
阅读量:0
在实际的开发过程中,也会遇到导入导出的功能,今天就简单的做一下总结。
1.需求:将下面word 数据导入到数据库并进行存储
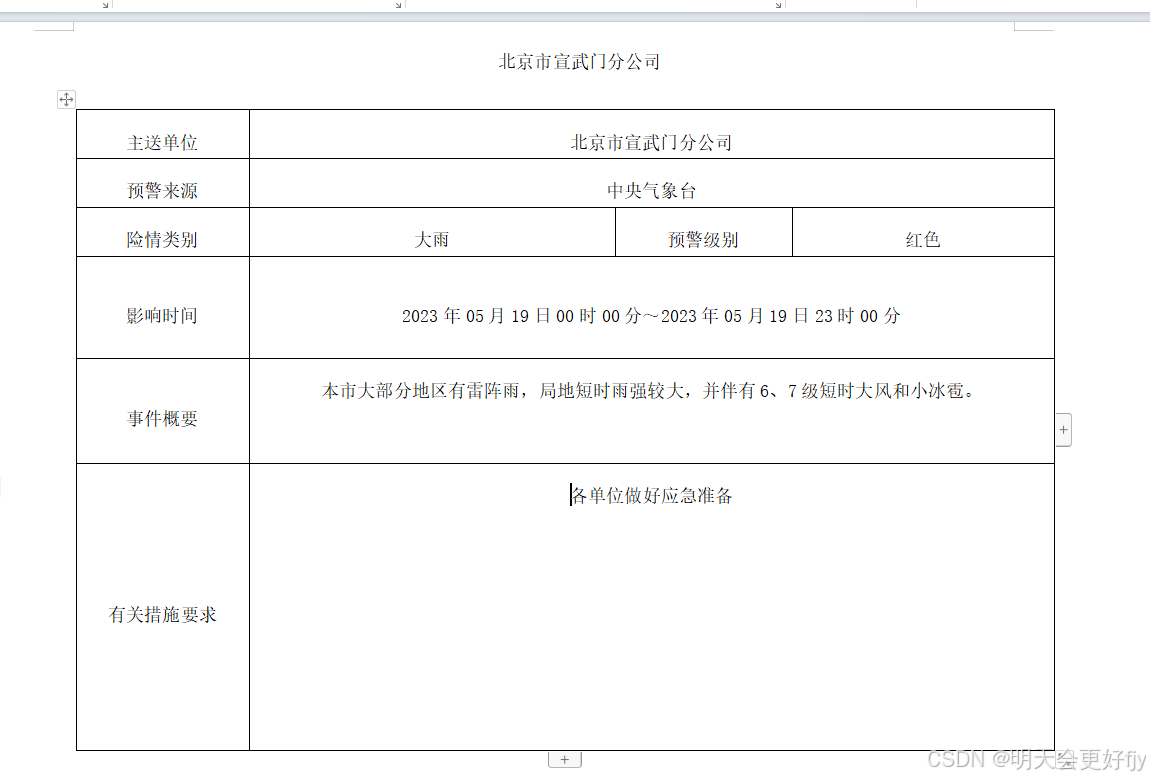
在Controller中
@RequestMapping(value = "/ImportWord") public @RawResponseBody Object ImportWord(HttpServletRequest request, @RequestParam("file") MultipartFile file) throws IOException, ParseException { return gwyjglyjtzBizc.ImportWord(request, file); }在Service的实现类中,
@Override public Object ImportWord(HttpServletRequest request, MultipartFile file) throws ParseException { boolean flag = false; List<String> rowList; String userId = null; String userName = null; String deptId = null; String deptName = null; Map<String, String> userMap = DeptUserUtils.getUserDept(request); if (userMap instanceof Map) { userId = ((Map<?, ?>)userMap).get("userId").toString(); userName = ((Map<?, ?>)userMap).get("userName").toString(); deptId = ((Map<?, ?>)userMap).get("deptId").toString(); deptName = ((Map<?, ?>)userMap).get("deptName").toString(); } String xqlb1 = ""; String xqdj1 = ""; String yjbt1 = ""; try { rowList = POIUtils.readYjtzWord(file); GwYjglYjtz gwYjglYjtz = new GwYjglYjtz(); for (int i = 0; i < rowList.size(); i++) { if (rowList.get(i).equals("主送单位")) { gwYjglYjtz.setFbdw(rowList.get(++i)); } if (rowList.get(i).contains("预警通知")) { yjbt1 += rowList.get(i); } if (rowList.get(i).contains("电缆预警")) { yjbt1 += rowList.get(i); gwYjglYjtz.setYjbt(yjbt1); } if (rowList.get(i).equals("险情类别")) { xqlb1 += rowList.get(++i) + ","; gwYjglYjtz.setXqlb(xqlb1); } if (rowList.get(i).equals("预警来源")) { gwYjglYjtz.setYjly(rowList.get(++i)); } if (rowList.get(i).equals("预警级别")) { xqdj1 += rowList.get(++i) + ","; gwYjglYjtz.setXqdj(xqdj1); } if (rowList.get(i).contains("事件概要")) { String string = rowList.get(++i); gwYjglYjtz.setSjgy(string); } if (rowList.get(i).equals("要求")) { gwYjglYjtz.setYgcsyq(rowList.get(i + 1)); } if (rowList.get(i).equals("影响时间")) { String string = rowList.get(++i); if (string.length() > 0) { String[] split1 = string.split("~"); SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); // 使用SimpleDateFormat来解析日期字符串 