
阅读量:0
7月17日,我们在《隐私计算匿踪查询技术深入浅出》中介绍了关于隐私计算中匿踪查询的定义和常见算法,并引出了前沿算法Simple PIR的介绍,本次将对Simple PIR进行正式的算法原理介绍。
1. Simple PIR快览
1.1 性能介绍
Simple PIR是Alexandra Henzinger等人在2023 USENIX Security Symposium发表的论文《One Server for the Price of Two: Simple and Fast Single-Server Private Information Retrieval》所涉及的算法【1】。
先来看下该算法的性能表现,性能好才值得深入。可以看到,Simple PIR直接将匿踪查询的生产性能门槛打掉了,服务端吞吐量(处理性能)基本接近最快的two-server PIR,而且在通信消耗上也是能接受的,如果是对通信量要求高的场景,可以采用DoublePIR,虽然服务端处理性能大概会比SimplePIR少1/3左右,但是通信消耗基本与SealPIR相当,且服务端处理性能是SealPIR的近60倍【1,2】。
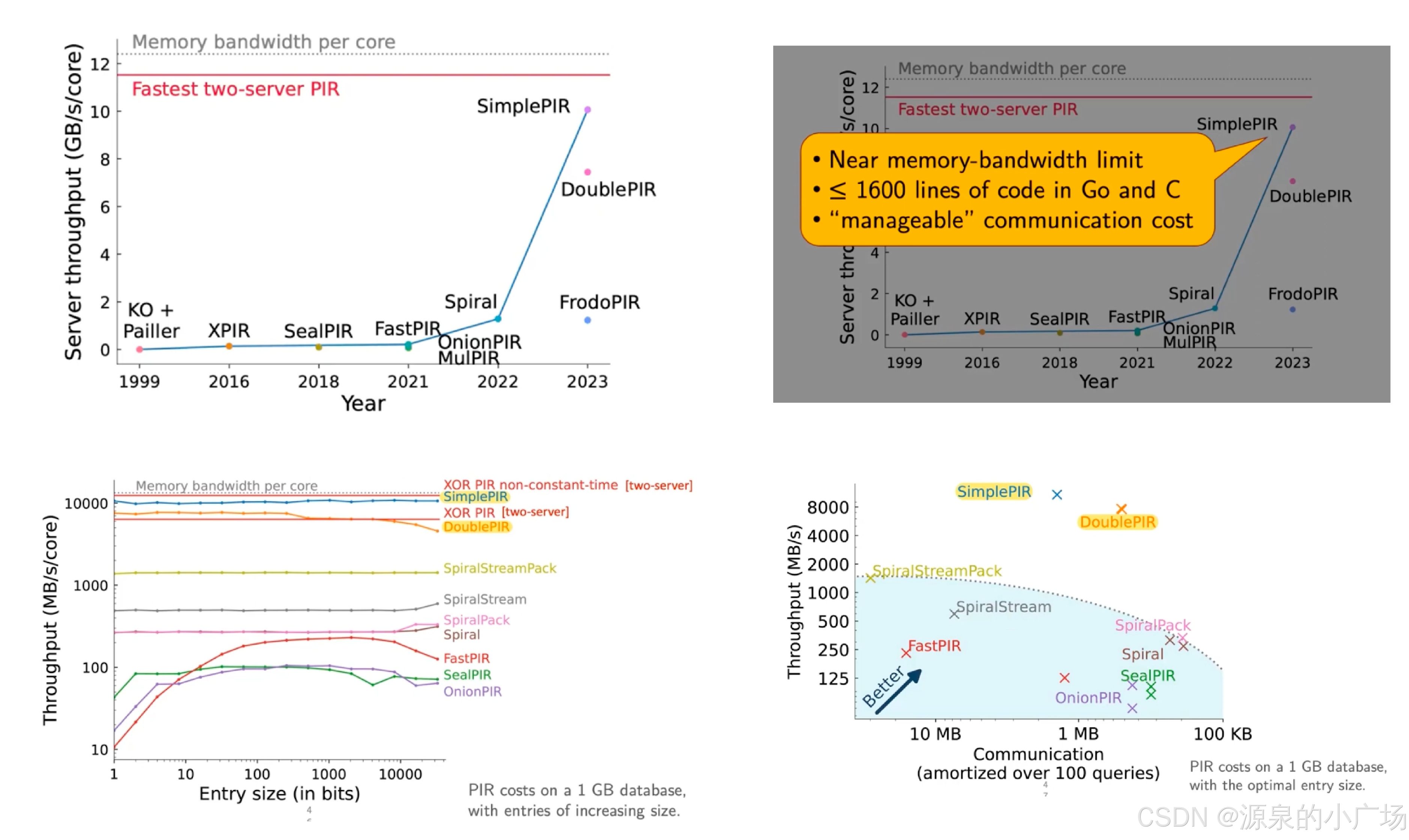
图1. SimplePIR&DoublePIR性能表现
论文给出了SimplePIR和DoublePIR在离线预处理阶段的计算与通信消耗,离线阶段会计算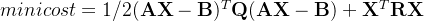 ,也就是db与矩阵A的矩阵乘,后续在算法原理步骤中会详细介绍。在线阶段的计算和通信消耗相对较小。这种采用offline pre-compution + online的模式,在PIR中也比较常见,比如Labeled PSI版本中setup阶段的预处理,会将最耗时的计算放在离线阶段完成。不过,虽然DoublePIR的性能已经有显著提升,但是在数据库行很长时,还是需要注意其通信代价。
