阅读量:0
图像分类是计算机视觉中的一项重要任务。在此任务中,我们假设每张图像只包含一个主对象。在这里,我们的目标是对主要对象进行分类。图像分类有两种类型:二元分类和多类分类。在本章中,我们将开发一个深度学习模型,使用 PyTorch 对图像进行二元分类。
图像二分类的目标是将图像分为两类。例如可能想知道医学图像是正常的还是恶性的。图像可以是具有一个通道的灰度图像,也可以是具有三个通道的彩色图像。
目录
准备数据集
在 Kaggle 网站上注册一个账户,访问链接下载数据集:
Histopathologic Cancer Detection | Kaggle![]() https://www.kaggle.com/c/histopathologic-cancer-detection/data下载后,将ZIP文件解压缩到名为data的文件夹中,将数据文件夹放在与代码相同的位置。数据文件夹中,有两个文件夹:train 和 test。train 文件夹包含 220,025 个大小为 96x96 的.tif图像。.tif图像以图像 ID 命名。
https://www.kaggle.com/c/histopathologic-cancer-detection/data下载后,将ZIP文件解压缩到名为data的文件夹中,将数据文件夹放在与代码相同的位置。数据文件夹中,有两个文件夹:train 和 test。train 文件夹包含 220,025 个大小为 96x96 的.tif图像。.tif图像以图像 ID 命名。
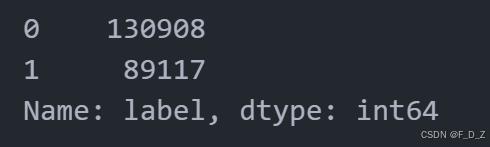
import pandas as pd # 定义csv文件路径 path2csv="./data/train_labels.csv" # 读取csv文件,并存储到DataFrame中 labels_df=pd.read_csv(path2csv) # 显示DataFrame的前几行 labels_df.head() # 打印labels_df数据框中label列的值计数 print(labels_df['label'].value_counts()) 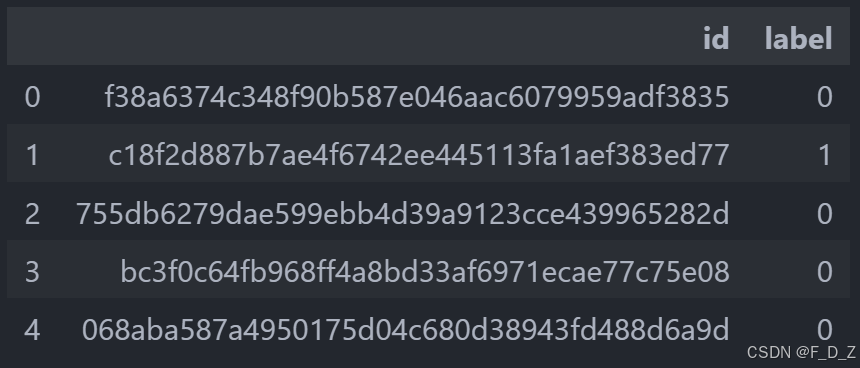
# 导入matplotlib库 %matplotlib inline # 绘制labels_df数据框中label列的直方图 labels_df['label'].hist();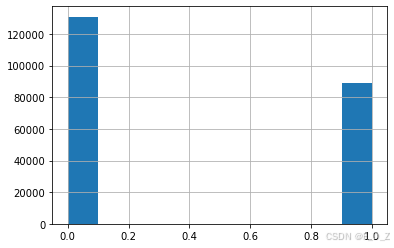
import matplotlib.pylab as plt from PIL import Image, ImageDraw import numpy as np import os %matplotlib inline # 设置训练数据路径 path2train="./data/train/" # 设置颜色模式,False为灰度,True为彩色 color=True # 获取标签为1的id malignantIds = labels_df.loc[labels_df['label']==1]['id'].values # 设置图像大小 plt.rcParams['figure.figsize'] = (10.0, 10.0) # 设置子图间距 plt.subplots_adjust(wspace=0, hspace=0) # 设置子图行数和列数 nrows,ncols=3,3 # 遍历标签为1的id for i,id_ in enumerate(malignantIds[:nrows*ncols]): # 获取图像路径 full_filenames = os.path.join(path2train , id_ +'.tif') # 打开图像 img = Image.open(full_filenames) # 在图像上绘制矩形 draw = ImageDraw.Draw(img) draw.rectangle(((32, 32), (64, 64)),outline="green") # 显示子图 plt.subplot(nrows, ncols, i+1) # 如果颜色模式为True,则显示彩色图像 if color is True: plt.imshow(np.array(img)) # 否则显示灰度图像 else: plt.imshow(np.array(img)[:,:,0],cmap="gray") # 关闭坐标轴 plt.axis('off')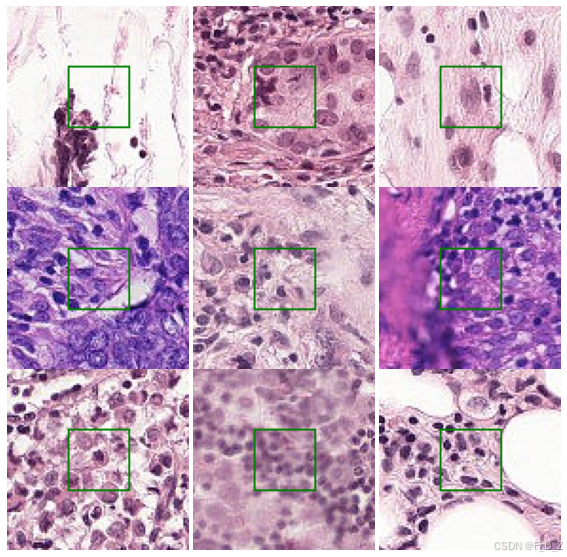
# 打印图像的形状 print("image shape:", np.array(img).shape) # 打印图像像素值的范围 print("pixel values range from %s to %s" %(np.min(img), np.max(img))) 
创建自定义数据集
