
阅读量:0
前言
本文介绍激光雷达与相机进行多层次融合,包括数据级融合、特征级融合和BEV级融合。
融合后的BEV特征可以支持不同的任务头,包括语义分割、实例编码和方向预测,最后进行后处理生成高清地图预测,它是来自ICRA 2024的。
会讲解论文整体思路、模型框架、论文核心点、损失函数、实验与测试效果等。
论文地址:SuperFusion: Multilevel LiDAR-Camera Fusion for Long-Range HD Map Generation
代码地址:https://github.com/haomo-ai/SuperFusion

一、模型框架
SuperFusion不仅支持30米内的短距离高清地图预测,同时还支持长达90米的长距离高清地图预测,供给下游路径规划和控制任务,提高自动驾驶的平稳性和安全性。
SuperFusion的模型框架,如下图所示:

- 图像分支,输入图像数据、稀疏点云图。提取图像特征,点云特征。
- 图像分支,通过图像数据和点云特征,进行深度估计。然后通过深度特征和图像特征,生成视锥特征,经过池化处理,生成图像BEV特征。
- 激光雷达点云分支,输入点云数据,经过主干网络提取特征。
- 激光雷达点云分支,通过融合图像特征,图像引导远距离激光雷达BEV特征预测。
- BEV对齐与特征融合,将相机和激光雷达的BEV特征结合起来。
- BEV特征后面接各种任务头,比如BEV语义分割、实例检测、方向预测等。
二、多层次数据融合
原始的激光雷达和相机数据具有不同的特点
- 激光雷达数据提供准确的3D结构信息,但存在无序和稀疏的问题。
- 摄像头数据则紧凑,能够捕捉环境的更多上下文信息,但缺少深度信息。
将相机和激光雷达数据融合为三个层次,以补偿这两种模态的不足并利用它们的优点:
- 数据级融合,图像深度估计中,加入LiDAR的稀疏深度信息,提高图像深度估计的准确性
- 特征级融合,使用图像特征,通过交叉注意力机制来指导激光雷达特征,实现长距离激光雷达BEV特征的预测
- BEV级融合,将相机和激光雷达BEV特征对齐,生成融合BEV特征
三、论文主要贡献
多层次激光雷达-摄像头融合网络的创新设计:该设计充分利用了激光雷达和摄像头两种模态的信息,生成高质量的融合BEV特征,为不同的任务提供支持。这种多层次融合策略的核心优势在于其能够综合各种传感器提供的数据,从而在细节和准确性方面提供了质的提升。
首次实现长距离HD地图生成:据作者所知,他们的工作是首次实现长达90米的长距离HD地图生成。这一创新对于自动驾驶的下游规划任务具有重大意义,因为它极大地扩展了自动驾驶系统的感知和预测范围,从而有助于提高自动驾驶车辆的安全性和效率。
在短距离和长距离HD地图生成方面超越现有最先进方法:SuperFusion在生成高清晰度(HD)地图的短距离和长距离范围内都显著优于现有的融合方法。这一点特别重要,因为它不仅显示了该方法在技术上的进步,还证明了它在实际应用中的可行性和效用,尤其是在需要精确长距离感知的自动驾驶场景中。
发布代码和新数据集:作者不仅提出了一种创新的技术方法,还公开了代码和一个新的用于评估长距离HD地图生成任务的数据集。
下面是SuperFusion自采集的数据集示例,但目前还没看到公开