,也就是db与矩阵A的矩阵乘,后续在算法原理步骤中会详细介绍。在线阶段的计算和通信消耗相对较小。这种采用offline pre-compution + online的模式,在PIR中也比较常见,比如Labeled PSI版本中setup阶段的预处理,会将最耗时的计算放在离线阶段完成。不过,虽然DoublePIR的性能已经有显著提升,但是在数据库行很长时,还是需要注意其通信代价。
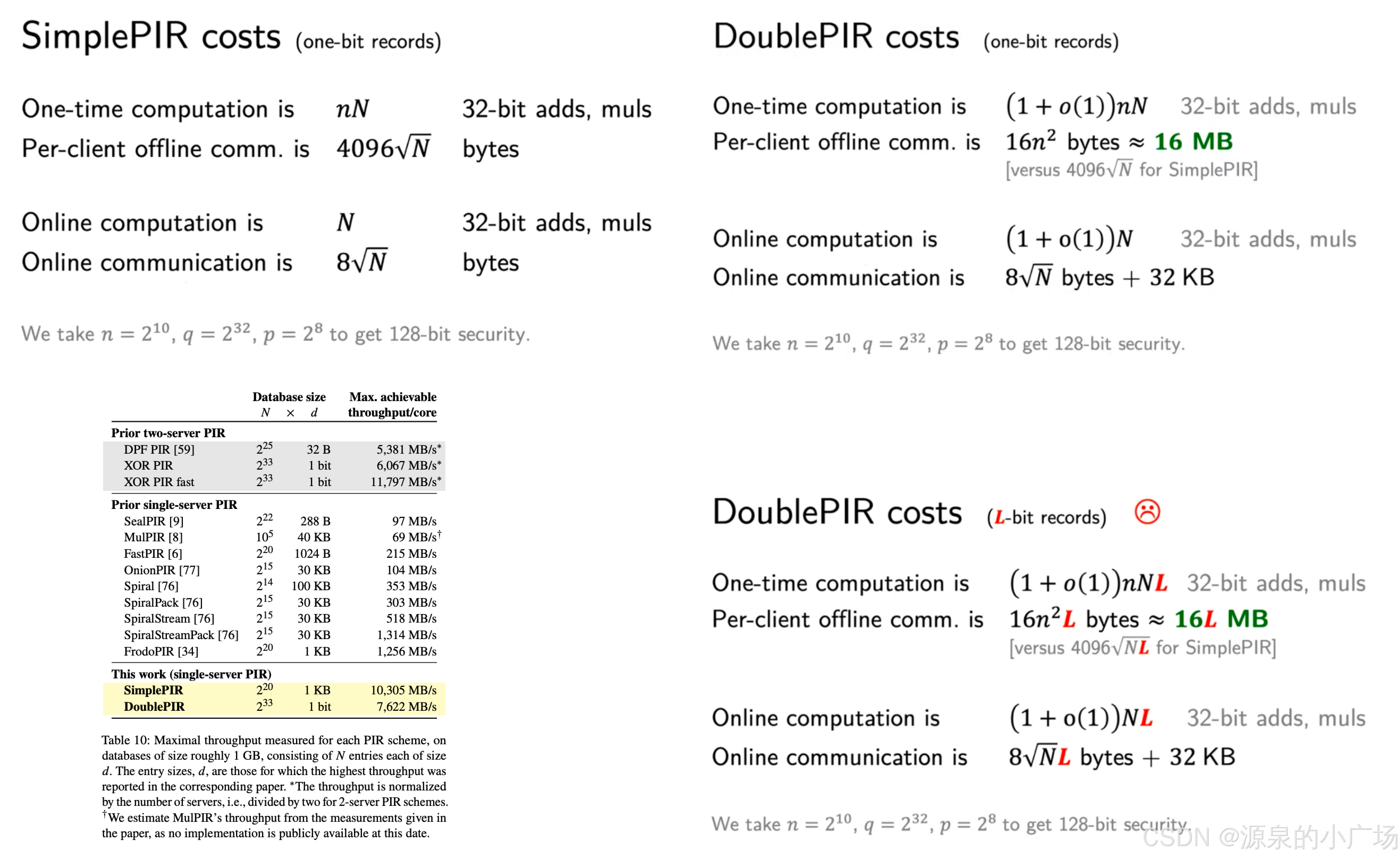
图2. SimplePIR&DoublePIR在离线阶段与在线阶段的计算与通信消耗
1.2 算法灵感来源
SimplePIR的原理,先抛开复杂的具体公式和步骤,本质上可以用两句话来描述:
1. (online)带有Regev encryption【3】的"Square-root" single-server PIR【4】方案;
2. (offline)服务器可以在一次性的预处理阶段中完成99.9%的工作。
接下来主要解释一下online的要点,offline比较容易理解,大头的计算放在离线阶段完成,提升在线阶段的处理效率。
1.2.1 Square-root” single-server PIR
这里的“Square-root” single-server PIR,其实是【4】提出的方案,可以理解为是一种简单的基于同态加密的匿踪查询方案,服务端原始数据有N,通过平方根,转换为边长的多维矩阵的形式,这样客户端发送的密文大小就只需要个,如图3所示,整体原理比较简单,基于同态加密实现,通过明文与密文的乘法得到最终的查询密文结果,返回客户端后进行解密,服务端由于是密文不能知晓查询的信息,客户端拿到的结果只有1对应的位置,其他位置为0,因此也不能知晓除查询外的其他信息。
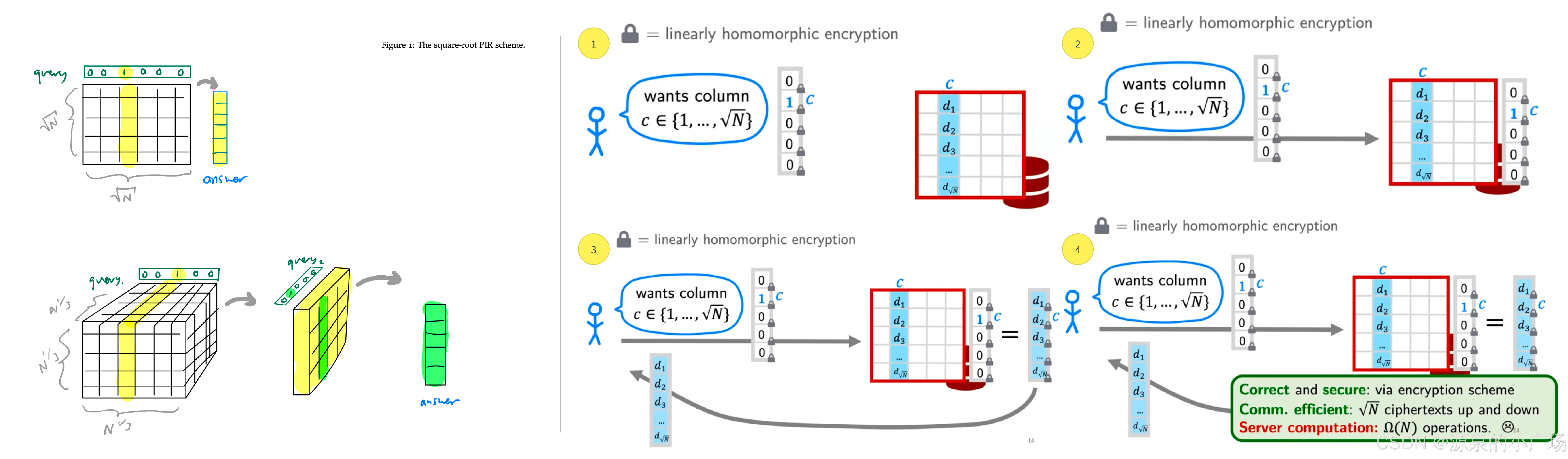
图3. Square-root single-server PIR
1.2.2 Regev encryption(LWE scheme)