SimpleDateFormat originalFormat = new SimpleDateFormat("yyyy年MM月dd日HH时mm分"); // 创建一个新的SimpleDateFormat来格式化输出 SimpleDateFormat targetFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm"); int a = 0; for (String s : split1) { try { Date date = originalFormat.parse(s); // 转换并打印结果 String formattedDate = targetFormat.format(date); System.out.println(formattedDate); if (a == 0) { gwYjglYjtz.setXxkssj(date); } else { gwYjglYjtz.setXxjssj(date); } a++; } catch (Exception e) { e.printStackTrace(); } } } gwYjglYjtz.setDjrid(userId); gwYjglYjtz.setDjr(userName); gwYjglYjtz.setDjdwid(deptId); gwYjglYjtz.setDjdw(deptName); gwYjglYjtz.setCreatetime(new Date()); } } super.add(gwYjglYjtz); flag = true; System.out.print("导入word成功"); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } return flag; }在这里需要通过输入流的方式把里面的内容读取出来,然后存储到集合中。
public static List<String> readYjtzWord(MultipartFile formFile) throws IOException { // 检查文件 checkDocFile(formFile); InputStream fis = formFile.getInputStream(); XWPFDocument document = new XWPFDocument(fis); // 创建返回对象,把每行中的值作为一个数组,所有的行作为一个集合返回 List<String[]> list = new ArrayList<String[]>(); // 遍历文档中的所有段落 List<String> list1 = new ArrayList<String>(); List<XWPFParagraph> paragraphs = document.getParagraphs(); for (XWPFParagraph paragraph : paragraphs) { // 获取并打印段落文本 String text = paragraph.getText(); String trim = text.trim(); String[] lines = trim.split("\n", 2); for (String s : lines) { list1.add(s); } System.out.println(trim); } // 如果需要处理表格,可以这样获取并遍历 List<XWPFTable> tables = document.getTables(); for (XWPFTable table : tables) { for (XWPFTableRow row : table.getRows()) { for (XWPFTableCell cell : row.getTableCells()) { for (XWPFParagraph p : cell.getParagraphs()) { String text = p.getText().trim(); list1.add(text); System.out.println(text); } } } } // 关闭输入流 fis.close(); return list1; }检查是否是指定文件格式
