
阅读量:0
文章目录
1. 概述
我们介绍了Zero-1-to-3框架,该框架仅需一张RGB图像即可改变物体的相机视角。为了在这种欠约束的情况下执行新视角合成,我们利用大规模扩散模型对自然图像学习到的几何先验知识。我们的条件扩散模型使用一个合成数据集来学习相对相机视角的控制,这使得可以生成在指定相机变换下同一物体的新图像。尽管该模型是在合成数据集上训练的,但它对分布外数据集以及自然图像(包括印象派绘画)具有很强的零样本泛化能力。我们的视角条件扩散方法还可以用于从单张图像进行3D重建的任务。定性和定量实验表明,通过利用互联网规模的预训练,我们的方法显著优于最先进的单视图3D重建和新视角合成模型。
2. 背景介绍
想象一个物体的3D形状和外观。这种能力对于日常任务(如物体操作[18]和在复杂环境中的导航[7])以及视觉创造力(如绘画[33])都非常重要。虽然这种能力部分可以用对几何先验(如对称性)的依赖来解释,但我们似乎能够轻松地概括出更具挑战性的物体,这些物体打破了物理和几何约束。事实上,我们可以预测那些在物理世界中不存在甚至不可能存在的物体的3D形状(见图1第三列)。为了实现这种程度的概括能力,人类依赖于通过一生的视觉探索积累的先验知识。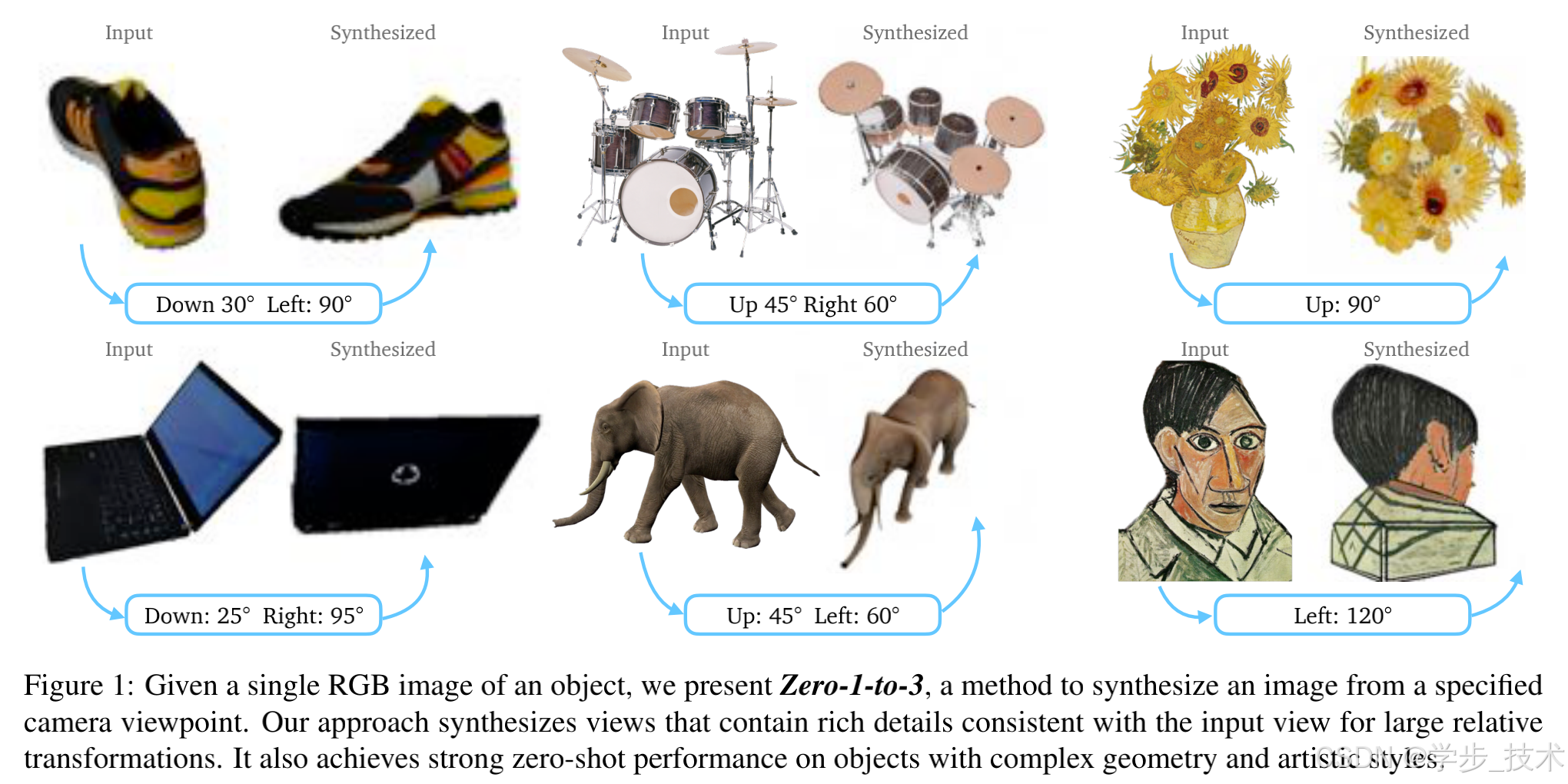
相比之下,大多数现有的3D图像重建方法由于依赖于昂贵的3D注释(如CAD模型)或特定类别的先验知识[37, 23, 36, 67, 68, 66, 27, 26, 2],而在封闭世界设置中操作。最近,一些方法通过在大规模多样化的数据集(如CO3D [44, 31, 36, 16])上进行预训练,在开放世界3D重建方面取得了重大进展。然而,这些方法在训练时通常仍需要与几何相关的信息,如立体视图或相机姿势。因此,与支持大型扩散模型[46, 45, 34]成功的互联网规模的文本图像集合[48]相比,它们使用的数据规模和多样性仍然微不足道。已有研究表明,互联网规模的预训练赋予了这些模型丰富的语义先验,但它们捕捉几何信息的程度仍然 largely unexplored。