Regev加密是Oded Regev【3】提出的一种基于格理论的公钥加密方案。它主要用于实现抗量子计算机攻击的密码系统。Regev加密方案的安全性基于Learning With Error问题,这是一个被广泛认为在量子计算机上也难以破解的问题。
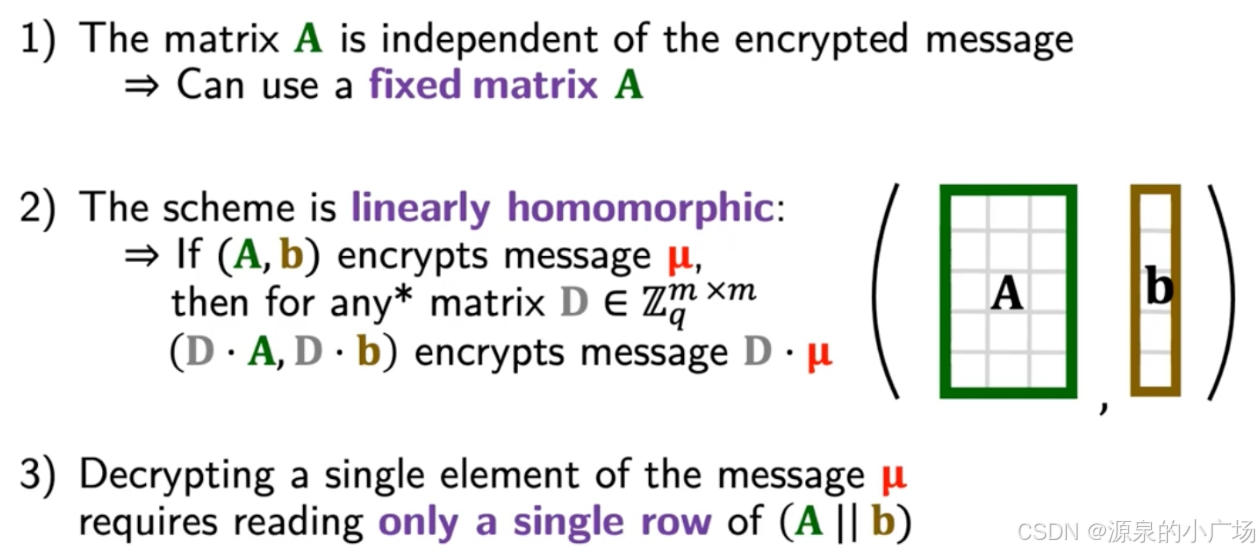
图4. Regev's encryption关键点
Regev加密方案的其他一些关键点:
- 基于LWE问题:Learning With Error问题是Regev加密方案的核心,它通过在向量中加入随机误差来增加解密的难度。
- 安全性:Regev加密方案在经典计算机和量子计算机上都具有很高的安全性。
- 公钥和私钥生成:公钥由一个矩阵和一个向量组成,私钥则是一个小向量。加密和解密操作都使用这些公私钥进行。
- 加密过程:消息通过与公钥矩阵进行矩阵计算,并加入随机误差来加密。解密过程则利用私钥和一个简单的矩阵运算来去除误差,从而恢复消息。
图5展示了LWE的加解密过程,结合Regev加密方案关键点来理解。LWE加解密思路是实现SimplePIR的核心,还需要讲解为什么LWE可以被用于PIR,接下来继续分析。
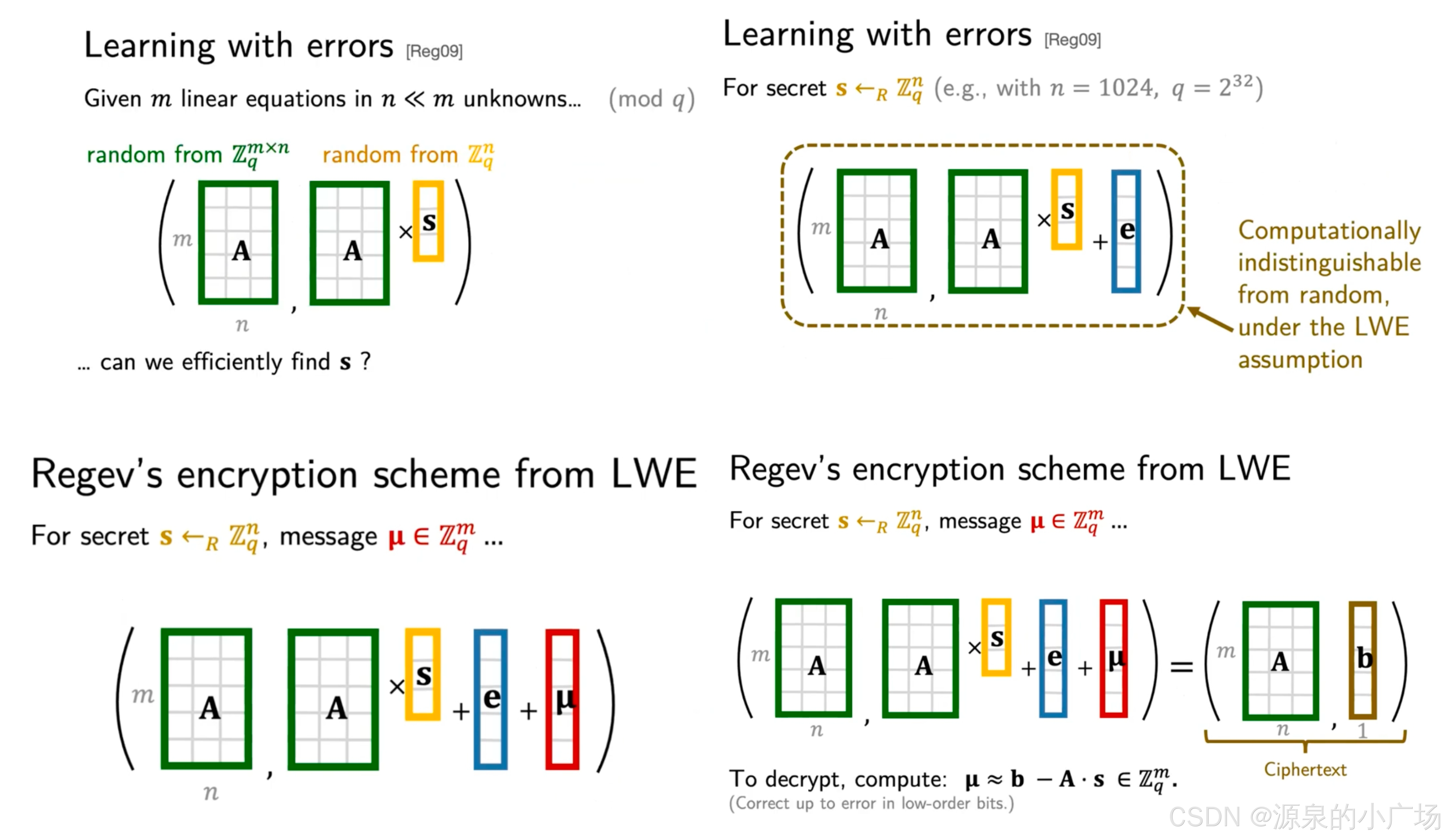
图5. Regev's encryption scheme from LWE
1.2.3 Learning with errors (LWE)及其同态特性
1.2.3.1 LWE示例
参考【6】中信息进行相应介绍。图6给出LWE示例,这个问题被称为“Learning with Error”或LWE,试图在数据中含有误差的情况下学习向量𝑠。输出的每一行可以称为一个“LWE样本”,因为它是向量𝐴的一行与𝑠的点积的噪声“观察值”。因此,误差也常被称为“噪声”,它所采样的分布称为“噪声分布”。挑战在于从最多𝑚个LWE样本中确定𝑠。
即使参数选择非常小,解决这个问题也被认为是非常困难的。例如,密码学家认为,当𝑛=512,𝑞=3329(模),误差均匀地采样自[-3,3]时,解决这个问题是很困难的。无论攻击者获得多少LWE样本,这个问题实例都很难解决,所以我们会说,对于这些参数,𝑚=∞。具体而言,称这些参数“难”意味着以下问题很难(实际上不可能)解决:
- 生成一个包含512个随机数的向量,每个数在[0,3328]范围内,称之为𝑠。
- 生成一个包含512个随机数的向量,每个数在[0,3328]范围内,称之为𝑎。
- 从集合{3326,3327,3328,0,1,2,3}中生成一个随机数,称之为𝑒。
- 计算𝑏=𝑎⋅𝑠+𝑒,其中⋅表示点积。
- 输出(𝑎,𝑏)。 可以重复步骤2-5,每次获得一个新的(𝑎,𝑏),次数不限。
- 找出𝑠。
到目前为止,讨论了LWE问题的“搜索”版本——试图在有噪声的样本中‘找到’𝑠。为了使用LWE构建加密,处理一个相关的LWE版本会很有用,我们称之为“区分”问题,这也被认为是困难的。在这个问题版本中,我们必须区分(𝐴,𝑏),其中𝑏=𝐴𝑠+𝑒(如上所述),和一个完全随机采样的(𝐴,𝑏)。也就是说,我们给出(𝐴,𝑏),需要猜测𝑏是“LWE方式”采样的,还是随机采样的。密码学家假设,对于前述相同的𝑛和𝑞选择,没有算法可以以高于极低(>2^−128)的概率输出正确的猜测。假设这个问题是困难的,我们可以用它来构建密码学,这被称为决策LWE假设,或‘DLWE’(在大多数情况下,决策变种实际上被证明等价于搜索变种,所以它通常也被称为‘LWE’)。
安全参数𝜆正式地捕捉了区分这些函数输出“非常困难”的概念——例如,如果DLWE假设在𝜆=128时成立,那么任何能够进行少于2^128次操作的攻击者都无法有效区分𝑏=𝐴𝑠+𝑒(如上所述)和完全随机采样的(𝐴,𝑏)。这种LWE样本“在计算上无法与随机区分”的概念是使其对加密有用的关键属性。这里省略对为什么DLWE假设成立以及在哪些参数下成立的深入解释。这仍然是一个活跃的研究领域,并且数学非常复杂。我们将假设对于某些𝑛、𝑞和噪声分布的选择,DLWE问题是完全不可解的。
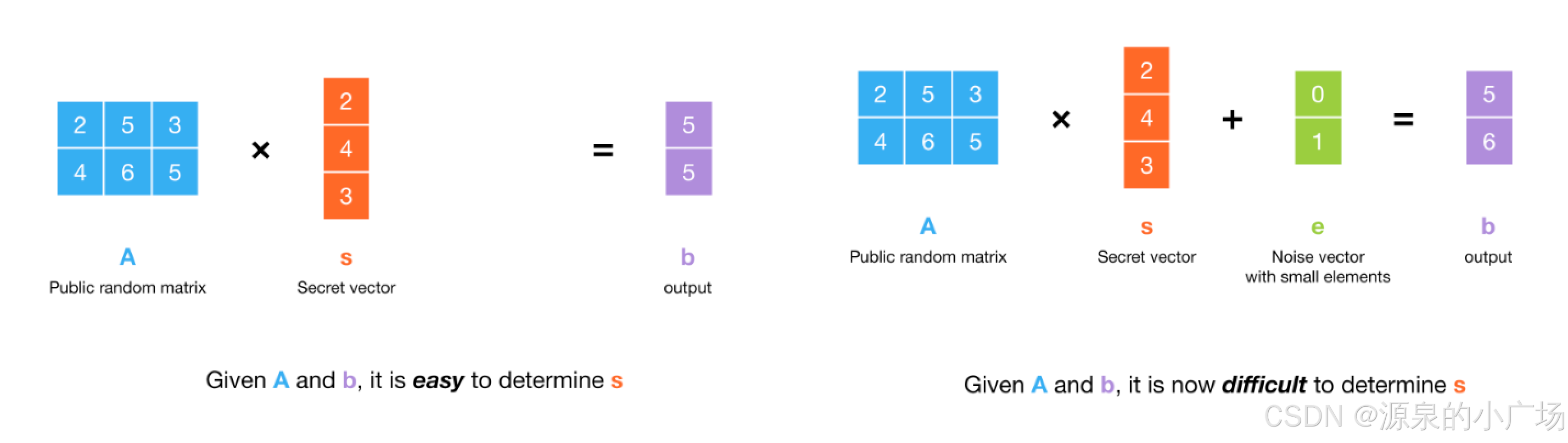
图6. LWE例子
1.2.3.2 Homomorphic Encryption from LWE(同态特性)
