
阅读量:0
目录
Flink HA集群规划
FLink HA集群规划如下:
| IP地址 | 主机名称 | Flink角色 | ZooKeeper角色 |
| 192.168.128.111 | bigdata111 | master | QuorumPeerMain |
| 192.168.128.112 | bigdata112 | worker、master | QuorumPeerMain |
| 192.168.128.113 | bigdata113 | worker | QuorumPeerMain |
bigdata111和bigdata112作为master节点,也就是实现JobManager的高可用。bigdata112和bigdata113作为worker节点,作为TaskManager节点。Flink HA集群使用ZooKeeper和HDFS实现。所以需要ZooKeeper集群和HDFS集群。假设已经部署好了ZooKeeper集群和HDFS集群。
环境变量配置
执行如下命令,打开配置文件
vi /etc/profile在文件末尾添加如下配置内容:
export HADOOP_CLASSPATH=`hadoop classpath`执行如下命令,生效配置文件:
source /etc/profile三台服务器同时配置。
masters配置
进去Flink安装目录下的conf目录,如图:
masters配置文件内容改为:
bigdata111:8081 bigdata112:8081将该配置同步到其他服务器,保持三台服务器相同配置。
scp -r masters bigdata112:`pwd` scp -r masters bigdata113:`pwd`复制成功后,如图:

flink-conf.yaml配置
进入Flink安装目录下的conf目录,如图:
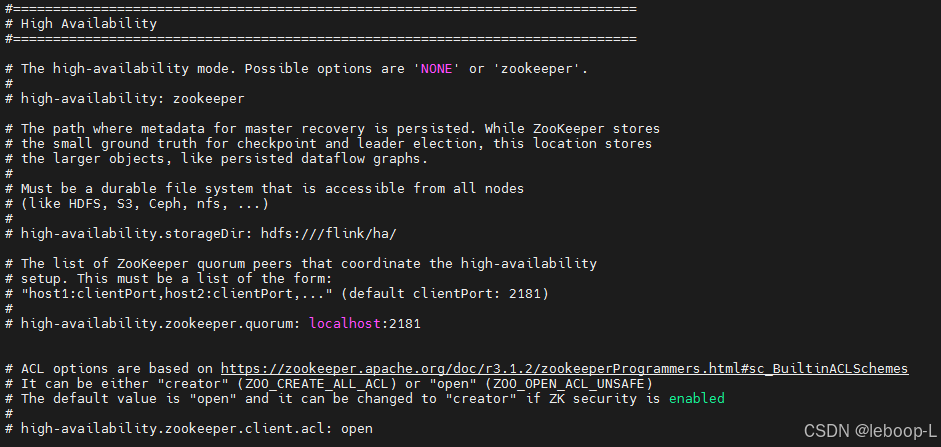
打开配置文件,Flink HA的默认配置如下:
将HA配置修改为如下内容:
# The high-availability mode. Possible options are 'NONE' or 'zookeeper'. # high-availability: zookeeper # The path where metadata for master recovery is persisted. While ZooKeeper stores # the small ground truth for checkpoint and leader election, this location stores # the larger objects, like persisted dataflow graphs. # # Must be a durable file system that is accessible from all nodes # (like HDFS, S3, Ceph, nfs, ...) # high-availability.storageDir: hdfs:///flink/ha/ # The list of ZooKeeper quorum peers that coordinate the high-availability # setup. This must be a list of the form: # "host1:clientPort,host2:clientPort,..." (default clientPort: 2181) # high-availability.zookeeper.quorum: bigdata111:2181,bigdata112:2181,bigdata113:2181 # ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes # It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE) # The default value is "open" and it can be changed to "creator" if ZK security is enabled # # high-availability.zookeeper.client.acl: open将该配置文件同步到其他服务器,命令如下:
scp -r flink-conf.yaml bigdata112:`pwd` scp -r flink-conf.yaml bigdata113:`pwd`同步成功后,如图:

测试
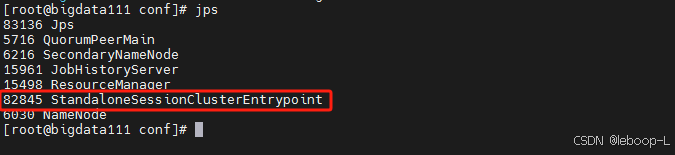
先后启动ZooKeeper集群、HDFS集群和flink集群,如图:

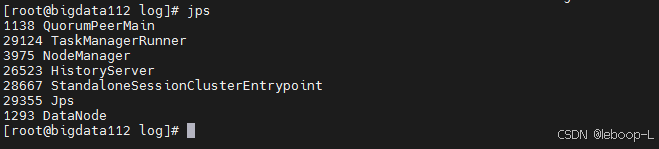
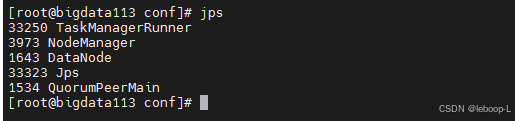
使用浏览器分别登录Flink web ui页面:
如图:

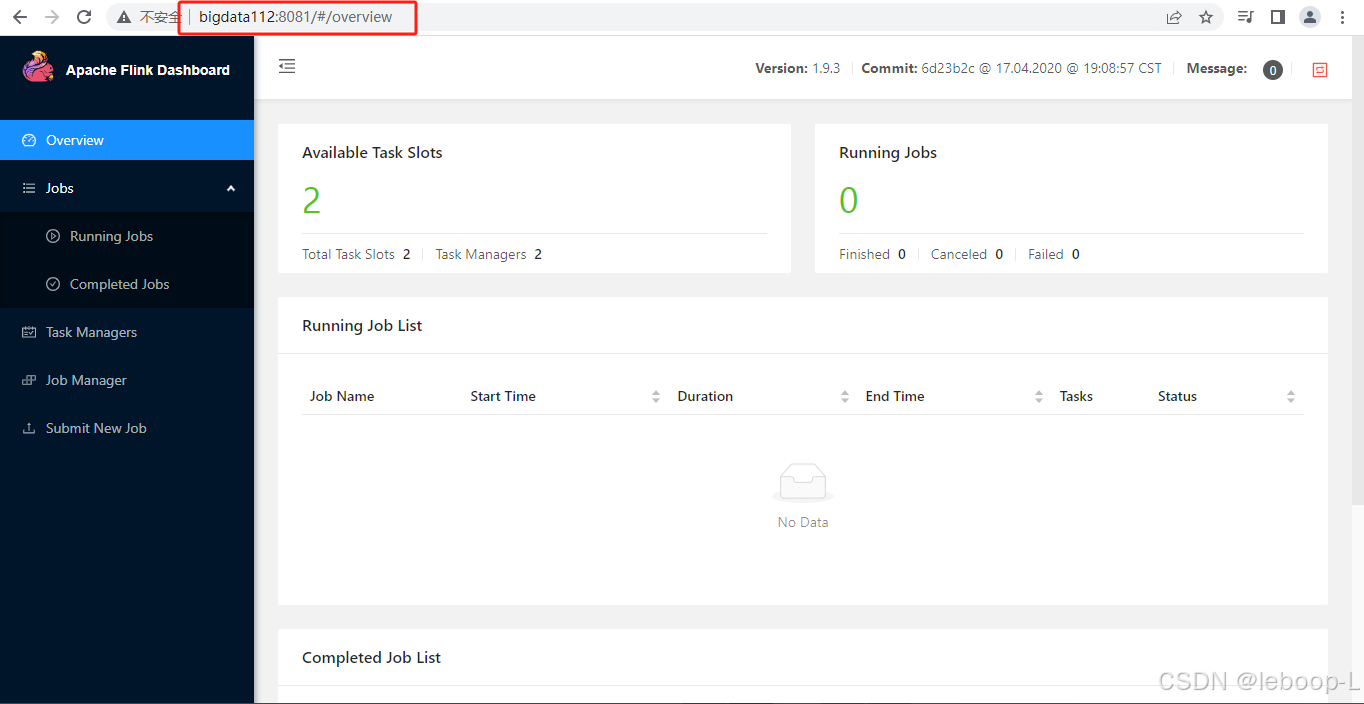
页面上无法区分哪个节点是active。HDFS上同时生成了HA的数据目录,如图:
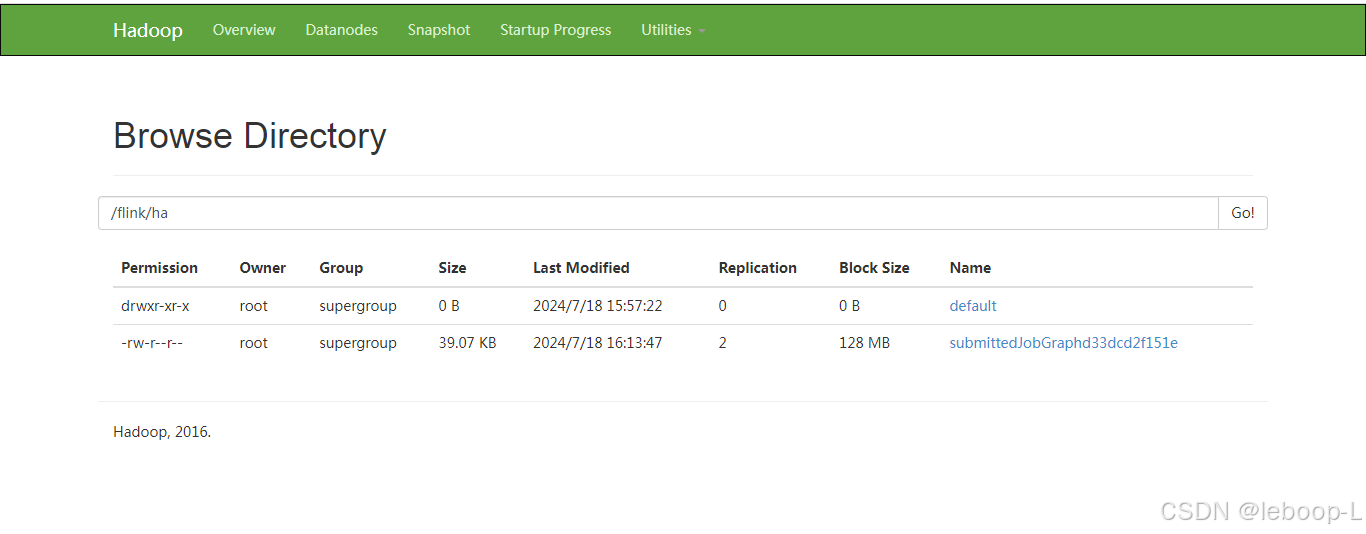
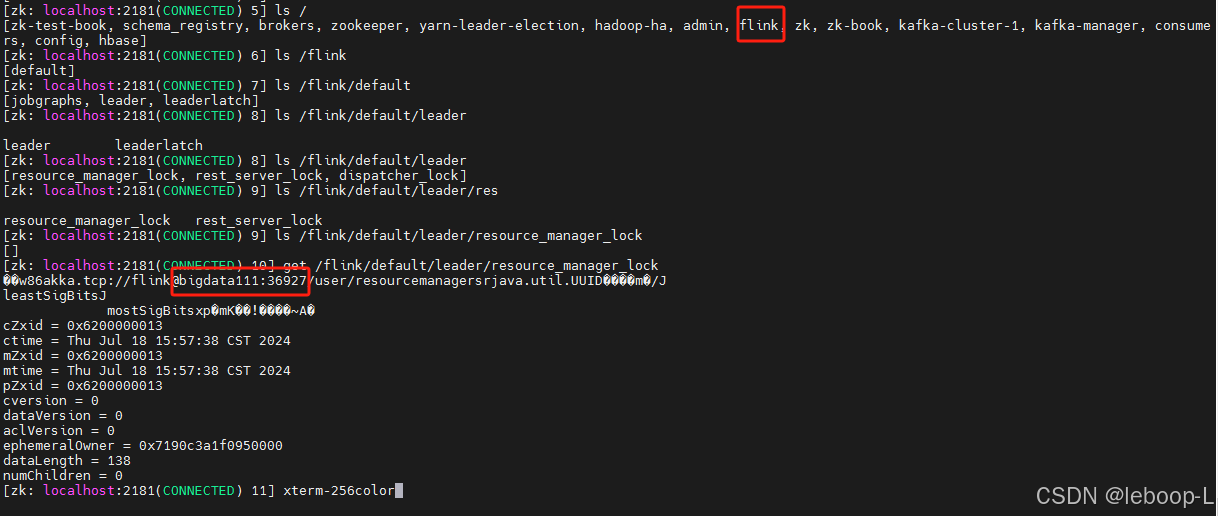
下面从ZooKeeper中查看哪一个节点是active:
执行zkCli.sh命令连接ZooKeeper集群,最终查找到当前Flink中active JobManager是bigdata111。如图:
现在在bigdata111上运行flink应用程序,命令如下:
flink run -c com.leboop.SocketStreamingWordCount /root/jars/flink-1.0-SNAPSHOT.jar --host bigdata111 --port 9999运行成功后如图:

此时在bigdata111和bigdata112上的web ui上均可以看到相同的正在运行的任务,如图:
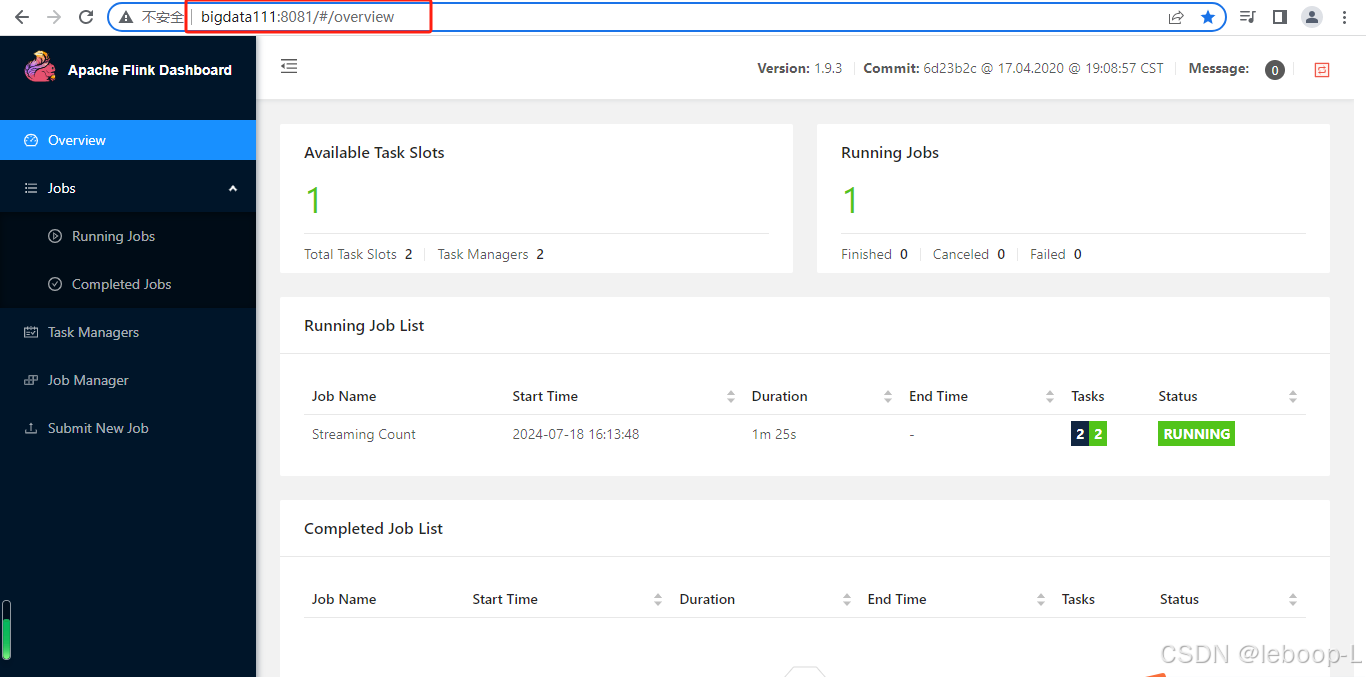
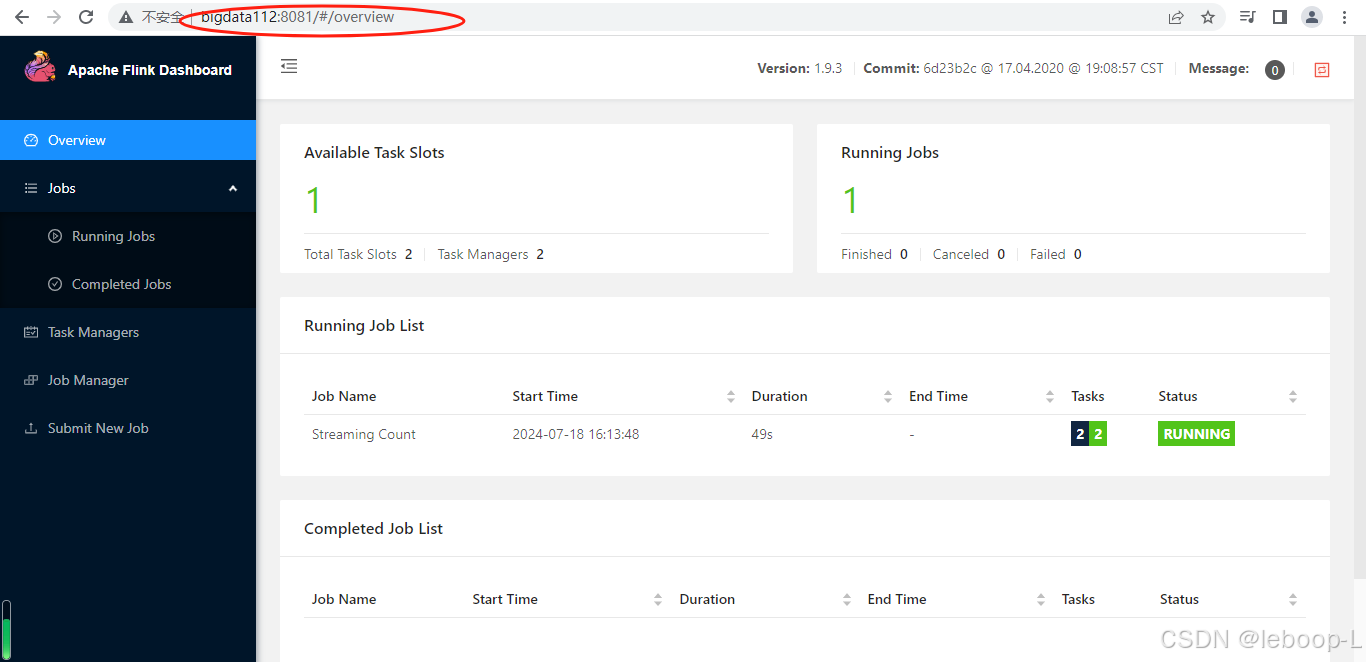
现在将bigdata111上的JobManager杀死,如图:
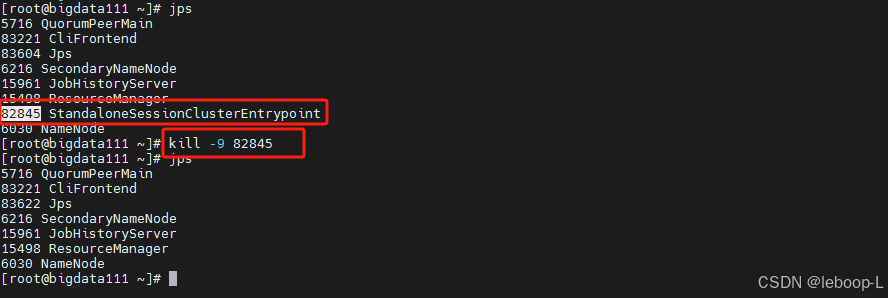
此时bigdata111无法打开web ui页面,如图:
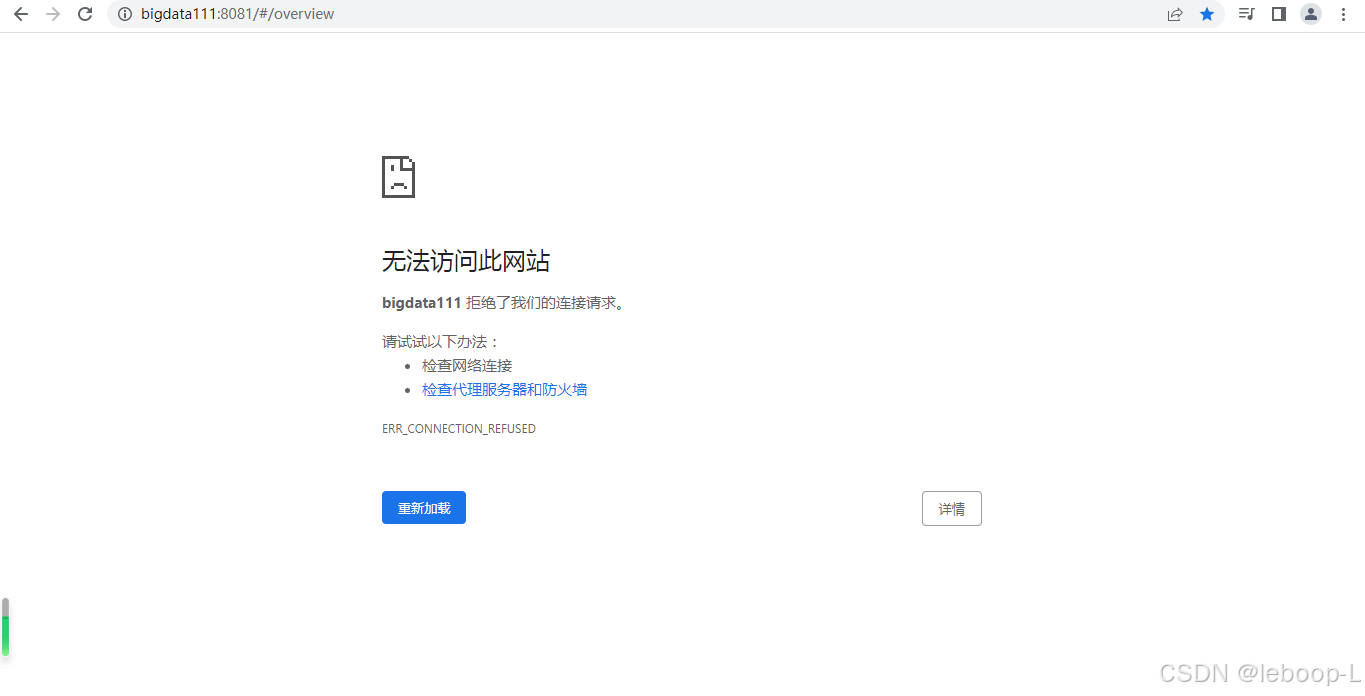
可以打开bigdata112的web ui页面,如图:
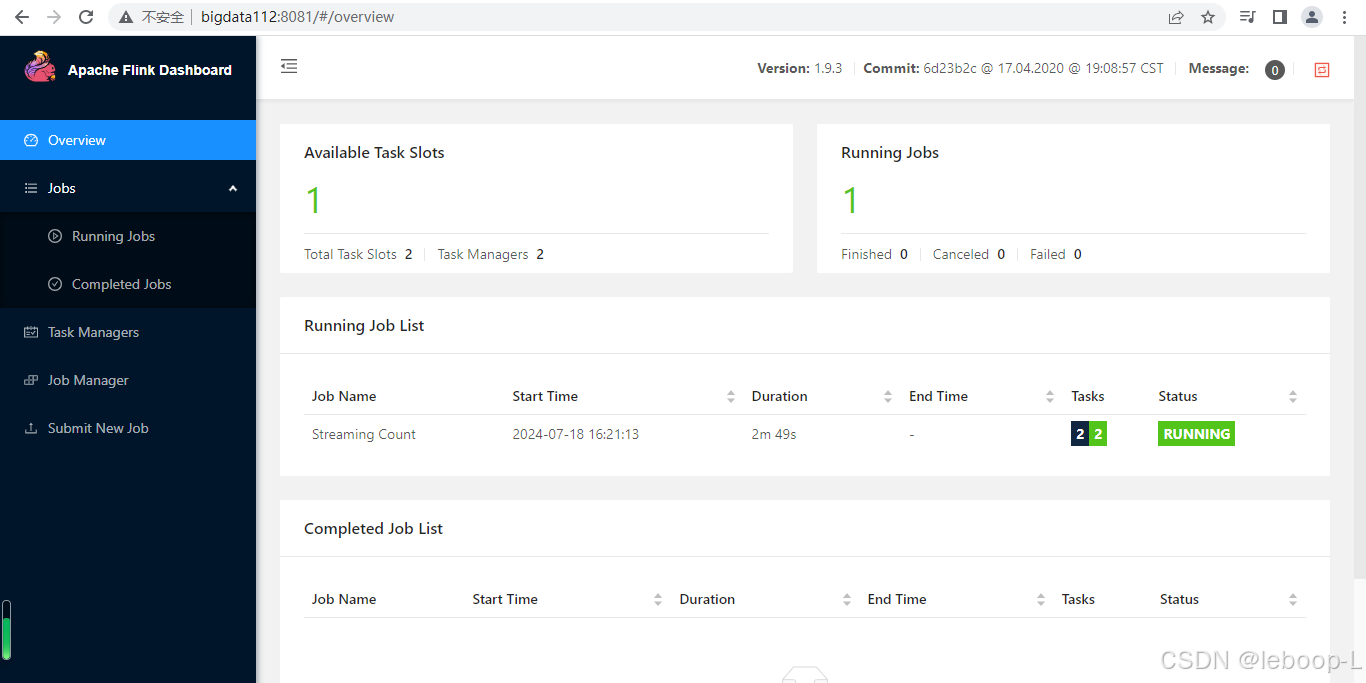
再次执行zkCli.sh命令,连接到ZooKeeper集群,查看节点信息如下: 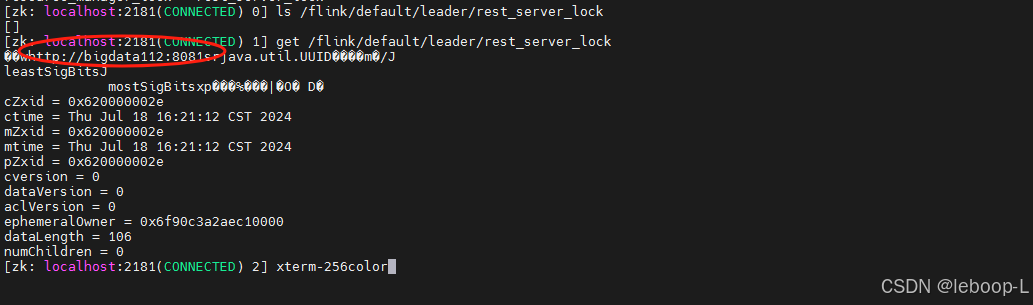
active JobManager节点已经切换到bigdata112。