在本文中,我们展示了能够学习控制机制以操控大型扩散模型(如Stable Diffusion [45])中的相机视角,以进行零样本新视角合成和3D形状重建。给定一张RGB图像,这两个任务都是严重欠约束的。然而,由于现代生成模型可用的训练数据规模(超过50亿张图像),扩散模型是自然图像分布的最先进表示,覆盖了从多个视角观察的众多物体。尽管它们是在没有任何相机对应关系的2D单眼图像上训练的,我们可以通过微调模型来学习在生成过程中对相对相机旋转和平移的控制。这些控制使我们能够对任意图像进行编码,并解码为我们选择的不同相机视角。图1展示了我们结果的几个示例。
本文的主要贡献是展示了大型扩散模型已经学习了关于视觉世界的丰富3D先验知识,即使它们只是在2D图像上训练的。我们还展示了新视角合成的最先进结果以及单张RGB图像的零样本3D重建的最先进结果。我们首先在第2节简要回顾相关工作。在第3节中,我们描述了通过微调大型扩散模型来学习相机外参控制的方法。最后,在第4节中,我们展示了几个定量和定性实验,以评估从单张图像进行几何和外观的零样本视角合成和3D重建。我们将发布所有代码和模型以及一个在线演示。
3. 方法
给定一个物体的单张RGB图像 x ∈ R H × W × 3 x \in \mathbb{R}^{H \times W \times 3} x∈RH×W×3,我们的目标是从不同的相机视角合成该物体的图像。设 R ∈ R 3 × 3 R \in \mathbb{R}^{3 \times 3} R∈R3×3 和 T ∈ R 3 T \in \mathbb{R}^3 T∈R3 分别为期望视角的相对相机旋转和平移。我们希望学习一个模型 f f f,该模型在这个相机变换下合成新的图像: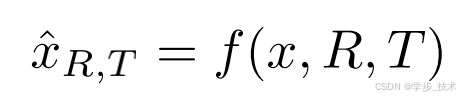
其中 x ^ R , T \hat{x}{R,T} x^R,T 表示合成的图像。我们希望估计的 x ^ R , T \hat{x}{R,T} x^R,T 在感知上与真实但未观察到的新视角图像 x R , T x_{R,T} xR,T 相似。
从单眼RGB图像进行新视角合成是一个严重欠约束的问题。我们的方法将利用大规模扩散模型(如Stable Diffusion)来执行这一任务,因为它们在从文本描述生成多样化图像时显示出了非凡的零样本能力。由于其训练数据的规模 [48],预训练的自然图像分布如今覆盖了大多数常见物体的视角。