处理数据集的传统方法是将所有图像加载到 NumPy 数组中,但这种方法在处理一个相对较大的数据集时会显著浪费计算机资源,尤其对于RAM有限的计算机。PyTorch 可以通过子类化 PyTorch Dataset 类来创建自定义 Dataset 类来解决这个问题。
创建自定义 Dataset 类时,需定义两个基本函数:__len__ 和 __getitem__。__len__ 函数返回数据集的长度,__getitem__ 函数返回指定索引处的图像。
import torch from PIL import Image from torch.utils.data import Dataset import pandas as pd import torchvision.transforms as transforms import os # 设置随机种子 torch.manual_seed(0) # 定义一个数据集类 class histoCancerDataset(Dataset): def __init__(self, data_dir, transform,data_type="train"): # 获取数据集的路径 path2data=os.path.join(data_dir,data_type) # 获取数据集的文件名 filenames = os.listdir(path2data) # 获取数据集的完整路径 self.full_filenames = [os.path.join(path2data, f) for f in filenames] # 获取标签文件的路径 path2csvLabels=os.path.join(data_dir,"train_labels.csv") # 读取标签文件 labels_df=pd.read_csv(path2csvLabels) # 将标签文件的索引设置为文件名 labels_df.set_index("id", inplace=True) # 获取每个文件的标签 self.labels = [labels_df.loc[filename[:-4]].values[0] for filename in filenames] # 设置数据转换 self.transform = transform def __len__(self): # 返回数据集的长度 return len(self.full_filenames) def __getitem__(self, idx): # 打开图片 image = Image.open(self.full_filenames[idx]) # 对图片进行转换 image = self.transform(image) # 返回图片和标签 return image, self.labels[idx] # 导入torchvision.transforms模块 import torchvision.transforms as transforms # 创建一个数据转换器,将数据转换为张量 data_transformer = transforms.Compose([transforms.ToTensor()]) # 定义数据目录 data_dir = "./data/" # 创建 histoCancerDataset 对象,传入数据目录、数据转换器和数据集类型 histo_dataset = histoCancerDataset(data_dir, data_transformer, "train") # 打印数据集的长度 print(len(histo_dataset)) 
# 加载一张图片 img,label=histo_dataset[9] # 打印图片的形状、最小值和最大值 print(img.shape,torch.min(img),torch.max(img))
拆分数据集
深度学习框架需要提供一个验证数据集来跟踪模型在训练期间的性能,这里使用 20% 的histo_dataset作为验证数据集,其余的作为训练数据集。
from torch.utils.data import random_split # 获取数据集的长度 len_histo=len(histo_dataset) # 计算训练集的长度,取数据集的80% len_train=int(0.8*len_histo) # 计算验证集的长度,取数据集的20% len_val=len_histo-len_train # 将数据集随机分割为训练集和验证集 train_ds,val_ds=random_split(histo_dataset,[len_train,len_val]) # 打印训练集和验证集的长度 print("train dataset length:", len(train_ds)) print("validation dataset length:", len(val_ds)) 
