阅读量:0
文章目录
1. 概述
支持远程协作者之间的交互和沟通。然而,明确的表达是出了名的难以创建,主要是因为目前的大多数方法依赖于几何标记和为人脸建模的特征,而不是为风格化的头像建模的特征。为应对情感和表现力生成说话头像的挑战,我们构建了情感说话头像数据集(Emotional Talking Avatar Dataset),这是一个包含 6 个不同风格化角色以 7 种不同情绪说话的视频语料库。除了数据集,我们还发布了一种情感说话头像生成方法,能够操控情感。我们验证了数据集和方法在生成基于音频的木偶戏示例中的有效性,包括与最新技术的比较和用户研究。最后,讨论了该方法在 VR 中动画化头像的各种应用。
2. 背景介绍
未来元宇宙中的技术,用户利用风格化的头像来代表自己。然而,VR头戴显示器(HMD)通常会遮挡用户面部的很大一部分,限制了大多数现有视频驱动的面部动画方法的适用性。虽然当前的音频驱动说话头像技术在基于HMD的头像中介通信方面有所进展,但仍存在一些挑战。当代方法在生成与音频演讲完全同步的唇部动作方面表现出色,但它们往往忽略了面部情感。鉴于面部表情是人类交流的主要非语言模式,解决这一差距至关重要。一些研究人员已经探索了能够操控情感和强度的情感说话面部生成方法,但这些方法是为人脸量身定制的,而不是为风格化角色脸。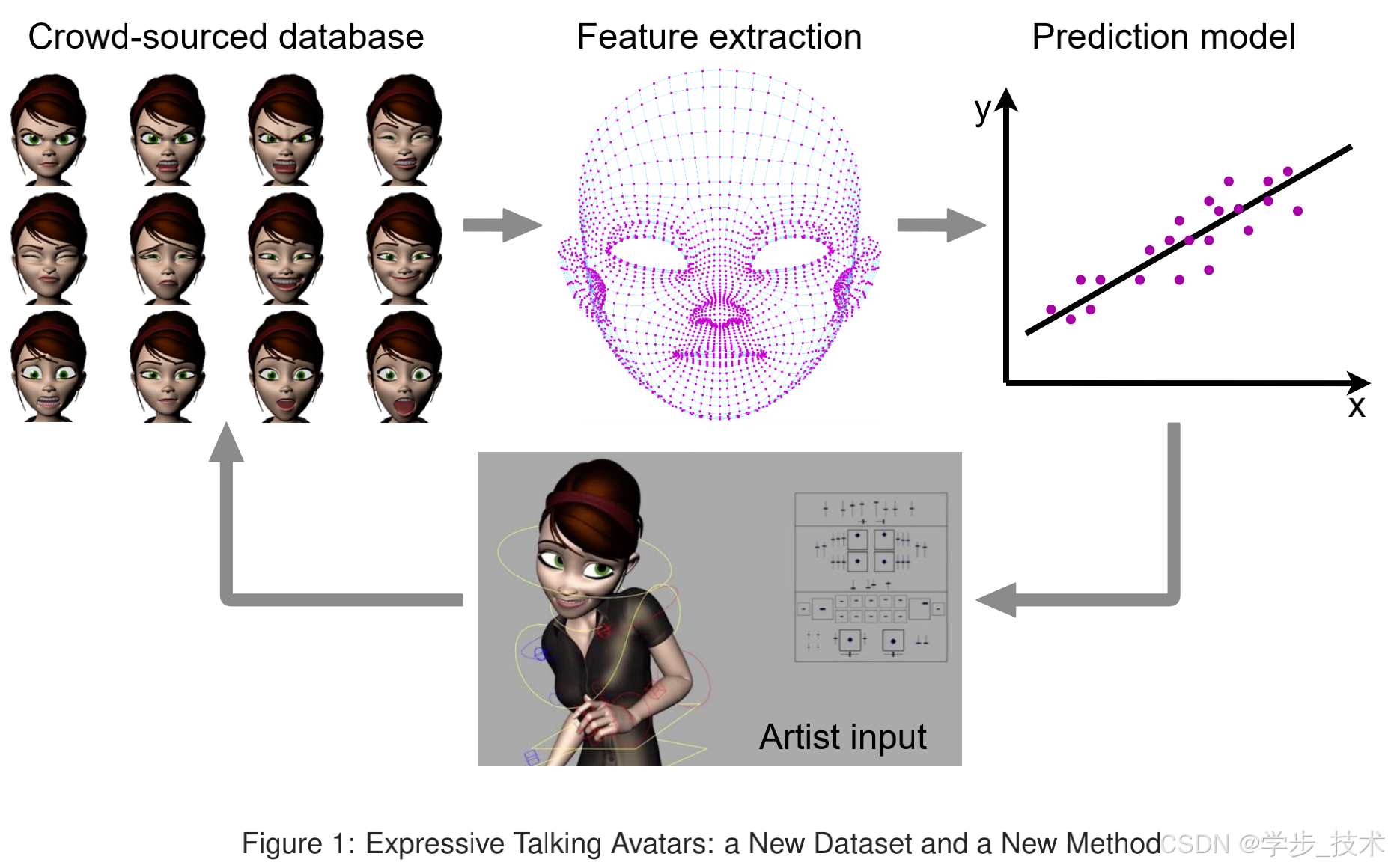
最近大量在说话头像生成任务中的进展涉及基于深度学习的方法,其中数据在性能中起着关键作用。我们认为缺乏高质量的3D骨架数据集是实现生动说话头像生成的主要障碍。如下一节所述,现有数据集主要是为人脸开发的,而不是风格化角色。Aneja等人开发了带有基本表情注释的风格化角色数据集。然而,他们的数据集仅包含标记的面部表情,缺乏带有同步唇部动作的视听动画片段。为解决这一差距,我们创建了情感说话头像数据集,包含六个头像以七种不同情绪讲话的动画。我们从现有的视听人类数据集中精心挑选了涵盖各种音素的情感一致的演讲文本。我们的内部专业动画师创作了恐惧、喜悦、中立、悲伤和惊讶的表情。
除了数据集,我们还提出了专为3D风格化角色设计的情感说话头像。这种方法首先利用预训练的HuBERT模型提取特征,精确生成控制口部动作的骨架参数。另一个情感分支用于生成无情感唇部动作的情感位移。通过简单的融合过程,我们创造了对音频输入和情感背景做出反应的情感响应说话头像。
我们通过测量情感识别、强度、同步性和自然性来验证我们的数据集和方法,这些因素对观众参与度至关重要。我们的数据集识别准确率为72%,与人类条件(从MEAD中选取的三种强度水平的视频和RAVDESS中‘正常’和‘强’强度水平的视频)平均准确率73.9%相当。结果还显示,我们的方法在唇同步质量和自然性方面与人类条件保持相同水平。此外,结果还显示,我们的说话头像生成方法显著提高了唇同步质量和自然性评分,同时在表情识别和强度方面与最先进的方法保持相同水平。这项研究做出了几项贡献,如下:
- 我们构建了一个高质量的情感说话头像数据集,这是第一个为风格化角色的3D骨架注释的情感视听语料库。
- 我们提出了一种新的情感说话头像生成方法,允许操控情感。
- 大量实验验证了数据集和我们富有表现力的头像生成方法,可以应用于未来的AR/VR/XR参考。

3. 数据集
3.1 设计标准
情感类别
我们使用了由Aneja等人定义的七种情感类别(愤怒、厌恶、恐惧、喜悦、悲伤、惊讶和中立)。这些类别在面部表情研究社区中被广泛认可,因为它们具有共识,并且涵盖了广泛的强度范围。此外,这些情感可以相互融合,创造出更多的表情。
语音语料库设计
对于音频语音内容,我们参考了MEAD和RAVDESS数据集,这些数据集包含演员表达各种情感的说话面部视频语料库。我们的选择过程涉及仔细挑选涵盖每个情感类别中所有音素的句子。每个情感类别中的句子被分为两部分:四个通用句子和七个情感特定句子。有关语音语料库的详细信息见表2.3。
3.2 数据采集
我们的内部专业艺术家逐帧精心制作动画剪辑,使用表2.3中列出的参考人类视频剪辑,并分析其关键动作和表情。他们创建详细的故事板,绑定角色,设置关键帧,并使用中间帧进行平滑过渡。特别注意复制面部表情,遵循《艺术家面部表情完整指南》的指导。有关面部表情及其特征的详细分类见表1。
4. 方法
4.1 概述
我们提出了一种面部动画方法,该方法通过输入音频和情感类别生成精确的唇部动作和表情。图3显示了系统的概述,该系统由三个基本组件组成。具体来说,我们首先使用预训练的HuBERT模型提取HuBERT特征,并引入Mou解码器以生成与口部区域相关的精确骨架参数。接下来,我们采用音频编码器和情感编码器,从MFCC中提取音频特征,并将情感输入到设计的Emo解码器中,以预测情感参数,这些参数进一步与唇部参数融合,以控制3D风格化角色在讲话时的情感。最后,通过Maya的渲染过程生成生动的动画。
4.2 架构
在网络架构中,有五个子网络:预训练的HuBERT编码器Eh、口部解码器Dm、音频编码器Ea、情感编码器Ee和情感解码器De。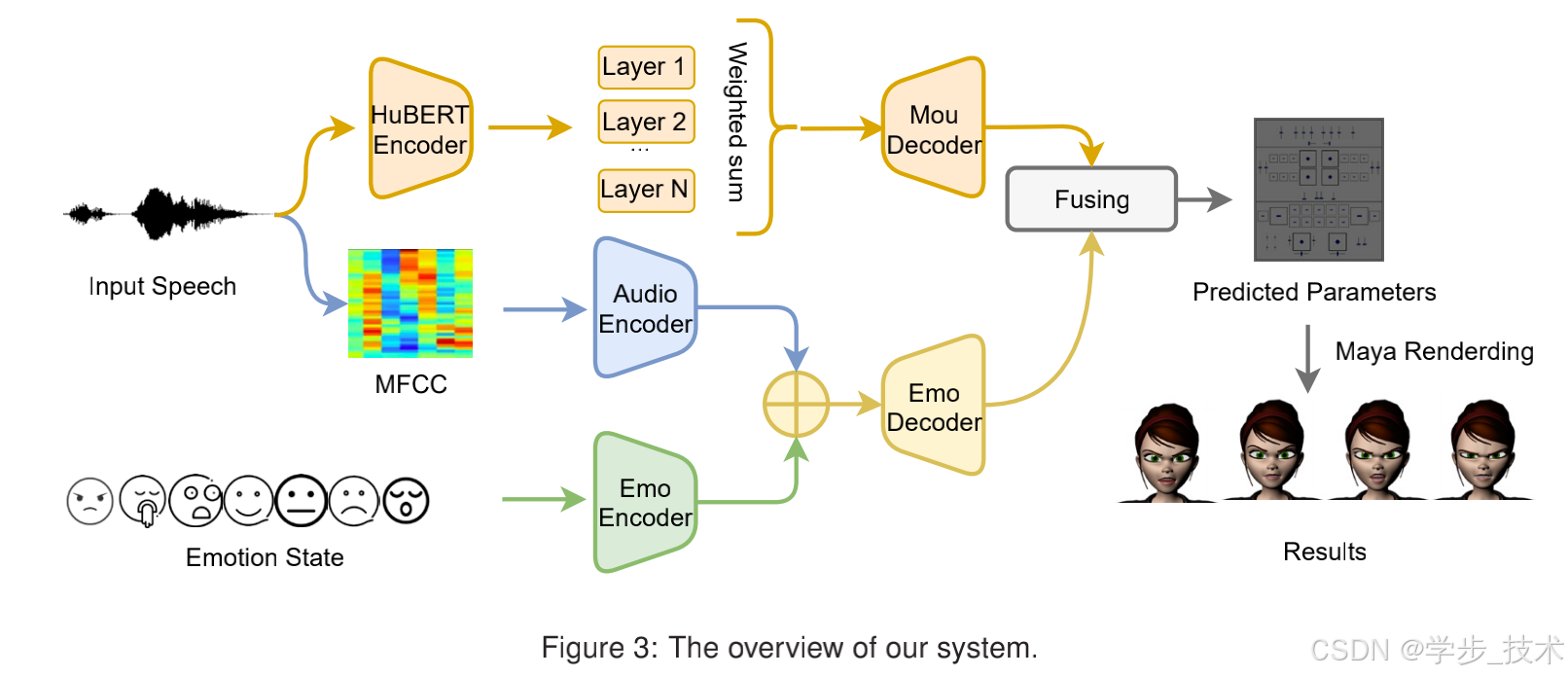
HuBERT编码器
为了充分利用音频中包含的信息,我们采用预训练的HuBERT模型来提取特征。我们预测N个隐藏层,这些层加权求和后作为后续输入的基础。得到的HuBERT特征fh可以表示为:
f h = ∑ i = 1 N ( α i h i ) , ∑ i = 1 N α i = 1 f_h = \sum_{i=1}^N (\alpha_i h_i) , \sum_{i=1}^N \alpha_i = 1 fh=∑i=1N(αihi),∑i=1Nαi=1