然而,要创建 f f f 我们必须克服两个挑战。首先,尽管大规模生成模型在不同视角下训练了大量多样化的物体,但这些表示并未明确编码视角之间的对应关系。其次,生成模型继承了互联网上反映的视角偏差。如图2所示,Stable Diffusion倾向于生成面向前方的椅子的规范姿势图像。这两个问题极大地阻碍了从大规模扩散模型中提取3D知识的能力。
3.1 学习控制相机视角
扩散模型最近在图像生成任务中取得了最先进的成果 [10]。去噪扩散概率模型 (DDPM) [20] 是一种设计用于学习训练数据分布的生成模型。在图像生成的背景下,通过逐渐去噪图像来生成样本,每个像素独立地从高斯分布中采样。
随着最新的大规模扩散模型 [40, 46, 45] 已经在互联网规模的数据上进行了文本到图像生成的训练,它们对自然图像分布的支持可能涵盖了大多数常见物体的视角,但这些视角在预训练模型中无法控制。一旦我们能够教会模型控制拍摄照片的相机外参的机制,那么我们就可以进行新视角合成。为此,给定一个成对图像及其相对相机外参的数据集 x , x ( R , T ) , R , T {x, x_{(R,T)}, R, T} x,x(R,T),R,T,如图3所示,我们的方法微调了预训练的扩散模型,以学习相机参数的控制,而不破坏其余的表示。
潜在扩散模型是一种特殊类型的扩散模型,其中扩散过程发生在预训练用于图像重建的变分自编码器的潜在空间中。按照 [45],我们使用具有编码器 E E E、去噪器 U-Net ϵ θ \epsilon_\theta ϵθ 和解码器 D D D 的潜在扩散架构。在扩散时间步长 t ∼ [ 1 , 1000 ] t \sim [1, 1000] t∼[1,1000],让 c ( x , R , T ) c(x, R, T) c(x,R,T) 为输入视图和相对相机外参的嵌入。令 z z z 为由 E E E 编码的输入图像的潜在表示。然后我们通过以下目标来微调模型: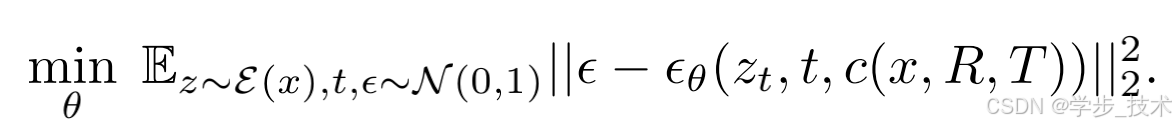