四、数据级融合——图像深度估计(融合点云数据)
原始的图像转为BEV视图,遵循常规LSS思想,需要对每个像素进行深度估计。
相比现有深度估计方法,LSS和CaDDN存在显著差异。
- LSS方法虽然也使用了激光雷达的深度信息,但其深度预测仅由语义分割损失隐式监督,精度不足。
- 而CaDDN虽然利用了激光雷达深度进行监督,但没有将激光雷达作为输入,限制了深度估计的鲁棒性。
SuperFusion的深度估计方法:
- 不仅使用了密集激光雷达深度图像进行监督,还将稀疏深度图作为附加通道并入RGB图像。
- 这种设计使得网络能够更有效地利用激光雷达和摄像头数据的互补信息,提高了深度估计和HD高清地图生成的准确性和可靠性。
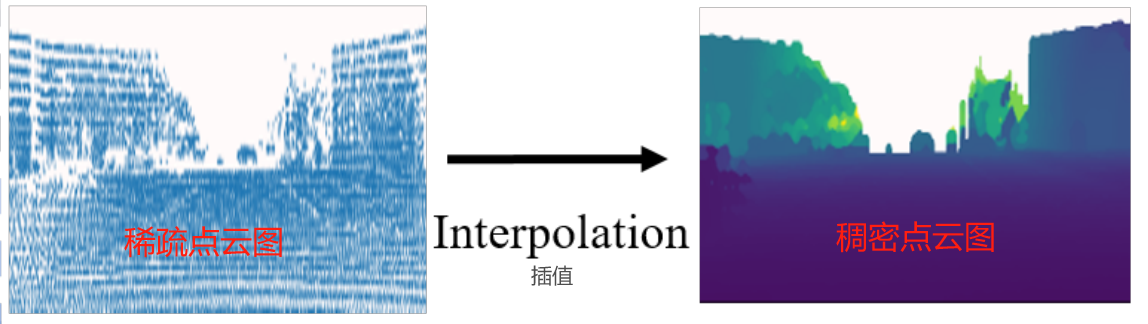
下面是SuperFusion进行图像深度估计的要点:
原始数据融合:首先,在原始数据层面,通过将激光雷达数据的深度信息融合到摄像头特征中来协助特征的BEV空间映射。这一步骤通过投影3D激光雷达点云到图像平面上,生成与RGB图像对应的稀疏深度图像,解决了摄像头数据缺乏深度信息的问题。
图像双分支网络:摄像头端采用双分支网络设计。第一分支提取2D图像特征,第二分支则连接一个深度预测网络,估算出每个元素的深度分布。通过这种结构,能够更好地估计深度信息,为生成密集深度图提供基础。
生成密集深度图作为标签:在稀疏深度图上插值生成密集深度图,此方法通过将每个像素的深度值离散化到深度分箱中,然后使用one-hot编码向量对深度预测网络进行监督,从而改善深度估计的准确性。
特征网格生成:最终,通过密集深度图和2D特征的外积生成最终的视锥(frustum)特征网格。这个特征网格能够支持不同的任务头,如语义分割、实例嵌入和方向预测,为生成HD高清地图预测提供数据支持。
公式版理解图像特征与深度特征融合:
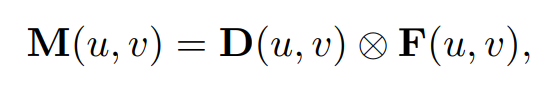
- 其中,M是指最终的视锥特征网格、(u,v)是指像素位置、D是指深度分布特征、F是指图像特征。
- ⊗表示外积操作,它用于结合两个向量D和F,生成最终的视锥特征网格M。
- 外积操作允许这两个向量的信息在每个像素位置相互补充,从而产生一个包含深度和视觉特征的综合表示。
各个特征的维度:
- 图像特征
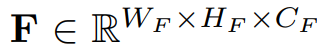
- 深度分布特征
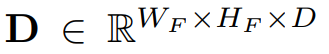
- 视锥特征

- BEV特征
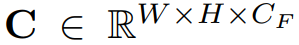
五、特征级融合——远距离激光雷达BEV特征预测(融合图像特征)
如下图所示,激光雷达通常在地面平面上具有较短的有效范围,而摄像头可以看到更远的距离。

