
阅读量:0
目录
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
本文目标:在Ubuntu系统上部署使用LivePortrait ,感谢快手团队对开源世界的贡献。
项目地址:https://github.com/KwaiVGI/LivePortrait
论文地址:https://arxiv.org/pdf/2407.03168
项目论文介绍
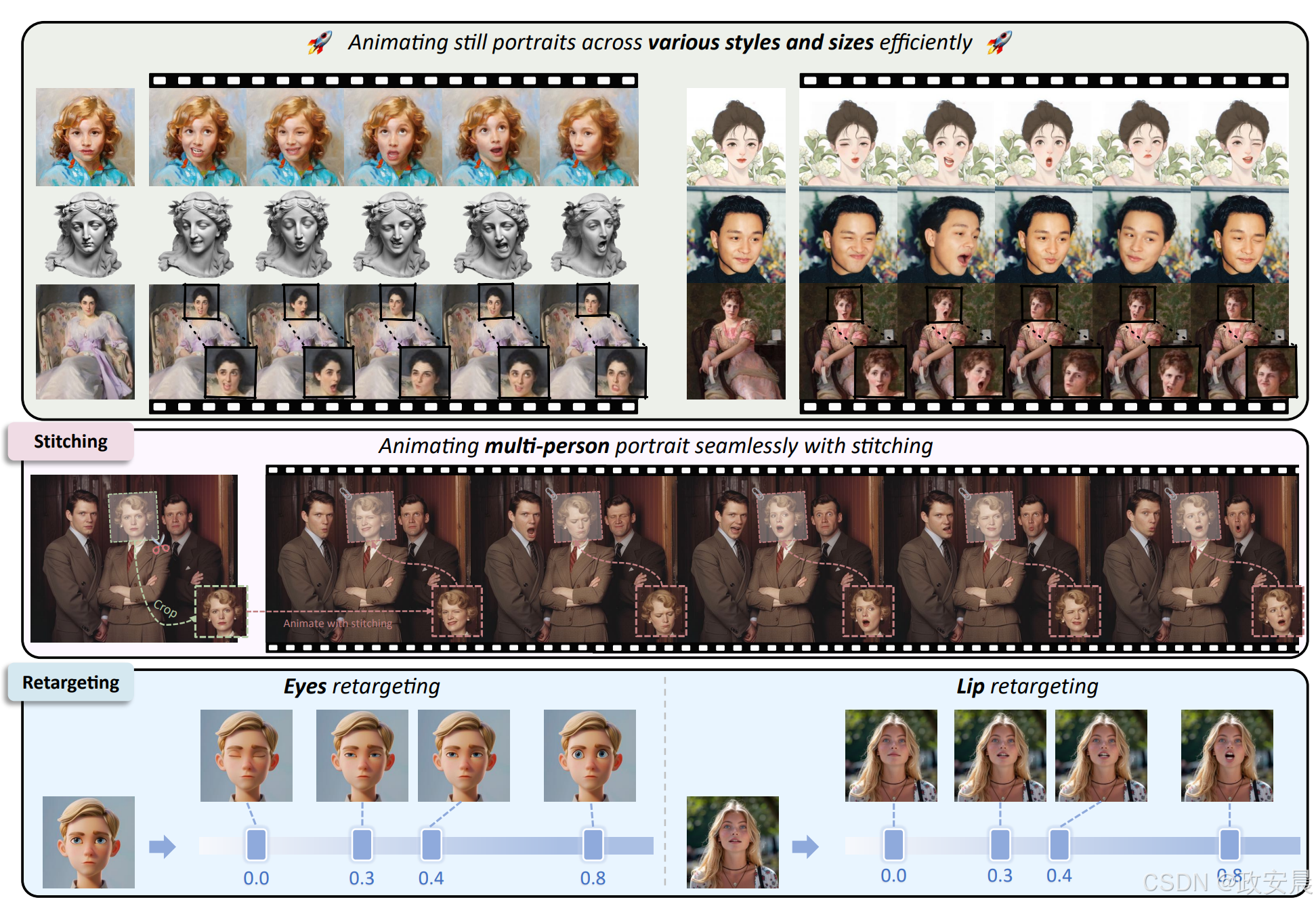
上图表达:该项目的模型产生了定性肖像动画。只要输入一张静态的肖像图像,我们的模型就能将其制作成生动的动画、确保无缝拼接,并能精确控制眼睛和嘴唇的动作。
肖像动画旨在从单个源图像中合成逼真的视频,使用它作为外观参考,并利用来自驱动视频、音频、文本或生成的运动(即面部表情和头部姿态)。
该项目不按照主流的基于扩散的方法进行探索和扩展,而是探索和扩展了基于隐式关键点的框架的潜力,该框架能够有效地平衡计算效率和可控性。在此基础上,该项目开发了一个名为LivePortrait的视频驱动肖像动画框架,重点关注更好的泛化性、可控性和效率,以便实际应用。为了提高生成质量和泛化能力,我们将训练数据扩大到约6900万帧高质量图像,采用混合图像-视频训练策略,升级网络架构,并设计更好的运动转换和优化目标。此外,我们发现紧凑的隐式关键点可以有效地表示一种混合形状,并精心提出了一个拼接和两个重新定位模块,利用小型MLP几乎没有计算开销,以增强可控性。实验结果表明,即使与基于扩散的方法相比,我们的框架也显著有效。在配备PyTorch的RTX 4090 GPU上,生成速度达到了12.8毫秒。