public static void checkDocFile(MultipartFile formFile) throws IOException { // 判断文件是否存在 if (null == formFile) { logger.error("文件不存在!"); throw new FileNotFoundException("文件不存在!"); } // 获得文件名 // String fileName = formFile.getName(); String fileName = formFile.getOriginalFilename(); // 判断文件是否是word文件 if (!fileName.endsWith(DOC) && !fileName.endsWith(DOCX)) { logger.error(fileName + "不是word文件!"); throw new IOException(fileName + "不是word文件!"); } }导出功能
首先我们需要在word 指定对应的模版,对应的字段需要用占位符,这里需要跟数据库的字段需要保持一致或者是和Map 里面的key 。
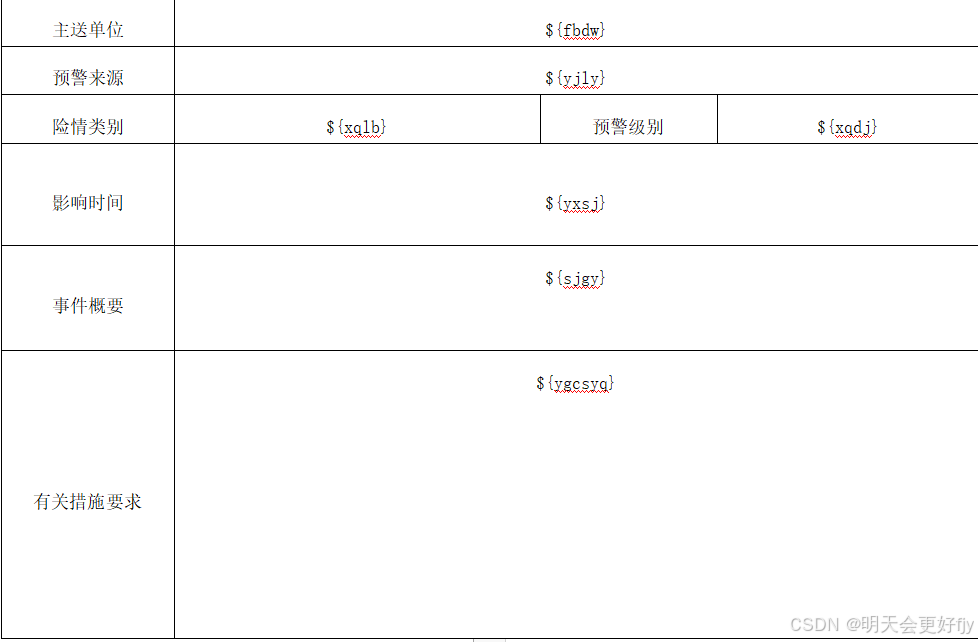
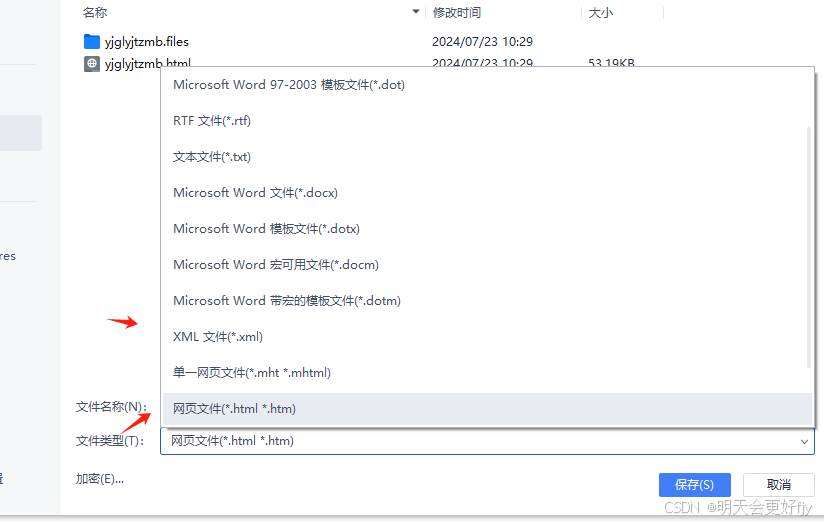
最终模版制作完成后,保存时请注意,文件类型。一般是xml ,由于电脑的原因我选择的是html 格式。
用编辑器打开编码一定要选择utf-8,不然将来导出的时候是乱码。
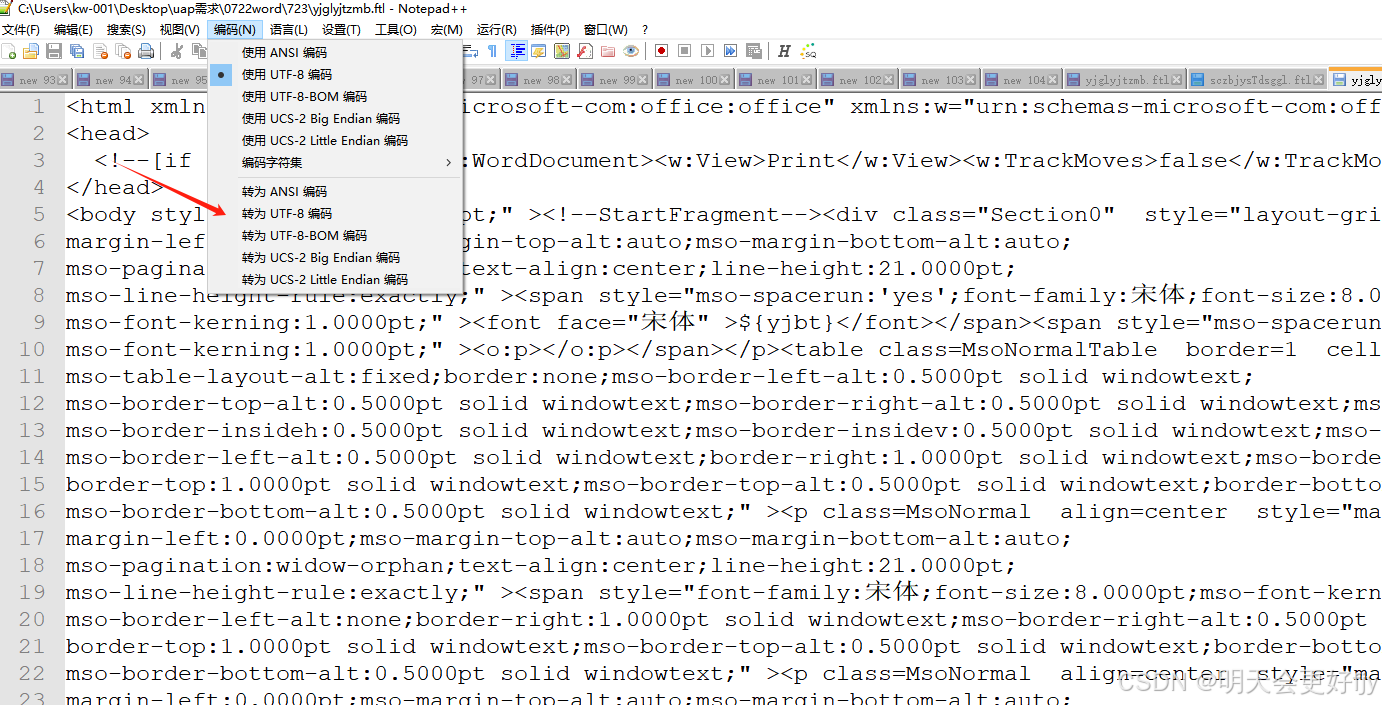

编码格式改后,如果还是出现乱码在head 标签中加入一下内容
<head> <!--[if gte mso 9]><xml><w:WordDocument><w:View>Print</w:View><w:TrackMoves>false</w:TrackMoves><w:TrackFormatting/><w:ValidateAgainstSchemas/><w:SaveIfXMLInvalid>false</w:SaveIfXMLInvalid><w:IgnoreMixedContent>false</w:IgnoreMixedContent><w:AlwaysShowPlaceholderText>false</w:AlwaysShowPlaceholderText><w:DoNotPromoteQF/><w:LidThemeOther>EN-US</w:LidThemeOther><w:LidThemeAsian>ZH-CN</w:LidThemeAsian><w:LidThemeComplexScript>X-NONE</w:LidThemeComplexScript><w:Compatibility><w:BreakWrappedTables/><w:SnapToGridInCell/><w:WrapTextWithPunct/><w:UseAsianBreakRules/><w:DontGrowAutofit/><w:SplitPgBreakAndParaMark/><w:DontVertAlignCellWithSp/><w:DontBreakConstrainedForcedTables/><w:DontVertAlignInTxbx/><w:Word11KerningPairs/><w:CachedColBalance/><w:UseFELayout/></w:Compatibility><w:BrowserLevel>MicrosoftInternetExplorer4</w:BrowserLevel><m:mathPr><m:mathFont m:val='Cambria Math'/><m:brkBin m:val='before'/><m:brkBinSub m:val='--'/><m:smallFrac m:val='off'/><m:dispDef/><m:lMargin m:val='0'/> <m:rMargin m:val='0'/><m:defJc m:val='centerGroup'/><m:wrapIndent m:val='1440'/><m:intLim m:val='subSup'/><m:naryLim m:val='undOvr'/></m:mathPr></w:WordDocument></xml><![endif]--> </head>引入对应的jar包
Controller
@RequestMapping(value = "exportMillCertificate", method = RequestMethod.GET) @ResponseBody public void exportMillCertificate(HttpServletRequest request, HttpServletResponse response, @RequestParam( value = "objId") String objId) throws Exception { gwyjglyjtzBizc.exportMillCertificate(request, response, objId); }Service 的实现类
