
阅读量:0
引言
随着科技的不断进步,计算机视觉逐渐成为了人工智能领域的重要分支之一。计算机视觉旨在让计算机具备“看懂”图像和视频的能力,从而理解和分析视觉信息。作为计算机视觉中的一个关键任务,图像分类涉及将输入的图像归类到预定义的类别中,这是许多实际应用的基础,如人脸识别、自动驾驶、医疗影像分析等。
图像分类不仅需要强大的计算能力,还要求对图像特征进行有效的提取与识别。随着深度学习技术的发展,特别是卷积神经网络(CNN)的广泛应用,图像分类的准确性和效率得到了极大的提升。经典网络结构如AlexNet、VGG和ResNet在各种图像分类任务中取得了显著的成果,为计算机视觉的发展奠定了坚实的基础。
本文将探讨计算机视觉与图像分类的技术原理、应用领域以及未来的发展方向。通过对这一领域的系统介绍,旨在为读者提供全面的理解,帮助他们掌握最新的技术动态,并认识到图像分类在现实世界中的重要性和广泛应用。
一、计算机视觉的基本概念
计算机视觉(Computer Vision)是一门研究如何使计算机“看懂”图像和视频,从而理解和处理视觉信息的科学。其目标是通过计算机来模拟人类视觉系统的功能,使计算机能够从图像或多维数据中获取有用信息,并做出相应的判断和决策。
1、定义与发展历史
计算机视觉涉及对数字图像的获取、处理、分析和理解,并从中提取高维数据以供进一步处理。它结合了计算机科学、人工智能、信号处理和神经科学等多个学科的知识。
计算机视觉的研究始于20世纪60年代,早期的研究主要集中在图像处理和模式识别上。随着计算能力的提升和算法的进步,计算机视觉逐渐扩展到更复杂的任务,如物体识别、场景理解和动作分析。21世纪以来,深度学习的兴起推动了计算机视觉的发展,使得许多视觉任务的性能显著提升。
2、主要研究方向与应用领域
计算机视觉有许多研究方向,每个方向都对应着不同的应用场景:
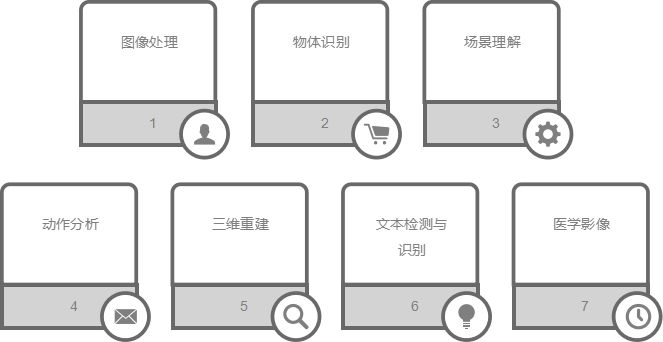
图像处理:包括图像的增强、恢复、分割和压缩等。应用于医学影像处理、卫星图像分析等领域。
物体识别:识别图像中的特定物体,如人脸识别、车牌识别等。在安全监控、身份验证等方面有广泛应用。
场景理解:从图像中提取场景信息,理解图像中的空间布局和物体关系。应用于自动驾驶、机器人导航等领域。
动作分析:分析视频中的人体动作和行为,用于运动分析、视频监控等。
三维重建:从二维图像恢复三维结构,应用于虚拟现实、增强现实、3D打印等领域。
文本检测与识别:从图像中检测并识别文本,应用于文档处理、车牌识别等。
医学影像:分析医学影像数据,用于疾病诊断和治疗规划。
3、计算机视觉的基本技术
图像获取:通过摄像头、扫描仪等设备获取数字图像。
图像预处理:对图像进行噪声去除、灰度化、二值化等处理,以提高图像质量。
特征提取:从图像中提取有用特征,如边缘、角点、纹理等。
模式识别:使用机器学习算法对提取的特征进行分类和识别。
深度学习:采用卷积神经网络(CNN)等深度学习模型,自动从图像中学习特征,提高分类和识别的精度。
通过以上技术,计算机视觉可以在多种复杂任务中取得优异的表现,推动了各行各业的技术进步和应用创新。
二、图像分类的技术原理