现如今,人们经常使用智能手机或其他录像设备来捕捉静态肖像,记录他们宝贵的时刻。iPhone上的实况照片功能可以通过录制拍摄前后1.5秒的时刻将静态肖像变得生动起来,可能是通过一种形式的视频录制实现的。然而,基于最近的进展,如生成对抗网络(GANs)和扩散,各种肖像动画方法使得将静态肖像转化为动态肖像成为可能,而不依赖于特定的录像设备。
在这篇论文中,我们的目标是给静态肖像图像添加动画,使其更具真实感和表现力,并同时追求高推理效率和精确可控性。尽管基于扩散的肖像动画方法在质量方面取得了令人印象深刻的结果,但它们通常计算成本高昂,并且缺乏精确的可控性,例如缝合控制。相反,我们广泛探索了基于隐式关键点的视频驱动框架,并扩展了它们的潜力,以有效平衡通用能力、计算效率和可控性。
论文中实际开展的工作
最近的基于视频的肖像动画方法可以分为非扩散和扩散两种方法,如表所总结。
(视频驱动的肖像动画方法摘要)
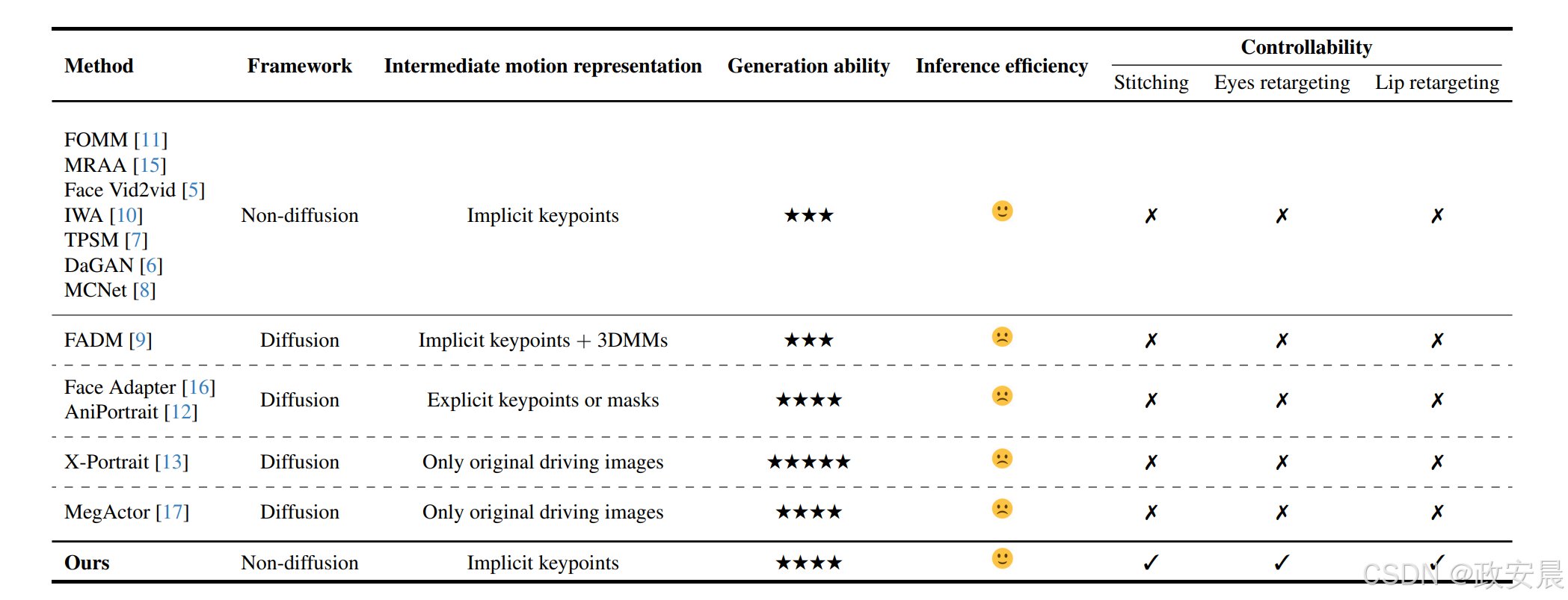
非扩散性的肖像动画
对于非扩散模型,基于隐式关键点的方法使用隐式关键点作为中间运动表示,并通过光流将源肖像图与驱动图像扭曲。FOMM 在每个关键点附近执行一阶Taylor展开,并使用局部仿射变换近似每个关键点附近的运动。MRAA 利用基于PCA的运动估计表示了关节动作。Face vid2vid 通过引入3D隐式关键点表示扩展了FOMM,并实现了自由视角的肖像动画。IWA 基于跨模态注意力改进了扭曲机制,可以扩展到使用多个源图像。为了更灵活地估计光流并更好地处理大尺度运动,TPSM 使用非线性薄板样条变换表示更复杂的运动。同时,DaGAN 利用密集深度图来估计捕捉关键驱动运动的隐式关键点。MCNet 设计了一个以身份表示为条件的记忆补偿网络,以解决复杂驱动运动引起的生成模糊问题。