# 遍历训练数据集 for x,y in train_ds: print(x.shape,y) break
# 遍历val_ds中的每个元素,x和y分别表示数据集的输入和标签 for x,y in val_ds: # 打印输入数据的形状和标签 print(x.shape,y) break 
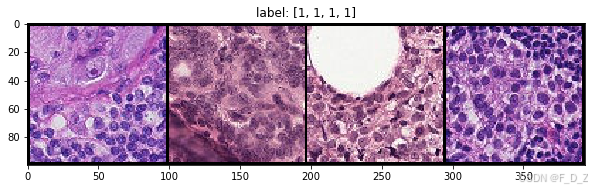
from torchvision import utils import numpy as np import matplotlib.pyplot as plt %matplotlib inline np.random.seed(0) def show(img,y,color=False): # 将img转换为numpy数组 npimg = img.numpy() # 将numpy数组的维度进行转置 npimg_tr=np.transpose(npimg, (1,2,0)) # 如果color为False,则将numpy数组的维度进行转置,并只取第一个通道 if color==False: npimg_tr=npimg_tr[:,:,0] # 使用imshow函数显示图像,并设置插值方式为最近邻插值,颜色映射为灰度 plt.imshow(npimg_tr,interpolation='nearest',cmap="gray") else: # 使用imshow函数显示图像,并设置插值方式为最近邻插值 plt.imshow(npimg_tr,interpolation='nearest') # 设置图像标题,显示标签 plt.title("label: "+str(y)) # 设置网格大小 grid_size=4 # 随机生成4个索引 rnd_inds=np.random.randint(0,len(train_ds),grid_size) print("image indices:",rnd_inds) # 根据索引获取对应的图像和标签 x_grid_train=[train_ds[i][0] for i in rnd_inds] y_grid_train=[train_ds[i][1] for i in rnd_inds] # 将图像组合成网格 x_grid_train=utils.make_grid(x_grid_train, nrow=4, padding=2) print(x_grid_train.shape) # 设置图像大小 plt.rcParams['figure.figsize'] = (10.0, 5) # 显示图像 show(x_grid_train,y_grid_train)

# 设置网格大小为4 grid_size=4 # 从验证数据集中随机选择4个索引 rnd_inds=np.random.randint(0,len(val_ds),grid_size) print("image indices:",rnd_inds) # 从验证数据集中获取这4个索引对应的图像 x_grid_val=[val_ds[i][0] for i in range(grid_size)] # 从验证数据集中获取这4个索引对应的标签 y_grid_val=[val_ds[i][1] for i in range(grid_size)] # 将这4个图像拼接成一个网格,每行4个图像,每个图像之间有2个像素的间隔 x_grid_val=utils.make_grid(x_grid_val, nrow=4, padding=2) print(x_grid_val.shape) # 显示拼接后的网格图像和对应的标签 show(x_grid_val,y_grid_val)
转换数据
图像转换和图像增强对于训练深度学习模型是必要的。通过使用图像转换可以扩展数据集或调整数据集大小并对其进行归一化,以实现更好的模型性能。典型的转换包括水平和垂直翻转、旋转和调整大小。可以在不更改标签的情况下为二元分类模型使用各种图像转换。例如旋转或翻转恶性图像,不会影响其恶性标签。