这种差异是因为激光雷达通过发射激光束,并测量反射回来的时间来确定对象的距离和形状,而摄像头通过捕捉光线形成图像,能够覆盖更大范围的视野。
通过融合图像特征,使得图像引导激光雷达远距离BEV特征预测,使用交叉注意力机制实现的。
- 激光雷达分支:用PointPillars和动态体素化作为点云编码器,生成每个点云的激光雷达BEV特征。由于激光雷达数据只包含一定范围内(通常约30米)的地面平面信息,这导致许多激光雷达BEV特征编码了大量的空白空间。
- 图像辅助预测:与激光雷达相比,摄像头能够覆盖更远的地面区域。因此,提出了一个预测模块,利用图像特征来预测激光雷达分支中未见区域的地面。这一预测模块是一个编解码器网络,通过卷积层将原始BEV特征L压缩到瓶颈特征B,然后使用交叉注意力机制来动态捕获B和前视图像特征F之间的关联。
融合的思路框架,如下图所示:
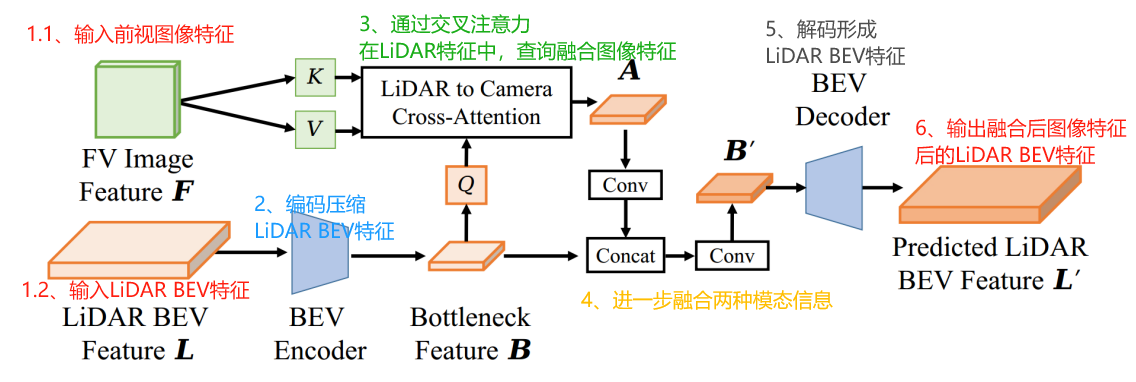
- 交叉注意力机制:用三个全连接层分别:将压缩后的LiDAR BEV特征B转换为查询Q,图像特征F转换为键K和值V。
- 然后计算Q和K的内积,表示激光雷达BEV中每个体素与其对应摄像头特征之间的相关性。
- 通过softmax操作归一化这个矩阵,然后与V相乘,得到聚合特征A。
- 特征融合:最后,将通过交叉注意力得到的聚合特征A通过卷积层处理以减少通道数,与压缩后的LiDAR BEV特征B进行拼接,再应用另一个卷积层,最终生成激光雷达BEV特征L′。
交叉注意力用公式表示为:
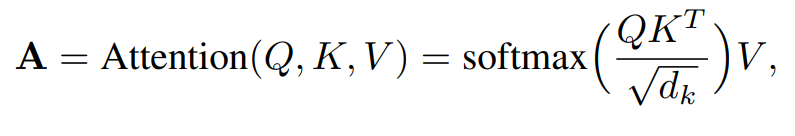
公式解析如下:

六、BEV级融合——多模态BEV对齐与特征融合
BEV对齐与特征融合的思路流程,如下图所示,将摄像头和激光雷达的BEV特征有效地结合起来,以改善长距离LiDAR BEV特征的预测。

输入特征:模块接收两种类型的BEV特征:摄像头BEV特征C和预测的LiDAR BEV特征L′。摄像头BEV特征来自图像特征和深度估计特征,而预测的LiDAR BEV特征则是通过之前描述的图像引导的LiDAR BEV预测方法得到的。
对齐的需求:由于深度估计误差和外部参数的不准确,从摄像头和激光雷达分支得到的BEV特征通常存在错位。直接连接这两种BEV特征会导致性能下降。为了解决这一问题,设计了一个BEV对齐和融合模块来改善特征的对齐,并提高整体预测性能。
特征对齐:使用流场Flow Field Δ来对摄像头BEV特征C进行空间变换,以对齐到LiDAR BEV特征的参考框架,生成对齐后的摄像头BEV特征C′。这一步骤是关键,因为它确保了两种类型的特征在空间上的一致性,从而使得融合更加有效。
特征融合:对齐后的摄像头BEV特征C′和预测的LiDAR BEV特征L′通过拼接Concat操作结合在一起,然后通过卷积层(Conv)、批标准化(BN)和ReLU激活函数处理,以融合这些特征并提取有用的信息,生成融合后的BEV特征。
输出:最终的融合BEV特征,可以被用作下游任务,例如语义分割、方向预测和物体检测的输入,进一步处理以生成更准确的BEV地图。
通过流场Δ对齐摄像头的BEV特征C到激光雷达的BEV特征L′,用公式表示:
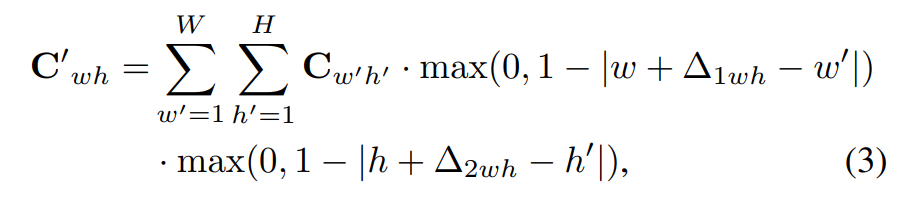
通过对每个像素位置进行变形操作来完成的,采用双线性插值的方式。
以下是公式各部分的解释:

七、损失函数
SuperFusion损失函数由四部分组成,考虑深度估计、语义分割、实例嵌入和方向预测损失。总体损失函数,如下所示:
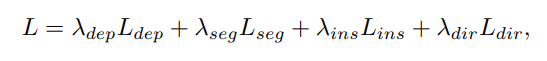
语义分割:使用交叉熵损失来指导语义分割的学习。
方向预测:将方向分为36个等分的类别,覆盖360度,使用交叉熵损失进行优化。这种离散化处理允许模型以分类问题的形式来预测车道方向。
深度预测:采用焦点损失Focal Loss进行优化,其中γ=2.0。焦点损失用于解决深度预测中的不平衡问题,增强模型对难以预测或少数类样本的关注。
实例嵌入:实例嵌入预测的损失定义为方差损失和距离损失的组合,通过参数α和β加权。
其中,实例嵌入的损失公式如下所示:
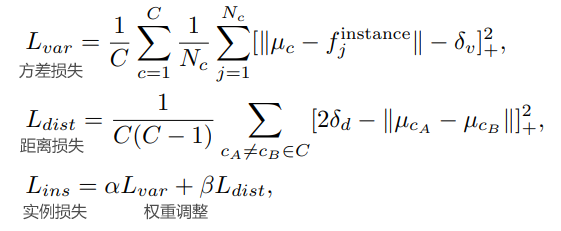

八、模型细节信息
模型架构设计:
摄像头分支主干网络:采用ResNet-101作为摄像头分支的主干网络。ResNet-101是一个深度残差网络,广泛用于图像识别和处理任务中,提供了强大的特征提取能力。
激光雷达(LiDAR)分支骨干网络:选择PointPillars作为LiDAR分支的骨干网络。PointPillars是专门为点云数据设计的网络,能有效处理三维空间信息。
深度估计:对DeepLabV3进行了修改,使其能够生成像素级别的深度箱概率分布,用于深度估计。DeepLabV3是一个语义分割网络,这里的修改让它能够适应深度预测任务。
训练细节:
预训练与初始化:摄像头分支的DeepLabV3骨干网络使用在MS-COCO数据集上预训练的模型进行初始化,其余部分随机初始化。这有助于加速训练过程并提高模型性能。
图像尺寸和点云体素化:图像尺寸设置为256×704,点云数据以0.15m的分辨率体素化。这样的设置平衡了处理速度和精度。
BEV HD地图范围:设置BEV HD地图的范围为0,900,90m × −15,15−15,15m,对应的深度箱间隔设为2.0–90.0m,间隔为1.0m。这个范围和深度分辨率适应了车辆周围环境的观测需求。
九、实验测试与效果
在nuScenes数据集测试,下面是不同方法的高精地图预测结果。

- 红色汽车代表汽车的当前位置。
- 每张地图相对于汽车的垂直长度为 90 m。
- 不同的颜色表示不同的高精地图元素实例。
- 对于地面真实高清地图,绿色是车道边界,红色是车道分隔线,蓝色是人行横道。
nuScenes 数据集上高精地图语义分割的 IoU 分数(%)

