
阅读量:0
最近我又在找工作了,悲哀啊~,面试官给了一道题,要求如下:
爬虫机试:https://detail.1688.com/offer/643272204627.html 过该链接的滑动验证码,拿到正确的商品信息页html,提取出商品维度的信息,输出json
由于时间紧迫,想着去破解加密参数x5sec估计时间也不够,最后采用自动化工具先应付一下面试,毕竟能不能入职还是未知数。
言归正传,先看效果图如下: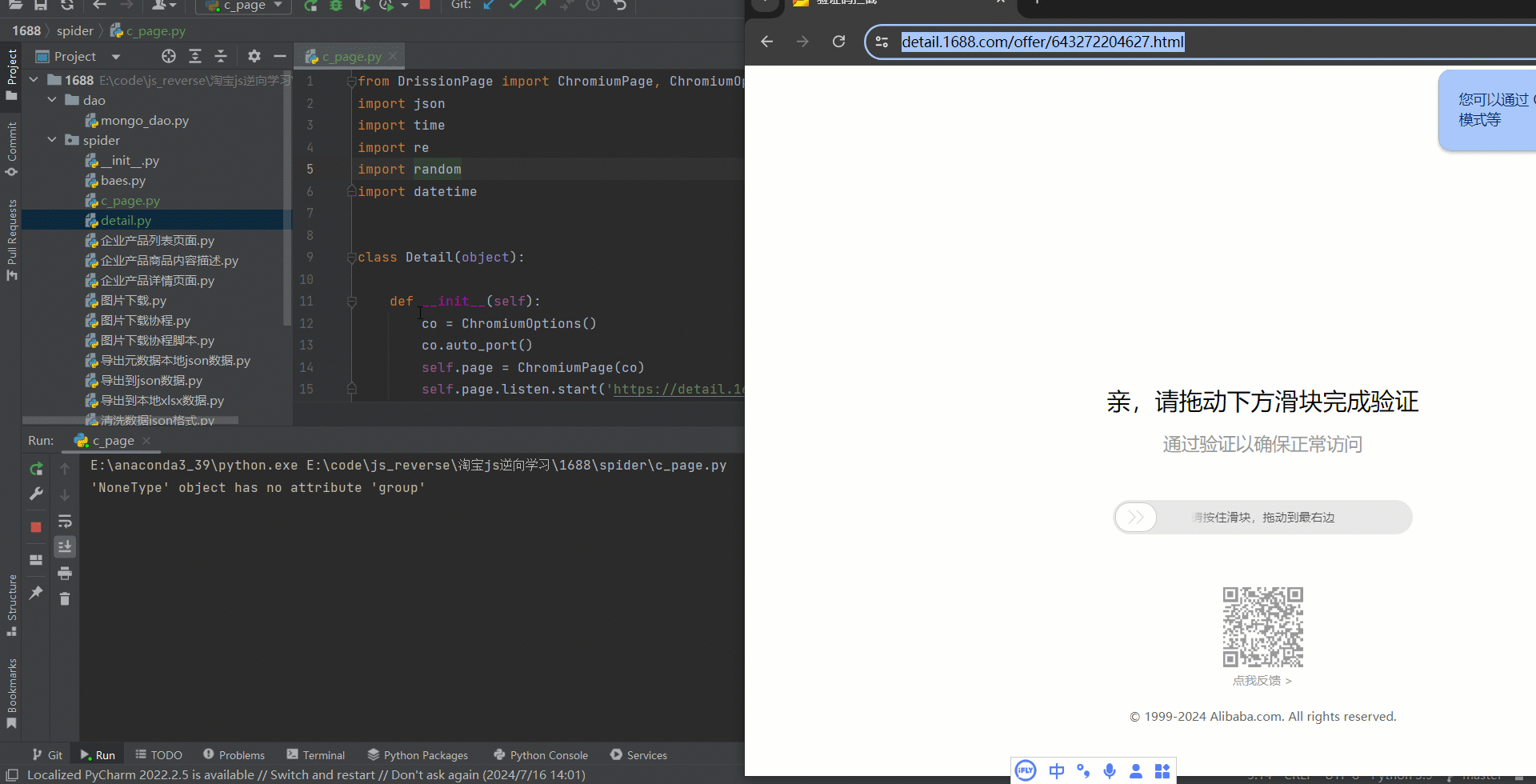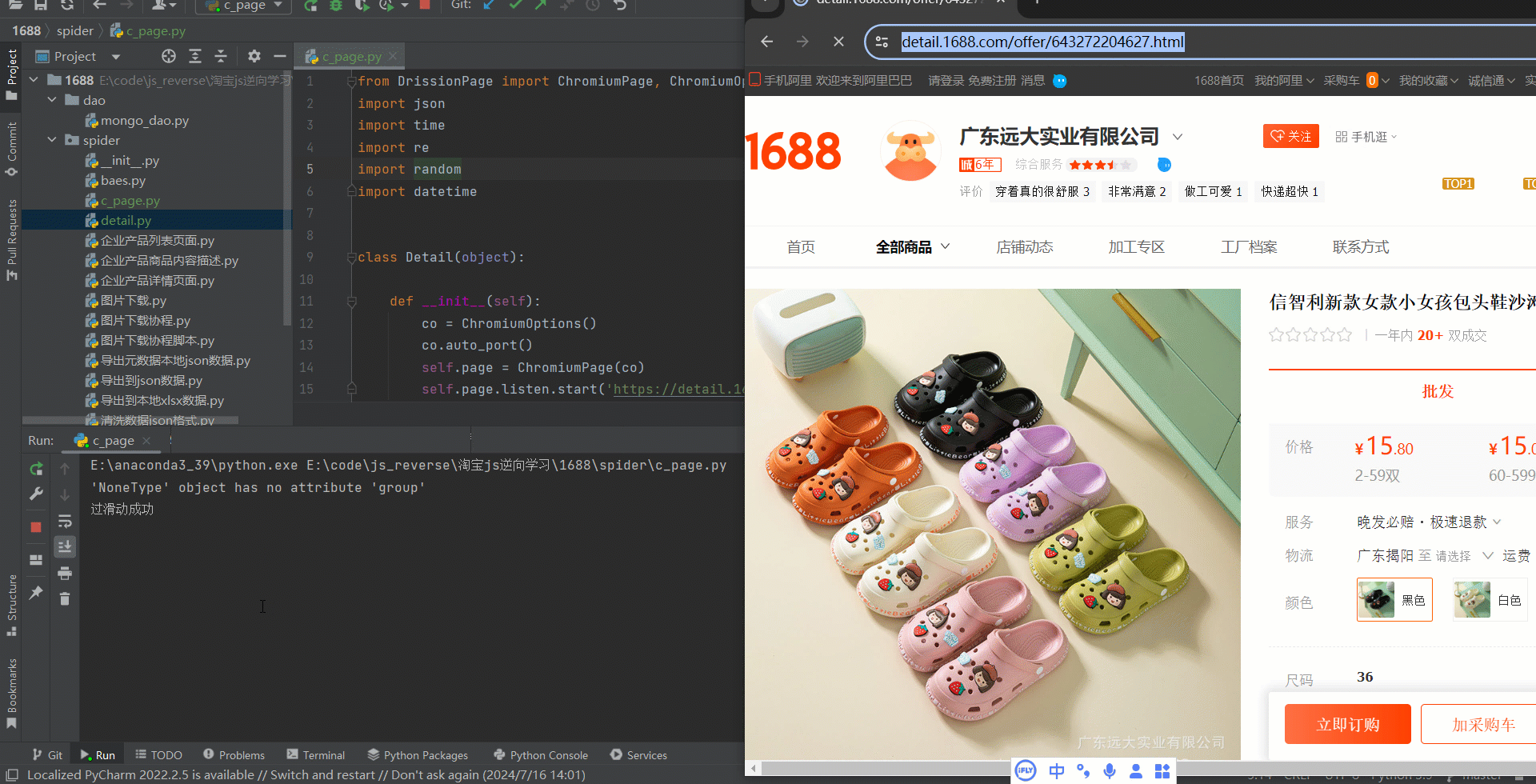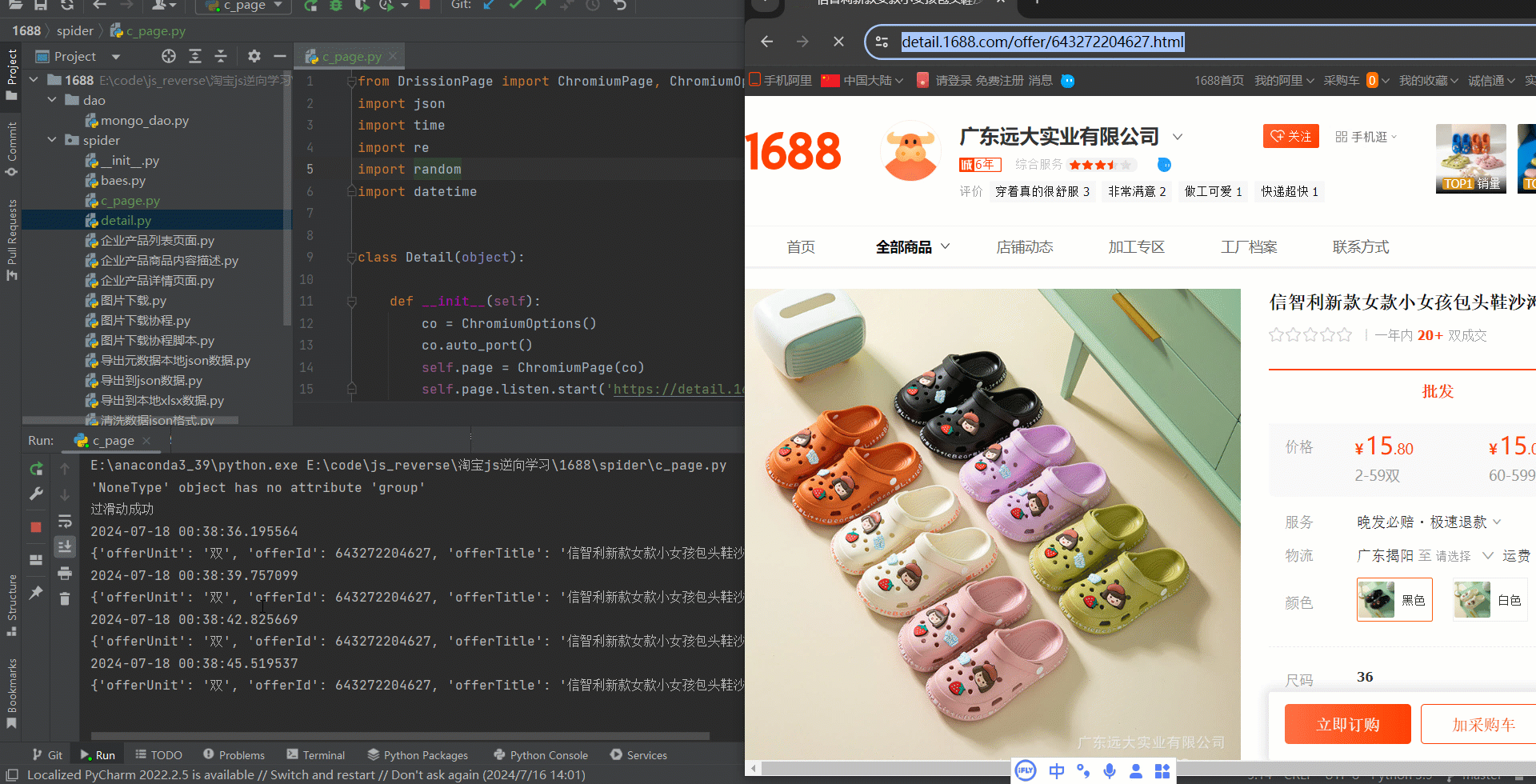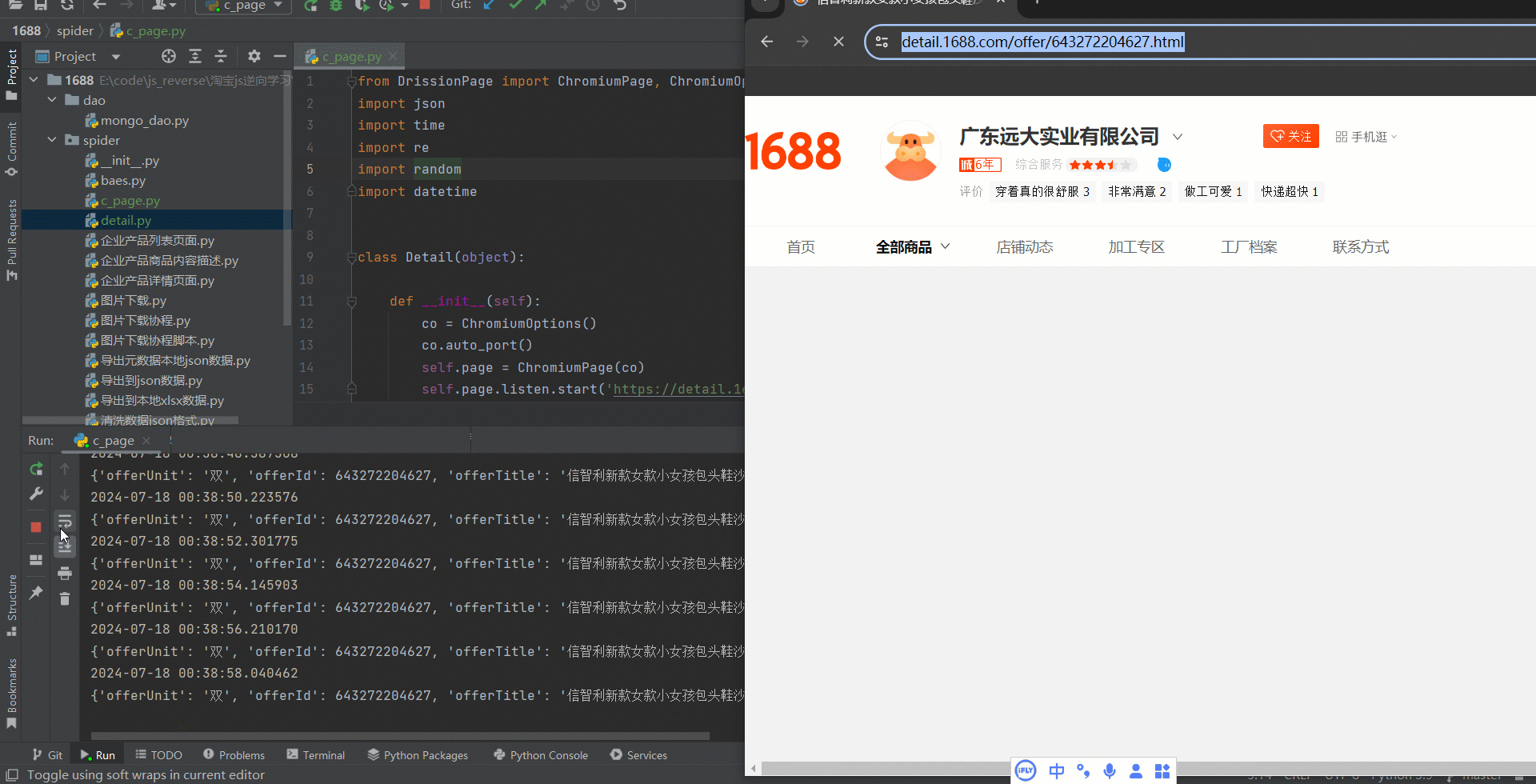
众所周知阿里的滑块检测是比较多的,常规的自动化工具无法过滑块。所有这次尝试用DrissionPage去破解。
DrissionPage文档地址如下:
https://www.drissionpage.cn/
每次运行代码后都会启动一个全新的浏览器,防止浏览器缓存被检测
from DrissionPage import ChromiumPage, ChromiumOptions co = ChromiumOptions() co.auto_port() page = ChromiumPage(co) 通过监听数据包的方式获取数据
