阅读量:0
爬取图片的信息
爬取图片与爬取文本内容相似,只是需要加上图片的url,并且在查找图片位置的时候需要带上图片的属性。
这里选取了一个4K高清的壁纸网站(彼岸壁纸https://pic.netbian.com)进行爬取。
具体步骤如下:
- 第一步依然是进入这个页面,这个壁纸网站分为好几种类型的壁纸图片,点击一个你想要爬取的类型,然后按F12,从中获取URL和请求方式(复制URL,会用到),这次就不用网页的"User-Agent’'了,用pycharm包中别人写好的。
然后发送我们的请求并获取这个网页的数据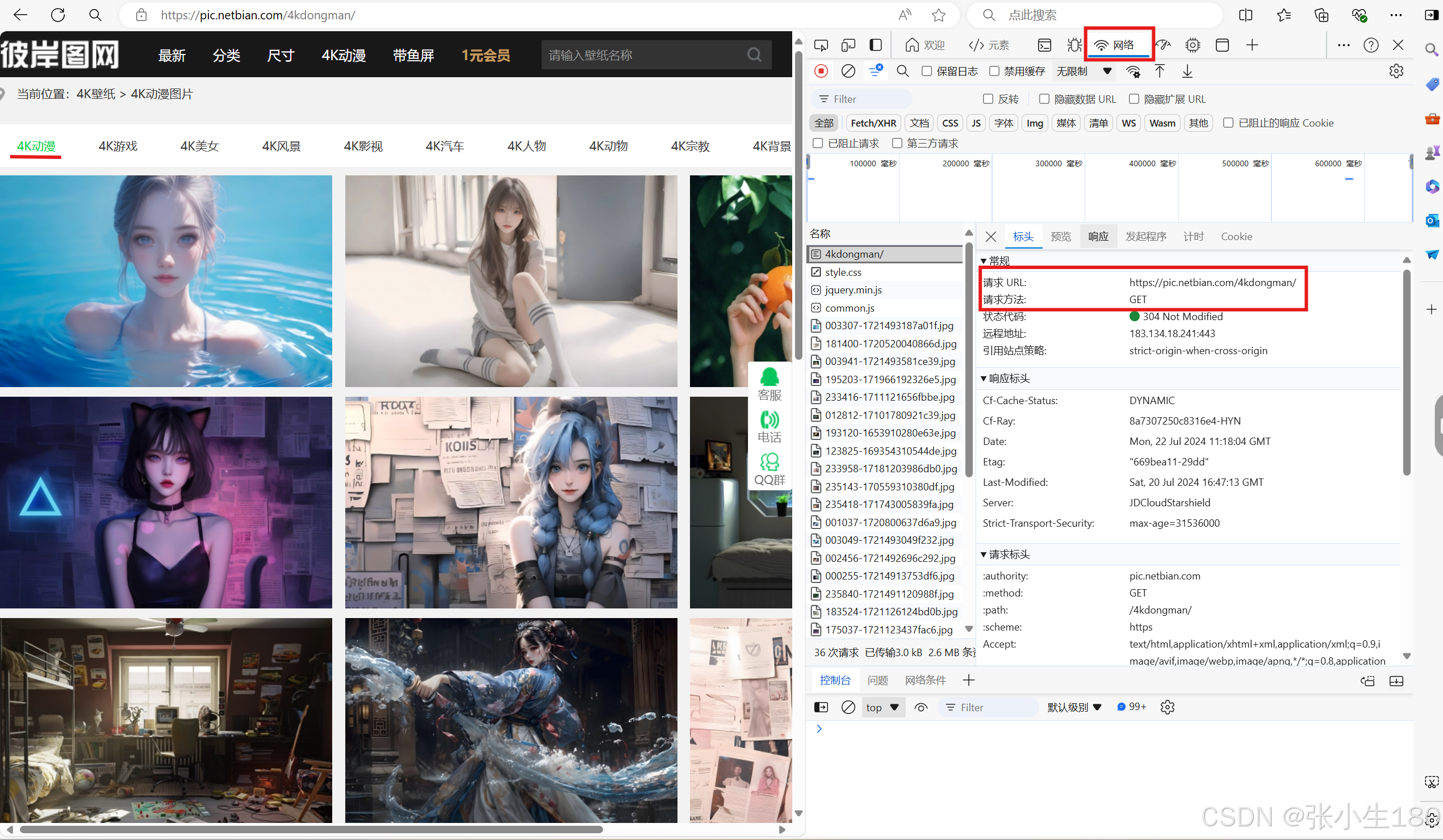
# url url = "https://pic.netbian.com/4kmeinv/" # UA伪装 用下载好的库中别人写好的UA head = {"User-Agent": fake_useragent.UserAgent().random} # 发送请求 response = requests.get(url, headers=head) # 获取想要的数据 res_text = response.text - 第二步打开元素栏,用左上角的寻找工具放在图片上,定位到元素栏中对应的标签,用数据分析的方法获取到图片信息。
其实每一张图片的排放就好像是一个个列表,其所有的信息都粗存在元素栏中的li标签中,我们想要获取多张照片,首先需要先将这些li标签都获取下来。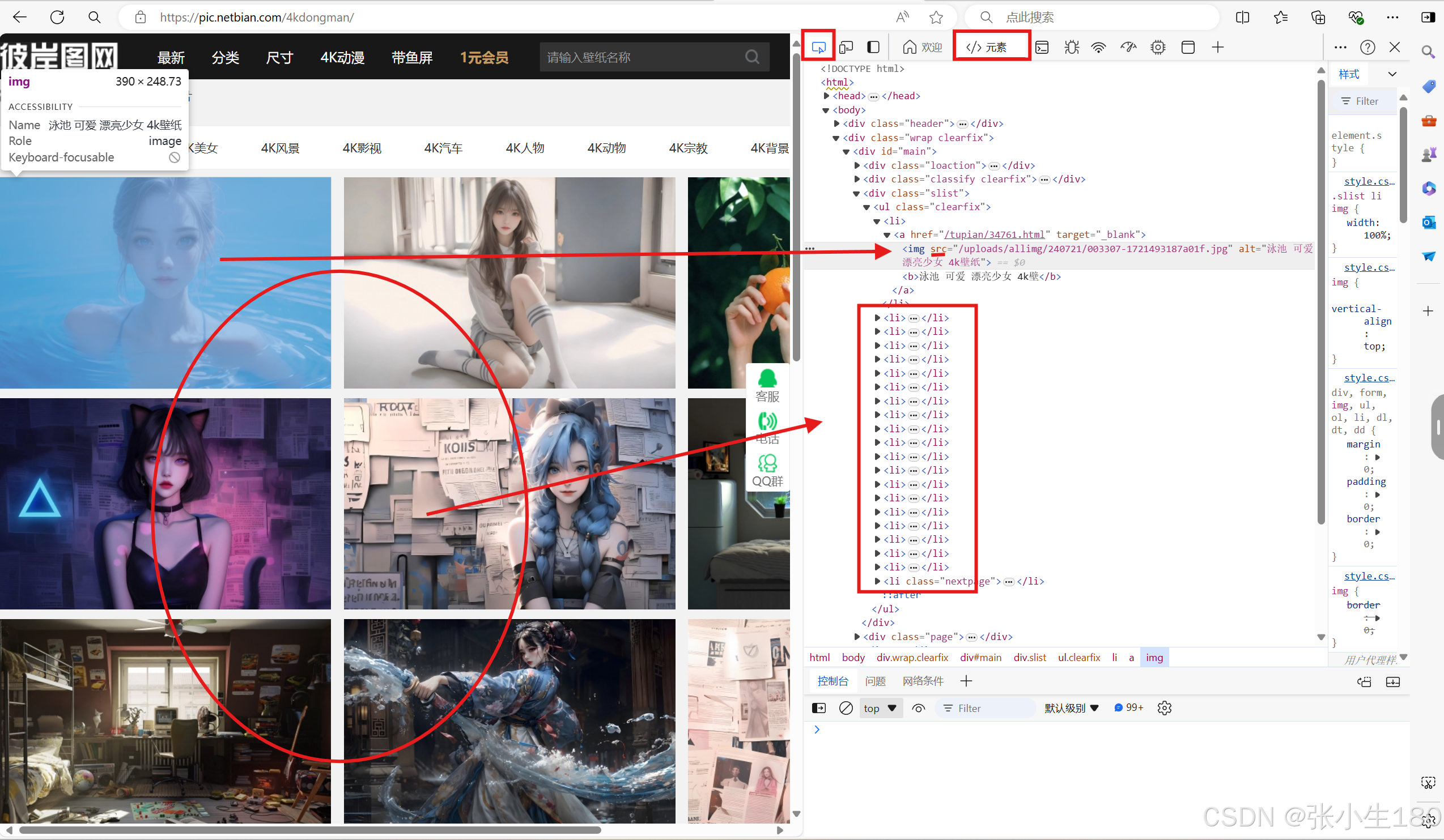