图像分类是计算机视觉中的一个基本任务,其目标是将输入图像分配到预定义的类别中。实现图像分类需要一系列步骤和技术,从数据收集到模型训练,再到最终的分类预测。以下是图像分类的基本流程和技术原理。
1、图像分类的基本流程
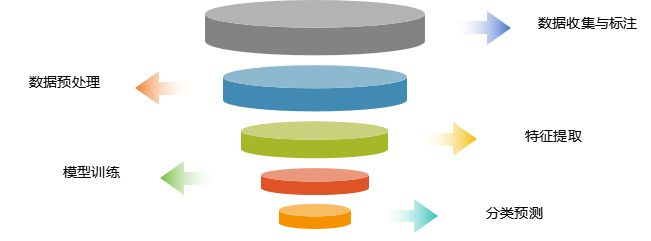
数据收集与标注
收集大量带有标签的图像数据,这是训练高效分类器的基础。
数据标注是指为每个图像分配正确的类别标签,通常需要人工参与。
数据预处理
图像缩放、裁剪、旋转等操作,以标准化输入图像。
数据增强(Data Augmentation):通过随机变化生成更多训练样本,提升模型的泛化能力。
特征提取
从图像中提取关键特征,可以使用手工设计的方法或深度学习方法。
手工设计的方法包括SIFT、HOG等。
深度学习方法通过卷积神经网络(CNN)自动学习图像特征。
模型训练
使用标注好的数据训练分类模型。
选择适当的损失函数和优化算法,逐步调整模型参数,以最小化分类错误。
分类预测
训练好的模型对新图像进行预测,输出图像所属的类别。
2、经典算法
线性分类器(如Logistic回归)
基于线性函数进行分类,适用于线性可分的数据。
算法简单,但对复杂图像数据的表现有限。
K近邻(K-Nearest Neighbors, KNN)
通过计算与训练样本的距离,将新图像归类到其最近的K个邻居的多数类别。
算法简单,但计算成本高,尤其在大规模数据集上。
支持向量机(Support Vector Machine, SVM)
通过找到最优分离超平面,实现数据分类。
适用于高维数据,但对大规模数据集训练时间较长。
3、深度学习在图像分类中的应用
卷积神经网络(CNN)的基本原理
CNN通过卷积层、池化层和全连接层对图像进行特征提取和分类。
卷积层:使用卷积核对图像进行局部扫描,提取特征图。
池化层:对特征图进行下采样,减少特征维度和计算量。
全连接层:将提取的特征进行分类,输出类别概率。
经典网络结构
LeNet:早期的CNN结构,主要用于手写数字识别。
AlexNet:2012年ImageNet竞赛的冠军网络,首次使用ReLU激活函数和Dropout技术。
VGG:使用较小的卷积核(3x3),增加网络深度,提高分类性能。
ResNet:引入残差连接,解决了深层网络的梯度消失问题。
迁移学习和预训练模型
在大规模数据集上预训练模型,然后在特定任务上进行微调。
通过迁移学习,可以在小数据集上取得良好的分类性能。
通过以上方法,图像分类在多个领域取得了显著的进展。
三、图像分类的实际应用
图像分类技术已经在多个行业和领域得到了广泛的应用,其强大的识别和分类能力帮助解决了许多实际问题。以下是一些主要的应用领域及其具体应用案例:
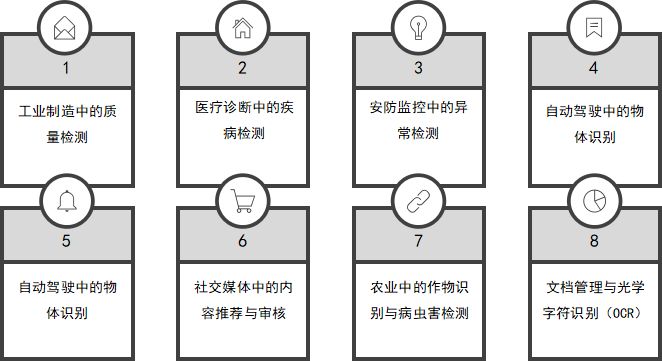
1、工业制造中的质量检测
产品质量控制:通过图像分类技术,自动检测生产线上的产品是否存在瑕疵或缺陷,如表面裂纹、颜色偏差等。
装配验证:检查产品的组装是否正确,确保各部件的位置和安装方式符合设计要求。
2、医疗诊断中的疾病检测
医学影像分析:利用图像分类技术分析X光片、CT扫描、MRI等医学影像,自动检测病变区域,如肿瘤、结节等。