@Override public void exportMillCertificate(HttpServletRequest request, HttpServletResponse response, String objId) throws Exception { SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); SimpleDateFormat originalFormat = new SimpleDateFormat("yyyy年MM月dd日HH时mm分"); // TODO Auto-generated method stub String sql = "select t.yjbt,t.fbdw,t.yjly,t.xqlb,t.xqdj,t.sjgy,t.ygcsyq,to_char(t.xxkssj,'yyyy-MM-dd hh24:mi:ss') as xxkssj,to_char(t.xxjssj,'yyyy-MM-dd hh24:mi:ss') as xxjssj from GW_GL_T t where t.obj_id=?"; List<Map<String, String>> list = this.hibernateDao.queryForListWithSql(sql, new String[] {objId}); Map<String, String> map0 = new HashMap<String, String>(); Map<String, String> map = new HashMap<String, String>(); if (!Tool.isEmptyList(list)) { map0 = list.get(0); // 应急标题 if (Tool.isEmptyStr(map0.get("yjbt"))) { map.put("yjbt", ""); } else { map.put("yjbt", map0.get("yjbt")); } // 发布单位 if (Tool.isEmptyStr(map0.get("fbdw"))) { map.put("fbdw", ""); } else { map.put("fbdw", map0.get("fbdw")); } // 预警来源 if (Tool.isEmptyStr(map0.get("yjly"))) { map.put("yjly", ""); } else { map.put("yjly", map0.get("yjly")); } // 险情类别 if (Tool.isEmptyStr(map0.get("xqlb"))) { map.put("xqlb", ""); } else { map.put("xqlb", map0.get("xqlb")); } // 预警级别 if (Tool.isEmptyStr(map0.get("xqdj"))) { map.put("xqdj", ""); } else { map.put("xqdj", map0.get("xqdj")); } // 影响时间 if (Tool.isEmptyStr(map0.get("xxkssj"))) { map.put("yxsj", ""); } else { String string = map0.get("xxkssj"); String string1 = map0.get("xxjssj"); Date parse = sdf.parse(string); Date parse1 = sdf.parse(string1); String format1 = originalFormat.format(parse); String format2 = originalFormat.format(parse1); map.put("yxsj", format1 + "~" + format2); } // 事件概要 if (Tool.isEmptyStr(map0.get("sjgy"))) { map.put("sjgy", ""); } else { map.put("sjgy", map0.get("sjgy")); } // 有关措施要求 if (Tool.isEmptyStr(map0.get("ygcsyq"))) { map.put("ygcsyq", ""); } else { map.put("ygcsyq", map0.get("ygcsyq")); } } else { map.put("yjbt", ""); map.put("fbdw", ""); map.put("yjly", ""); map.put("xqlb", ""); map.put("xqdj", ""); map.put("yxsj", ""); map.put("sjgy", ""); map.put("ygcsyq", ""); } // map.put("yxsj", ""); String yjbt = map0.get("yjbt"); WordUtils.exportWord(request, response, map, "yjglyjtzmb.ftl", yjbt);调用工具类的方法生成Word文档