该项目在工作中使用了预定义的动作表示,如3DMM blendshapes。另一些工作提出了从头学习潜在表达表示的方法。MegaPortrait利用高分辨率图像升级动画分辨率到百万像素。EMOPortraits使用一个富含表情的训练视频数据集和表情增强的损失来表达强烈的动作。
基于扩散的肖像动画
扩散模型通过迭代地去除噪音,从高斯噪声中合成所需的数据样本。之后,提出了潜在扩散模型(LDMs),并将训练和推理过程转移到压缩的潜在空间中以进行高效计算。LDMs已广泛应用于全身舞蹈生成、音频驱动的肖像动画和视频驱动的肖像动画等许多并发工作中。
FADM 是第一个基于扩散的肖像动画方法。它通过预训练的隐式关键点模型获得粗略的动画结果,然后在3DMMs的指导下使用扩散模型得到最终的动画效果。Face Adapter 使用身份适配器来增强源肖像的身份保持,并使用空间条件生成器来生成明确的空间条件,即关键点和前景遮罩,作为中间的动作表示。
一些作品使用了相互自注意力和类似于AnimateAnyone 的时间注意力架构,以实现更好的图像质量和外观保持。AniPortrait使用明确的空间条件,即关键点,作为中间运动表示方法。X-Portrait 提出直接使用原始驱动视频来为肖像画提供动画效果,而不是使用中间的运动表示方法。它使用了基于隐式关键点的方法进行跨身份训练。MegActor 也使用原始驱动视频来为源肖像画提供动画效果。它使用现有的人脸交换和风格化框架来获取跨身份训练对,并对背景外观进行编码以提高动画的稳定性。
方法论
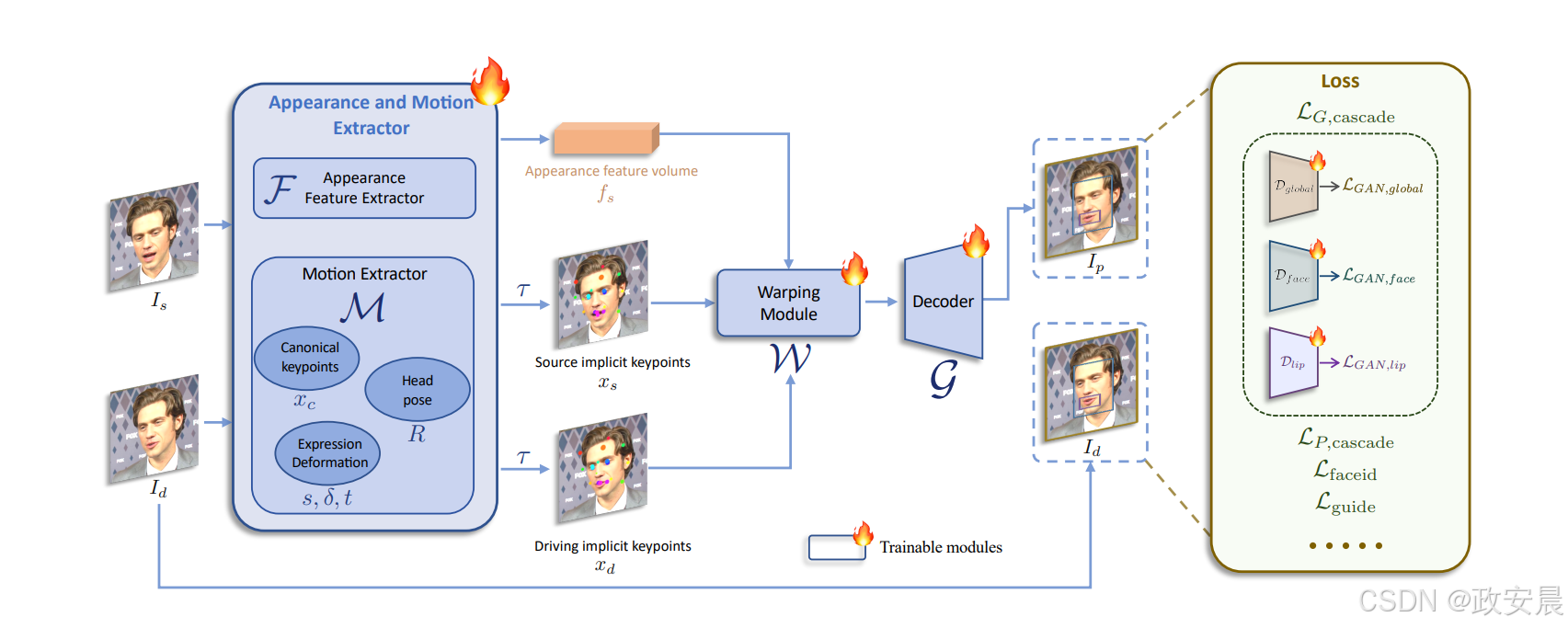
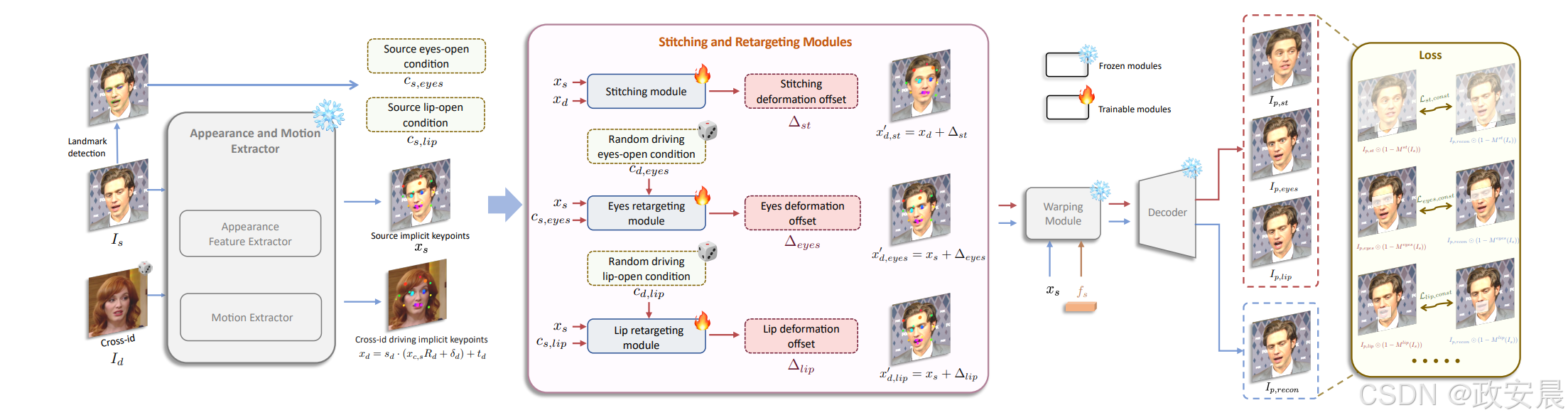
该项目首先简要回顾了基于视频的人像动画框架face vid2vid ,并介绍了项目的重要改进,旨在增强动画的泛化能力和表现力。然后,论文介绍了精心设计的拼接和重新定位模块(感兴趣的小伙伴可以看原始论文,我们这里是为大家基于ubuntu系统部署项目并应用,所以,论文部分仅是简要介绍,小伙伴们多包涵,嘻嘻 —— 政安晨注),这些模块提供了所需的可控性,且计算开销极小。最后,论文详细介绍了推理流程。