病理图像分类:从病理切片图像中识别不同类型的细胞和组织,辅助病理医生进行诊断。
3、安防监控中的异常检测
人脸识别:通过图像分类技术识别人脸,应用于身份验证、出入管理等场景。
异常行为检测:分析监控视频中的人物行为,检测并报警潜在的异常或危险行为,如闯入、徘徊等。
4、自动驾驶中的物体识别
行人检测:识别道路上的行人,帮助自动驾驶系统做出避让决策,确保行车安全。
交通标志识别:识别道路上的交通标志,帮助自动驾驶系统理解和遵守交通规则。
车辆检测:识别周围车辆的位置和类型,辅助自动驾驶系统进行路径规划和避障。
5、社交媒体中的内容推荐与审核
图像内容分类:对用户上传的图像进行分类,推荐相关内容或广告,提升用户体验。
不良内容检测:识别并过滤不良或违规图像内容,如暴力、色情等,维护平台健康环境。
6、零售和电子商务
商品识别:通过图像分类技术识别商品类别,帮助用户快速找到所需商品。
库存管理:自动识别和分类仓库中的商品,提升库存管理效率。
7、农业中的作物识别与病虫害检测
作物识别:通过图像分类技术识别不同种类的作物,辅助农业生产和管理。
病虫害检测:识别作物上的病虫害,提供早期预警和防治建议,保障农业生产安全。
8、文档管理与光学字符识别(OCR)
文档分类:对扫描或拍摄的文档图像进行分类,提升文档管理和检索效率。
光学字符识别(OCR):从图像中提取并识别文本信息,用于电子化处理和数据输入。
图像分类技术在这些应用领域中展现了强大的潜力和广泛的应用前景。通过不断的发展和创新,图像分类技术将继续推动各行业的技术进步和应用创新。
四、挑战与未来发展方向
尽管图像分类技术取得了显著的进展,并在多个领域得到了广泛应用,但仍然面临诸多挑战。以下是当前图像分类技术面临的主要挑战及其未来的发展方向。
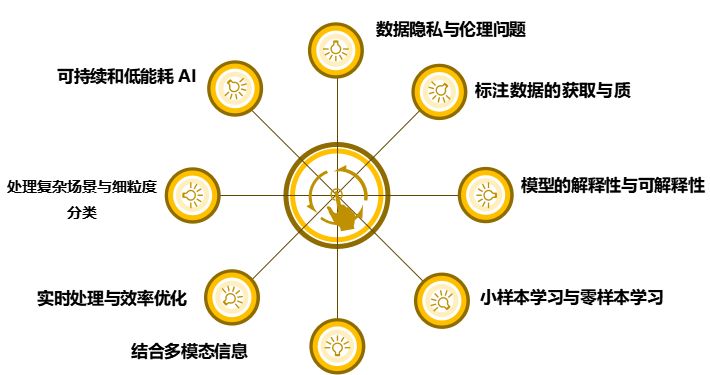
1、数据隐私与伦理问题
数据隐私:随着图像数据的广泛收集和使用,用户隐私保护成为一个重要问题。如何在保护用户隐私的同时,充分利用数据进行模型训练是一个亟待解决的难题。
伦理问题:在一些敏感领域,如人脸识别和医疗诊断,图像分类技术的使用涉及伦理问题。例如,如何防止技术的滥用,确保公平性和透明度。
2、标注数据的获取与质量控制
数据标注成本高:高质量的标注数据是训练图像分类模型的基础,但数据标注往往耗时耗力,成本高昂。
标注数据的质量控制:确保标注数据的准确性和一致性,对于提高模型的性能至关重要。如何自动检测和修正标注错误是一个重要的研究方向。
3、模型的解释性与可解释性
黑箱模型:深度学习模型,尤其是深层神经网络,通常被视为黑箱模型,难以解释其内部机制和决策过程。这对一些关键应用(如医疗诊断)带来了信任和法律上的挑战。
可解释性研究:未来需要更多研究专注于提升模型的可解释性,使其决策过程透明化,增加用户对技术的信任。
4、小样本学习与零样本学习
数据稀缺问题:在一些特定领域,如医学影像,获取大量标注数据困难且昂贵。如何在小样本或无样本的情况下,训练出高性能的图像分类模型,是一个重要的研究方向。
小样本学习:通过数据增强、迁移学习等技术,在小样本数据上训练模型。
零样本学习:利用现有知识和数据,推理和分类从未见过的类别。
5、结合多模态信息
