
阅读量:0
决策树是最经常使用的数据挖掘算法。它之所以如此流行,一个很重要的原因就是不需要了解机器学习的知识,就能搞明白决策树是如何工作的。
决策树的优缺点:
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
缺点:可能会产生过度匹配问题。
使用数据类型:数值型和标称型。
在构造决策树时,我们需要解决的第一个问题就是,当前数据集上哪个特征在划分数据分类时起到决定性作用。为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征。完成测试之后,原始数据集就被划分为几个数据集。这些数据子集会分布在第一个决策点的所有分支上。如果某个分支下的数据属于同一类型,则已经正确地划分数据分类,无需进一步对数据集进行分割。如果数据子集内的数据不属于同一类型,则需要重复划分数据子集的过程。划分数据子集的算法与划分原始数据集的方法相同,直到所有具有相同类型的数据均在一个数据子集内。
创建分支的伪代码:
If so return 类标签
else
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集
调用函数并增加返回结果到分支节点中
return 分支节点
上面的伪代码是一个递归函数,在倒数第二行调用它自己。
决策树的一般流程:
1、收集数据
2、准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化
3、分析数据:构造树完成字后,我们应该检查图形是够符合预期
4、训练算法
5、测试算法
6、使用算法
一些决策树算法采用二分法划分数据,但如果依据某个属性划分数据将会产生4个可能的值,我们也可以将数据划分成4块。
以下面的数据为例,这里有5个海洋生物,我们要将动物划分为两类:鱼类和非鱼类。现在我们要决定依据第一个特征还是第二个特征:
| 不浮出水面能否生存 | 是否有脚蹼 | 属于鱼类 | |
| 1 | 是 | 是 | 是 |
| 2 | 是 | 是 | 是 |
| 3 | 是 | 否 | 否 |
| 4 | 否 | 是 | 否 |
| 5 | 否 | 是 | 否 |
划分数据集的大原则是:将无序的数据变得更加有序。我们可以使用多种方法划分数据集,但是每种方法都有各自的优缺点。组织杂乱无章数据的一种方法是使用信息论度量信息,信息论是量化处理信息的分支科学。我们可以在划分数据之前或之后使用信息论量化度量信息的内容。
在划分数据集之前之后信息发生的变化称为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据即获得的信息增益,获得信息增益最高的特征就是最好的选择。
在可以评测那种数据划分方式是最好的数据划分之前,我们必须学习如何计算信息增益。集合信息的度量方式称为香农熵或者简称为熵。
熵定义为信息的期望值,在明晰这个概念之前,我们必须指导信息的定义。如果待分类的失误肯呢个划分在多个分类之中,则符号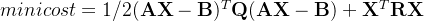 的信息定义为:
的信息定义为:
其中是选择改分类的概率
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,通过下面的公式得到:
其中n是分类的数目。
下面代码的功能是计算给定数据集的熵:
from math import log def calcShannonEnt(dataSet): numEntries=log(dataSet) labelCounts={} for featVec in dataSet: currentLabel=featVec[-1] if currentLabel not in labelCounts.keys(): labelCounts[currentLabel]=0 labelCounts[currentLabel] += 1 shannonEnt=0.0 for key in labelCounts: prod=float(labelCounts[key])/numEntries shannonEnt-=prod*log(prod,2) return shannonEnt函数中,首先计算数据中实例的总数,我们也可以在需要时再计算这个值,但是由于代码中多次用到这个值,为了提高代码的效率,我们显示地声明一个变量保存实例总数。然后创建了一个数据字典,它的键值是最后一列的数值。如果当前键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。最后,使用所有类标签的发生频率计算类别出现的概率。我们将用这个概率计算香农熵,统计所有类标签发生的次数。
我们输入上面的鱼类分类数据:
def createDataSet(): dataSet=[[1,1,'yes'], [1,1,'yes'], [1,0,'no'], [0,1,'no'], [0,1,'no'],] labels=['no surfacing','flippers'] return dataSet,labelsmyDat,labels=createDataSet() print(calcShannonEnt(myDat)) 
熵越高,则混合的数据也越多,我们可以在数据集中添加更多的分类,观察熵是如何变化的。这里我们增加第三个名为maybe的分类,测试熵的变化。
myDat[0][-1]='maybe' print(calcShannonEnt(myDat))
得到熵之后,我们就可以按照获取最大信息增益的方法划分数据集。