# 数据解析 获取所有的li标签,并存放在li_list中 tree = etree.HTML(res_text) li_list = tree.xpath("//div[@class='slist']/ul/li") - 第三步获取图片与获取文本内容不同的是,需要再获取图片的url,图片的url就在上图箭头所指的位置,但是这个仅仅只是图片在这个板块的位置,所以前面需要在前面加上这个壁纸网站的地址,这样获取的图片信息才是完整的,可以被打开。
因为先前已经将存放图片信息的li标签都存放在了li_list中,所以我们就用for循环遍历这个列表,以便获取更多的图片信息。
for li in li_list: # 图片的url img_url = "https://pic.netbian.com" + "".join(li.xpath("./a/img/@src")) # 发送请求 img_response = requests.get(img_url, headers=head) # 获取想要的数据 img_content = img_response.content - 第四步将获取到的图片存放在文件夹中
# pic_name = 0 这次的代码封装在函数中,将这个变量放在了函数外面,给获取的图片编号 # 将pic_name定义为全局变量,方便调用 global pic_name with open(f"./picLibbb/{pic_name}.jpg", "wb") as fp: fp.write(img_content) pic_name += 1 - 第五步为了获取更多的照片,因为每一页能展示的照片有限,所以我们需要for循环遍历每一页的网址;
每一页的网址都只是在页面数量上的差别,所以可以遍历。
第一页的网址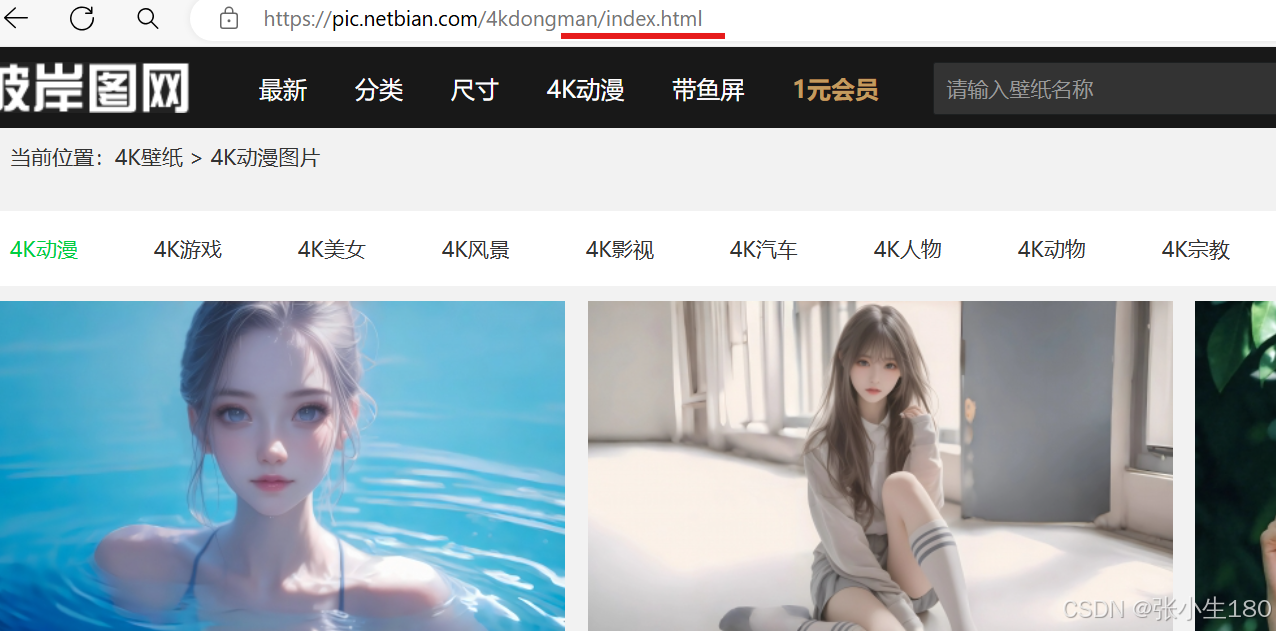
第二页的网址
第三页的网址
url = "https://pic.netbian.com/4kmeinv/" request_pic(url) for i in range(1,10): next_url = f"https://pic.netbian.com/4kmeinv/index_{i}.html" request_pic(next_url) 完整代码:
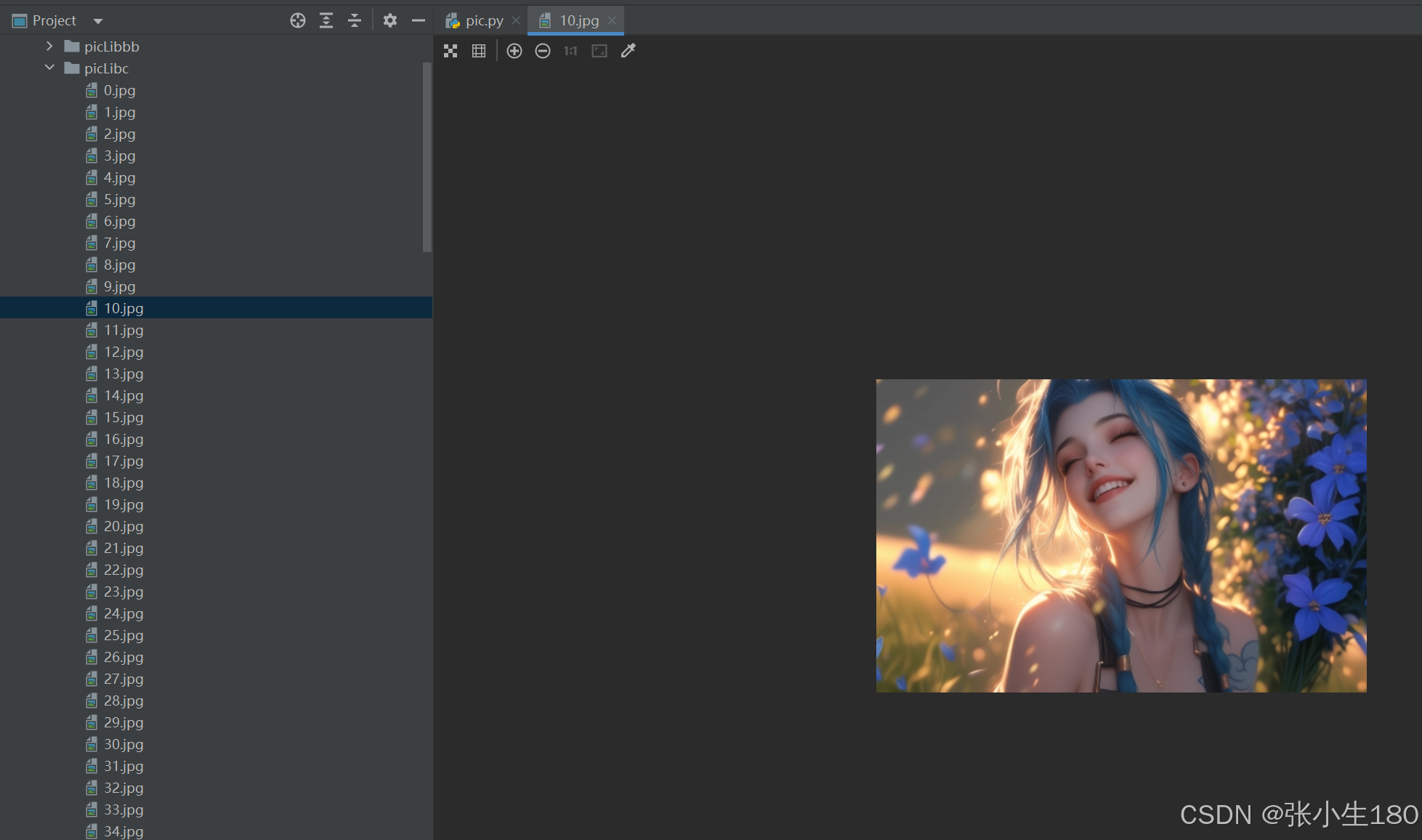
# 获取图片数据 import os.path import fake_useragent import requests from lxml import etree # UA伪装 head = {"User-Agent": fake_useragent.UserAgent().random} pic_name = 0 def request_pic(url): # 发送请求 response = requests.get(url, headers=head) # 获取想要的数据 res_text = response.text # 数据解析 tree = etree.HTML(res_text) li_list = tree.xpath("//div[@class='slist']/ul/li") for li in li_list: # 图片的url img_url = "https://pic.netbian.com" + "".join(li.xpath("./a/img/@src")) # 发送请求 img_response = requests.get(img_url, headers=head) # 获取想要的数据 img_content = img_response.content global pic_name with open(f"./picLib/{pic_name}.jpg", "wb") as fp: fp.write(img_content) pic_name += 1 if __name__ == '__main__': # 创建存放照片的文件夹 if not os.path.exists("./picLib"): os.mkdir("./picLibbb") # 网站的url url = "https://pic.netbian.com/4kdongman/" request_pic(url) for i in range(1,10): next_url = f"https://pic.netbian.com/4kmeinv/index_{i}.html" request_pic(next_url) 爬取后的效果如下: