
阅读量:0
进程创建 fork
1.fork 之后发生了什么
- 将给子进程分配新的内存块和内核数据结构(形成了新的页表映射)
- 将父进程部分数据结构内容拷贝至子进程
- 添加子进程到系统进程列表当中
- fork 返回,开始调度器调度
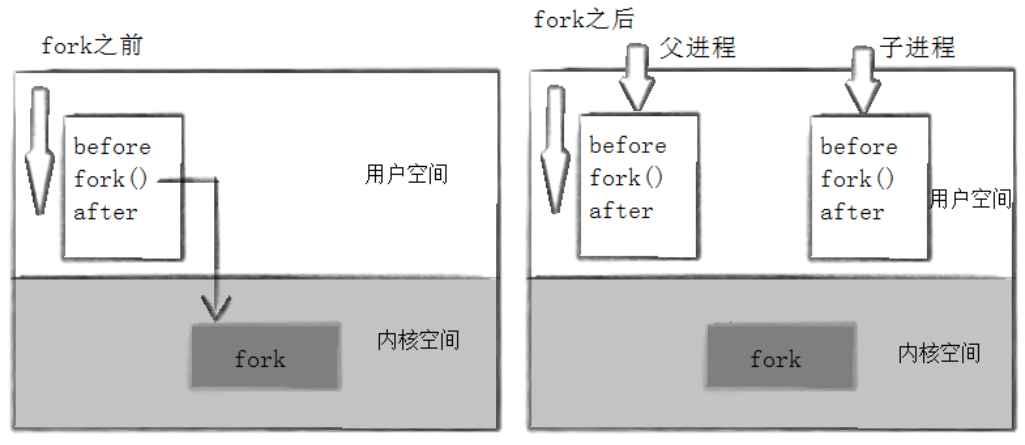
这样就可以回答之前返回两个值?
发生了写实拷贝,形成了两个物理空间块
测试
#include <stdio.h> #include <unistd.h> #include <stdlib.h> int main(void) { printf("Before -> pid: %d\n", getpid()); fork(); printf("After -> pid: %d\n", getpid()); sleep(1); return 0; }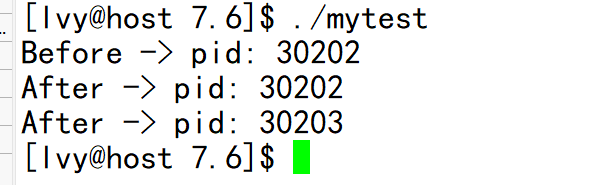
创建了一个子进程
一般来说子进程创建之后,会共享父进程的所有代码
是怎么知道的呢?没关系,eip 程序计数器会出手!
eip 叫做 程序计数器,用来保存当前正在执行的指令的下一条指令。eip 程序计数器会拷贝给子进程,子进程便从该 eip 所指向的代码处开始执行。
我们再来重新思考一下 fork 之后操作系统会做什么:
" 进程 = 进程的数据结构 + 进程的代码和数据 "
创建子进程的内核数据结构:
(struct task_struct + struct mm_struct + 页表)+ 代码继承父进程,数据以写时拷贝的方式来进行共享或者独立。
代码共享,写实拷贝确保了进程的独立性
写实拷贝
当任意一方试图写入,就会按照写时拷贝的方式各自拷贝一份副本出来。写时拷贝本身由操作系统的内存管理模块完成的。
选择暂时先不给你,等你什么时候要用什么时候再给。这就变相的提高了内存的使用情况。
fork
fork 之后利用 if-else 进行分流, 让父子执行不同的代码块。我们做网络写服务器的时候会经常采用这样的编码方式,例如父进程等待客户端请求,生成子进程来处理请求。
继承大纲后又有所区别
fork 肯定不是永远都成功的,fork 也是有可能调用失败的。
测试
#include <stdio.h> #include <unistd.h> #include <stdlib.h> int main(void) { for (;;) {//写了一个死循环 pid_t id = fork(); if (id < 0) { printf("子进程创建失败!\n"); break; } if (id == 0) { printf("I am a child... %d\n", getpid()); sleep(2); // 给它活2秒后 exit exit(0); // 成功就退出 } } return 0; }
进程终止 exit
为什么要使用return?
思考:代码运行完的结果一般有以下三种:
代码运行完毕,结果正确
代码运行完毕,结果不正确
代码异常中止
成功了就是成功了,失败了就会有各种原因
我们重点来对不正确进行思考
- 进程中,谁会关心我运行的情况呢? 父进程
怎么表示不同的出错原因呢?
A: 进程的退出码
- return 0 表示正确
- main函数的返回值本质:表示进程运行完成时,是否是正确的结果,如果不是,我们可以用不同的数字表示出错的原因
模拟一个逻辑的实现
$? : 保存的是最近的一次进程退出的时候的退出码

我们想要进步,不再是随便无脑 return 了,我该怎么办呢?
一般而言,失败的非零值我该如何设置呢?非零值默认表达的含义又是什么呢?
首先,失败的非零值是可以自定义的,我们可以看看系统对于不同数字默认的 错误码 是什么含义。C 语言当中有个的 string.h 中有一个 strerror 接口
如果感兴趣可以看看 2.6.32 的内核代码中的 /usr/include/asm-generic/errno.h 及 errno-base.h,输出错误原因定义归纳整理如下:
#define EPERM 1 /* Operation not permitted */ #define ENOENT 2 /* No such file or directory */ #define ESRCH 3 /* No such process */ #define EINTR 4 /* Interrupted system call */ #define EIO 5 /* I/O error */ #define ENXIO 6 /* No such device or address */ #define E2BIG 7 /* Argument list too long */ #define ENOEXEC 8 /* Exec format error */ #define EBADF 9 /* Bad file number */查看错误码 strerror(i)
我们可以在 Linux 下写个程式去把这些错误码给打印出来:
结果如下:
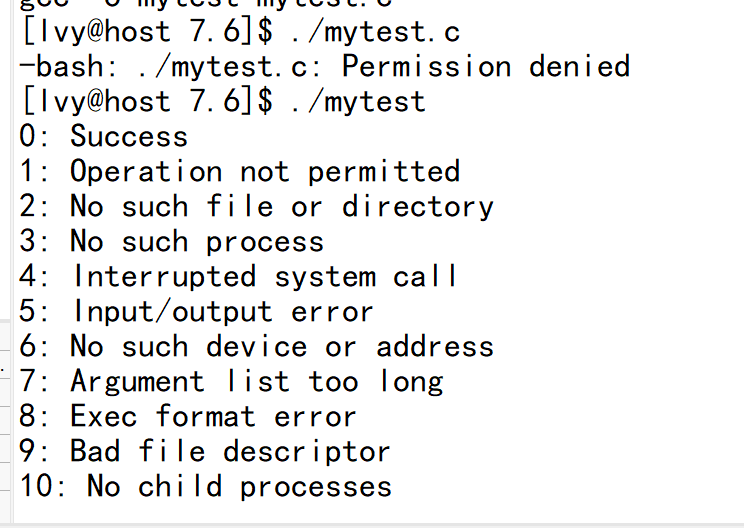
系统提供的错误码和
添加图片
const char *errString[]={ "success", "error 1", "error 2", "error 3" };实践:
对于 ls myfile.txt 的查看
- $?: 2
其中,0 表示 success,1 表示权限不允许,2 找不到文件或目录。
我们刚才 ls 一个不存在的,再 echo $? 显示对应的错误码就是 2:
所以无论正确还是不正确,统一会采用进程的退出码来进行判定
不同的错误码,方便我们定位问题出在哪里
我们可以通过以下方法来查看
C 语言中 errno - number of last error
打印错误 strerror(errno)
?:如果代码异常了,退出码还有意义吗?