口部解码器
口部解码器由两层一维卷积神经网络和两层双向LSTM网络组成。前者负责将提取的HuBERT特征从50Hz下采样到25Hz,而后者能够将特征解码为有意义的潜在表示,从而预测唇部区域的骨架参数序列。
音频编码器
考虑到表情与节奏和节拍的相关性,我们从提供的输入音频信号中提取梅尔频率倒谱系数(MFCC),并使用一秒的时间滑动窗口配对视频帧和音频信号。音频帧采样率和视频帧速率均设置为25。随后,我们应用音频编码器,音频编码器由卷积神经网络(CNN)和多层感知器(MLP)组成,处理28×12维的音频特征输入并获得所需的音频特征。
情感编码器
我们首先将情感标签编码为独热向量e,并将其输入情感编码器。情感编码器利用两层全连接(FC)神经网络和LeakyReLU激活,将独热向量映射到情感嵌入。这个嵌入在每个时间步重复。
情感解码器
基于音频的时间特性,我们设计了一个长短期记忆(LSTM)网络和一个全连接层,将提取的音频特征和情感嵌入映射到骨架参数。我们模型中的LSTM由三层60个节点和100个时间步组成。这样可以更好地捕捉音频信号和骨架参数之间的顺序关系。
4.3 目标函数
公式上,给定一个音频 a = { a ( 1 ) , . . . , a ( T ) } a = \{a(1),...,a(T)\} a={a(1),...,a(T)} 和输入的情感条件e,我们可以分别生成预测的口部骨架参数 y ^ m = { y ^ m ( 1 ) , . . . , y ^ m ( T ) } \hat{y}_m = \{ \hat{y}_m(1),..., \hat{y}_m(T) \} y^m={y^m(1),...,y^m(T)} 和表情骨架参数 y ^ e = { y ^ e ( 1 ) , . . . , y ^ e ( T ) } \hat{y}_e = \{ \hat{y}_e(1),..., \hat{y}_e(T) \} y^e={y^e(1),...,y^e(T)}:
[ y ^ m ( t ) , h ( t ) , c ( t ) ] = D m ( E h ( a ( t ) ) , y ^ m ( t − 1 ) , h ( t − 1 ) , c ( t − 1 ) ) [\hat{y}_m(t),h(t), c(t)] = D_m(E_h(a(t)), \hat{y}_m(t−1),h(t−1),c(t−1)) [y^m(t),h(t),c(t)]=Dm(Eh(a(t)),y^m(t−1),h(t−1),c(t−1)),