self.page.listen.start('https://detail.1688.com/all') 自定义滑块轨迹,这点还是比较重要的,模拟的越像人工轨迹越不会被检测。
def slide(self): """ 滑动代码 :return: """ ele = self.page.wait.eles_loaded("x://span[contains(@id,'nc_1_n1z')]", timeout=20) if ele: ele = self.page.ele("#nc_1_n1t") time.sleep(3) ele.hover() self.page.actions.hold('#nc_1_n1z') self.page.actions.move(100, duration=random.random()) self.page.actions.move(100, duration=random.random()) self.page.actions.move(59, duration=3) 报错捕获,目前发现当抓取的数据超过一定量后,必然会触发封控机制,这时候就需要换IP处理。
if self.page.wait.eles_loaded("#recyclerview"): print('过滑动成功') elif self.page.wait.eles_loaded("#nc_1_refresh1"): print('滑动失败') # 需要继续处理....... elif self.page.wait.eles_loaded("#login-form"): print('需要登陆/换IP') # 需要继续处理....... 完整代码如下:
from DrissionPage import ChromiumPage, ChromiumOptions import json import time import re import random import datetime class Detail(object): def __init__(self): co = ChromiumOptions() co.auto_port() self.page = ChromiumPage(co) self.page.listen.start('https://detail.1688.com/offer/643272204627.html') def slide(self): """ 滑动代码 :return: """ ele = self.page.wait.eles_loaded("x://span[contains(@id,'nc_1_n1z')]", timeout=20) if ele: ele = self.page.ele("#nc_1_n1t") time.sleep(3) ele.hover() self.page.actions.hold('#nc_1_n1z') self.page.actions.move(100, duration=random.random()) self.page.actions.move(100, duration=random.random()) self.page.actions.move(59, duration=3) def request_body(self): url = 'https://detail.1688.com/offer/643272204627.html' self.page.get(url) res = self.page.listen.wait() pattern = r'window\.__INIT_DATA\s*=\s*(\{.*?\})\s*</script>' match = re.search(pattern, res.response.body) try: json_data = match.group(1) dict_data = json.loads(json_data) temp_model = dict_data.get('globalData').get('tempModel') print(datetime.datetime.now()) print(temp_model) except Exception as e: print(e) self.slide() if self.page.wait.eles_loaded("#recyclerview"): print('过滑动成功') elif self.page.wait.eles_loaded("#nc_1_refresh1"): print('滑动失败') # 需要继续处理....... elif self.page.wait.eles_loaded("#login-form"): print('需要登陆/换IP') # 需要继续处理....... def run(self): for i in range(1, 100000): self.request_body() if __name__ == '__main__': detail = Detail() detail.run() 最后总结一下,代码是半成品,想要实现完美的抓取阿里1688数据
- 第一需要完成IP代理模块;
- 第二完善报错机制;
- 第三优化滑块轨迹逻辑。
