
阅读量:0
目录
引言
数字人技术,作为人工智能领域的一项前沿技术,正逐渐成为现实世界与虚拟世界交互的重要桥梁。从早期的简单动画角色到现代高度逼真的虚拟助手,数字人技术经历了翻天覆地的变化。随着深度学习、计算机视觉和自然语言处理等技术的飞速发展,数字人不仅在外观上越来越接近真人,在交互能力上也日益智能化。
作为全球领先的科技公司之一,阿里巴巴一直致力于推动数字人技术的发展。通过整合集团内部的顶尖技术和资源,阿里巴巴在数字人领域取得了一系列创新成果。这些成果不仅提升了用户体验,也为整个行业的发展提供了新的方向和动力。
在这样的背景下,阿里巴巴蚂蚁集团推出了EchoMimic项目,一个开源的AI数字人项目,旨在赋予静态图像以生动的语音和表情。EchoMimic的问世,不仅标志着阿里巴巴在数字人领域的又一次技术突破,也为数字人技术的进一步普及和应用开辟了新的道路。
一、EchoMimic概述
EchoMimic是由阿里巴巴蚂蚁集团推出的一款开源AI数字人项目,它通过先进的深度学习技术,将静态图像转化为具有动态语音和表情的数字人像。这项技术的核心在于它能够根据音频输入,实时生成与语音同步的口型和面部表情,从而创造出逼真的动态肖像视频。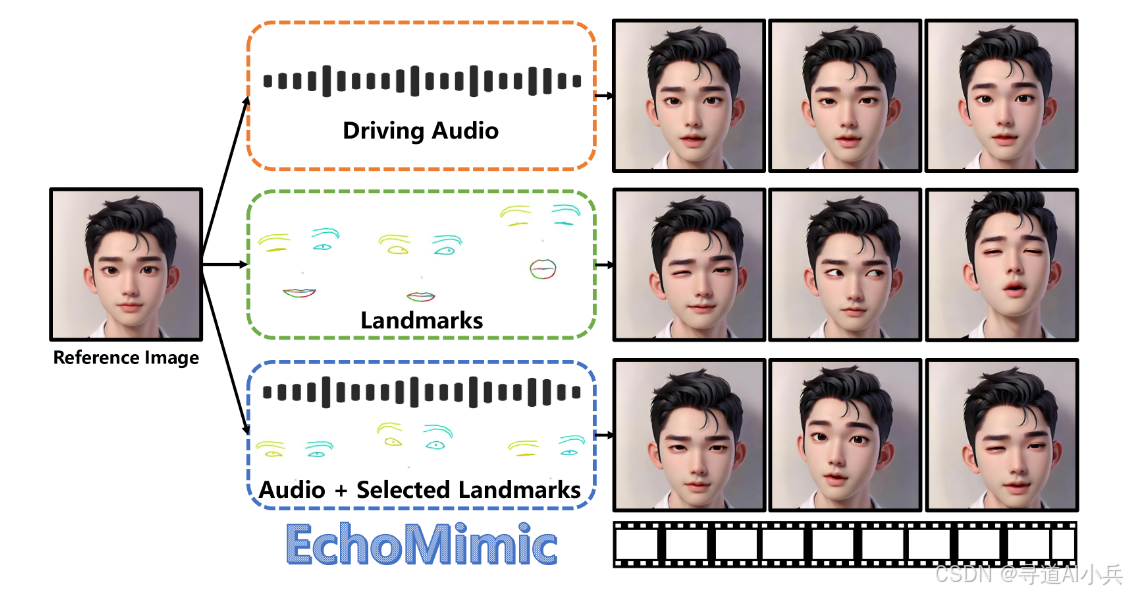
EchoMimic的诞生背景
随着数字媒体和虚拟现实技术的普及,市场对于高质量、高互动性的数字人像的需求日益增长。然而,传统的数字人像生成技术存在诸多限制,如对音频或面部关键点的过度依赖,导致生成的动画不够自然或稳定性不足。EchoMimic的诞生正是为了解决这些问题,通过创新的技术手段,提供一种更为自然、流畅的数字人像生成方案。
EchoMimic与传统数字人技术的区别
EchoMimic与传统数字人技术的主要区别在于其多模态学习策略和创新的训练方法。它不仅能够独立使用音频或面部标志点生成动画,还能将两者结合起来,通过音频和面部关键点的双重训练,生成更加逼真和自然的动态肖像。此外,EchoMimic还支持多语言,具有跨语言能力和风格多样性,使其能够适应不同的应用场景和用户需求。
二、EchoMimic的功能特性
1)音频同步动画
EchoMimic的音频同步动画功能是其最引人注目的特点之一。通过深度分析音频波形,系统能够精确捕捉语音的节奏、音调、强度等关键特征,并实时生成与语音同步的口型和面部表情。这项功能使得静态图像能够展现出与真实人类几乎无异的动态表现。2)面部特征融合
面部特征融合技术是EchoMimic的另一项核心优势。项目采用面部标志点技术,通过高精度的面部识别算法,捕捉眼睛、鼻子、嘴巴等关键部位的运动,并将这些特征融合到动画中,极大地增强了动画的真实感和表现力。3)多模态学习
EchoMimic的多模态学习能力体现在它能够同时处理音频和视觉数据。系统通过深度学习模型,将这两种类型的数据进行有效整合,提升了动画的自然度和表现力,使得生成的动画在视觉上和语义上都能与音频内容高度一致。4)跨语言能力
EchoMimic支持中文普通话和英语等多种语言,这使得不同语言区域的用户都能利用该技术制作动画。跨语言能力不仅拓宽了EchoMimic的应用范围,也为多语言环境下的数字人像生成提供了可能。5)风格多样性
EchoMimic能够适应不同的表演风格,无论是日常对话、歌唱还是其他形式的表演,都能通过相应的参数调整来实现。这种风格多样性为用户提供了广泛的应用场景,满足了不同用户的需求。
三、EchoMimic技术原理解析
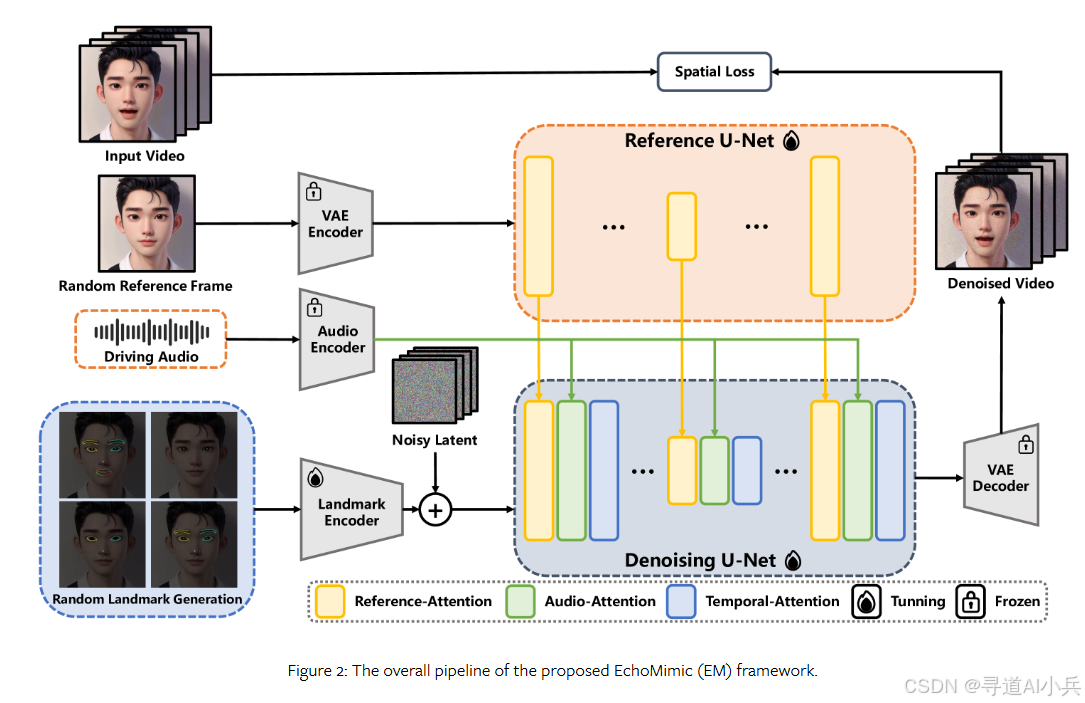
EchoMimic的技术原理包括以下几个方面:
- 音频特征提取:EchoMimic首先对输入的音频进行深入分析,利用先进的音频处理技术提取出语音的节奏、音调、强度等关键特征。