关键效果对比:


咱们接下来即将部署的这个名为 LivePortrait 的 repo 包,含有论文 LivePortrait 的官方 PyTorch 实现: 具有拼接和重定向控制功能的高效肖像动画的 PyTorch 官方实现。 项目团队也正在积极更新和改进此软件源。
基于Ubuntu的部署实践开始
1. 克隆代码并准备环境
git clone https://github.com/KwaiVGI/LivePortrait cd LivePortrait # create env using conda conda create -n LivePortrait python=3.9 conda activate LivePortrait # install dependencies with pip # for Linux and Windows users pip install -r requirements.txt # for macOS with Apple Silicon users pip install -r requirements_macOS.txt过程演绎如下:
下载项目
建立环境

安装依赖
注意:确保您的系统已安装 FFmpeg,包括 ffmpeg 和 ffprobe! - 项目团队说明
—— 在咱们这篇实验中,政安晨的电脑已经安装。

2. 下载预训练权重
下载预训练权重的最简单方法是从 HuggingFace 下载:
# first, ensure git-lfs is installed, see: https://docs.github.com/en/repositories/working-with-files/managing-large-files/installing-git-large-file-storage git lfs install # clone and move the weights git clone https://huggingface.co/KwaiVGI/LivePortrait temp_pretrained_weights mv temp_pretrained_weights/* pretrained_weights/ rm -rf temp_pretrained_weights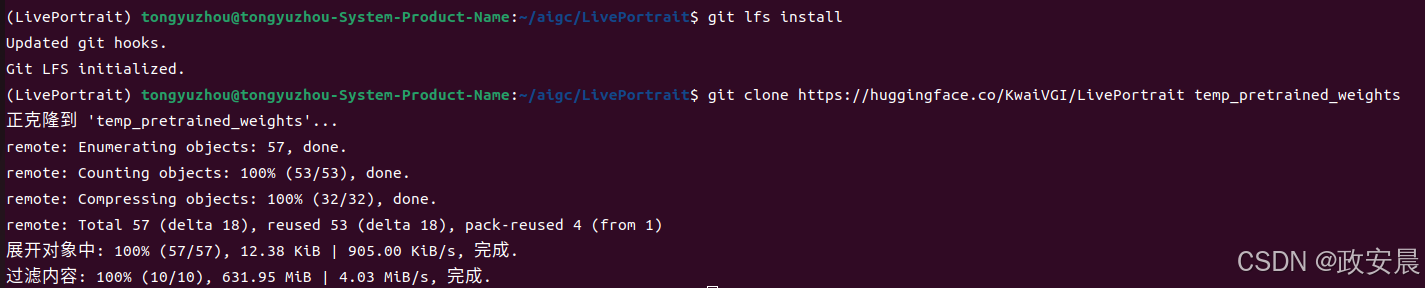
![]()

确保目录结构如下或包含以下内容:
pretrained_weights
├── insightface
│ └── models
│ └── buffalo_l
│ ├── 2d106det.onnx
│ └── det_10g.onnx
└── liveportrait
├── base_models
│ ├── appearance_feature_extractor.pth
│ ├── motion_extractor.pth
│ ├── spade_generator.pth
│ └── warping_module.pth
├── landmark.onnx
└── retargeting_models
└── stitching_retargeting_module.pth
3. 推理
快速上手