本质可能就是代码没有跑完,都跑不到那个地方了
进程的退出码无意义了,因为可能都到不了 return
? : 那么如何知道发生了什么异常呢? 发信号
eg. 野指针
举例 8 11 表示异常
kill -8 出现野指针 -11 段错误
终止进程的做法:
#include<stdlib.h>
exit 的退出码 12
exit 在任意地方被调用,都表示调用进程直接退出
return 只表示当前函数的返回
测试
#include <stdio.h> #include <stdlib.h> void func() { printf("hello func\n"); exit(111); } int main(void) { func(); return 10; }
注意,只有在 main 函数调 return 才叫做 进程退出,其他函数调 return 叫做 函数返回。
_exit 和 exit
exit 会清理缓冲区,关闭流等操作,而 _exit 什么都不干,直接终止。
void func() { printf("hello exit"); exit(0); } int main(void) { func(); printf("hello _exit"); _exit(0); }
是否冲刷缓冲区的区别
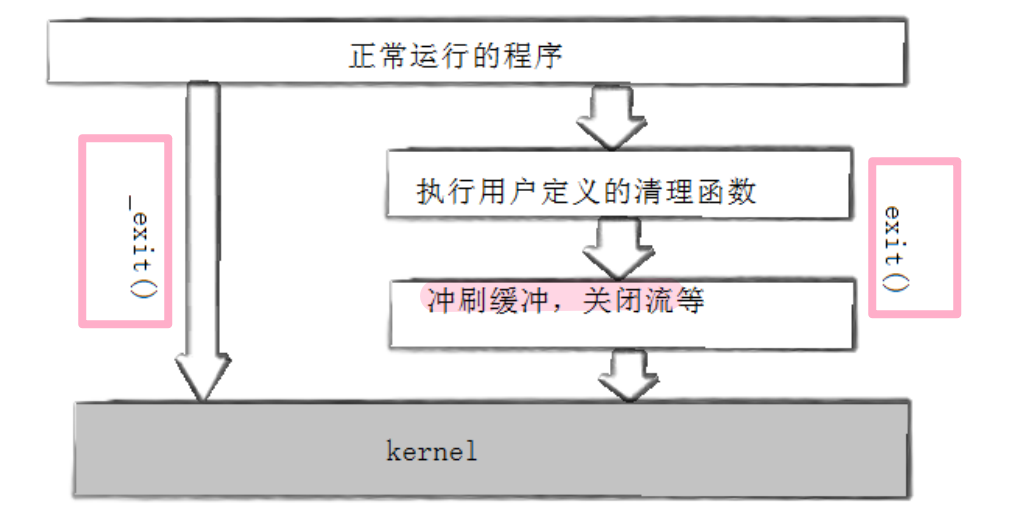
缓冲区(Buffer)的概念在计算机科学中非常广泛,但在你提供的上下文中,缓冲区指的是一种用于临时存储数据的内存区域。在介绍内核的数据结构缓冲池时,缓冲区的概念主要与提升性能和合理利用内存资源有关。
具体来说,你提供的描述强调了以下几点:
- 开辟空间和初始化有成本:
- 在操作系统中,每次为新进程或新数据结构开辟内存空间并初始化都需要花费时间和资源,这会影响系统性能。
- 废弃的数据结构链表:
- 为了优化这种开销,Linux 操作系统会维护一张废弃的数据结构链表。这个链表上存放的是那些已经被标记为“无效”的数据结构,但其内存空间并没有被立即释放。这些数据结构包括
task_struct和mm_struct等。
- 为了优化这种开销,Linux 操作系统会维护一张废弃的数据结构链表。这个链表上存放的是那些已经被标记为“无效”的数据结构,但其内存空间并没有被立即释放。这些数据结构包括
- 重用策略:
- 当一个进程被释放(即终止)后,它的相关数据结构不会立即被完全删除,而是被标记为无效并加入废弃的数据结构链表中。
- 当有新的进程创建时,操作系统会首先检查这个链表,从中取出一个合适的、已经存在的但无效的数据结构(如
task_struct和mm_struct),进行必要的初始化然后再使用。
- 内核的数据结构缓冲池:
- 这种方法本质上是一种内存池,也即“缓冲池”,专门用来存放和重用数据结构的内存。
- Slab 分配器(Slab Allocator)即是实现这种内存池概念的机制之一。通过使用 slab 分配器,系统能有效减少重复的内存分配和释放操作,提高运行效率,并减少内存碎片化的问题。
它的原理是将内存按照大小分成不同的块,然后将这些块以页的形式进行分配和管理。当需要分配内存时,slab 分配器会从对应大小的块中选择一个可用的块分配给程序,当内存不需要时,这块内存又会被返回到对应的块中以便后续重复使用,从而降低了内存的分配和释放开销。这种方式可以提高内存分配的性能,减少内存碎片化
sum:
缓冲区在这个背景下的概念是指一块预分配的内存,用来存储和重复利用特定类型的数据结构。这种做法可以显著减少频繁的内存分配和释放所带来的开销,提高系统性能,这也是 slab 分配器背后的核心思想。
slab 分配器:根据合适的内存拿,不要就放回去
我们 printf 一定是把数据写入缓冲区中,合适的时候,在进行刷新
这个缓冲区绝对不在哪里?
绝对不在内核里,在用户空间,要不然一定会被刷新