- 面部标志点定位:通过高精度的面部识别算法,EchoMimic能够精确地定位面部的关键区域,包括嘴唇、眼睛、眉毛等,为后续的动画生成提供基础。
- 面部动画生成:结合音频特征和面部标志点的位置信息,EchoMimic运用复杂的深度学习模型来预测和生成与语音同步的面部表情和口型变化。
- 多模态学习:项目采用多模态学习策略,将音频和视觉信息进行深度融合,生成的动画不仅在视觉上逼真,而且在语义上与音频内容高度一致。
- 深度学习模型应用:
- 卷积神经网络(CNN):用于从面部图像中提取特征。
- 循环神经网络(RNN):处理音频信号的时间动态特性。
- 生成对抗网络(GAN):生成高质量的面部动画,确保视觉效果的逼真性。
- 创新训练方法:EchoMimic采用了创新的训练策略,允许模型独立地或结合地使用音频和面部标志点数据,以提高动画的自然度和表现力。
- 预训练和实时处理:项目使用了在大量数据上预训练的模型,EchoMimic能够快速适应新的音频输入,并实时生成面部动画。
四、EchoMimic的应用场景
1)娱乐领域
在娱乐领域,EchoMimic的应用前景广阔。无论是电影、电视剧的后期制作,还是游戏角色的动画设计,EchoMimic都能够提供逼真的面部动画,增强观众的沉浸感。此外,它还可以用于虚拟偶像的创建,让虚拟偶像在直播、演唱会等场合中更加生动。2)教育领域
教育是EchoMimic另一个重要的应用领域。利用EchoMimic技术,可以创建虚拟教师或助教,提供更加个性化和互动性强的学习体验。这些虚拟教育角色可以根据学生的学习进度和反应,实时调整教学内容和方式。3)虚拟现实
虚拟现实(VR)技术与EchoMimic的结合,可以为用户提供更加真实和自然的交互体验。在VR环境中,用户可以与具有高度逼真表情和口型的虚拟角色进行交流,无论是在模拟训练还是虚拟社交场景中,都能够提升用户的参与度。4)其他潜在应用
除了上述领域外,EchoMimic还有许多其他潜在的应用场景。例如,在医疗领域,它可以用于创建虚拟医生或心理咨询师,提供远程诊断和心理支持;在客户服务领域,它可以作为虚拟客服,提供24小时的咨询服务;在广告行业,它可以用来生成更加吸引人的广告角色,提高广告的传播效果。
五、本地部署与安装指南
1、系统要求
在开始本地部署EchoMimic之前,用户需要确保其系统满足以下基本要求:
- 操作系统:支持Linux和Windows系统。
- 处理器:建议使用高性能的CPU,以保证处理速度。
- 内存:至少8GB RAM,推荐16GB或更高,以便于处理复杂的模型和数据集。
- 图形处理单元(GPU):推荐使用NVIDIA系列显卡,至少具备6GB显存,以实现深度学习模型的高效训练和推理。
2、环境配置
部署EchoMimic需要安装以下环境和依赖库:
- Python:推荐使用Python 3.6及以上版本。
- 深度学习框架:如PyTorch或TensorFlow,根据EchoMimic的实现选择合适的框架。
- 音频处理库:如Librosa,用于音频特征的提取和处理。
- 其他依赖:根据项目的具体依赖列表安装所需的库。
3、安装步骤
1)克隆仓库:首先,通过Git克隆EchoMimic的GitHub仓库到本地机器。
git clone https://github.com/BadToBest/EchoMimic.git 2)安装依赖:进入项目目录,安装所需的Python依赖。
conda create -n echomimic python=3.8 conda activate echomimic cd EchoMimic pip install -r requirements.txt 3)下载 ffmpeg-static
下载并解压 ffmpeg-static,然后