- IoU:交并比越高越好
- C:相机
- L:激光雷达
nuScenes 数据集上转动场景的高清地图生成的 IoU 分数 (%)
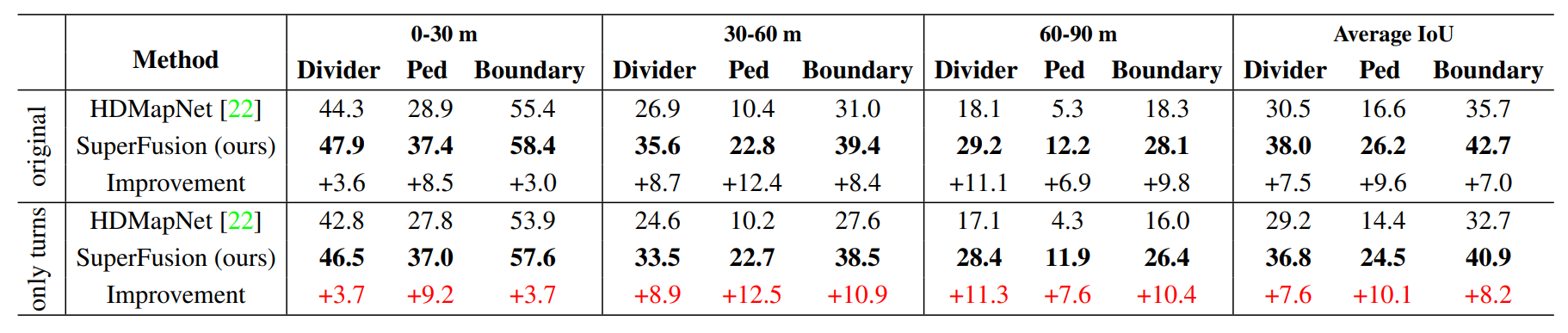
- 将 HDMapNet 和我们的结果进行比较,并显示SuperFusion的性能改进
- 粗体数字是最好的性能,红色数字表示更大的改进。
nuScenes 数据集上的实例检测结果。

- 倒角距离的预定义阈值是 1.0 m,IoU 阈值是 0.1
- 例如,当且仅当 CD 低于且 IoU 高于定义的阈值时,预测才被视为真阳性
- AP:越高越好
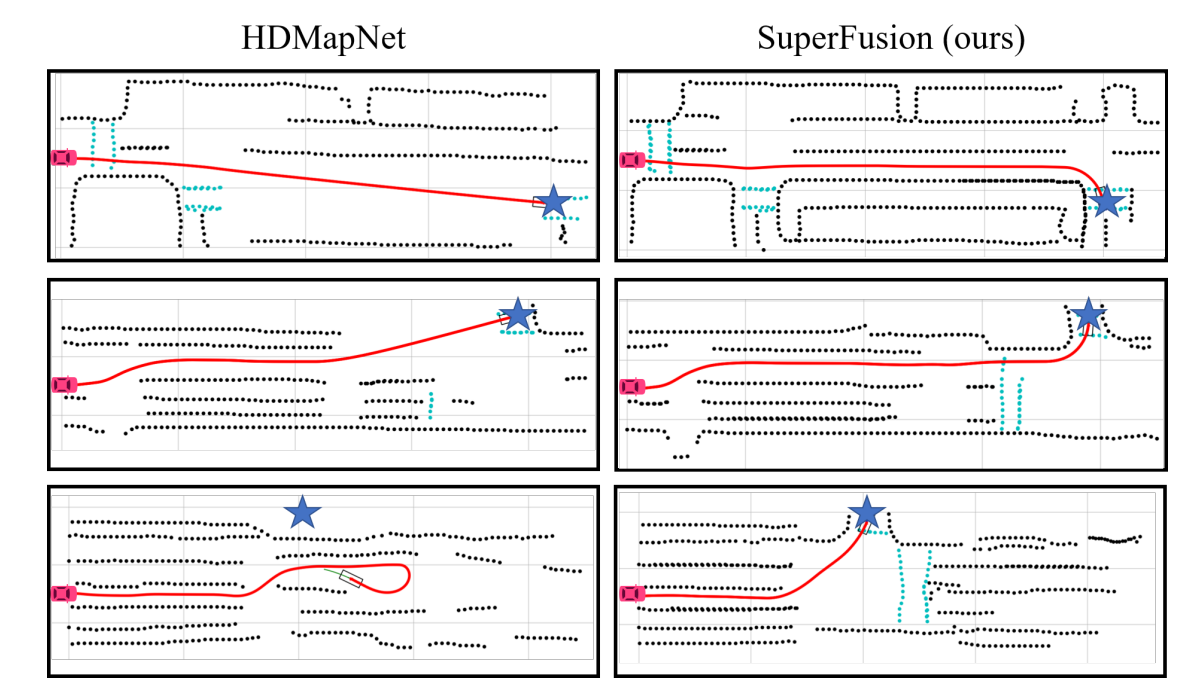
生成的高清地图上的路径规划结果:
在自采集数据集,远距离高清地图生成效果:

本文先介绍到这里,后面会分享“多模态融合”的其它数据集、算法、代码、具体应用示例。