一旦模型 ϵ θ \epsilon_\theta ϵθ 被训练好,推理模型 f f f 就可以通过从高斯噪声图像 [45] 迭代去噪来生成图像,条件是 c ( x , R , T ) c(x, R, T) c(x,R,T)。
本文的主要结果是,通过这种方式微调预训练的扩散模型,使它们能够学习控制相机视角的通用机制,这种机制可以超出微调数据集中看到的物体进行外推。换句话说,这种微调允许“添加”控制,并且扩散模型可以保留生成真实感图像的能力,只是现在能够控制视角。这种组合性在模型中建立了零样本能力,最终模型可以为缺乏3D资产的对象类以及从未出现在微调集合中的对象类合成新视角。
3.2 视角条件扩散
从单张图像进行3D重建需要低级感知(深度、阴影、纹理等)和高级理解(类型、功能、结构等)。因此,我们采用了一种混合条件机制。在一个流中,输入图像的CLIP [39] 嵌入与 ( R , T ) (R, T) (R,T) 连接形成“有姿态的CLIP”嵌入 c ( x , R , T ) c(x, R, T) c(x,R,T)。我们应用交叉注意力来条件去噪U-Net,这提供了输入图像的高级语义信息。在另一流中,输入图像与正在去噪的图像通道连接,帮助模型保持正在合成的对象的身份和细节。为了能够应用无分类器指导 [21],我们按照 [3] 提出的类似机制,随机将输入图像和有姿态的CLIP嵌入设置为空向量,并在推理期间缩放条件信息。
3.3 3D重建
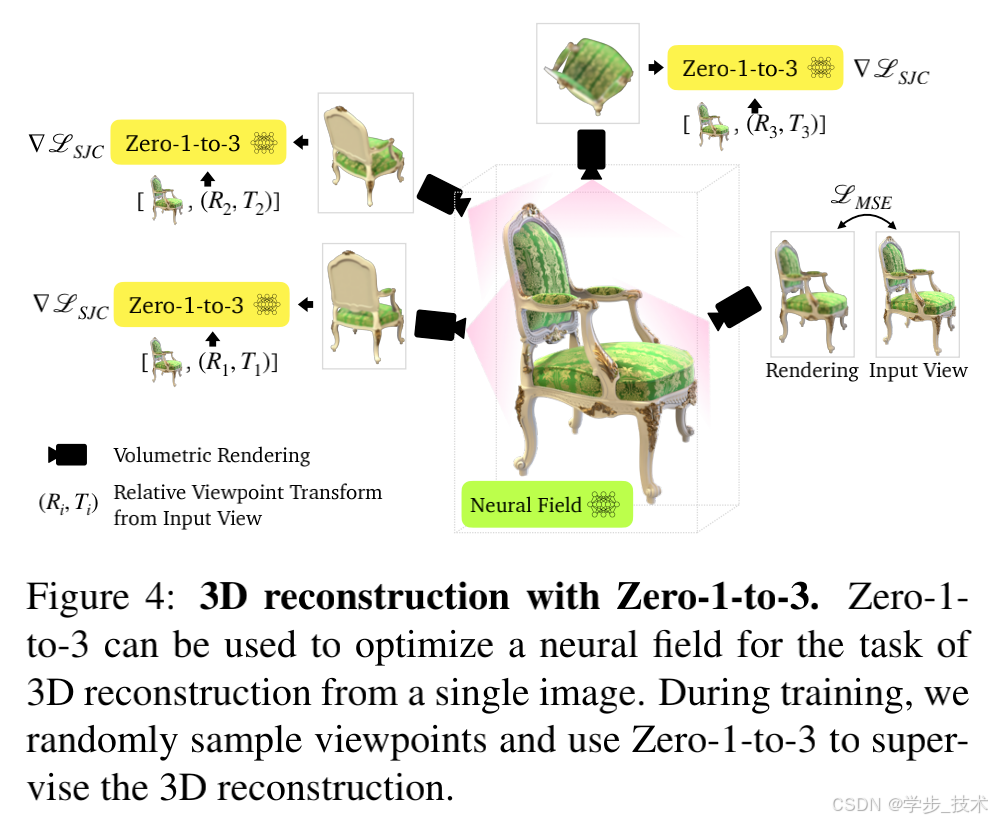
在许多应用中,合成物体的新视角是不够的。需要一个完整的3D重建来捕捉物体的外观和几何。我们采用最近开源的框架Score Jacobian Chaining (SJC) [54],通过文本到图像扩散模型的先验来优化3D表示。然而,由于扩散模型的概率性质,梯度更新高度随机。SJC中使用的一个关键技术受到DreamFusion [38] 的启发,是将无分类器指导值设置为比平常高得多。这种方法降低了每个样本的多样性,但提高了重建的保真度。