# 定义训练数据增强的转换器 train_transformer = transforms.Compose([ # 随机水平翻转,翻转概率为0.5 transforms.RandomHorizontalFlip(p=0.5), # 随机垂直翻转,翻转概率为0.5 transforms.RandomVerticalFlip(p=0.5), # 随机旋转45度 transforms.RandomRotation(45), # 随机裁剪,裁剪后的尺寸为96,缩放范围为0.8到1.0,宽高比为1.0 transforms.RandomResizedCrop(96,scale=(0.8,1.0),ratio=(1.0,1.0)), # 转换为张量 transforms.ToTensor()]) # 定义一个数据转换器,将数据转换为张量 val_transformer = transforms.Compose([transforms.ToTensor()]) # 将训练数据集的转换器赋值给训练数据集的transform属性 train_ds.transform=train_transformer # 将验证数据集的转换器赋值给验证数据集的transform属性 val_ds.transform=val_transformer创建数据加载器
PyTorch 数据加载器可以用于批处理数据,如果不使用数据加载器,则需要编写代码来循环数据集并提取数据批处理, 而PyTorch Dataloader可以自动执行此过程。
# 导入DataLoader类 from torch.utils.data import DataLoader # 创建训练数据集的DataLoader,batch_size为32,shuffle为True,表示每次迭代时都会打乱数据集 train_dl = DataLoader(train_ds, batch_size=32, shuffle=True) # 创建验证数据集的DataLoader,batch_size为64,shuffle为False,表示每次迭代时不会打乱数据集 val_dl = DataLoader(val_ds, batch_size=64, shuffle=False) # 遍历训练数据集 for x, y in train_dl: print(x.shape) print(y.shape) break # 遍历验证数据集 for x, y in val_dl: print(x.shape) print(y.shape) break

构建分类模型
构建一个由四个卷积神经网络(CNN)和两个全连接层组成的分类模型,卷积层处理输入图像并提取特征向量,该特征向量被逐层馈送到全连接层,最终进入二元分类输出层:
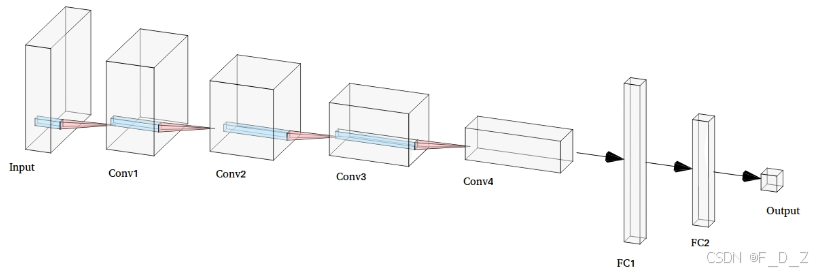
# 从验证数据集中提取出y值 y_val=[y for _,y in val_ds] # 定义一个函数,计算准确率 def accuracy(labels, out): # 计算预测结果与真实标签相同的数量,并除以标签的总数,得到准确率 return np.sum(out==labels)/float(len(labels)) # 计算所有预测结果为0的准确率 acc_all_zeros=accuracy(y_val,np.zeros_like(y_val)) # 计算所有预测结果为1的准确率 acc_all_ones=accuracy(y_val,np.ones_like(y_val)) # 计算随机预测的准确率 acc_random=accuracy(y_val,np.random.randint(2,size=len(y_val))) # 打印随机预测的准确率 print("accuracy random prediction: %.2f" %acc_random) # 打印所有预测结果为0的准确率 print("accuracy all zero prediction: %.2f" %acc_all_zeros) # 打印所有预测结果为1的准确率 print("accuracy all one prediction: %.2f" %acc_all_ones)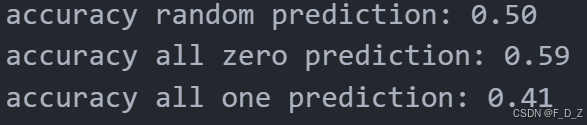
import torch.nn as nn import numpy as np # 定义一个函数,用于计算卷积层的输出形状 def findConv2dOutShape(H_in,W_in,conv,pool=2): # 获取卷积核的大小 kernel_size=conv.kernel_size # 获取卷积的步长 stride=conv.stride # 获取卷积的填充 padding=conv.padding # 获取卷积的扩张 dilation=conv.dilation # 计算卷积后的输出高度 H_out=np.floor((H_in+2*padding[0]-dilation[0]*(kernel_size[0]-1)-1)/stride[0]+1) # 计算卷积后的输出宽度 W_out=np.floor((W_in+2*padding[1]-dilation[1]*(kernel_size[1]-1)-1)/stride[1]+1) # 如果有池化层,则计算池化层输出的高度和宽度 if pool: H_out/=pool W_out/=pool return int(H_out),int(W_out) # 定义一个卷积层,输入通道数为3,输出通道数为8,卷积核大小为3x3 conv1 = nn.Conv2d(3, 8, kernel_size=3) # 计算卷积层的输出形状 h,w=findConv2dOutShape(96,96,conv1) # 打印输出形状 print(h,w)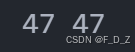
