
Kafka架构
Kafka架构,由多个组件组成,如下图所示:
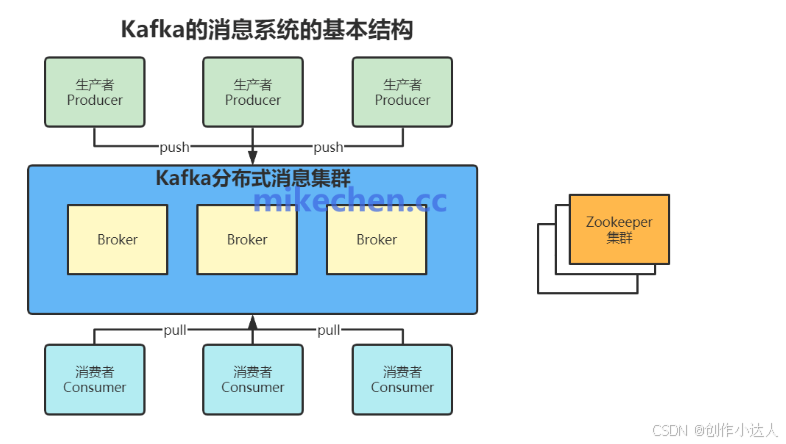
主要会包含:Topic、生产者、消费者、消费组等组件。
服务代理(Broker)
Broker是Kafka集群中的一个节点,每个节点都是一个独立的Kafka服务器。
它负责存储和处理发布到Kafka的消息,消息以主题(topic)的形式进行分类和组织。
如下图所示:
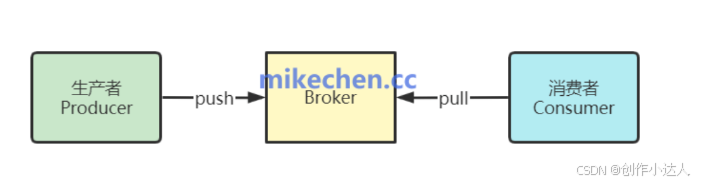
每个Broker可以承载多个主题的分区(partition),并使用日志文件(log)来持久化存储消息。
Topic(主题)
Topic可以理解为一个队列,Topic是消息的分类单元,一个 Topic 又分为一个或多个分区。
每个Topic可以被分成多个分区,每个分区在不同的Broker节点上进行存储。
Topic主题的数据以一系列有序的消息进行组织。
生产者(Producer)
Producer是向Kafka发送消息的客户端应用程序,它将消息发布到指定的主题。
可以选择将消息发送到特定分区,或让Kafka自动选择分区。
如下图所示:
生产者负责将消息进行缓冲和批量发送,以提高性能和吞吐量。
消费者(Consumer)
Consumer是从Kafka订阅和接收消息的客户端应用程序,它订阅一个或多个主题,并从指定的分区中拉取消息。
如下图所示:
消费者可以以不同的消费组(consumer group)形式组织,每个消费组内的消费者共同消费主题中的消息,以实现负载均衡和容错。
Consumer Group(消费组)
消费组是一组具有相同消费者组ID的消费者的集合,在同一个消费组内,每个分区只能由一个消费者进行消费,以实现负载均衡。
如果消费者组中的消费者数量多于主题分区的数量,那么一些消费者将处于空闲状态。
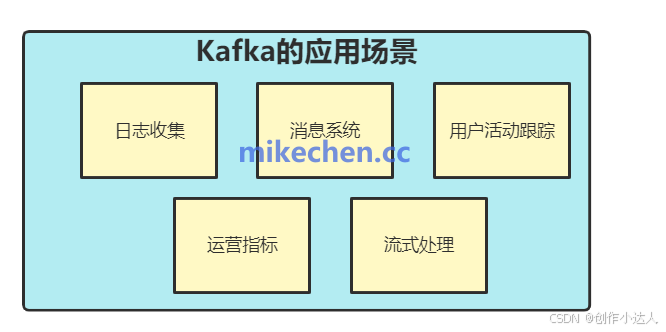
Kafka应用场景
Kafka的应用场景包括:日志收集、事件驱动架构、实时分析、指标监控等,主要用于构建实时流数据管道和流处理应用程序。
-
消息系统:Kafka可以作为一个高效的消息中间件,用于解耦生产者和消费者。
-
指标监控:Kafka可以用于实时监控和分析,将指标数据发送到Kafka,然后通过流处理工具(如Spark Streaming)进行处理和告警。
-
事件驱动架构:Kafka可作为事件驱动架构的一部分,用于收集和传递各种事件。
-
日志聚合:Kafka可以作为日志聚合的解决方案,将各种日志数据集中聚合到一个地方。
-
分布式追踪:Kafka可以用于分布式系统跟踪,将各种数据发送到Kafka中进行实时处理和分析。
kafka 为什么会那么快?