如图4所示,与SJC类似,我们随机采样视角并进行体积渲染。然后我们用高斯噪声 ϵ ∼ N ( 0 , 1 ) \epsilon \sim \mathcal{N}(0, 1) ϵ∼N(0,1) 扰动结果图像,并通过应用条件于输入图像 x x x、有姿态的CLIP嵌入 c ( x , R , T ) c(x, R, T) c(x,R,T) 和时间步长 t t t 的U-Net ϵ θ \epsilon_\theta ϵθ 来去噪它们,以近似分数到非噪声输入 x π x_\pi xπ 的得分: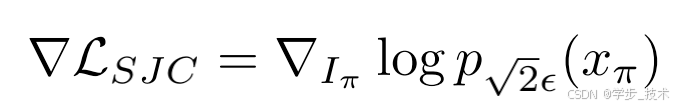
其中 ∇ L S J C \nabla L_{SJC} ∇LSJC 是由 [54] 引入的PAAS得分。
此外,我们用MSE损失优化输入视图。为了进一步正则化NeRF表示,我们还对每个采样视角应用深度平滑损失,并对近视图变化的一致性损失进行正则化。
3.4 数据集
我们使用最近发布的Objaverse [8] 数据集进行微调,这是一个包含800K+ 3D模型的大规模开源数据集,由100K+艺术家创建。虽然它没有像ShapeNet [4] 那样的明确类别标签,但Objaverse包含大量高质量的3D模型,具有丰富的几何结构,其中许多具有细粒度的细节和材质属性。对于数据集中的每个对象,我们随机采样12个相机外参矩阵 M e M_e Me,指向对象的中心,并用光线追踪引擎渲染12个视图。在训练时,可以为每个对象采样两个视图,以形成图像对 ( x , x ( R , T ) ) (x, x_{(R,T)}) (x,x(R,T))。定义这两个视角之间映射的相对视角变换 ( R , T ) (R, T) (R,T) 可以很容易地从这两个外参矩阵中推导出来。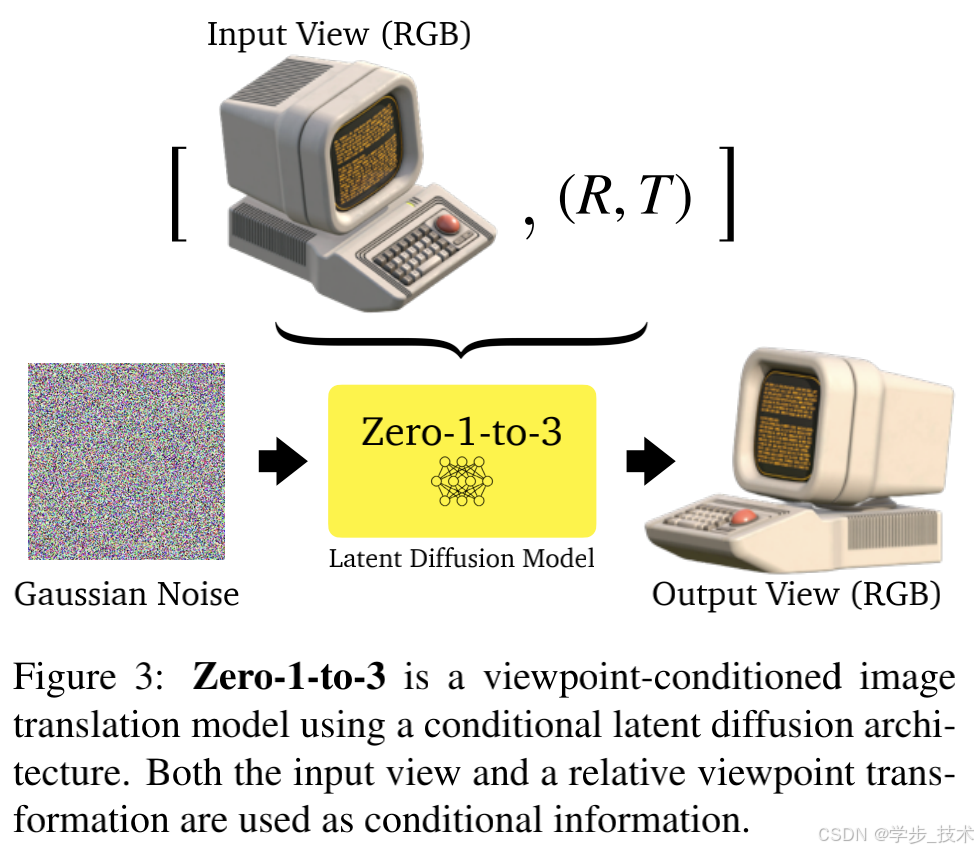
4. 实验评测

我们评估了模型在零样本新视角合成和3D重建方面的性能。正如Objaverse的作者所确认的那样,我们在本文中使用的数据集和图像都不属于Objaverse数据集,因此可以认为这些结果是零样本的。我们定量比较了我们的模型与最先进的合成物体和场景在不同复杂度水平上的表现。我们还报告了使用各种真实图像的定性结果,包括我们拍摄的日常物品图片和绘画。
4.1 任务
我们描述了两个密切相关的任务,这些任务以单视图RGB图像作为输入,并以零样本方式应用它们。