# For Linux and Windows python inference.py # For macOS with Apple Silicon, Intel not supported, this maybe 20x slower than RTX 4090 PYTORCH_ENABLE_MPS_FALLBACK=1 python inference.py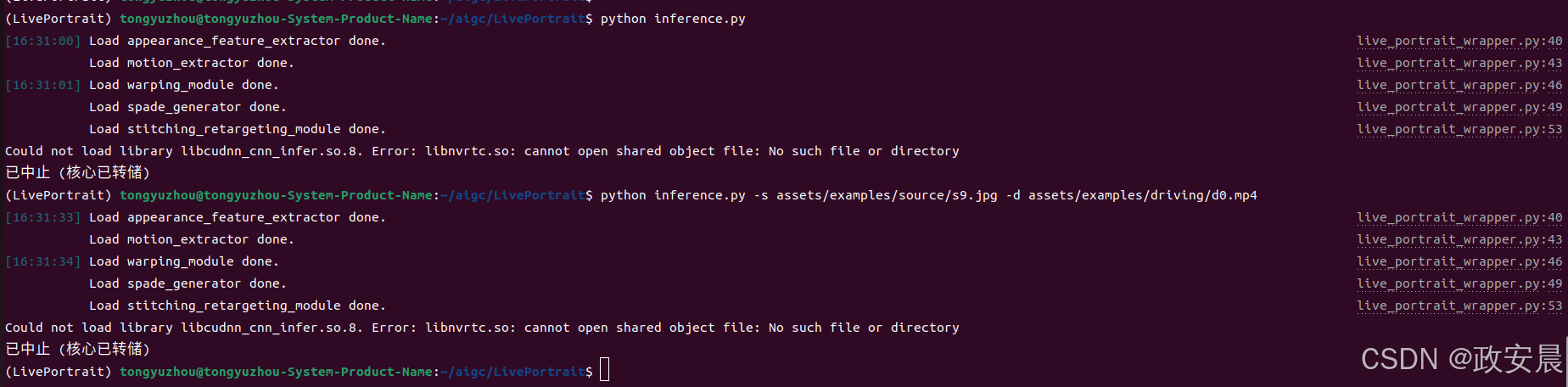
如上图所示,在执行推理的过程中,您可能会遇到错误,重新安装几个包,如我下图:
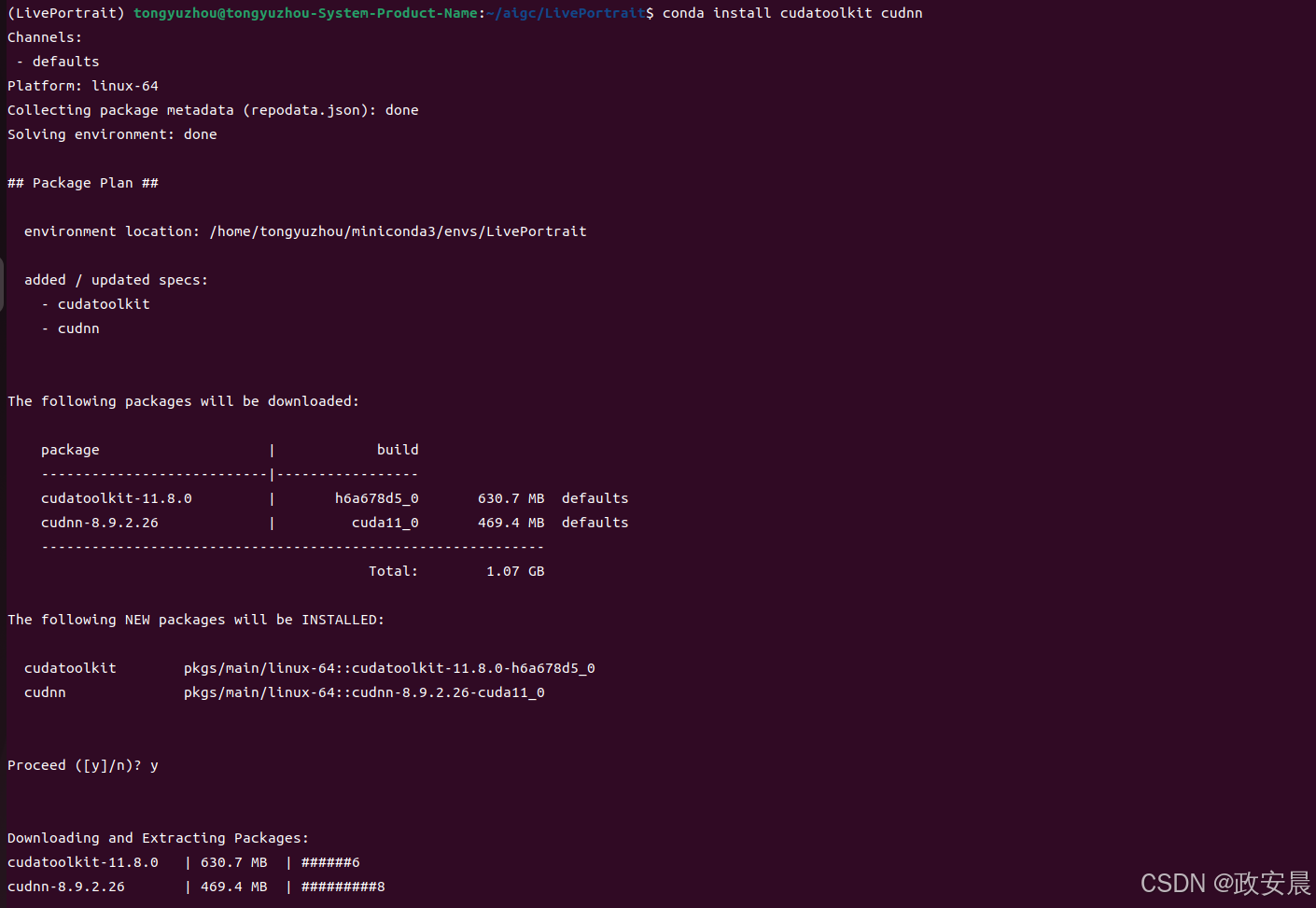
再重新执行推理:
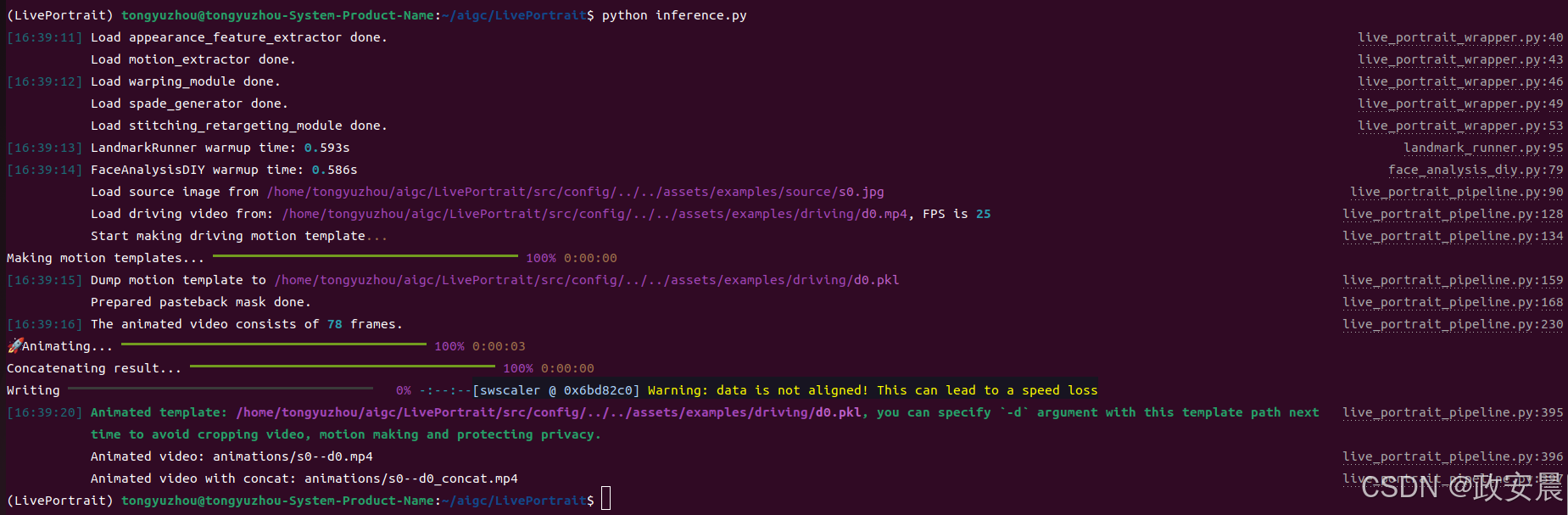
(成功!)
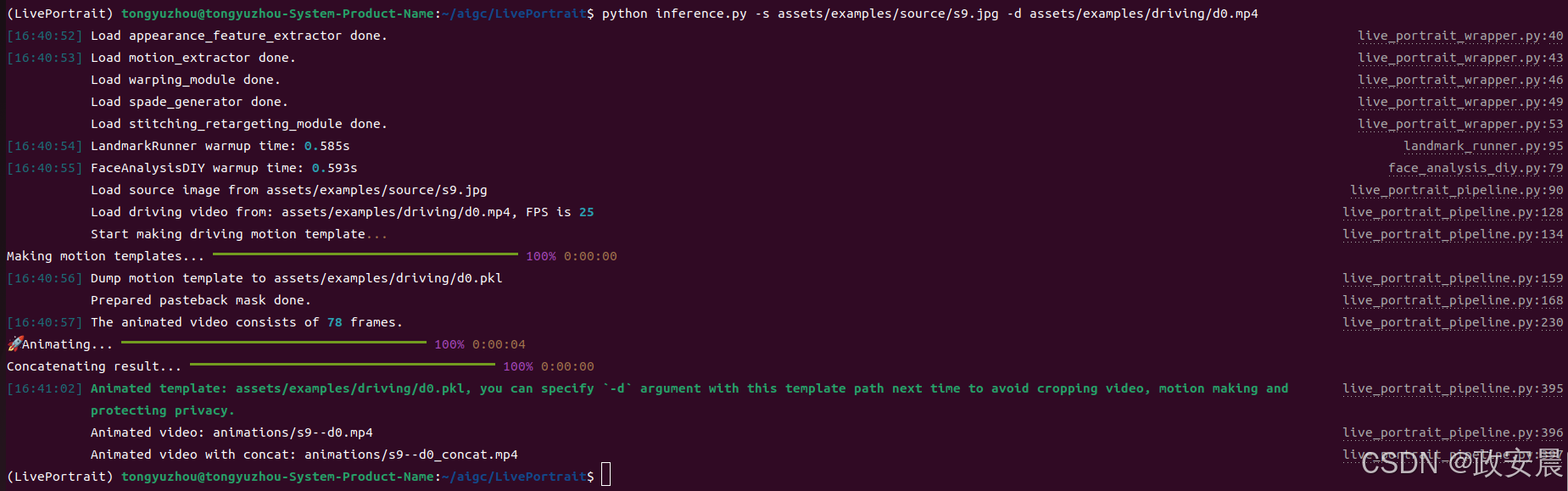

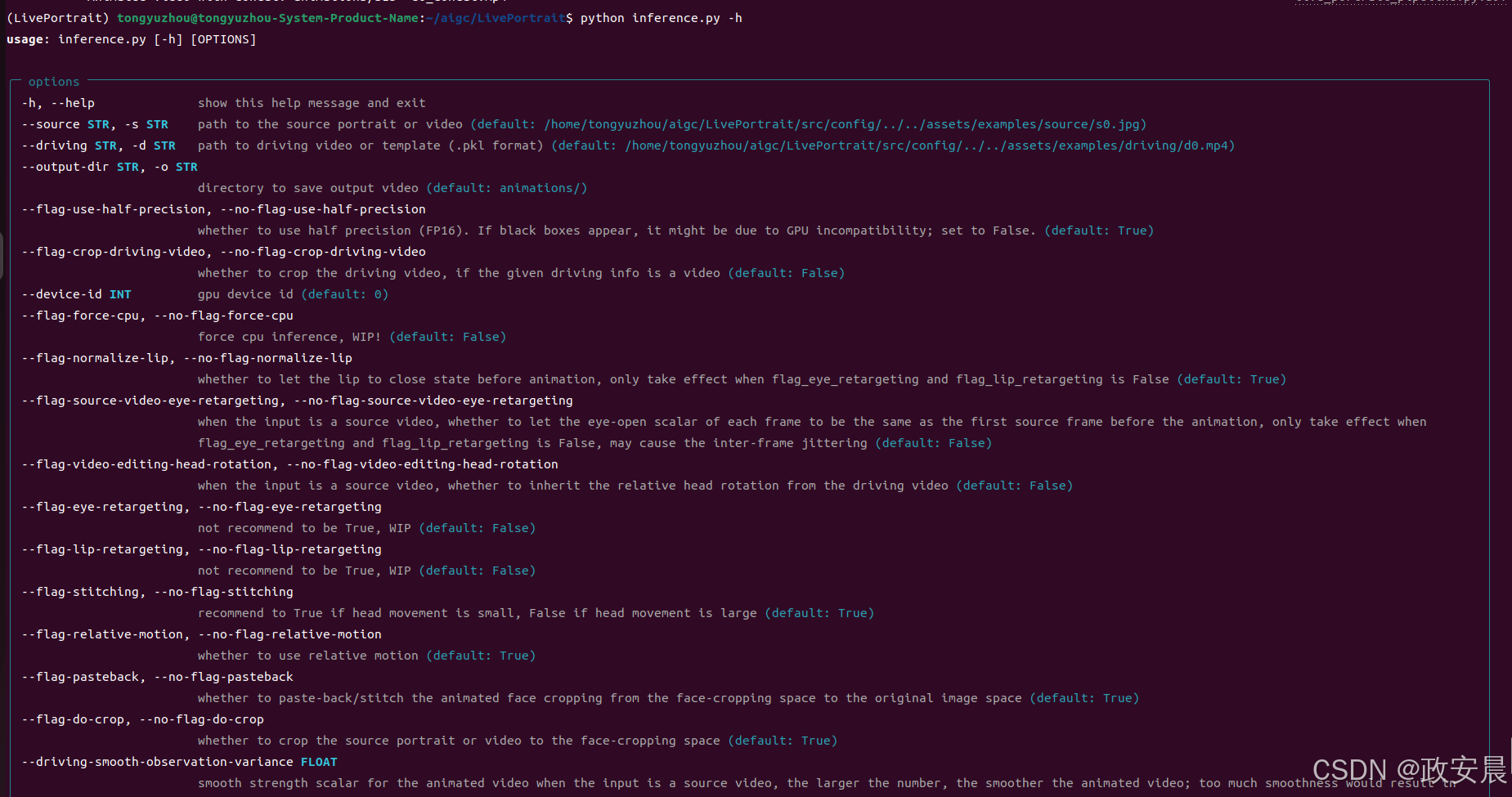
查看帮助:
如果脚本运行成功,就会得到一个名为 animations/s6--d0_concat.mp4 的 mp4 输出文件。 该文件包括以下结果:驱动视频、输入图像或视频以及生成结果。

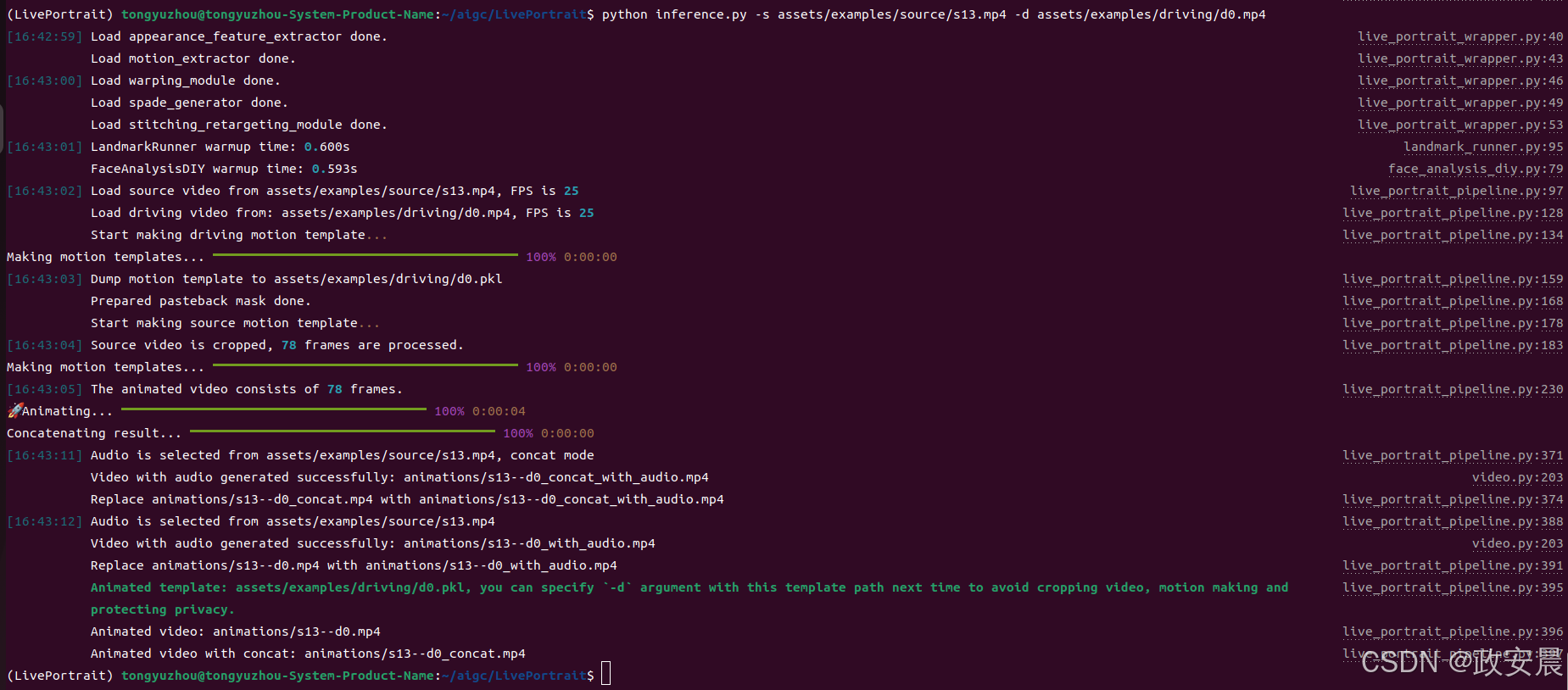
或者,也可以通过指定 -s 和 -d 参数来更改输入:
# source input is an image python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d0.mp4 # source input is a video ✨ python inference.py -s assets/examples/source/s13.mp4 -d assets/examples/driving/d0.mp4 # more options to see python inference.py -h(后面的用法,小伙伴们自己探索吧!)