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self, params): super(Net, self).__init__() # 获取输入形状 C_in,H_in,W_in=params["input_shape"] # 获取初始卷积核数量 init_f=params["initial_filters"] # 获取第一个全连接层神经元数量 num_fc1=params["num_fc1"] # 获取分类数量 num_classes=params["num_classes"] # 获取dropout率 self.dropout_rate=params["dropout_rate"] # 定义第一个卷积层 self.conv1 = nn.Conv2d(C_in, init_f, kernel_size=3) # 计算卷积层输出形状 h,w=findConv2dOutShape(H_in,W_in,self.conv1) # 定义第二个卷积层 self.conv2 = nn.Conv2d(init_f, 2*init_f, kernel_size=3) h,w=findConv2dOutShape(h,w,self.conv2) # 定义第三个卷积层 self.conv3 = nn.Conv2d(2*init_f, 4*init_f, kernel_size=3) h,w=findConv2dOutShape(h,w,self.conv3) # 定义第四个卷积层 self.conv4 = nn.Conv2d(4*init_f, 8*init_f, kernel_size=3) h,w=findConv2dOutShape(h,w,self.conv4) # 计算展平后的尺寸 self.num_flatten=h*w*8*init_f # 定义第一个全连接层 self.fc1 = nn.Linear(self.num_flatten, num_fc1) # 定义第二个全连接层 self.fc2 = nn.Linear(num_fc1, num_classes) def forward(self, x): # 第一个卷积层 x = F.relu(self.conv1(x)) # 最大池化 x = F.max_pool2d(x, 2, 2) # 第二个卷积层 x = F.relu(self.conv2(x)) x = F.max_pool2d(x, 2, 2) # 第三个卷积层 x = F.relu(self.conv3(x)) x = F.max_pool2d(x, 2, 2) # 第四个卷积层 x = F.relu(self.conv4(x)) x = F.max_pool2d(x, 2, 2) x = x.view(-1, self.num_flatten) # 第一个全连接层 x = F.relu(self.fc1(x)) x=F.dropout(x, self.dropout_rate) # 第二个全连接层 x = self.fc2(x) return F.log_softmax(x, dim=1) # 定义一个字典 params_model={ "input_shape": (3,96,96), # 输入形状 "initial_filters": 8, # 初始滤波器数量 "num_fc1": 100, # 第一全连接层神经元数量 "dropout_rate": 0.25, # dropout率 "num_classes": 2, # 类别数量 } # 创建模型 cnn_model = Net(params_model) #模型移动到cuda设备 if torch.cuda.is_available(): device = torch.device("cuda") cnn_model=cnn_model.to(device) #打印模型 print(cnn_model)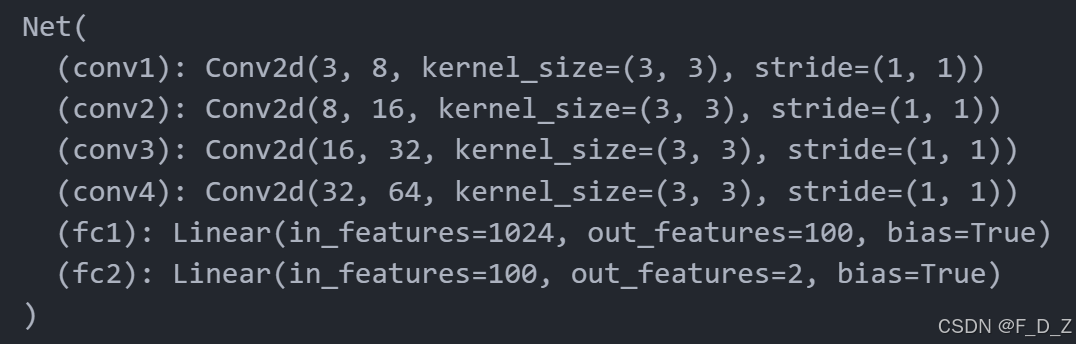
# 导入torchsummary模块,用于打印模型结构 from torchsummary import summary # 打印cnn_model模型的结构,输入大小为(3, 96, 96) summary(cnn_model, input_size=(3, 96, 96))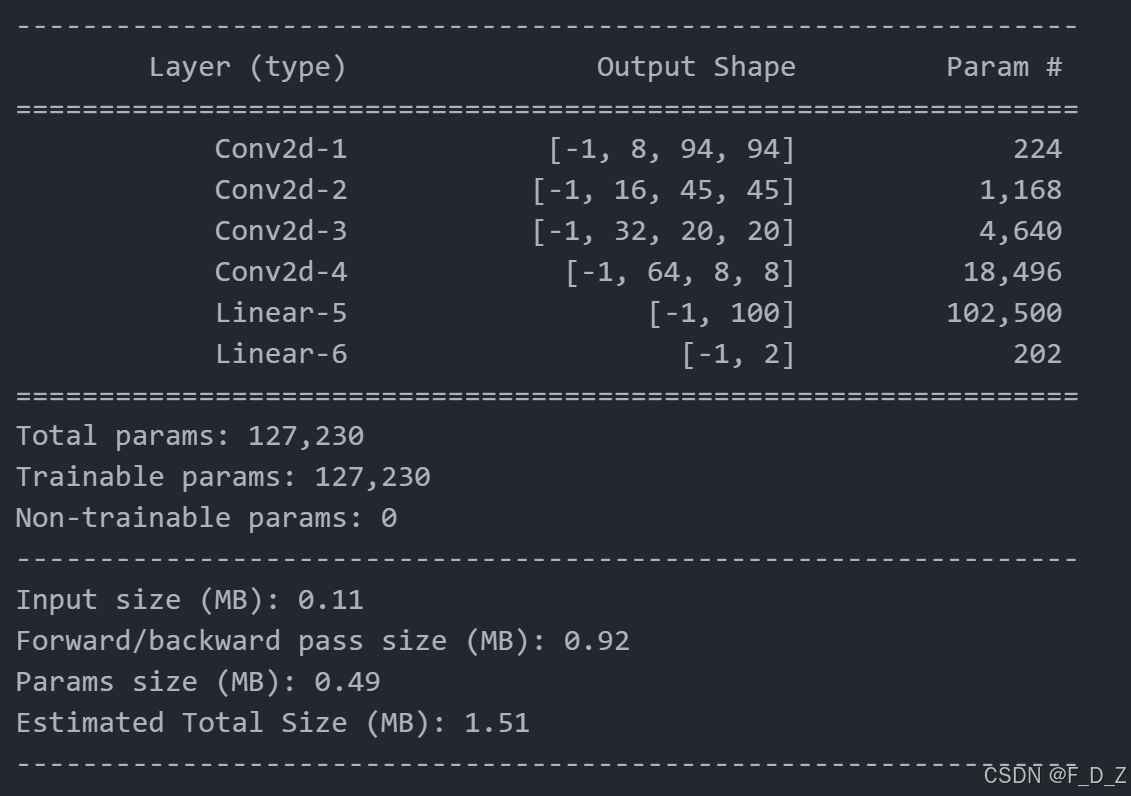
定义损失函数