[ y ^ e ( t ) , h ( t ) , c ( t ) ] = D e ( E a ( a ( t ) ) , E e ( e ) , y ^ e ( t − 1 ) , h ( t − 1 ) , c ( t − 1 ) ) [\hat{y}_e(t),h(t), c(t)] = D_e(E_a(a(t)),E_e(e), \hat{y}_e(t−1),h(t−1),c(t−1)) [y^e(t),h(t),c(t)]=De(Ea(a(t)),Ee(e),y^e(t−1),h(t−1),c(t−1))
其中,h(t), c(t)分别表示时间t处的LSTM单元的隐藏状态和细胞状态,T指视频帧数。然后,我们融合预测的参数以获得最终结果 y ^ ( t ) \hat{y}(t) y^(t):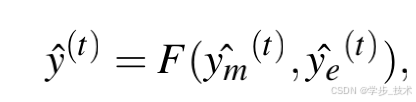
为了优化网络,我们定义了L2损失函数和Soft-DTW损失。Soft-DTW是vanilla动态时间规整(DTW)的变体,它解决了vanilla DTW中不可反向传播梯度的问题。DTW旨在优化序列数据的对齐并测量其相似性。最近的研究突出了DTW在处理不等长序列数据时的优越对齐能力。借鉴这些发现,我们将Soft-DTW损失集成到我们的工作中,以解决数据集中音频和真实骨架参数之间的潜在同步问题。由于设备、传输和存储不一致导致现有数据集中普遍存在的同步挑战在3D数据集中因动画师错误而被放大。因此,与传统的MSE损失相比,使用Soft-DTW损失在增强音频唇部同步方面具有显著优势,这在下一节中得到了验证。我们还引入了帧间连续性损失,以解决抖动问题。给定真实的骨架参数y,总损失函数L可以表示为: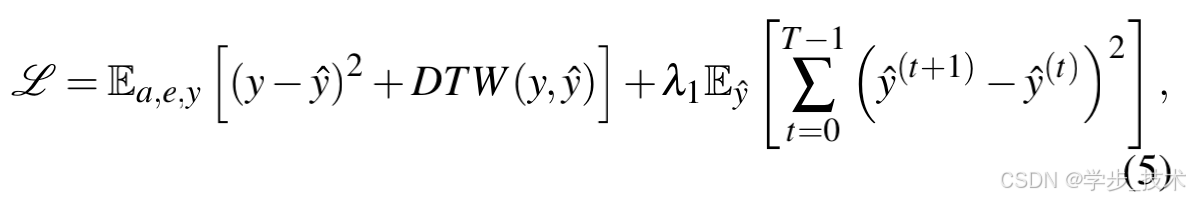
其中,GT y表示真实的骨架参数,特别是指导我们3D角色执行预期动作的重要因素。从我们构建的数据集中获得的,我们将其作为音频驱动动画任务的标签。因此,我们通过测量预测值 y ^ \hat{y} y^与真实值y之间的差异来计算损失,并用它来训练我们的网络。
5. 实验评测
5.1 用户研究
我们从上海交通大学招募了25名参与者参与本研究的各个方面。20名参与者完成了任务1,另外5名参与者被指定完成任务2。参与者的平均年龄为22岁,年龄范围在19至24岁之间,其中12人为男性。他们并不知道实验的目的。
任务1:为了评估我们的数据集,我们生成了使用数据集中包含的3D面部骨骼动画片段,并附有相应的骨骼参数。我们将数据集分为四组(见表2.3中的编号)。
任务2:为了评估我们的方法,我们随机选择了75%的数据集来训练我们的模型和EVP \cite{evp},并使用其余的数据集作为地面真值。然后,我们运行我们的方法和EVP方法来创建主要角色表情的7个动画片段,并应用多角色适配网络 \cite{evp} 将表情转移到不同的5个风格化角色上。
任务1:实验涉及7个角色(Human, Mery, Bonnie, Ray, Malcolm, Rose和Miosha) × \times × 7种情绪(中性、愤怒、悲伤、恐惧、厌恶、快乐和惊讶) × \times × 2个句子(常见句子和情绪相关句子) × \times × 4组数据集的混合设计。对于跟踪方法采用被试间设计,而对于角色、情绪和跟踪方法则采用被试内设计。
每个参与者参与98次试验,评估人类表情和6个角色表情:7 × \times × (7种情绪 × \times × 2种句子) = 98次试验。因此,总试验次数为1960次。
任务2:实验采用6个角色(Mery, Bonnie, Ray, Malcolm, Rose和Miosha) × \times × 7种情绪(中性、愤怒、悲伤、恐惧、厌恶、快乐和惊讶) × \times × 3种方法的被试内设计。
每个参与者参与126次试验,评估生成的主要角色表情和5个不同风格化角色的表情转移结果:6 × \times × (7种情绪 × \times × 3种捕捉方法) = 126次试验。总试验次数为630次。为了防止疲劳或顺序效应,视频片段以随机顺序呈现给参与者。
参与者首先收到一份信息表,并被要求签署相应的同意书。然后他们被引导观看动画片段并回答四个问题:
- “角色表现的是什么情绪?” 参与者选择以下词语之一:中性、愤怒、悲伤、恐惧、厌恶、快乐、惊讶或其他。
- “角色表现的情绪有多强烈?” 参与者在1到7的范围内评估强度,其中1表示“完全没有”,7表示“非常强烈”。
- “口型动作与语言同步吗?” 参与者在1到7的范围内评估口型同步性,其中1表示完全不同步,7表示非常同步。
- “角色的整体自然程度如何?” 参与者在1到7的范围内评估自然程度,其中1表示“完全不自然”,7表示“非常自然”。
每个参与者完成一次练习试验,在此期间他们可以提问,然后继续进行测量试验。参与者获得50元人民币的报酬,整个实验大约持续30分钟。研究方案获得了上海交通大学研究伦理委员会的批准。
对于统计分析,我们对视频进行了单独的重复测量方差分析(ANOVA),检查与识别、强度、同步性和自然性相关的结果。没有异常值,并且数据在每种条件下均呈正态分布,通过箱线图和Shapiro–Wilk检验( p > 0.05 p > 0.05 p>0.05)确认。我们进行了Mauchly’s检验以验证数据的球形性,每当它显著时,我们采用Greenhouse-Geisser校正并标注星号“*”。事后检验使用Bonferroni检验进行均值比较。