驱动视频自动裁剪
若要使用自己的驱动视频,建议您:
—— Crop it to a 1:1 aspect ratio (e.g., 512x512 or 256x256 pixels), or enable auto-cropping by --flag_crop_driving_video. —— Focus on the head area, similar to the example videos. —— Minimize shoulder movement. —— Make sure the first frame of driving video is a frontal face with neutral expression.以下是通过 --flag_crop_driving_video 进行自动裁剪的案例:
python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d13.mp4 --flag_crop_driving_video如果发现自动裁剪效果不佳,可以修改 --scale_crop_driving_video、--vy_ratio_crop_driving_video 选项来调整缩放比例和偏移量,或者手动调整。
运动模板制作
您还可以使用自动生成的以 .pkl 结尾的运动模板文件来加快推理速度,并保护隐私,例如:
python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d5.pkl # portrait animation python inference.py -s assets/examples/source/s13.mp4 -d assets/examples/driving/d5.pkl # portrait video editing4. Gradio 界面
我们还提供了 Gradio 界面,只需运行即可获得更好的体验:
# For Linux and Windows users (and macOS with Intel??) python app.py # For macOS with Apple Silicon users, Intel not supported, this maybe 20x slower than RTX 4090 PYTORCH_ENABLE_MPS_FALLBACK=1 python app.py
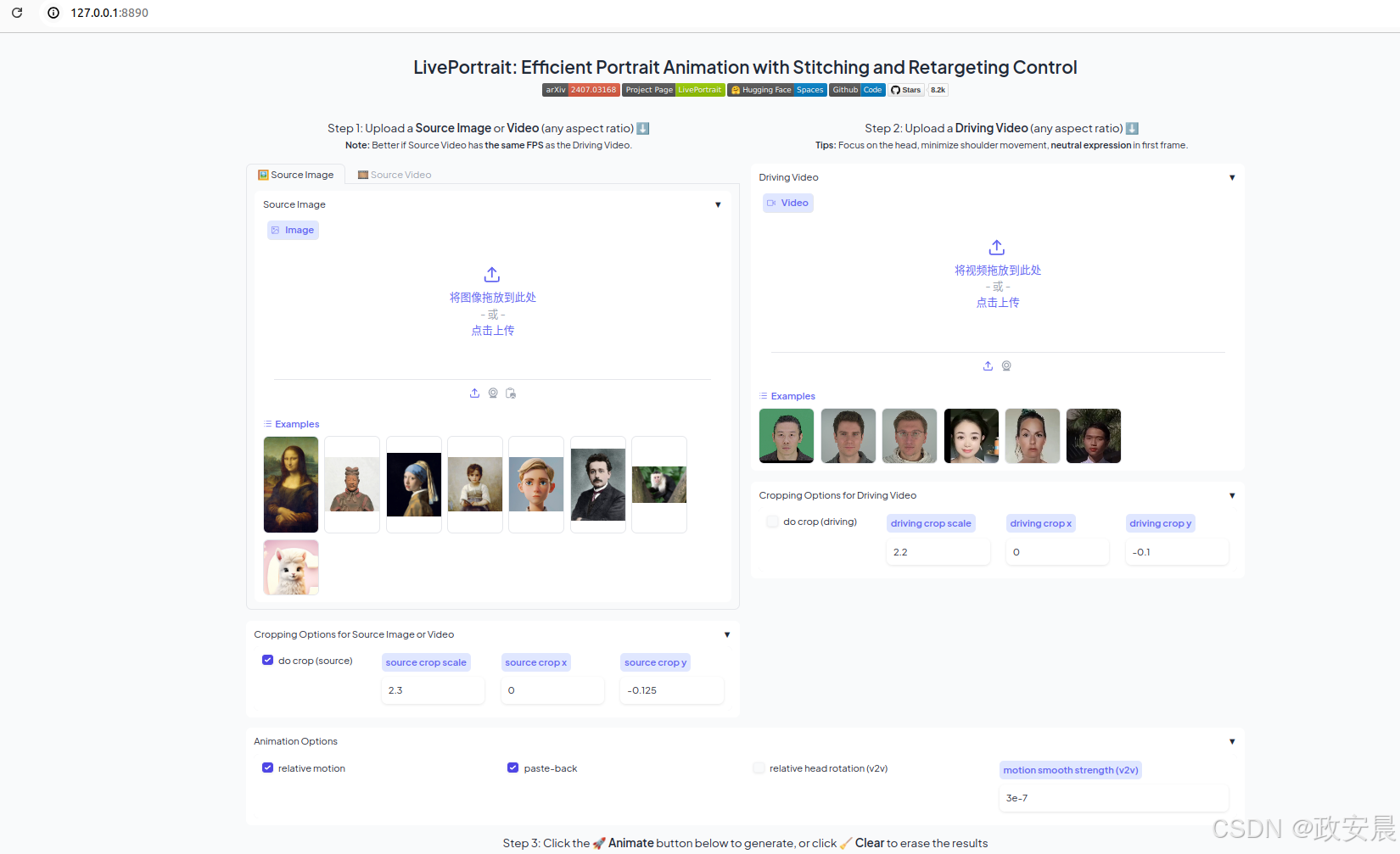