在了解了LWE问题不可解之后,接下来看看如何用它构建同态加密。首先,我们将使用LWE构建普通加密,然后尝试使其同态化。
假设我们有一个秘密密钥𝑠,从𝑍𝑞中均匀随机抽样。然后,DLWE假设表明,对于一个随机矩阵𝐴和噪声向量𝑒,向量𝑏=𝐴𝑠+𝑒是无法与随机区分的,利用这一点来构建加密。
从简单开始,假设我们想加密一个比特𝑥∈{0,1}。利用𝑏无法与随机区分的事实来加密𝑥。假如从𝑍𝑞中抽取了一个真正的均匀随机元素𝑟,然后给你𝑟+𝑥,你将无法得知关于𝑥的任何信息(记住𝑍𝑞是模q的整数,所以它“环绕”)。这是因为𝑟是随机选择的,所以无论𝑥是什么,𝑟+𝑥看起来仍然是随机的;密码学家称这为“盲化”。
现在,我们知道(𝐴,𝑏)实际上不是随机的;但是,根据DLWE假设,对于不知道密钥的攻击者,它也无异于随机的——在可行的操作量内无法与随机区分。让我们尝试用(𝐴,𝑏)盲化𝑥。由于𝑥只是一个比特,我们将把我们的𝑚设置为1进行加密——这使得𝑏是𝑍𝑞中的一个单值,因此我们可以将𝑥加密为密文(𝐴,𝑐=𝑏+𝑥)。
因为在可行的操作量内无法与随机进行区分,因此将消息𝑥添加到LWE样本中的𝑏会给我们一个密文(𝐴,𝑐=𝑏+𝑥),它不会向攻击者泄露任何关于𝑥的信息。解下来看看如何使用秘密密钥解密这个密文呢?
要用秘密密钥𝑠解密密文(𝐴,𝑐),我们可以计算𝑐−𝐴𝑠,并得到:
𝑐−𝐴𝑠=(𝑏+𝑥)−𝐴𝑠=((𝐴𝑠+𝑒)+𝑥)−𝐴𝑠=𝑥+𝑒
这给了我们非常接近我们想要的结果。我们的目标是恢复𝑥,但我们得到了𝑥+𝑒。回想一下,𝑒是从噪声分布中采样的噪声,所以它不是均匀随机的。然而,由于𝑥∈{0,1},我们无法从𝑥+𝑒中提取消息𝑥,因为我们的噪声分布是一个范围较小的居中分布。回想之前的参数示例:𝑛=512,𝑞=3329,噪声分布为[−3,3];在𝑒是-3到3之间的随机整数的情况下,不可能恢复𝑥,因为𝑥是0或1。