新视角合成。新视角合成是一项长期存在的计算机视觉问题,需要模型隐式地学习物体的深度、纹理和形状。由于只有单一视角,输入信息极其有限,这需要利用先验知识的方法进行新视角合成。最近流行的方法依赖于通过随机采样视图优化隐式神经场,并使用CLIP一致性目标 [25]。然而,我们的方法在3D重建和新视角合成的顺序上进行了颠倒,同时保持了输入图像所描绘物体的身份。这种方式使得在围绕物体旋转时通过概率生成模型来建模自遮挡的不确定性,并且能够有效地利用大规模扩散模型所学习的语义和几何先验知识。
**3D重建。**我们还可以采用一种随机的3D重建框架,例如SJC [54]或DreamFusion [38],以创建最可能的3D表示。我们将其参数化为体素辐射场 [5, 50, 14],然后通过在密度场上执行Marching Cubes算法来提取网格。将视角条件扩散模型应用于3D重建,为引导丰富的2D外观先验知识向3D几何提供了一条可行的路径。
4.2 基线
为了与我们方法的范围保持一致,我们仅比较在零样本环境下操作并使用单视图RGB图像作为输入的方法。
对于新视角合成,我们与几种最先进的单图像算法进行了比较。特别是,我们基准测试了DietNeRF [25],它通过在视点之间使用CLIP图像到图像一致性损失来正则化NeRF。此外,我们还比较了Image Variations (IV) [1],这是一种针对图像而非文本提示进行微调的Stable Diffusion模型,可以看作是一种具有Stable Diffusion的语义最近邻搜索引擎。最后,我们适应了SJC [54],一种基于扩散的文本到3D模型。我们将原始的文本条件扩散模型替换为图像条件扩散模型,称之为SJC-I。直观地说,我们在NeRF优化过程中应用了基于图像的语义指导而不是基于文本的语义指导。
对于3D重建,我们使用了两种最先进的单视图算法作为基线:(1)Multiview Compressive Coding (MCC) [59],这是一种基于神经场的方法,可以将RGB-D观察结果补全为3D表示;(2)Point-E [35],这是一个对彩色点云进行扩散的模型。MCC在CO3Dv2 [44]上训练,而Point-E显著地在一个更大的OpenAI内部3D数据集上训练。我们还比较了SJC-I。