分类任务的标准损失函数是交叉熵损失或对数损失。在定义损失函数时需要考虑模型输出的数量及其激活函数,对照表如下。对于二元分类任务,可以选择一个或两个输出。通常使用 log_softmax 函数,因为它更容易扩展到多类分类。PyTorch 将 log 和 softmax 操作合并为一个函数。
| 输出激活 | 输出数量 | 损失函数 |
|---|---|---|
| None | 1 | nn.BCEWithLogitsLoss |
| Sigmoid | 1 | nn.BCELoss |
| None | 2 | nn.CrossEntropyLoss |
| log_softmax | 2 | nn.NLLLoss |
# 定义损失函数为负对数似然损失函数,并设置reduction参数为sum,表示将所有样本的损失相加 loss_func = nn.NLLLoss(reduction="sum") # 设置随机种子,使得每次运行结果一致 torch.manual_seed(0) # 定义输入数据的维度 n,c=8,2 # 生成随机数据 y = torch.randn(n, c, requires_grad=True) # 定义LogSoftmax函数 ls_F = nn.LogSoftmax(dim=1) # 对数据进行LogSoftmax处理 y_out=ls_F(y) # 打印处理后的数据形状 print(y_out.shape) # 生成随机目标数据 target = torch.randint(c,size=(n,)) # 打印目标数据形状 print(target.shape) # 计算损失函数 loss = loss_func(y_out, target) # 打印损失函数值 print(loss.item()) 
# 反向传播,计算梯度 loss.backward() print (y.data) 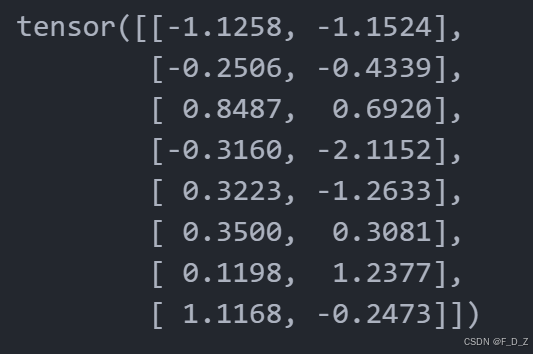
定义优化器
torch.optim 包提供了通用优化器的实现。优化器将保持当前状态,并根据计算出的梯度更新参数。对于二元分类任务,最常使用 SGD 和 Adam 优化器。
from torch import optim # 定义优化器,使用Adam算法,传入模型参数和学习率 opt = optim.Adam(cnn_model.parameters(), lr=3e-4) # 定义一个函数,用于获取当前的学习率 def get_lr(opt): # 遍历opt中的param_groups for param_group in opt.param_groups: # 返回param_group中的学习率 return param_group['lr'] # 调用get_lr函数,获取当前的学习率 current_lr=get_lr(opt) # 打印当前的学习率 print('current lr={}'.format(current_lr))
from torch.optim.lr_scheduler import ReduceLROnPlateau # 定义学习率调度器 # opt:优化器 # mode:模式,'min'表示当验证损失不再下降时减小学习率 # factor:学习率减小因子,当验证损失不再下降时,学习率将乘以该因子 # patience:耐心,当验证损失不再下降时,等待多少个epoch再减小学习率 # verbose:是否打印信息 lr_scheduler = ReduceLROnPlateau(opt, mode='min',factor=0.5, patience=20,verbose=1) # 遍历100次 for i in range(100): # 每次步进1 lr_scheduler.step(1)
模型训练与评估
训练和验证脚本可能很长且重复,为了提高代码可读性并避免代码重复,需要构建一些辅助函数。