因此,我们需要对如何在密文中编码消息𝑥做一个小改动。我们不再只是直接添加我们的消息值0或1(𝑐=𝑏+𝑥),而是添加消息的“放大”版本:我们将消息加密为𝑐=𝑏+⌊𝑞/2⌋⋅𝑥。这里,值⌊𝑞/2⌋是𝑞除以2并向下取整到最近的整数。这样做的目的是,当我们用𝑐−𝐴𝑠解密时,我们会得到⌊𝑞/2⌋⋅𝑥+𝑒。如果𝑒是从一个比⌊𝑞/2⌋小得多的范围内采样的,那么现在可以从𝑥+𝑒中恢复𝑥——只需要“丢弃低位”噪声。基本上,检查𝑥+𝑒是接近𝑞/2的情况(这种情况下𝑥=1),还是接近0的情况(这种情况下𝑥=0)。
同态加法
同态特性是我们学习LWE和Regev方案的最终目的。假设我们有两个密文(𝐴1, 𝑐1)和(𝐴2, 𝑐2),它们分别加密了消息𝑚1和𝑚2,所有这些都使用相同的密钥𝑠。然后我们知道,对于某些噪声𝑒1和𝑒2,以下内容是正确的:
𝑐1−𝐴1𝑠=⌊𝑞/2⌋⋅𝑚1+𝑒1
𝑐2−𝐴2𝑠=⌊𝑞/2⌋⋅𝑚2+𝑒2
如果解密(𝑐1, 𝐴1),你会得到𝑚1,同样对于(𝑐2, 𝐴2)也是如此。
那么,简单地将密文相加,通过分别添加𝐴和𝑐组件来构造一个新密文:(𝐴3 = 𝐴1 + 𝐴2, 𝑐3 = 𝑐1 + 𝑐2)。如果我们尝试解密:
𝑐3−𝐴3𝑠=(𝑐1+𝑐2)−(𝐴1+𝐴2)𝑠=𝑐1−𝐴1𝑠+𝑐2−𝐴2𝑠=⌊𝑞/2⌋⋅𝑚1+𝑒1+⌊𝑞/2⌋⋅𝑚2+𝑒2=⌊𝑞/2⌋⋅(𝑚1+𝑚2)+𝑒1+𝑒2
我们得到了消息的和𝑚1 + 𝑚2,并带有噪声𝑒1 + 𝑒2。这意味着如果我们将一个加密了1的密文和一个加密了0的密文相加,我们将得到一个加密了1的新密文。当我们将两个都编码为1的密文相加时,我们将得到一个编码为0的密文(消息是比特,位的相加就像XOR运算)。我们可以向服务器发送一堆加密的比特,它可以响应所有这些比特的XOR运算,而不会知道输入比特或输出比特。在我们进行同态加法时,噪声发生了变化。对于我们的示例参数,噪声分布是[−3, 3]。这意味着𝑒1和𝑒2都落在[−3, 3]范围内。但它们的和𝑒1 + 𝑒2呢?它们的和可以落在更宽的范围[−6, 6]。幸运的是,这个范围还不够大,不足以使我们的消息比特不可恢复——我们选择了𝑞 = 3329,只要噪声小于⌊𝑞/4⌋ = 832,我们应该可以正确解密。但是请注意,这是一个有限的预算;如果我们不断相加密文,噪声范围最终会超过𝑞/4。到那时,如果我们尝试解密,就有可能得到不正确的消息。如果我们添加超过278个密文(278⋅3 > 𝑞/4),解密失败的概率(虽然很小)将存在。同态加法时噪声“增长”的这个概念是基本的——同态加密的主要挑战之一是控制“噪声增长”,以便能够进行计算而不会使噪声增长过大,导致结果不正确。