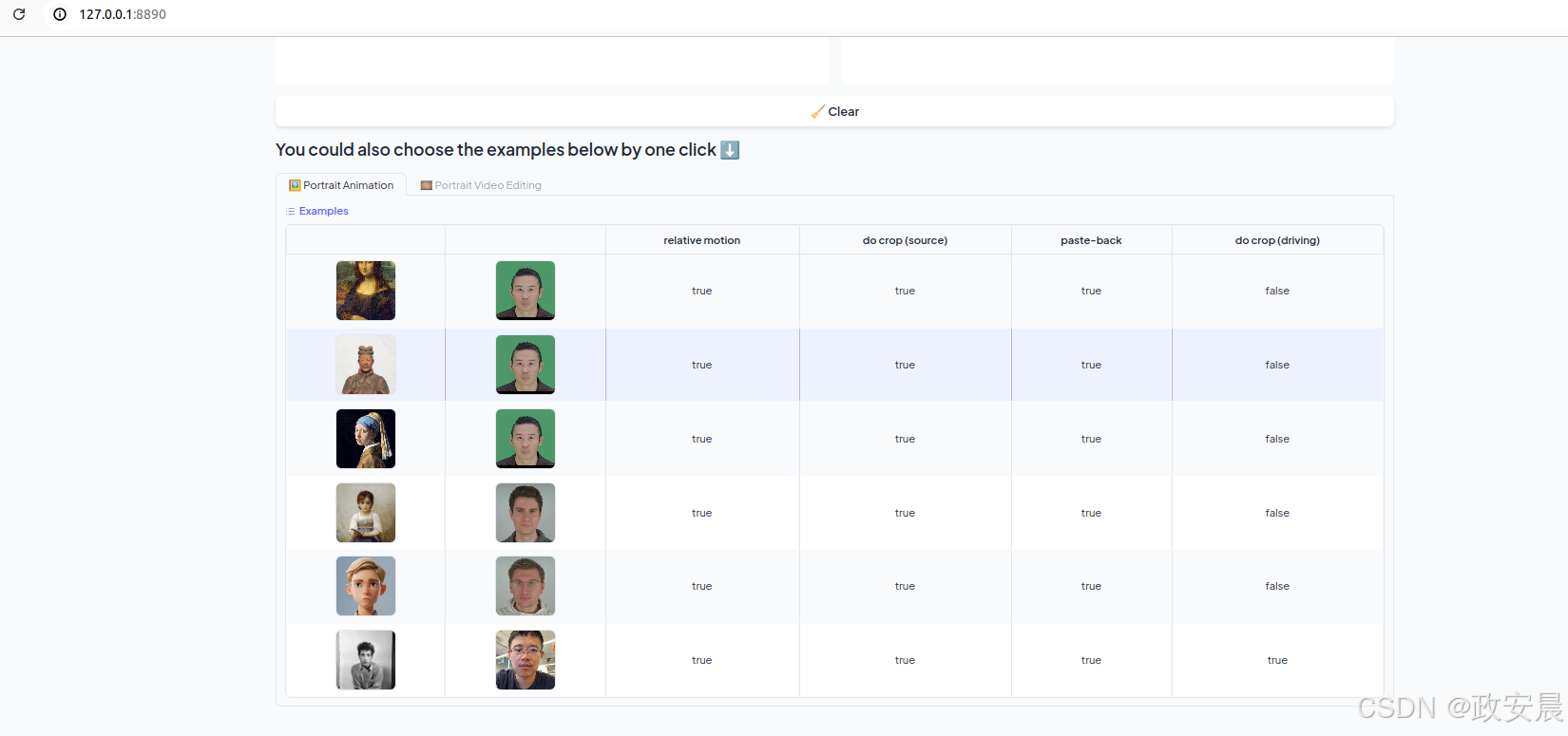
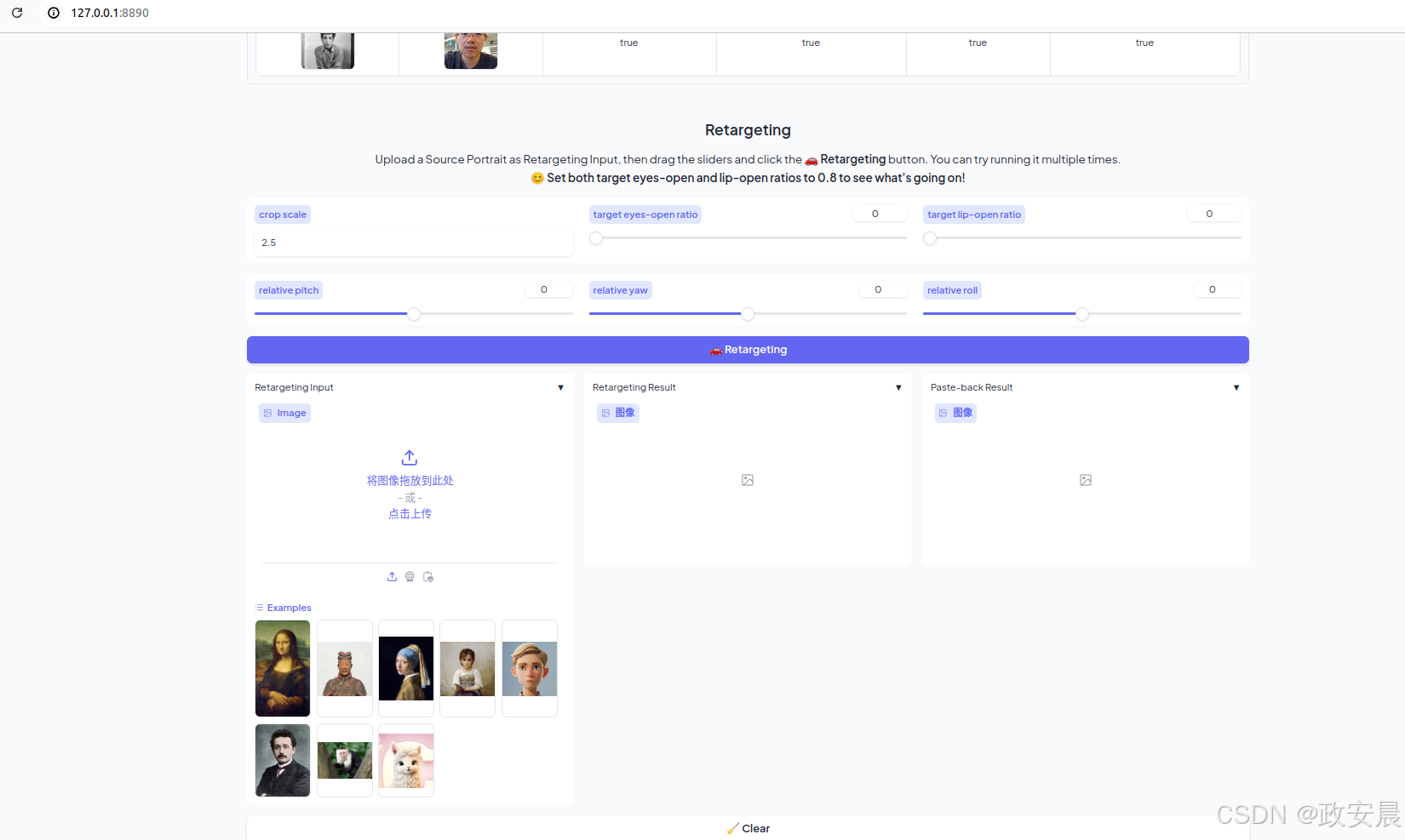
您可以根据需要指定 --server_port、--share 和 --server_name 参数!
我们还提供了一个加速选项--flag_do_torch_compile。 首次推理会触发一个优化过程(约一分钟),使后续推理速度提高 20-30%。 不同 CUDA 版本的性能提升可能有所不同。
# enable torch.compile for faster inference python app.py --flag_do_torch_compile注意:Windows 和 macOS 不支持此方法。
—— 这也是政安晨坚持探索Linux部署应用各类开源AI框架的原因。
5. 推理速度评估
我们还提供了一个脚本,用于评估每个模块的推理速度:
# For NVIDIA GPU python speed.py以下是使用本地 PyTorch 框架和 torch.compile 在 RTX 4090 GPU 上推断一帧图像的结果:
| Model | Parameters(M) | Model Size(MB) | Inference(ms) |
|---|---|---|---|
| Appearance Feature Extractor | 0.84 | 3.3 | 0.82 |
| Motion Extractor | 28.12 | 108 | 0.84 |
| Spade Generator | 55.37 | 212 | 7.59 |
| Warping Module | 45.53 | 174 | 5.21 |
| Stitching and Retargeting Modules | 0.23 | 2.3 | 0.31 |
注:"缝合 "和 "重定向 "模块的数值代表三个连续 MLP 网络的综合参数数量和总推理时间。
社区资源
探索项目社区提供的宝贵资源,提升您的 LivePortrait 体验:
项目社区一定是还做出了更多了不起的贡献!
再次感谢开源项目团队的付出,该项目在Ubuntu系统上部署执行,很好地推动了一些相关工作的进展!