一共有四个原因
-
磁盘顺序读写
-
PageCache 页缓存技术
-
零拷贝技术
-
kafka 分区架构
磁盘顺序读写
生产者发送数据到 kafka 集群中,最终会写入到磁盘中,会采用顺序写入的方式。消费者从 kafka 集群中获取数据时,也是采用顺序读的方式。无论是机械磁盘还是固态硬盘 SSD,顺序读写的速度都是远大于随机读写的。
-
机械磁盘顺序读写省去了
磁头频繁寻址和旋转盘片的开销 -
固态硬盘SSD以Page为单位做读写,以Block为单位做垃圾回收。写相同数据量的情况下,顺序写
制造更少的垃圾Block,所以比随机写有更高的性能。
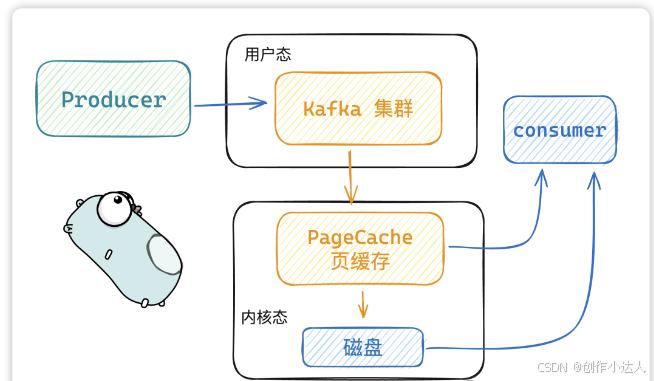
PageCache 页缓存技术
-
当 kafka 有写操作时,先将数据写入
PageCache中,然后在顺序写入到磁盘中。 -
当读操作发生时,先从
PageCache中查找,如果找不到,再去磁盘中读取。
零拷贝技术
一般性能的瓶颈都是网络io、磁盘io。我们来看下从磁盘读取数据到网卡场景下,传统 IO 的整个过程:
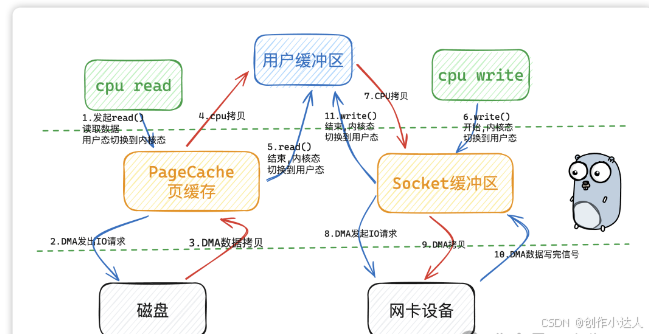
DMA方式,Direct Memory Access,也称为成组数据传送方式,有时也称为直接内存操作。DMA方式在数据传送过程中,没有保存现场、恢复现场之类的工作。
传统 IO 模型下,从磁盘读取数据,写到网卡设备中,经历了 4 次用户态和内核态之间的切换和数据的拷贝。红色箭头为数据拷贝。 那能不能让拷贝次数发送的少一点呢?但是kafka 采用了 sendfile 的零拷贝技术
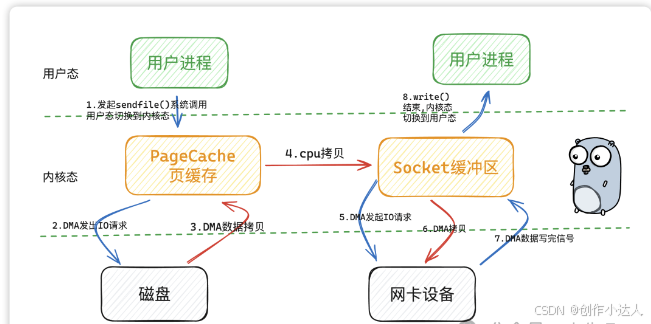
所谓的零拷贝技术不是指不发生拷贝,而是在用户态没有进行拷贝。