对于情绪识别,将响应转换为“1”(正确)或“0”(错误)并在刺激重复中取平均值。图5(a)显示愤怒( M = . 921 , S E = . 014 M = .921, SE = .014 M=.921,SE=.014)、快乐( M = . 925 , S E = . 019 M = .925, SE = .019 M=.925,SE=.019)、中性( M = . 886 , S E = . 027 M = .886, SE = .027 M=.886,SE=.027)和悲伤( M = . 836 , S E = . 034 M = .836, SE = .034 M=.836,SE=.034)的准确率较高,而厌恶( M = . 407 , S E = . 041 M = .407, SE = .041 M=.407,SE=.041)和恐惧( M = . 375 , S E = . 05 M = .375, SE = .05 M=.375,SE=.05)对用户来说非常难以察觉。我们还观察到角色表情识别的准确率有时可能高于人类,这可能是因为角色具有更简单的几何结构,风格化使表情更容易识别。
我们比较了7种情绪在7个角色中的平均得分。发现角色的主效应显著, F ( 6 , 114 ) = 3.215 , p = . 006 F(6,114) = 3.215, p = .006 F(6,114)=3.215,p=.006,角色 × \times × 情绪的交互效应也显著, F ( 36 , 684 ) = 3.957 , p < . 001 F(36,684) = 3.957, p < .001 F(36,684)=3.957,p<.001。这表明不同角色的识别得分在不同情绪下表现不同。
我们对表情识别的初步结果显示,情绪的主效应显著, F ( 3.79 , 72.003 ) = 53.139 , p < . 001 ∗ F(3.79,72.003) = 53.139, p < .001* F(3.79,72.003)=53.139,p<.001∗。因此,我们检查了参与者对七种表情类别的评分。图4展示了每个表情类别的感知表情识别的混淆矩阵。在每个子图中,对于给定的行(例如愤怒),列显示参与者对相应表情类别的一致性百分比(在所有感知的人类/角色愤怒表情中平均)。
我们角色的强度评分普遍较高,这在夸张的卡通动画中是预期的。图5(b)显示7种情绪在7个角色中的平均强度评分。所有角色的中性( M = 3.461 , S E = . 398 M = 3.461, SE = .398 M=3.461,SE=.398)的平均得分显著低于其余情绪的平均得分。
我们发现角色的主效应、情绪的主效应以及角色 × \times × 情绪的交互效应均显著, F ( 1.963 , 37.288 ) = 8.515 , p < . 001 ∗ F(1.963,37.288) = 8.515, p < .001* F(1.963,37.288)=8.515,p<.001∗, F ( 1.874 , 35.606 ) = 27.03 , p < . 001 ∗ F(1.874,35.606) = 27.03, p < .001* F(1.874,35.606)=27.03,p<.001∗, F ( 36 , 684 ) = 3.386 , p < . 001 F(36,684) = 3.386, p < .001 F(36,684)=3.386,p<.001,分别。这表明不同角色的强度得分在不同情绪下表现不同。
我们查看了7种情绪在7个角色条件下的同步性和自然性评分。然而,在角色、情绪和角色 × \times × 情绪的交互效应方面,没有发现统计学显著的效果,因此我们没有包括同步性和自然性的图结果。
5.2 我们方法的结果
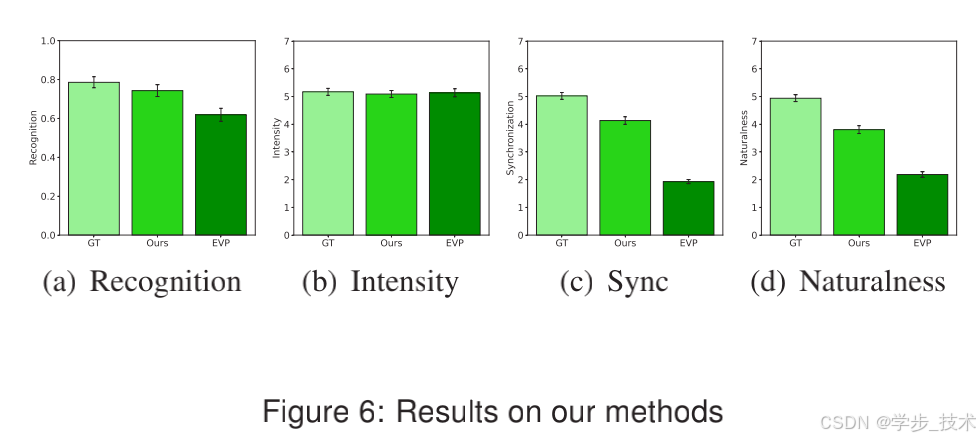
\textbf{识别} 图6(a)显示了三种生成方法在六个风格化角色中的平均识别得分比较。所有角色的平均得分对于GT( M = . 786 , S E = . 046 M = .786, SE = .046 M=.786,SE=.046)和我们的方法( M = . 743 , S E = . 033 M = .743, SE = .033 M=.743,SE=.033)略高于EVP( M = . 619 , S E = . 03 M = .619, SE = .03 M=.619,SE=.03)的平均得分。我们发现生成方法的主效应显著, F ( 2 , 8 ) = 5.056 , p = . 038 F(2,8) = 5.056, p = .038 F(2,8)=5.056,p=.038。然而,Bonferroni事后比较没有发现这些条件之间的显著效应。
\textbf{强度} 图6(b)显示了三种生成方法在六个风格化角色中的平均强度得分比较。所有角色的平均得分分别为GT( M = 5.171 , S E = . 603 M = 5.171, SE = .603 M=5.171,SE=.603)、我们的方法( M = 5.09 , S E = . 62 M = 5.09, SE = .62 M=5.09,SE=.62)和EVP( M = 5.133 , S E = . 668 M = 5.133, SE = .668 M=5.133,SE=.668)。结果显示主效应, F ( 1.021 , 4.085 ) = . 056 , p = . 83 ∗ F(1.021,4.085) = .056, p = .83* F(1.021,4.085)=.056,p=.83∗。