public static void exportWord(HttpServletRequest request, HttpServletResponse response, Map<String, String> map, String templateName, String fileName) throws IOException { String pathString = request.getSession().getServletContext().getRealPath("/WEB-INF/templete/"); logger.info("获取到的模板路径是:templetePath------->" + pathString); configuration.setDirectoryForTemplateLoading(new File(pathString)); Template freemarkerTemplate = configuration.getTemplate(templateName); File file = null; InputStream fin = null; ServletOutputStream out = null; try { // 调用工具类的createDoc方法生成Word文档 file = createDoc(map, freemarkerTemplate); fin = new FileInputStream(file); response.setCharacterEncoding("utf-8"); response.setContentType("application/msword"); // 设置浏览器以下载的方式处理该文件名 // + DateUtil.currentDateToString() fileName = fileName + ".doc"; response.setHeader("Content-Disposition", "attachment;filename=".concat(String.valueOf(URLEncoder.encode(fileName, "UTF-8")))); out = response.getOutputStream(); byte[] buffer = new byte[512]; // 缓冲区 int bytesToRead = -1; // 通过循环将读入的Word文件的内容输出到浏览器中 while ((bytesToRead = fin.read(buffer)) != -1) { out.write(buffer, 0, bytesToRead); } } finally { if (fin != null) fin.close(); if (out != null) out.close(); if (file != null) file.delete(); // 删除临时文件 } } private static File createDoc(Map<String, String> dataMap, Template template) { String name = ".doc"; File f = new File(name); Template t = template; try { // 这个地方不能使用FileWriter因为需要指定编码类型否则生成的Word文档会因为有无法识别的编码而无法打开 Writer w = new OutputStreamWriter(new FileOutputStream(f), "utf-8"); t.process(dataMap, w); w.close(); } catch (Exception ex) { ex.printStackTrace(); throw new RuntimeException(ex); } return f; }最终效果图与导入的是一致里,今天就先到这,在开发过程中不一定会遇到这些,但是觉得还不错那就点赞收藏一波哈,万一哪天用到里。