export FFMPEG_PATH=/path/to/ffmpeg-4.4-amd64-static 4)下载预训练模型
根据需要下载并解压预训练模型权重文件,以便快速开始使用EchoMimic。
git lfs install git clone https://huggingface.co/BadToBest/EchoMimic pretrained_weights 5)音频驱动的算法推理
运行 python 推理脚本:
python -u infer_audio2vid.py python -u infer_audio2vid_pose.py 6)音频驱动的算法推理 On Your Own Case
编辑推理配置文件 ./configs/prompts/animation.yaml,并添加您自己的案例:
test_cases:
“path/to/your/image”:
- “path/to/your/audio”
运行 python 推理脚本:
python -u infer_audio2vid.py 7)Ref. Img. 之间的运动对齐。和驱动视频。
(首先从huggingface下载带有“_pose.pth”后缀的检查点)
在 demo_motion_sync.py 中编辑driver_video并ref_image到您的路径,然后运行
python -u demo_motion_sync.py 8)音频和姿势驱动的算法推理
编辑 ./configs/prompts/animation_pose.yaml,然后运行
python -u infer_audio2vid_pose.py 9)姿势驱动的算法推理
在infer_audio2vid_pose.py的第 135 行中设置 draw_mouse=True。编辑 ./configs/prompts/animation_pose.yaml,然后运行
python -u infer_audio2vid_pose.py 10)运行 Gradio UI
python -u webgui.py --server_port=3000 结语
EchoMimic的推出不仅在技术上实现了突破,更在行业应用上展示了广阔的前景。其在娱乐、教育、虚拟现实等多个领域的应用,预示着数字人技术将在未来扮演更加重要的角色。EchoMimic的成功也为其他科技公司提供了宝贵的经验和启示,推动了整个行业的发展。
随着技术的不断进步,未来的数字人技术将更加智能化、个性化。EchoMimic所展示的多模态学习和跨语言能力,将是未来数字人技术发展的重要方向。我们有理由相信,数字人将越来越成为人们日常生活的一部分,提供更加丰富和便捷的服务。
参考引用
为了确保文章的准确性和权威性,以下是本文引用的相关资源链接:
- EchoMimic项目官网: https://badtobest.github.io/echomimic.html
- EchoMimic GitHub仓库: https://github.com/BadToBest/EchoMimic
- Hugging Face模型库: https://huggingface.co/BadToBest/EchoMimic
- arXiv技术论文: https://arxiv.org/html/2407.08136

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,加入技术交流群,开启编程探索之旅。
💘精心准备📚500本编程经典书籍、💎AI专业教程,以及高效AI工具。等你加入,与我们一同成长,共铸辉煌未来。
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