\textbf{同步性} 图6©显示了三种生成方法在六个角色中的平均同步性评分。所有角色的平均得分对于GT( M = 5.024 , S E = . 703 M = 5.024, SE = .703 M=5.024,SE=.703)和我们的方法( M = 4.133 , S E = . 633 M = 4.133, SE = .633 M=4.133,SE=.633)显著高于EVP( M = 2.857 , S E = . 336 M = 2.857, SE = .336 M=2.857,SE=.336),表明我们的生成方法和EVP在口型动作方面存在显著差异。我们发现生成方法的主效应显著, F ( 2 , 8 ) = 8.609 , p = . 01 F(2,8) = 8.609, p = .01 F(2,8)=8.609,p=.01。Bonferroni事后比较表明EVP与GT ( p = . 016 p = .016 p=.016) 和EVP与我们的生成方法 ( p = . 026 p = .026 p=.026) 之间有显著差异。
\textbf{自然性} 图6(d)显示了三种生成方法在六个风格化角色中的平均自然性评分比较。所有角色的平均得分分别为GT( M = 4.99 , S E = . 619 M = 4.99, SE = .619 M=4.99,SE=.619)、我们的方法( M = 4.952 , S E = . 448 M = 4.952, SE = .448 M=4.952,SE=.448)和EVP( M = 3.905 , S E = . 454 M = 3.905, SE = .454 M=3.905,SE=.454)。结果显示主效应, F ( 2 , 8 ) = 5.616 , p = . 03 F(2,8) = 5.616, p = .03 F(2,8)=5.616,p=.03,并且Bonferroni事后比较表明GT与EVP ( p = . 04 p = .04 p=.04) 之间存在显著差异。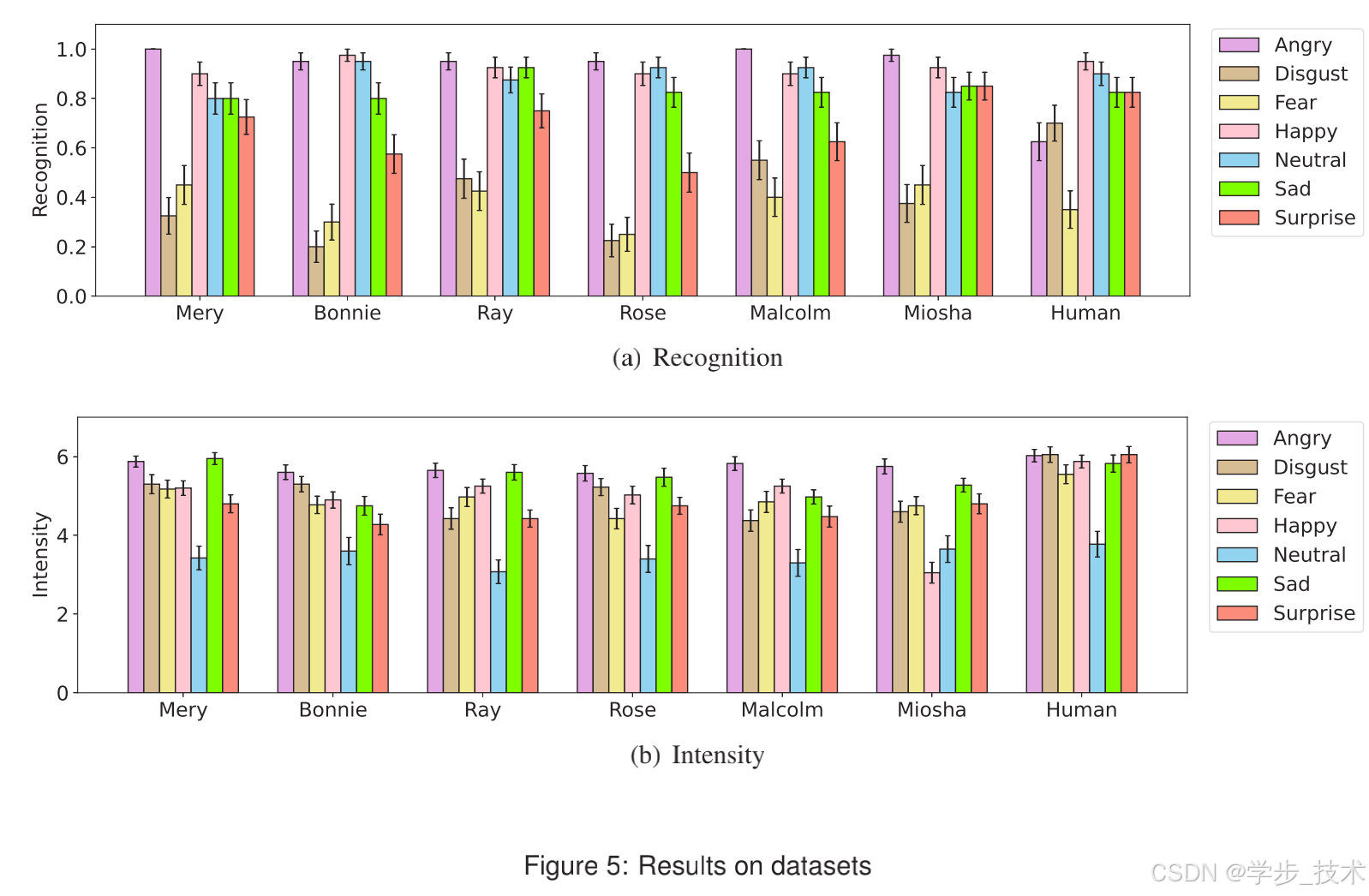
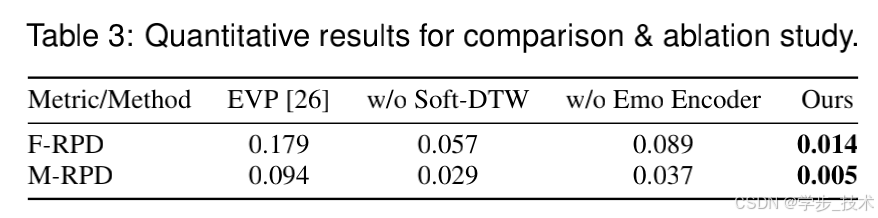
5.3 比较与消融研究
我们引入了两个新指标:面部装配参数距离(F-RPD)和口部装配参数距离(M-RPD),用于计算不同方法(EVP、去除 Soft-DTW、去除 Emo Encoder 和我们的方法)生成的面部和口部装配参数与真实值(GT)之间的距离。EVP \cite{26} 处理了与我们方法相同的任务。在消融研究中,我们用均方误差(MSE)损失替代 Soft-DTW 损失,标记为“去除 Soft-DTW”。“去除 Emo Encoder”指的是我们框架中去除 Emo Encoder 的版本,它生成的是中性面孔,而不包含任何表情。表 3 的结果表明,Soft-DTW 损失和我们框架中的情感分支在实现嘴唇同步和表情生成中发挥了重要作用。