# 定义一个函数metrics_batch,用于计算预测结果和目标之间的正确率 def metrics_batch(output, target): # 将输出结果的最大值所在的索引作为预测结果 pred = output.argmax(dim=1, keepdim=True) # 计算预测结果和目标之间的正确率 corrects=pred.eq(target.view_as(pred)).sum().item() # 返回正确率 return corrects # 定义输入数据的维度,n为样本数,c为特征数 n,c=8,2 # 生成一个随机张量,维度为n*c,requires_grad=True表示需要计算梯度 output = torch.randn(n, c, requires_grad=True) # 打印输出张量 print (output) # 打印输出张量的形状 print(output.shape) # 生成一个全为1的张量,维度为n,dtype为long target = torch.ones(n,dtype=torch.long) print(target.shape) #调用metrics_batch函数,传入输出张量和目标张量 metrics_batch(output,target) 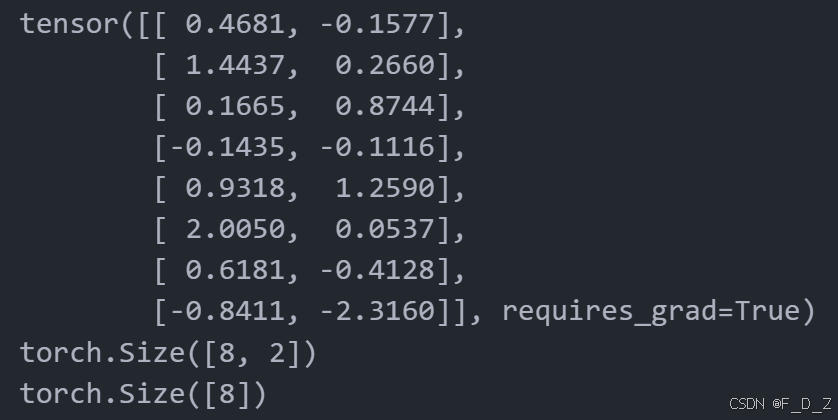
def loss_batch(loss_func, output, target, opt=None): # 计算batch的损失 loss = loss_func(output, target) # 计算batch的指标 metric_b = metrics_batch(output,target) # 如果有优化器,则进行反向传播和参数更新 if opt is not None: opt.zero_grad() loss.backward() opt.step() # 返回损失和指标 return loss.item(), metric_b # 定义设备为全局变量 device = torch.device("cuda") def loss_epoch(model,loss_func,dataset_dl,sanity_check=False,opt=None): # 初始化运行损失和运行指标 running_loss=0.0 running_metric=0.0 # 获取数据集长度 len_data=len(dataset_dl.dataset) # 遍历数据集 for xb, yb in dataset_dl: # 将批次移动到设备上 xb=xb.to(device) yb=yb.to(device) # 获取模型输出 output=model(xb) # 获取每个批次的损失 loss_b,metric_b=loss_batch(loss_func, output, yb, opt) # 更新运行损失 running_loss+=loss_b # 更新运行指标 if metric_b is not None: running_metric+=metric_b # 如果是sanity check,则跳出循环 if sanity_check is True: break # 计算平均损失值 loss=running_loss/float(len_data) # 计算平均指标值 metric=running_metric/float(len_data) return loss, metric def train_val(model, params): # 获取参数 num_epochs=params["num_epochs"] loss_func=params["loss_func"] opt=params["optimizer"] train_dl=params["train_dl"] val_dl=params["val_dl"] sanity_check=params["sanity_check"] lr_scheduler=params["lr_scheduler"] path2weights=params["path2weights"] # 记录训练和验证损失 loss_history={ "train": [], "val": [], } # 记录训练和验证指标 metric_history={ "train": [], "val": [], } # 记录最佳模型权重 best_model_wts = copy.deepcopy(model.state_dict()) # 记录最佳验证损失 best_loss=float('inf') # 遍历所有epoch for epoch in range(num_epochs): # 获取当前学习率 current_lr=get_lr(opt) # 打印当前epoch和当前学习率 print('Epoch {}/{}, current lr={}'.format(epoch, num_epochs - 1, current_lr)) # 将模型设置为训练模式 model.train() # 计算训练集上的损失和指标 train_loss, train_metric=loss_epoch(model,loss_func,train_dl,sanity_check,opt) # 将训练集上的损失和指标添加到历史记录中 loss_history["train"].append(train_loss) metric_history["train"].append(train_metric) # 