由于MCC需要深度输入,我们使用MiDaS [43, 42]进行深度估计。通过假设标准的尺度和偏移值,将获得的相对视差图转换为绝对伪度量深度图,以在整个测试集上看起来合理。
4.3 基准和指标
我们在Google Scanned Objects (GSO) [11]和RTMV [51]上评估了这两项任务,GSO是一个高质量的家用物品扫描数据集,而RTMV包含了复杂场景,每个场景由20个随机物体组成。在所有实验中,使用相应的真实3D模型来评估3D重建。
对于新视角合成,我们使用四个指标对方法和基线进行全面的数值评估,涵盖了图像相似性的不同方面:PSNR、SSIM [56]、LPIPS [64]和FID [19]。对于3D重建,我们测量了Chamfer Distance和体积IoU。
4.4 新视角合成结果
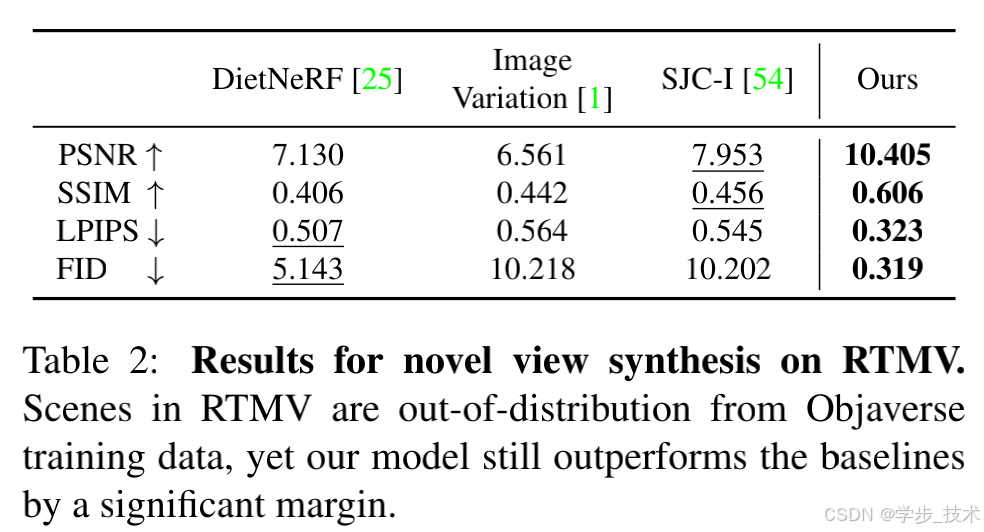
我们在表1和表2中展示了数值结果。图5显示,与所有基线相比,我们的方法在GSO上能够生成与真实情况高度一致的高度真实感图像。即使在图6中显示的RTMV数据集上的场景超出了Objaverse数据集的分布,这种趋势仍然存在。在我们的基线中,我们观察到Point-E具有令人印象深刻的零样本泛化能力。然而,生成的点云尺寸较小,极大地限制了Point-E在新视角合成中的适用性。
图7进一步展示了我们模型对具有挑战性几何和纹理的物体的泛化性能,以及在保持物体类型、身份和低级细节的同时合成高保真视点的能力。
\textbf{样本多样性。}从单一图像进行新视角合成是一个严重欠约束的任务,这使得扩散模型在捕捉潜在的不确定性方面比NeRF具有特别适合的架构。由于输入图像是2D的,它们总是只描绘了物体的部分视图,留下许多未被观察到的部分。图8例证了从新视点采样的可能性多样性和高质量图像。
\textbf{消融研究。}在表3中,我们通过改变微调或从头训练的训练集规模,研究了Zero-1-to-3的扩展特性。即使在具有较少Objaverse示例(8K)的情况下,我们的方法也优于基线。此外,使用所有可用示例(800K),从Stable Diffusion初始化比从头训练模型有显著的改进。这两种观察都支持了我们的假设。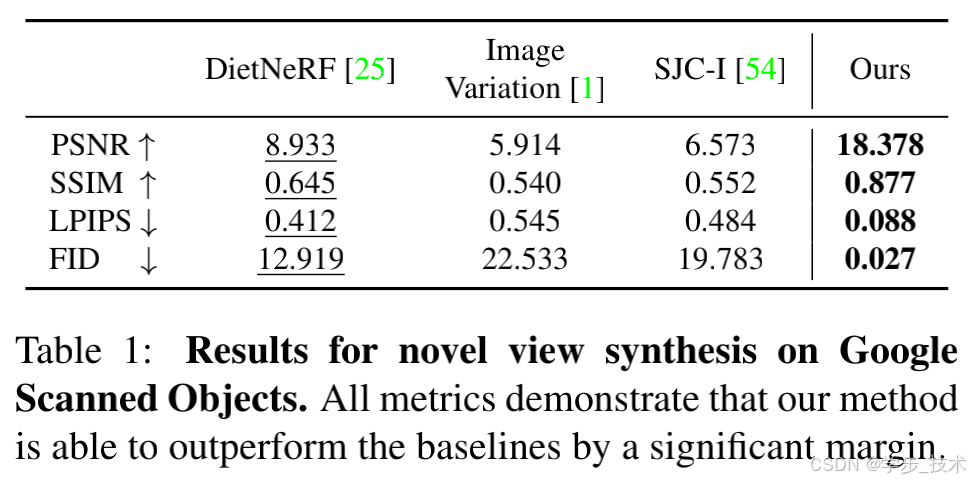