单一模态的局限性:仅依赖图像信息进行分类,可能无法充分理解复杂场景。结合其他模态的信息(如文本、音频等),可以提供更丰富的上下文信息,提高分类精度。
多模态学习:未来的研究应更多地关注多模态学习,开发能够处理和融合多种类型数据的模型,提升整体性能。
6、实时处理与效率优化
计算资源需求高:深度学习模型,特别是大型卷积神经网络,训练和推理过程需要大量计算资源和时间。
效率优化:通过模型压缩、量化、硬件加速等技术,提高模型的运行效率,使其能够在边缘设备上实时处理图像。
7、处理复杂场景与细粒度分类
复杂场景识别:在实际应用中,图像通常包含复杂的背景、遮挡和多样化的对象,增加了分类的难度。
细粒度分类:细粒度分类需要区分具有细微差异的类别,如不同品种的花、鸟类等。这对模型的识别能力和精度提出了更高要求。
8、可持续和低能耗AI
环境影响:大规模训练深度学习模型需要大量的能源消耗,对环境产生影响。
低能耗AI:未来的研究需要关注如何在降低能耗的同时,保持模型的高性能,开发可持续的AI技术。
尽管图像分类技术在多个领域取得了显著的成就,但仍然面临诸多挑战。通过不断的技术创新和研究,我们可以克服这些挑战,进一步提升图像分类技术的性能和应用广度。未来,图像分类技术将在保护隐私、提高可解释性、优化效率、融合多模态信息等方面取得重要进展,推动各行各业的技术进步和应用创新。
结论
在当今信息技术迅猛发展的背景下,计算机视觉与图像分类技术正日益成为推动各行各业变革的重要力量。本文探讨了计算机视觉与图像分类的基本概念、技术原理、实际应用以及面临的挑战和未来发展方向。
首先,我们了解了计算机视觉的基本概念和发展历程,认识到其在多种应用场景中的重要性。接着,深入解析了图像分类的技术原理,从数据收集、预处理、特征提取到模型训练和分类预测,为读者提供了全面的技术背景知识。
在实际应用方面,我们看到图像分类技术已经在工业制造、医疗诊断、安防监控、自动驾驶、社交媒体、零售、农业等多个领域取得了显著成效。这些应用不仅提高了各行业的效率和准确性,还带来了全新的解决方案和商业模式。
然而,图像分类技术也面临诸多挑战,如数据隐私与伦理问题、标注数据的获取与质量控制、模型的解释性、小样本学习、结合多模态信息、实时处理与效率优化、处理复杂场景与细粒度分类以及低能耗AI等。解决这些挑战,需要科研人员和工程师们不断创新,探索新的方法和技术。
展望未来,图像分类技术将在以下几个方面取得重要进展:
隐私保护与伦理考量:开发更安全和透明的技术,保护用户隐私,确保技术的公平和合法使用。
数据标注自动化:通过自动化标注工具和技术,降低数据标注的成本和时间,提高标注质量。
可解释AI:增强模型的可解释性,使其决策过程透明化,增加用户对技术的信任。
小样本与零样本学习:通过数据增强、迁移学习和知识图谱等技术,提升小样本和零样本条件下的模型性能。
多模态融合:开发能够处理和融合多种类型数据的模型,提升整体分类性能。
效率优化与低能耗:优化模型结构和算法,利用硬件加速,降低计算资源消耗,实现实时处理。
总之,图像分类技术在未来将继续发展,并在各个领域发挥更加重要的作用。通过不断的技术创新和跨学科合作,我们可以克服当前的挑战,推动图像分类技术走向新的高度,为社会带来更多的福祉和价值。