同态加法是构建PIR所需的一个关键属性。
同态明文乘法
回顾一下我们想要从同态加密方案中得到的两个关键属性:
- 同态加法:如果密文𝑐1加密了𝑚1,密文𝑐2加密了𝑚2,那么𝑐' = 𝑐1 + 𝑐2加密了𝑚1 + 𝑚2。
- 同态明文乘法:如果密文𝑐1加密了𝑚1,而我们有另一个明文𝑚2,那么𝑐' = 𝑐1 * 𝑚2加密了𝑚1 * 𝑚2。
我们已经展示了如何实现同态加法。现在转向同态明文乘法。在本示例方案中,仅加密比特,到目前为止,我们的方案中的每个明文值只是一个比特。因此,同态明文乘法实际上仅涉及能够将密文乘以明文0或1。要将密文乘以明文0,只需将整个密文清零;要将密文乘以明文1,只需对密文不做任何处理。所以,我们已经拥有了同态明文乘法!现在,我们有了最终构建PIR所需的所有组件“同态密文加法”和“同态明文乘法”。
2. SimplePIR算法流程解析
有了上述介绍的背景知识,理解了基于LWE实现的同态特性组件,我们其实基本上能理解SimplePIR所要做的事情了。图7展示了 SimplePIR服务端计算,这里的(A, qu)其实就是公钥, hintc是预处理的计算,ans是服务端处理结果返回给客户端。
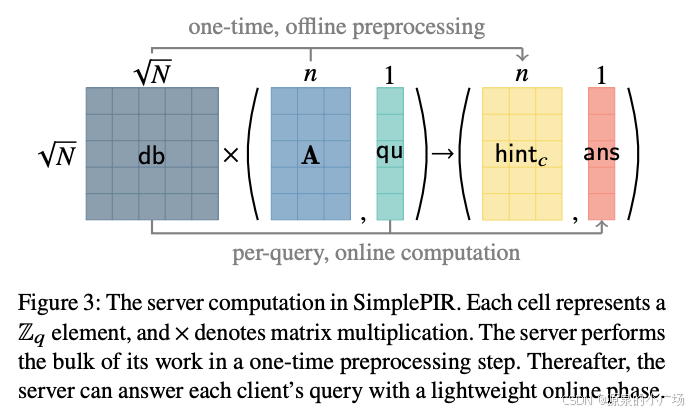
图7. SimplePIR服务端计算图
图8是基于前述LWE算法原理,来讲解SimplePIR的算法计算流程,对其中关键步骤都做了注释说明,并验证了最终查询结果的正确性。
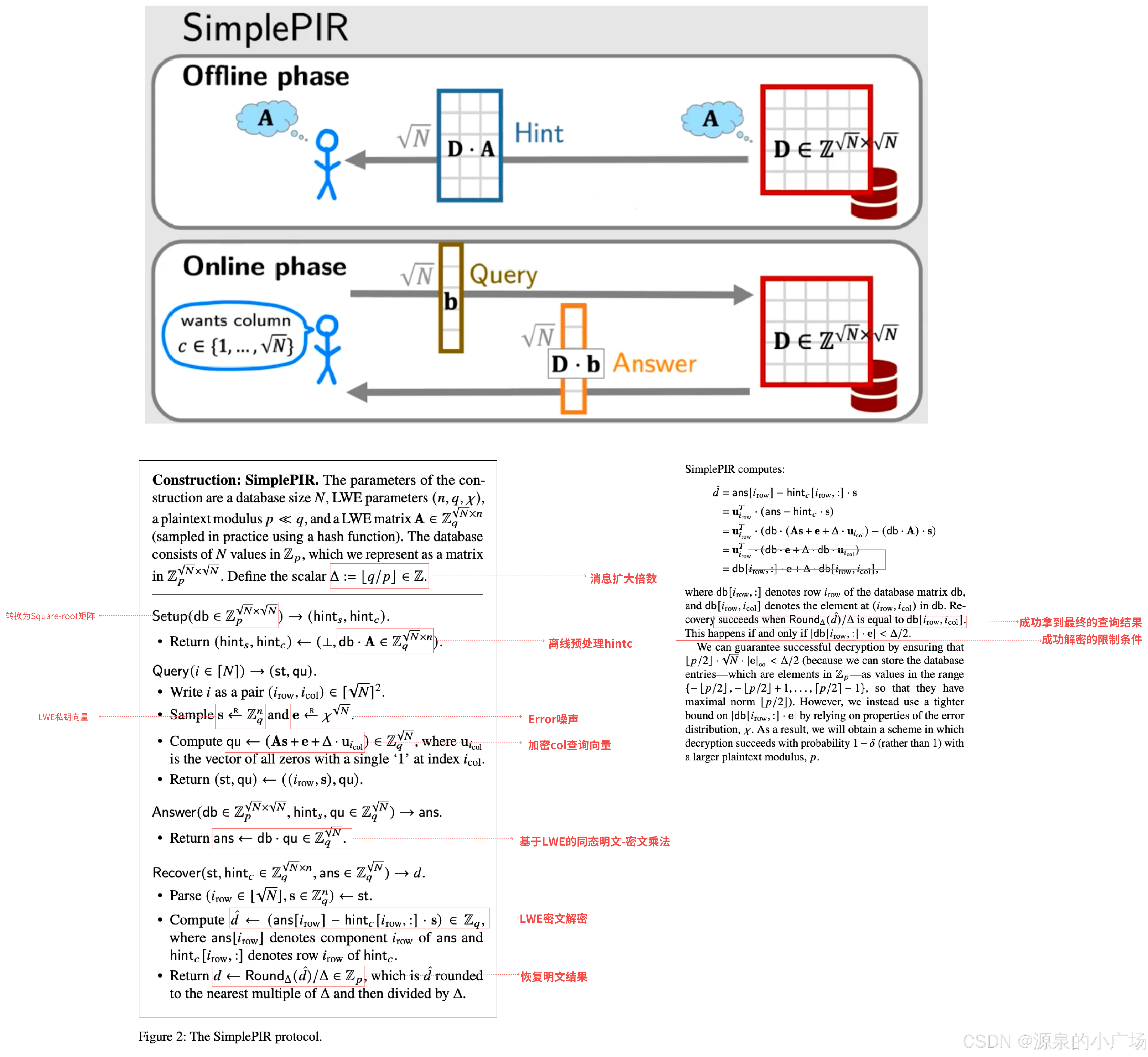
图8. SimplePIR算法流程图解及关键步骤注释
3. DoublePIR算法流程解析