4.5 3D重建结果
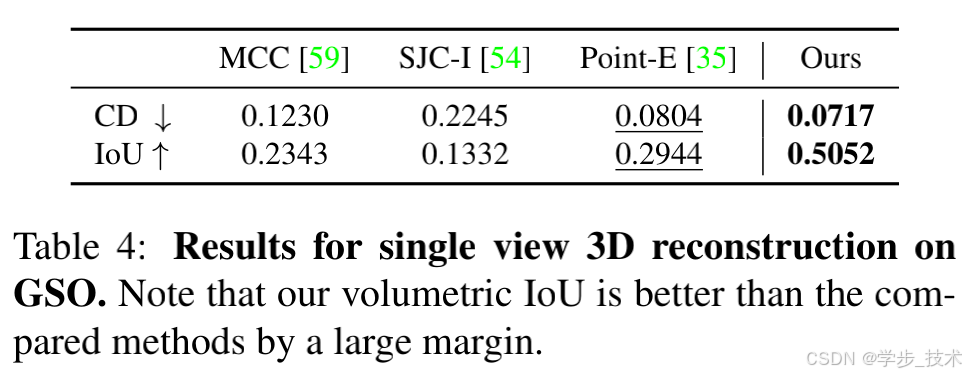
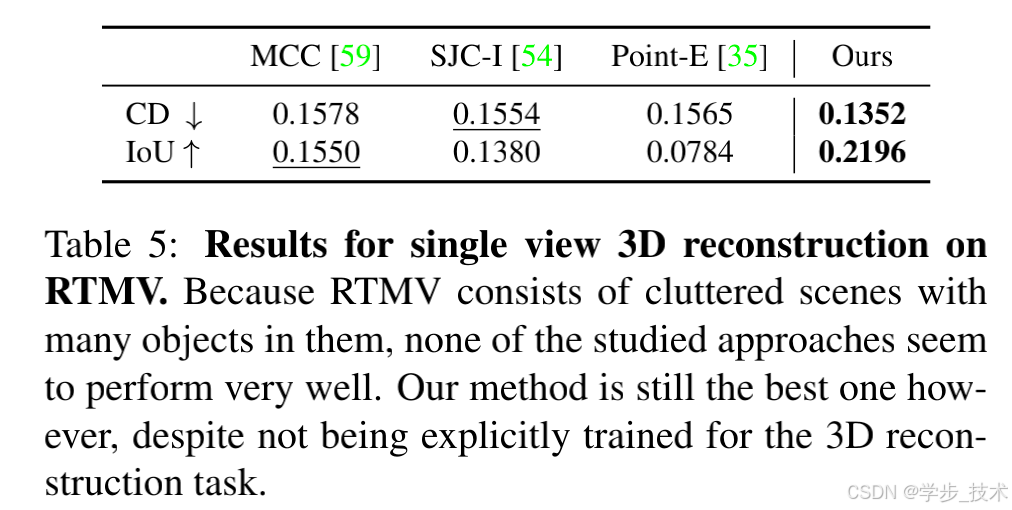
我们在表4和表5中展示了数值结果。图9定性地显示了我们的方法重建了与真实情况一致的高保真3D网格。MCC倾向于很好地估计输入视图可见的表面,但经常无法正确推断物体背面的几何。SJC-I也经常无法重建有意义的几何。然而,Point-E具有令人印象深刻的零样本泛化能力,能够预测物体几何的合理估计。然而,它生成的非均匀稀疏点云只有4096个点,有时会导致重建表面出现孔洞(根据其提供的网格转换方法)。因此,它获得了良好的CD分数,但在体积IoU方面有所不足。我们的方法利用了视角条件扩散模型所学习的多视图先验知识,并将其与NeRF风格表示的优势结合起来。正如表4和表5所示,这两种因素在CD和体积IoU方面都比现有方法有显著改进。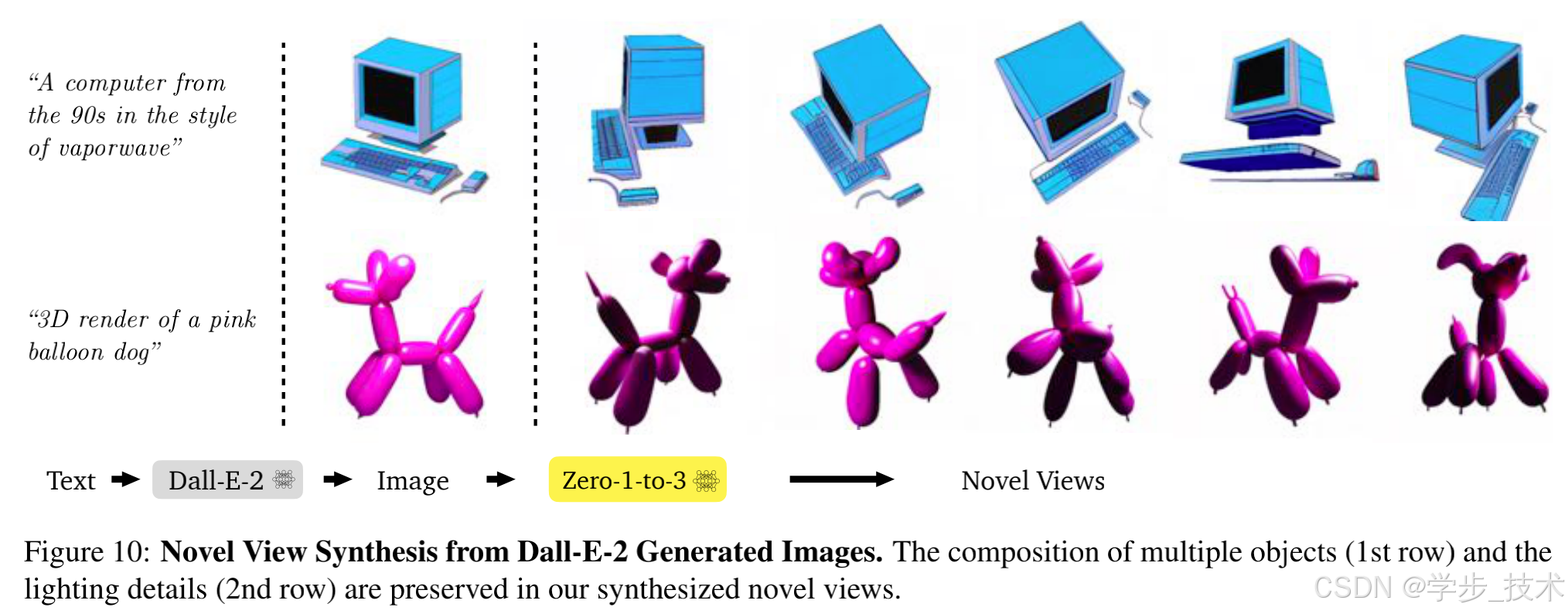
4.6 从文本到图像到3D
除了真实图像外,我们还测试了我们的模型在由txt2img模型(如Dall-E-2 [41])生成的图像上的表现。如图10所示,我们的模型能够生成这些图像的新视角,同时保持物体的身份。我们认为这在许多文本到3D生成应用中将非常有用。
5. 讨论
在这项工作中,我们提出了一种新颖的方法Zero-1-to-3,用于零样本单图像新视角合成和3D重建。我们的方法利用了Stable Diffusion模型,该模型在互联网上规模化的数据上进行了预训练,并捕捉到了丰富的语义和几何先验知识。为了提取这些信息,我们在合成数据上微调了模型,以学习对相机视点的控制。由于能够利用Stable Diffusion学习的强大物体形状先验知识,所得到的方法在几个基准测试中表现出了最先进的结果。
\textbf{从物体到场景。}我们的方法在单一物体的数据集上进行了训练,背景为简单的背景。尽管我们在RTMV数据集上展示了对包含多个物体的场景的强泛化能力,但与GSO的分布内样本相比,质量仍有所下降。因此,对复杂背景场景的泛化仍然是我们方法的重要挑战。