将模型设置为评估模式 model.eval() # 计算验证集上的损失和指标 with torch.no_grad(): val_loss, val_metric=loss_epoch(model,loss_func,val_dl,sanity_check) # 如果验证集上的损失小于最佳损失,则更新最佳损失和最佳模型权重 if val_loss < best_loss: best_loss = val_loss best_model_wts = copy.deepcopy(model.state_dict()) # 保存最佳模型权重 torch.save(model.state_dict(), path2weights) print("Copied best model weights!") # 将验证集上的损失和指标添加到历史记录中 loss_history["val"].append(val_loss) metric_history["val"].append(val_metric) # 更新学习率 lr_scheduler.step(val_loss) # 如果学习率发生变化,则加载最佳模型权重 if current_lr != get_lr(opt): print("Loading best model weights!") model.load_state_dict(best_model_wts) # 打印训练集上的损失、验证集上的损失和验证集上的准确率 print("train loss: %.6f, dev loss: %.6f, accuracy: %.2f" %(train_loss,val_loss,100*val_metric)) print("-"*10) # 加载最佳模型权重 model.load_state_dict(best_model_wts) return model, loss_history, metric_history import copy # 定义损失函数 loss_func = nn.NLLLoss(reduction="sum") # 定义优化器 opt = optim.Adam(cnn_model.parameters(), lr=3e-4) # 定义学习率调度器 lr_scheduler = ReduceLROnPlateau(opt, mode='min',factor=0.5, patience=20,verbose=1) # 定义训练参数 params_train={ "num_epochs": 100, # 训练轮数 "optimizer": opt, # 优化器 "loss_func": loss_func, # 损失函数 "train_dl": train_dl, # 训练数据集 "val_dl": val_dl, # 验证数据集 "sanity_check": True, # 是否进行sanity check "lr_scheduler": lr_scheduler, # 学习率调度器 "path2weights": "./models/weights.pt", # 模型权重保存路径 } # 训练和验证模型 cnn_model,loss_hist,metric_hist=train_val(cnn_model,params_train)
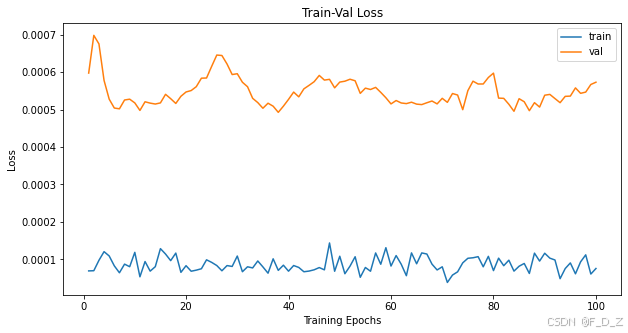
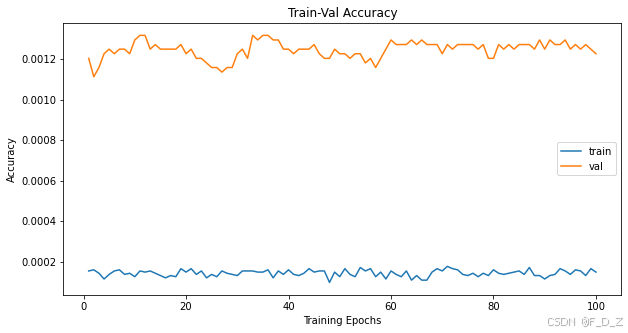
# 获取训练参数中的训练轮数 num_epochs=params_train["num_epochs"] # 绘制训练和验证损失曲线 plt.title("Train-Val Loss") plt.plot(range(1,num_epochs+1),loss_hist["train"],label="train") plt.plot(range(1,num_epochs+1),loss_hist["val"],label="val") plt.ylabel("Loss") plt.xlabel("Training Epochs") plt.legend() plt.show() # 绘制训练和验证准确率曲线 plt.title("Train-Val Accuracy") plt.plot(range(1,num_epochs+1),metric_hist["train"],label="train") plt.plot(range(1,num_epochs+1),metric_hist["val"],label="val") plt.ylabel("Accuracy") plt.xlabel("Training Epochs") plt.legend() plt.show()