论文中为什么还提出了DoublePIR算法呢?回顾一下SimplePIR的过程,可以发现,返回的ans比较大,与数据库大小相关,如图9所示。如果数据库规模很庞大,那么在通信侧很不友好。所以作者提出一种低通信消耗的方案,如图10所示,返回的对象就要小很多,达到降低通信量的目的。
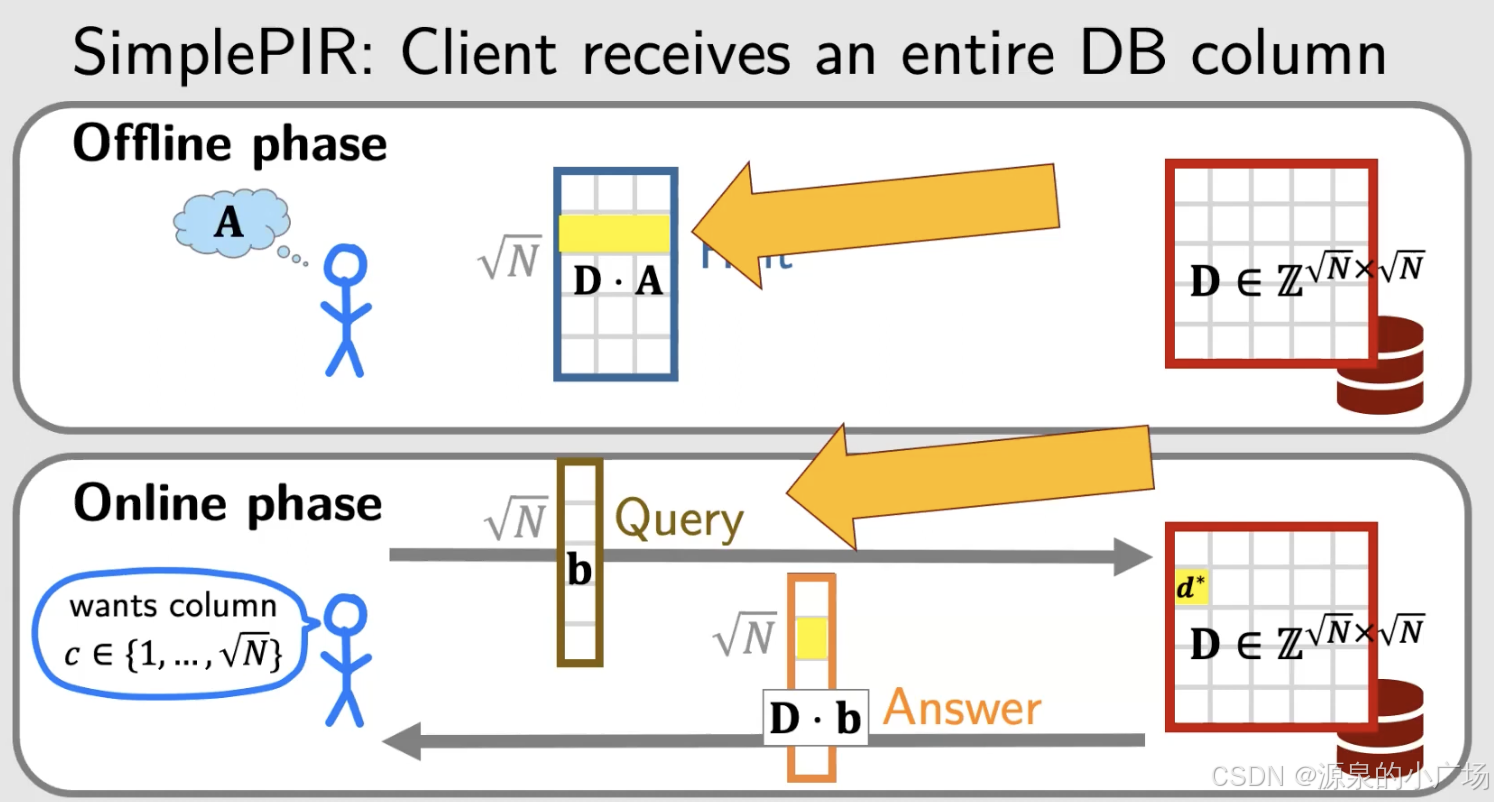
图9. SimplePIR返回整列结果
改进版本:
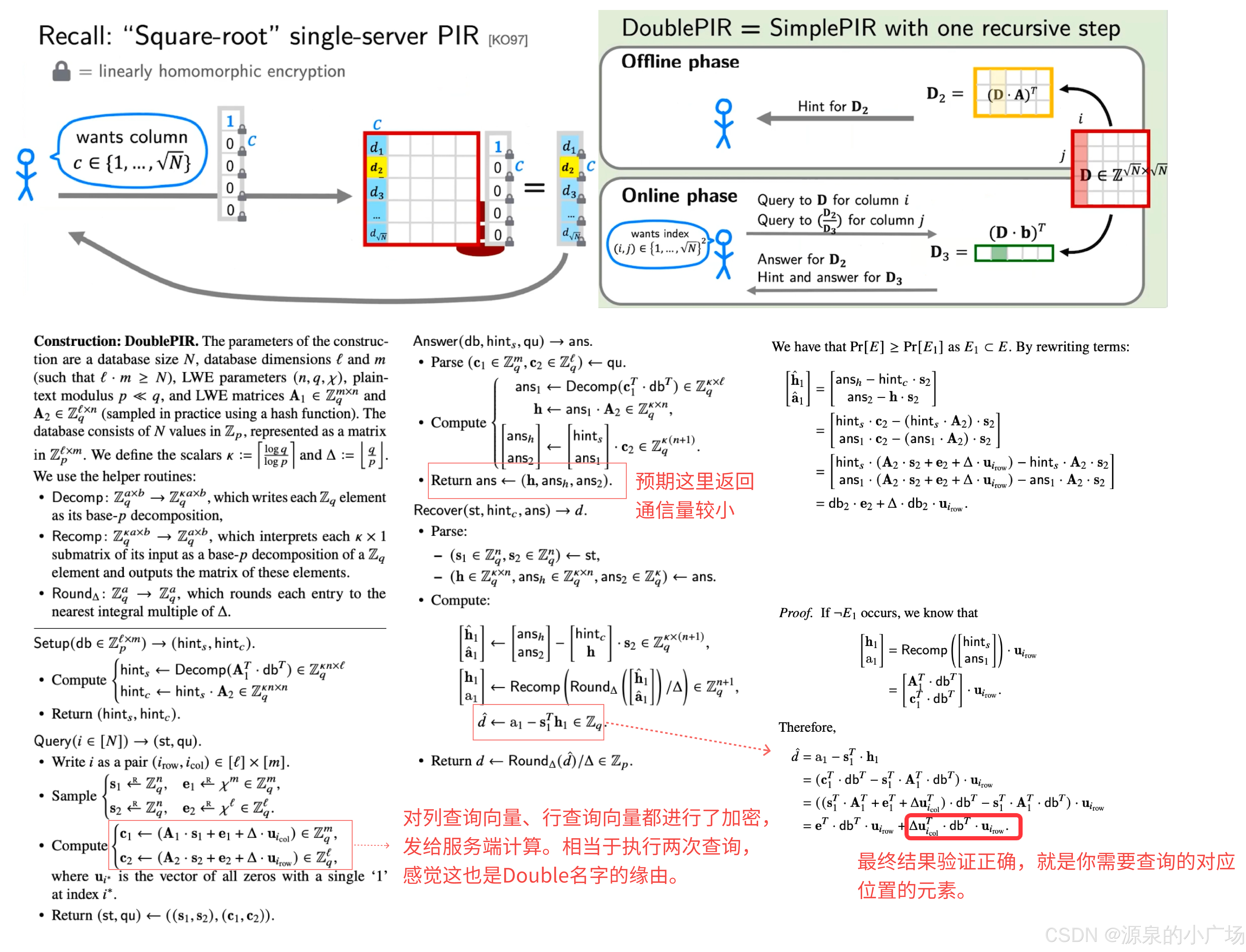
图10. DoublePIR计算流程注解
4. 参考文献
【1】Henzinger, Alexandra, et al. "One Server for the Price of Two: Simple and Fast {Single-Server} Private Information Retrieval." 32nd USENIX Security Symposium (USENIX Security 23). 2023.
【2】Henry Corrigan-Gibbs: Simple and Fast Private Information Retrieval
【3】Regev, Oded. "On lattices, learning with errors, random linear codes, and cryptography." Journal of the ACM (JACM) 56.6 (2009): 1-40.
【4】Kushilevitz, Eyal, and Rafail Ostrovsky. "Replication is not needed: Single database, computationally-private information retrieval." Proceedings 38th annual symposium on foundations of computer science. IEEE, 1997.
【6】Private information retrieval using homomorphic encryption
