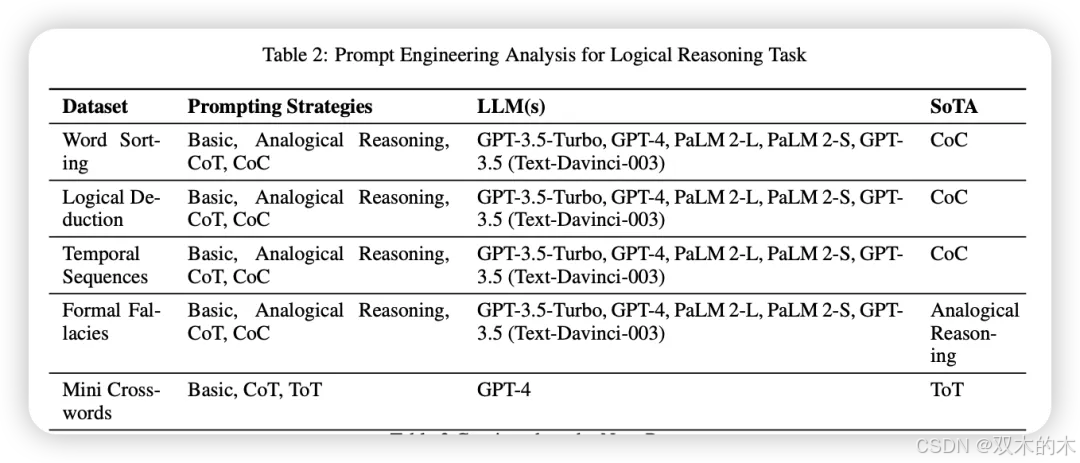
逻辑推理任务
检验模型对自然语言的理解能力,以遵循一系列带有输入的指令,并解决给定问题。
常识推理
与逻辑推理任务不同,常识推理任务衡量的是模型在人类通常所说的常识方面的能力,即利用普遍的实用知识来进行判断。它不涉及解决问题以得出答案。

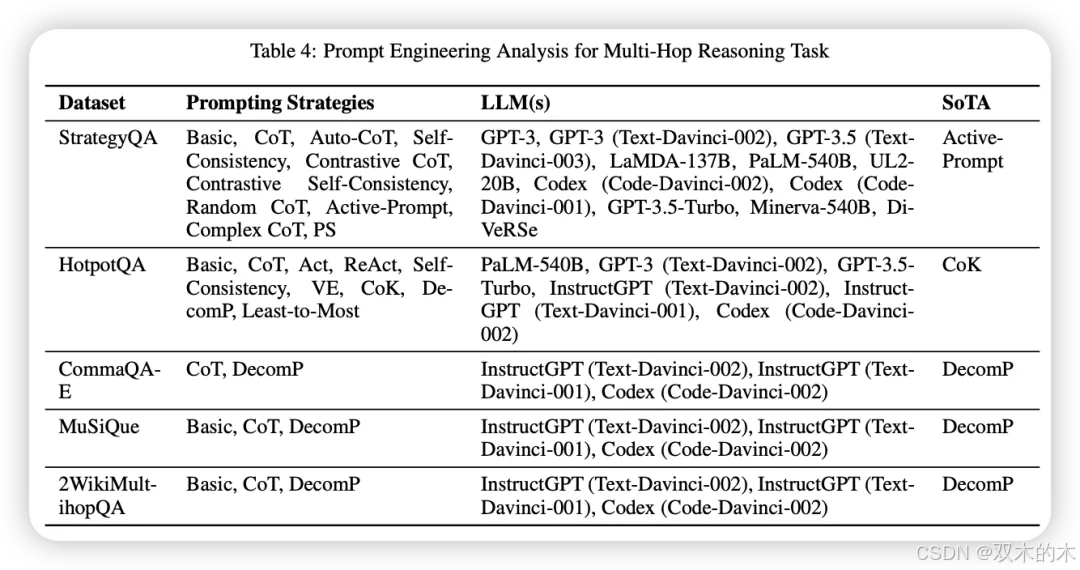
多跳推理
多跳推理任务评估模型在从上下文的不同部分连接证据片段以回答给定查询方面的能力
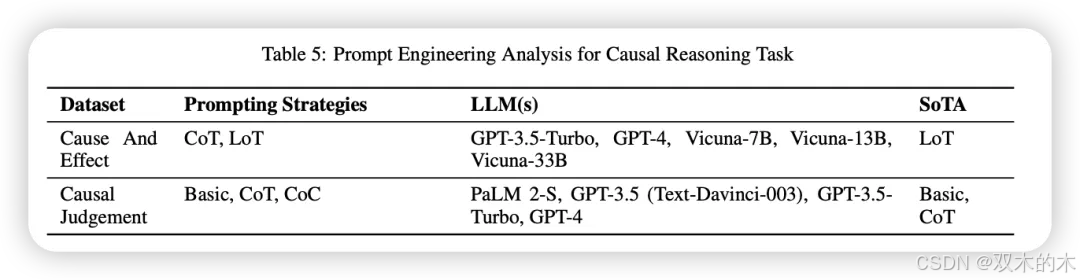
因果推理
因果推理任务检验模型处理因果关系的能力。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。
